 C/C++協程編程的相關概念和技巧
C/C++協程編程的相關概念和技巧
一、引言
協程的定義和背景
協程(Coroutine),又稱為微線程或者輕量級線程,是一種用戶態的、可在單個線程中并發執行的程序組件。協程可以看作是一個更輕量級的線程,由程序員主動控制調度。它們擁有自己的寄存器上下文和棧,可以在多個入口點間自由切換,而不是像傳統的函數調用那樣在一個入口點開始、另一個入口點結束。協程的概念最早可以追溯到1963年,由Melvin Conway提出。經過多年的發展,協程已經成為了現代編程語言和框架中的一種重要編程范式。
協程與線程、進程的區別
協程、線程和進程都是程序執行的基本單元,但它們之間有一些顯著的區別:
- 進程:進程是操作系統分配資源和調度的基本單位,具有獨立的內存空間和系統資源。進程間的通信和切換開銷較大。
- 線程:線程是進程內的一個執行單元,擁有自己的執行棧和寄存器上下文,但共享進程內的內存空間和系統資源。線程間的切換開銷小于進程,但仍受到操作系統調度。
- 協程:協程是在用戶態實現的,可以在一個線程內并發執行。協程擁有自己的寄存器上下文和棧,但協程間的切換由程序員主動控制,避免了操作系統調度開銷。
協程相較于線程的優點
- 上下文切換開銷小:協程之間的上下文切換僅涉及用戶態,避免了內核態切換帶來的開銷。
- 內存占用低:協程的棧空間通常較小,且可動態調整,有效降低內存占用。
- 高并發性能:由于協程的調度開銷小,可以創建大量協程并發執行,提高程序性能。
協程的優勢與局限性
優勢:
- 輕量級:協程的創建和切換開銷遠小于線程,適用于高并發場景。
- 靈活性:協程調度由程序員主動控制,更適應于復雜的邏輯和任務調度需求。
- 高效:協程在單個線程內并發執行,避免了線程同步的開銷,提高了CPU利用率。
局限性:
- 用戶態:協程是用戶態實現的,不能利用多核并行處理的優勢。
- 協作:協程需要程序員主動調度,需要對代碼邏輯有更好的把控,以避免死鎖等問題。
- 兼容性:協程在不同編程語言和平臺上的實現和支持程度不同,可能需要額外的庫和工具支持。
- 異常處理復雜:協程的異常處理機制通常較為復雜,需要特殊處理以保證異常安全。
二、協程基礎知識
在了解協程編程之前,我們需要掌握一些基本概念,包括生成器、協程、堆棧以及協程的狀態。
基本概念
生成器(generator):
生成器是一種特殊的函數,它可以保存當前執行狀態,并在下次調用時從保存的狀態繼續執行。生成器使用關鍵字yield來暫停函數執行,并返回一個值,下次調用時從yield的位置繼續執行。
協程(coroutine):
協程是一種用戶態的程序組件,擁有自己的寄存器上下文和棧。協程可以在多個入口點間自由切換,實現非搶占式的多任務調度。協程與生成器類似,都可以暫停執行并在下次調用時恢復執行,但協程的調度更加靈活。
堆棧(stack):
堆棧是一種先進后出(LIFO)的數據結構,用于保存函數調用的狀態。在協程切換時,會將當前協程的堆棧信息保存起來,下次恢復執行時再加載該堆棧信息。這使得協程能夠實現非線性的執行流程。
協程的基本原理
協程的基本原理包括以下幾點:
- 協程控制塊:保存協程的狀態、棧指針、上下文等信息。
- 協程創建:分配協程控制塊和棧空間,初始化協程狀態。
- 協程切換:在協程之間進行上下文切換,包括保存和恢復協程的上下文。
- 協程銷毀:釋放協程占用的資源,如棧空間,刪除協程控制塊。
- 協程調度器:管理所有協程的創建、調度和銷毀。協程調度器負責在多個協程之間進行上下文切換,以實現協程并發執行。
協程狀態
在協程的生命周期中,它會經歷不同的狀態,主要包括運行中、掛起和終止三種。
- a. 運行中:協程正在執行,具有線程上下文。當協程函數被調用時,協程會進入運行中狀態。
- b. 掛起:協程暫停執行,保存當前的堆棧信息和上下文。當遇到如yield或其他協程操作時,協程會進入掛起狀態,等待再次恢復執行。
- c. 終止:協程執行完畢,釋放協程的資源。當協程函數執行到返回值時,協程會進入終止狀態。
理解協程的基本概念和狀態對于編寫高效的協程程序至關重要。接下來,我們將學習如何在Linux C/C++編程中使用協程來實現高并發和靈活的任務調度。
三、C/C++協程編程實踐
創建和使用協程
a. 協程函數編寫
協程函數是指實際執行協程任務的函數。在編寫協程函數時,需要遵循以下原則:
- 協程函數通常接受一個指針類型的參數,用于傳遞數據和狀態;
- 協程函數需要考慮到任務的并發性,避免使用全局變量和非線程安全的函數;
- 在協程函數中,可以使用yield或其他協程操作來掛起和恢復執行。
b. 協程創建
使用協程庫提供的接口創建協程。在創建協程時,需要指定協程函數、傳遞給協程函數的參數以及協程的棧大小。
例如,在libaco中創建協程的方式如下:
#include < aco.h >
void *co_func(void *arg) {
// 協程任務邏輯
}
int main() {
aco_t *co = aco_create(NULL, NULL, 0, co_func, NULL);
}
c. 協程切換與恢復
協程的切換和恢復由協程庫提供的接口實現。切換協程時,需要保存當前協程的執行狀態,并加載另一個協程的執行狀態。恢復協程時,需要從保存的狀態中恢復執行。例如,在libaco中切換和恢復協程的方式如下:
例如,在libaco中創建協程的方式如下:
#include < aco.h >
void *co_func(void *arg) {
// 協程任務邏輯
aco_yield(); // 切換到其他協程
}
int main() {
aco_t *co = aco_create(NULL, NULL, 0, co_func, NULL);
aco_resume(co); // 恢復協程執行
}
d. 協程的結束和清理
當協程任務執行完畢,協程會進入終止狀態。在協程終止之后,需要對協程的資源進行清理。例如,在libaco中結束和清理協程的方式如下:
#include < aco.h >
void *co_func(void *arg) {
// 協程任務邏輯
}
int main() {
aco_t *co = aco_create(NULL, NULL, 0, co_func, NULL);
aco_resume(co);
// 協程任務執行完畢,清理協程資源
aco_destroy(co);
}
四、同步和異步協程操作
在協程編程中,通常需要處理多個協程之間的同步和異步操作。同步操作需要等待其他協程完成某個任務,而異步操作則允許協程并發地執行任務。為了實現同步和異步操作,我們可以使用協程鎖、協程信號量和通道等機制。
a. 同步協程操作
同步協程操作用于實現多個協程之間的協作。在同步操作中,一個協程需要等待其他協程完成某個任務才能繼續執行。同步協程操作的實現可以使用以下機制:
- 協程鎖(coroutine lock):協程鎖是一種同步原語,用于確保同一時間只有一個協程可以訪問共享資源。協程鎖的實現類似于線程鎖,但協程鎖的等待過程不會阻塞線程。
- 協程信號量(coroutine semaphore):協程信號量是一種計數同步原語,用于限制同時訪問共享資源的協程數量。信號量可以保證一定數量的協程可以同時訪問共享資源,其他協程需要等待信號量可用。
在libmill中使用協程鎖和信號量
#include < libmill.h >
coroutine void co_func(lock *lk, semaphore *sem) {
// 獲取協程鎖
lock_acquire(lk);
// 執行臨界區代碼
lock_release(lk);
// 獲取協程信號量
sem_acquire(sem);
// 訪問共享資源
sem_release(sem);
}
int main() {
lock lk = lock_make();
semaphore sem = sem_make(3);
// 創建多個協程并執行
go(co_func(lk, sem));
go(co_func(lk, sem));
go(co_func(lk, sem));
// 等待所有協程執行完畢
msleep(now() + 1000);
}
使用libaco協程庫實現一個簡單的生產者-消費者模型(協程鎖和協程條件變量)
#include < aco.h >
#include < queue >
#include < mutex >
#include < condition_variable >
std::queue< int > q;
std::mutex mtx;
std::condition_variable cv;
const int max_queue_size = 10;
void* producer(void *arg) {
aco_t* this_co = aco_get_co();
for (int i = 0; i < 100; ++i) {
std::unique_lock< std::mutex > lock(mtx);
cv.wait(lock, [&](){ return q.size() < max_queue_size; });
q.push(i);
printf("Producer: %dn", i);
cv.notify_one();
lock.unlock();
aco_yield();
}
return NULL;
}
void* consumer(void *arg) {
aco_t* this_co = aco_get_co();
while (true) {
std::unique_lock< std::mutex > lock(mtx);
cv.wait(lock, [&](){ return !q.empty(); });
int item = q.front();
q.pop();
printf("Consumer: %dn", item);
cv.notify_one();
lock.unlock();
aco_yield();
}
return NULL;
}
int main() {
aco_thread_init(NULL);
aco_t* main_co = aco_create(NULL, NULL, 0, NULL, NULL);
aco_t* producer_co = aco_create(main_co, NULL, 0, producer, NULL);
aco_t* consumer_co = aco_create(main_co, NULL, 0, consumer, NULL);
for (int i = 0; i < 100; ++i) {
aco_resume(producer_co);
aco_resume(consumer_co);
}
aco_destroy(producer_co);
aco_destroy(consumer_co);
aco_destroy(main_co);
return 0;
}
b. 異步協程操作
異步協程操作允許多個協程并發地執行任務,無需等待其他協程完成。異步操作可以提高程序的并發性能,特別是在I/O密集型任務中。
- 通道(channel)是一種實現異步協程操作的有效機制。
通道(channel):通道是一種先進先出(FIFO)的隊列,可以在多個協程之間傳遞數據。協程可以向通道發送數據,并在其他協程中接收數據。通道實現了協程間的異步通信和數據傳遞。
除了使用通道(channel)實現異步協程操作外,還可以使用其他方式如事件驅動編程和協程池來實現協程間的異步操作。
簡單的生產者-消費者模型(libmill協程庫_實現異步操作)
#include < libmill.h >
#include < stdio.h >
typedef struct item {
int value;
} item;
coroutine void producer(chan ch, int id) {
for (int i = 0; i < 10; ++i) {
item it;
it.value = i;
chs(ch, item, it);
printf("Producer %d: %dn", id, i);
msleep(now() + rand() % 100);
}
}
coroutine void consumer(chan ch, int id) {
while (1) {
item it = chr(ch, item);
printf("Consumer %d: %dn", id, it.value);
msleep(now() + rand() % 100);
}
}
int main() {
srand(time(NULL));
chan ch = chmake(item, 5);
for (int i = 0; i < 3; ++i) {
go(producer(ch, i));
}
for (int i = 0; i < 5; ++i) {
go(consumer(ch, i));
}
// 運行一段時間,讓生產者和消費者協程有機會執行
msleep(now() + 5000);
// 釋放通道資源
chclose(ch);
return 0;
}
在這個示例中,我們使用了libmill協程庫,它包含了內置的通道支持。我們創建了3個生產者協程和5個消費者協程。生產者協程將生產的數據通過通道發送,消費者協程從通道中接收數據。這種方式可以實現生產者和消費者之間的異步操作。
生產者協程在每次生產一個數據項后,會休眠一段隨機的時間,這樣可以模擬生產過程中的延遲。類似地,消費者協程在接收到一個數據項并處理后,也會休眠一段隨機的時間。這些休眠時間可以在現實生活中的生產和消費過程中產生延遲,從而演示異步協程操作。
事件驅動編程
事件驅動編程是一種異步編程范式,協程在等待某個事件(如IO操作完成、定時器觸發等)時可以讓出執行權。
事件驅動的協程庫通常提供一種事件循環機制,用于監聽和處理事件。
下面是一個使用libev庫(事件驅動庫)和libaco(協程庫)實現異步網絡服務器的示例:
#include < ev.h >
#include < aco.h >
#include < unistd.h >
#include < fcntl.h >
#include < arpa/inet.h >
static aco_t *main_co;
static ev_io accept_watcher;
void setnonblock(int fd) {
int flags = fcntl(fd, F_GETFL);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
void on_accept(EV_P_ ev_io *w, int revents) {
struct sockaddr_in addr;
socklen_t addrlen = sizeof(addr);
int fd = accept(w- >fd, (struct sockaddr *)&addr, &addrlen);
if (fd < 0) {
return;
}
setnonblock(fd);
// 創建一個新的協程來處理客戶端請求
aco_t *client_co = aco_create(main_co, NULL, 0, echo_client_handler, NULL);
aco_share_stack_t *ss = aco_get_ss_by_co(client_co);
aco_resume(client_co);
// ...其他代碼...
}
五、協程池
協程池是另一種實現異步操作的方法,它可以用于限制同時運行的協程數量。
協程池有助于提高系統資源的利用率,降低上下文切換的開銷,并實現負載均衡。
協程池的核心概念是重用協程,以提高資源利用率并降低創建和銷毀協程的開銷。協程池可以根據具體需求調整大小,從而實現對系統資源的動態管理。為了實現這一目標,協程池通常需要以下幾個關鍵組件:
一個協程隊列,用于存儲空閑協程。
一個互斥量(mutex),用于保護協程隊列,防止多個線程同時訪問隊列造成數據競爭。
一個條件變量(condition variable),用于協調生產者和消費者線程之間的同步。當協程池為空時,消費者線程將阻塞等待新的協程加入;當協程池滿時,生產者線程將阻塞等待協程被釋放。
創建和銷毀協程的方法,以便根據需求動態調整協程池大小。
以下是一個更為完善的協程池實現,包括了上述所述的各個組件:
- 一個協程隊列,用于存儲空閑協程。
- 一個互斥量(mutex),用于保護協程隊列,防止多個線程同時訪問隊列造成數據競爭。
- 一個條件變量(condition variable),用于協調生產者和消費者線程之間的同步。當協程池為空時,消費者線程將阻塞等待新的協程加入;當協程池滿時,生產者線程將阻塞等待協程被釋放。
- 創建和銷毀協程的方法,以便根據需求動態調整協程池大小。
下面是一個使用協程池的簡單示例:
#include < aco.h >
#include < vector >
// 定義一個協程池結構體
typedef struct co_pool {
std::vector< aco_t * > pool;
int max_size;
int current_size;
} co_pool;
// 初始化一個協程池
co_pool *init_co_pool(int max_size) {
co_pool *pool = new co_pool;
pool- >max_size = max_size;
pool- >current_size = 0;
return pool;
}
// 獲取一個空閑協程
aco_t *get_co_from_pool(co_pool *pool, aco_t *creator_co, void *arg) {
if (pool- >current_size < pool- >max_size) {
aco_t *co = aco_create(creator_co, NULL, 0, task_func, arg);
pool- >pool.push_back(co);
pool- >current_size++;
return co;
} else {
// ...處理協程池已滿的情況,如阻塞等待或者創建新的協程...
}
}
// 釋放已完成任務的協程
void release_co_to_pool(co_pool *pool, aco_t *co) {
// 在這里可以重置協程的狀態,并將其放回到協程池中以供后續使用
// 或者將其銷毀以釋放資源
}
// 銷毀協程池
void destroy_co_pool(co_pool *pool) {
// 銷毀協程池中的所有協程,并釋放相關資源
for (aco_t *co : pool- >pool) {
aco_destroy(co);
}
delete pool;
}
C++ 類封裝
在這個協程池實現中,我們使用了C++類來封裝協程池的相關操作,提高了代碼的可讀性和可維護性。協程池的主要方法包括get_coroutine()、release_coroutine()和析構函數。
#include < aco.h >
#include < vector >
#include < mutex >
#include < condition_variable >
#include < queue >
class CoroutinePool {
public:
CoroutinePool(int max_size, aco_t *main_co) : max_size_(max_size), main_co_(main_co), current_size_(0) {
}
aco_t *get_coroutine() {
std::unique_lock< std::mutex > lock(mutex_);
if (pool_.empty()) {
if (current_size_ < max_size_) {
aco_t *co = aco_create(main_co_, NULL, 0, task_func, NULL);
++current_size_;
return co;
} else {
cv_.wait(lock, [&](){ return !pool_.empty(); });
}
}
aco_t *co = pool_.front();
pool_.pop();
return co;
}
void release_coroutine(aco_t *co) {
std::unique_lock< std::mutex > lock(mutex_);
pool_.push(co);
cv_.notify_one();
}
~CoroutinePool() {
for (aco_t *co : pool_) {
aco_destroy(co);
}
}
private:
int max_size_;
aco_t *main_co_;
int current_size_;
std::queue< aco_t * > pool_;
std::mutex mutex_;
std::condition_variable cv_;
};
使用協程池處理并發任務的示例
#include < aco.h >
#include < vector >
#include < mutex >
#include < condition_variable >
#include < queue >
#include < thread >
// ...協程池相關函數定義...
void* task_func(void *arg) {
aco_t* this_co = aco_get_co();
// 執行任務
// ...
aco_yield(); // 任務完成后,讓出執行權
return NULL;
}
int main() {
aco_thread_init(NULL);
aco_t* main_co = aco_create(NULL, NULL, 0, NULL, NULL);
// 創建一個協程池
co_pool *pool = init_co_pool(5);
// 創建一個任務隊列
std::queue< void * > tasks;
std::mutex tasks_mutex;
std::condition_variable tasks_cv;
// 生產任務
std::thread task_producer([&](){
for (int i = 0; i < 20; ++i) {
std::unique_lock< std::mutex > lock(tasks_mutex);
tasks.push((void *)(intptr_t)i);
tasks_cv.notify_one();
lock.unlock();
}
});
// 使用協程池處理任務
while (true) {
std::unique_lock< std::mutex > lock(tasks_mutex);
tasks_cv.wait(lock, [&](){ return !tasks.empty(); });
void *task = tasks.front();
tasks.pop();
lock.unlock();
// 從協程池中獲取一個協程并分配任務
aco_t *co = get_co_from_pool(pool, main_co, task);
aco_resume(co);
// 釋放已完成任務的協程
release_co_to_pool(pool, co);
}
task_producer.join();
// 銷毀協程池
destroy_co_pool(pool);
aco_destroy(main_co);
return 0;
}
六、協程在實際項目中的應用場景
協程作為一種輕量級的并發解決方案,在許多實際項目中得到了廣泛應用。接下來,我們將探討協程在實際項目中的一些典型應用場景。
網絡編程
在網絡編程中,協程可以輕松地處理并發連接和請求。借助協程,我們可以編寫出簡潔、高效的網絡應用程序。以下是一些典型的應用場景:
- 并發任務處理
在網絡服務器中,往往需要處理大量并發的客戶端連接和請求。使用協程,我們可以為每個連接或請求創建一個協程,從而實現高效的并發處理。相較于線程和進程,協程具有更低的創建、切換和銷毀開銷,因此在處理大量并發任務時具有更好的性能。
- 生產者消費者模型
生產者消費者模型是一種常見的并發設計模式,在網絡編程中有廣泛的應用。使用協程,我們可以輕松實現生產者消費者模型。例如,一個協程可以作為生產者,將接收到的請求放入隊列中;另一個協程可以作為消費者,從隊列中取出請求并處理。通過協程間的通信和同步機制,如通道(channel)和信號量(semaphore),我們可以實現高效的生產者消費者模型。
- 異步I/O與事件驅動編程
協程與異步I/O和事件驅動編程相結合,可以實現高效的網絡應用程序。在這種模型中,協程在等待I/O操作完成時讓出執行權,從而提高整體程序的并發性能。我們可以利用I/O多路復用技術(如epoll、kqueue、IOCP等)來實現高效的事件驅動協程調度。
并行計算
在并行計算領域,協程也可以發揮重要作用。它們可以幫助我們更輕松地實現負載均衡、數據處理等任務,提高程序的并行性能。以下是一些典型的應用場景:
負載均衡
負載均衡是在并行計算中實現高效任務分配的關鍵技術。通過協程,我們可以實現動態的任務調度和負載均衡。例如,可以為每個計算任務創建一個協程,并根據任務的執行情況,動態地調整協程的優先級和資源分配,從而實現高效的負載均衡。
數據處理
協程可以幫助我們實現并行的數據處理任務。在大規模數據處理場景中,可以使用協程實現多個處理任務之間的并發執行,提高數據處理的吞吐量。例如,在數據流處理、數據挖掘、機器學習等領域,我們可以利用協程實現高效的數據并行計算。
嵌入式系統
協程在嵌入式系統中也有很多應用場景。嵌入式系統通常面臨資源受限和實時調度的挑戰。在這些場景下,協程可以為我們提供輕量級、高效的并發解決方案。
資源受限場景
在資源受限的嵌入式系統中,協程可以作為一種輕量級的并發解決方案。與線程和進程相比,協程具有更低的創建、切換和銷毀開銷,從而在資源受限的場景下提供更好的性能。
實時調度
嵌入式系統通常需要實時響應外部事件,如傳感器輸入、控制器操作等。協程可以幫助我們實現實時調度,從而滿足嵌入式系統的實時性要求。例如,在實時操作系統(RTOS)中,我們可以使用協程實現高效、靈活的任務調度,從而實現對外部事件的實時響應。
七、協程棧調優
協程棧大小對于協程的性能和內存占用具有重要影響。合理地調整協程棧大小,可以在保證性能的同時減少內存占用。以下是一些建議:
- 監測實際使用情況:在運行協程程序時,觀察協程棧的實際使用情況,以確定合適的棧大小。根據不同協程任務的特點,可以針對性地調整棧大小。
- 優化代碼結構:通過優化代碼結構,減少局部變量和遞歸深度,可以降低協程棧的大小需求。
- 合理選擇協程調度算法:根據任務需求和資源情況,選擇合適的協程調度算法,以實現公平、高效的協程調度。
- 利用I/O多路復用技術:在I/O密集型任務中,使用I/O多路復用技術(如epoll、kqueue、IOCP等)來實現高效的事件驅動協程調度。
- 控制協程并發數量:過多的協程可能會導致系統資源過載。在實際項目中,可以通過協程池、信號量等手段來控制協程的并發數量。
- 利用協程局部性:在設計協程任務時,盡量將相關的邏輯和數據保持在同一個協程中,從而提高任務執行效率和減少協程間的通信開銷。
- 適當優化協程棧大小:協程的棧大小可以影響協程的創建和切換性能。通過實驗找到合適的棧大小,以在保證性能的同時減少內存占用。
- 利用協程鎖和信號量進行同步:在協程間共享資源時,可以使用協程鎖和信號量來實現同步,以避免競爭條件和提高程序的穩定性。
- 優化數據傳輸和通信:在協程間傳遞數據時,使用高效的數據結構和通信機制,如通道(channel),可以減少數據傳輸的開銷并提高程序性能。
- 利用協程友好的異步庫:在實際項目中,可以選擇與協程兼容的異步庫(如C-ares、libcurl等),以充分發揮協程在異步I/O場景下的優勢。
- 監控協程性能指標:在運行協程程序時,持續監控性能指標(如協程數量、響應時間、內存占用等),以便及時發現性能瓶頸并進行優化。
協程調度策略優化
協程調度策略對于協程程序的性能具有重要影響。優化協程調度策略,可以提高程序的并發性能和響應性。以下是一些建議:
選擇合適的調度算法:根據協程任務的特點和程序需求,選擇合適的協程調度算法,如Round-Robin、優先級調度等。
利用I/O多路復用技術:在I/O密集型任務中,使用I/O多路復用技術(如epoll、kqueue、IOCP等)實現高效的事件驅動協程調度。
動態調整協程優先級:根據協程任務的實際執行情況,動態調整協程的優先級,以實現更公平、高效的協程調度。
協程與線程池的結合
協程和線程池可以結合使用,充分發揮各自的優勢,提高程序的并發性能和資源利用率。以下是一些建議:
使用線程池處理計算密集型任務:在線程池中處理計算密集型任務,可以有效地利用多核處理器資源,提高計算性能。
使用協程處理I/O密集型任務:在協程中處理I/O密集型任務,可以實現高效的異步I/O操作和事件驅動編程。
在線程池中使用協程:在每個線程中運行多個協程,可以實現更高效的任務調度和資源利用。
避免協程調度的瓶頸
協程調度的瓶頸可能會影響程序的并發性能。避免協程調度的瓶頸,可以提高程序的響應性和吞吐量。
以下是一些建議:
- 平衡協程數量:創建過多的協程可能會導致調度開銷增大,從而影響程序性能。根據系統資源和任務需求,合理地平衡協程數量,以避免調度瓶頸。
- 減少協程間同步:過多的協程間同步操作可能導致調度瓶頸。盡量減少協程間的同步操作,或者使用高效的同步機制,如協程鎖、信號量、通道等。
- 優化協程調度器:優化協程調度器的實現,如減少鎖競爭、使用高效的數據結構等,以降低調度開銷。
- 避免協程饑餓:確保協程任務得到及時調度,避免某些協程長時間等待調度而導致的饑餓現象。根據任務的優先級和實際需求,合理地調整協程調度策略。
- 利用協程池:使用協程池可以有效地減少協程的創建和銷毀開銷,降低調度瓶頸。同時,協程池可以方便地管理協程資源,提高程序的穩定性。
- 減少上下文切換開銷:上下文切換是協程調度過程中的一個關鍵開銷。為減少上下文切換的開銷,可以盡量避免不必要的協程切換,或者使用更高效的上下文切換機制(如swapcontext等)。此外,在實現協程庫時,可以考慮優化上下文切換的底層實現,以降低性能損耗。
- 利用CPU緩存友好的數據結構:協程調度過程中的數據結構對程序性能具有重要影響。使用CPU緩存友好的數據結構(如無鎖隊列、數組等),可以提高協程調度的性能。在設計協程調度器時,可以考慮使用高效的數據結構來管理協程任務隊列、事件隊列等。
- 協程任務劃分:合理地劃分協程任務,可以降低協程調度的復雜性和開銷。在設計協程任務時,可以根據任務的性質和資源需求進行劃分,以降低任務之間的依賴關系和同步開銷。例如,可以將計算密集型和I/O密集型任務分別放在不同的協程中執行。
- 動態協程優先級調整:通過動態調整協程的優先級,可以更靈活地調度協程任務,提高程序的響應性。例如,可以根據任務的實時需求和資源狀況,為關鍵任務分配更高的優先級,以確保其得到及時處理。
- 線程和協程的協同調度:合理地將線程和協程結合使用,可以進一步提高程序的并發性能。例如,在計算密集型任務中,可以利用線程池實現多核并行計算;而在I/O密集型任務中,可以使用協程實現高效的異步I/O操作和事件驅動編程。在這種情況下,可以嘗試實現線程和協程的協同調度策略,以實現更高效的資源利用和任務調度。
綜上所述,在實際應用中,通過優化協程棧大小、調度策略、協程與線程池的結合以及避免協程調度瓶頸等方面,我們可以充分發揮協程在并發編程中的優勢,實現高性能、易于維護的程序。在實際項目中,可以根據需求和資源限制靈活地使用協程,以滿足各種場景的需求。
八、調試協程
在實際項目中,調試協程代碼是至關重要的。本文將介紹如何調試協程,包括堆棧跟蹤、調試工具與技巧以及如何處理協程中的異常。
協程堆棧跟蹤
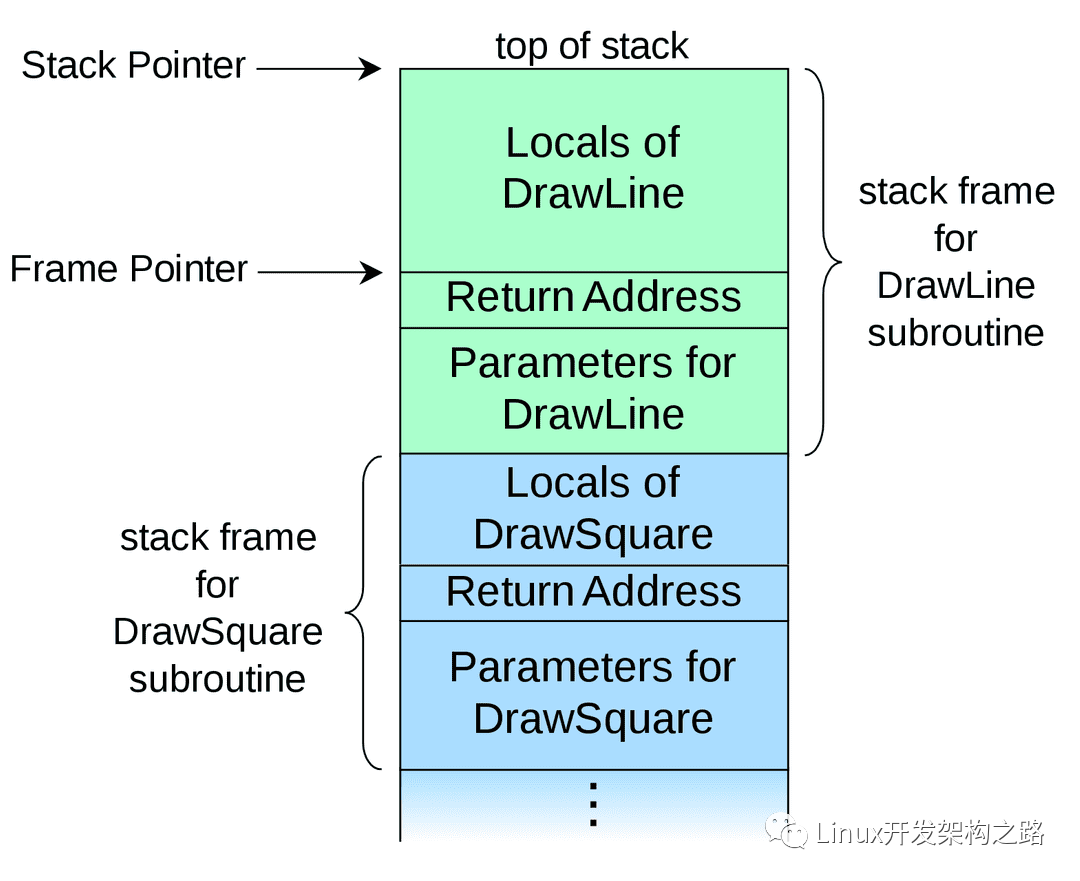
協程堆棧跟蹤是分析和調試協程程序的基本技術。在調試協程時,我們需要關注當前協程的狀態、堆棧幀以及局部變量等信息。以下是一些建議:
使用協程庫提供的調試接口:很多協程庫提供了獲取協程堆棧信息的接口。使用這些接口,可以幫助我們了解當前協程的狀態和堆棧情況,從而定位問題所在。
保存協程上下文:在協程切換時,保存完整的協程上下文信息,包括寄存器值、堆棧幀等,有助于我們分析和調試協程程序。
分析調用棧:通過分析協程的調用棧,可以找出潛在的問題,如協程阻塞、死鎖等。
調試工具與技巧
調試協程程序時,可以使用一些調試工具和技巧來提高調試效率。以下是一些建議:
使用GDB等調試器:GDB等調試器可以幫助我們查看協程的狀態、局部變量、寄存器值等信息。通過設置斷點和單步調試,我們可以更加深入地了解協程的執行過程。
使用日志和斷言:在協程代碼中添加日志和斷言,可以幫助我們定位問題。日志可以記錄協程的執行過程,而斷言可以檢測程序中的潛在錯誤。
代碼審查和測試:通過代碼審查和測試,可以提前發現協程程序中的問題,從而減少調試的難度。
如何處理協程中的異常
在協程程序中,異常處理也是一個重要的環節。以下是一些建議:
捕獲協程內部的異常:在協程函數中,使用try-catch語句捕獲潛在的異常,防止異常導致程序崩潰。對于C++中的異常,可以使用try和catch語句來捕獲異常;對于C語言中的異常,可以使用setjmp和longjmp等方法實現異常捕獲和處理。
返回錯誤代碼:在協程函數中,可以使用錯誤代碼表示異常情況,從而將異常信息傳遞給調用者。
使用全局異常處理機制:通過設置全局異常處理器,可以用于捕獲異常.
使用協程調試庫
除了使用通用的調試工具和技巧外,還可以考慮使用專門針對協程設計的調試庫。這些庫通常提供了一些針對協程特性的調試功能,如協程堆棧檢查、協程調度日志等。例如,有一些開源的協程調試庫,如 libgo 的 libgo-dbg 等,可以輔助我們更輕松地定位協程相關問題。
可視化調試工具
在調試協程時,可以考慮使用可視化調試工具,如 IDE(集成開發環境)中的調試器。這些工具通常提供了直觀的界面,方便我們查看協程狀態、調用棧以及變量值等信息。另外,一些可視化調試工具還提供了針對協程的特殊功能,如協程并發可視化、協程狀態跟蹤等,可以幫助我們更有效地定位協程問題。
性能剖析
在調試協程程序時,可能會遇到性能問題。為了找出性能瓶頸,可以使用性能剖析工具(如 gperftools、Valgrind 等)來分析協程程序的性能。這些工具可以幫助我們了解程序在執行過程中的資源消耗情況,如 CPU 使用率、內存占用等。通過性能剖析,我們可以找出協程程序中的性能瓶頸,從而進行針對性的優化。
協程泄露檢測
協程泄露是協程程序中的一種常見問題。當協程沒有正確地釋放資源(如內存、文件描述符等)時,可能導致資源泄露。為了檢測協程泄露,可以使用內存泄露檢測工具(如 Valgrind、LeakSanitizer 等),并結合協程庫提供的資源跟蹤功能。通過這些工具,我們可以定位泄露的協程,從而解決資源泄露問題。
總之,在調試協程時,可以結合多種工具和技巧來提高調試效率。這包括使用協程庫提供的調試接口、通用調試器、專門針對協程的調試庫、可視化調試工具、性能剖析工具以及泄露檢測工具等。同時,通過捕獲和處理協程中的異常,我們可以確保協程程序的穩定性和健壯性。
九、協程安全問題
在并發編程中,協程安全問題是一個重要的議題。協程間數據競爭和死鎖是需要特別關注的問題。以下內容將討論如何避免這些安全問題。
數據競爭
數據競爭發生在兩個或多個協程同時訪問共享數據時。為了避免數據競爭,可以使用協程鎖、信號量等同步原語,確保同一時刻只有一個協程訪問共享資源。
死鎖
死鎖是指兩個或多個協程互相等待彼此持有的資源,導致無法繼續執行。避免死鎖的方法包括:
- 設計合理的資源請求順序,遵循一定的協程訪問順序。
- 使用超時機制,當資源請求超過指定時間時,釋放已持有的資源。
協程與異常處理
協程中的異常處理和傳統同步編程類似。使用C++的異常處理機制(try-catch-finally),可以捕獲并處理協程中發生的異常。在協程函數中,處理異常的關鍵步驟如下:
- 使用try-catch語句捕獲異常。
- 在catch語句中處理異常,并在適當的情況下重新拋出異常。
- 使用finally語句確保資源的釋放和清理工作得到執行。
協程資源管理
在協程編程中,資源管理是另一個重要的議題。這里討論如何在協程中安全地管理資源:
- 在協程函數中使用RAII(Resource Acquisition Is Initialization)原則,確保資源在初始化時自動分配并在析構時自動釋放。
- 使用智能指針(如std::shared_ptr、std::unique_ptr)管理動態分配的內存資源。
- 避免全局變量和靜態變量,使用局部變量和傳遞參數的方式共享數據。
協程編程風格和編碼規范
為了保持代碼的可讀性和可維護性,以下是一些關于協程編程風格和編碼規范的建議:
- 使用有意義的命名約定,如協程函數名、變量名等。
- 使用注釋來說明代碼的功能和設計理念。
- 遵循代碼的模塊化和封裝原則,將功能模塊化,通過接口進行交互。
- 協程函數中避免使用過長的代碼,將復雜任務拆分成多個協程函數。
- 在代碼中使用錯誤處理和異常處理,確保程序的穩定性。
協程調度策略
協程的調度策略對于程序的性能和響應性有很大影響。合理的調度策略可以減少上下文切換開銷,提高資源利用率。以下是一些建議:
- 基于優先級的調度:為協程設置優先級,根據優先級進行調度。優先級高的協程先執行,優先級相同的協程使用先進先出(FIFO)策略執行。
- 協作式調度:協程主動讓出執行權,例如在等待資源或I/O操作時。這種策略可以減少不必要的上下文切換,提高程序的響應性。
協程異常傳遞
在協程編程中,有時需要將異常從一個協程傳遞到另一個協程。以下是實現異常傳遞的一些建議:
- 使用通道(Channel)或其他通信機制傳遞異常信息。
- 在協程之間建立父子關系,子協程在發生異常時通知父協程。
協程組織結構
合理地組織協程結構可以提高代碼的可讀性和可維護性。以下是關于協程組織結構的一些建議:
- 使用協程層級結構,將相似功能的協程組織在一起。
- 使用協程池對協程進行管理,根據任務需求動態創建和銷毀協程。
協程與其他并發模型的對比
在實際項目中,除了協程之外,還有其他并發編程模型,如多線程和多進程。
以下是對比這些并發模型的一些建議:
- 根據任務類型選擇合適的并發模型。例如,對于計算密集型任務,使用多線程或多進程可能更適合。而對于I/O密集型任務,協程能提供更高的性能。
- 混合使用不同的并發模型。例如,在協程中使用線程池,結合協程的輕量級特性和線程的并發能力。
十、協程的狀態
協程在執行過程中會經歷不同的狀態。以下是常見的協程狀態:
- 初始狀態:協程創建后尚未執行的狀態。
- 運行狀態:協程正在執行的狀態。
- 掛起狀態:協程暫停執行,等待某個條件(如I/O完成或信號量)恢復執行的狀態。
- 結束狀態:協程執行完成并退出的狀態。
協程的創建與銷毀
創建協程的過程通常包括以下步驟:
- 分配協程控制塊和棧空間。
- 初始化協程控制塊,設置協程狀態、協程函數及其參數。
- 將協程加入調度器等待執行。
銷毀協程的過程包括:
- 從調度器中移除協程。
- 釋放協程占用的資源,如棧空間。
- 刪除協程控制塊。
協程的調度與切換
協程的調度是指在多個協程之間進行上下文切換。協程調度器負責管理協程的調度。以下是協程調度的關鍵步驟:
- 選擇下一個要執行的協程。
- 保存當前協程的上下文(如寄存器、棧指針等)。
- 恢復下一個協程的上下文。
- 切換到下一個協程并執行。
- 協程的切換通常涉及到底層匯編指令,用于保存和恢復寄存器、棧指針等CPU狀態。
協程棧管理
協程棧是用于保存協程局部變量、函數調用參數和返回地址等信息的內存區域。協程棧管理主要包括:
- 分配和釋放協程棧空間。
- 在協程切換時保存和恢復棧指針。
- 在協程結束時清理棧空間。
- 協程棧空間的大小通常是有限的,因此需要注意避免棧溢出。有些協程庫支持棧大小的動態調整,以提高內存利用率。
協程庫實例解析
以下是幾個常見的C/C++協程庫:
libco:騰訊開源的一個輕量級協程庫,支持Linux和macOS平臺。提供了協程創建、切換、銷毀等基本功能。
libmill:一個簡單的C協程庫,支持結構化并發。提供了協程創建、切換、通道等高級功能。
boost::asio::spawn:Boost.Asio庫提供的一個協程功能,使用C++11特性,使得異步編程更簡潔易懂。Boost.Asio協程與異步I/O操作緊密結合,實現高性能的網絡編程。
十一、協程庫實例解析
本節將詳細介紹libco協程庫的使用方法和實現原理。
libco簡介
libco是騰訊開源的一個輕量級協程庫,支持Linux和macOS平臺。它主要使用匯編進行協程上下文切換,以提高性能。libco 提供了協程創建、切換、銷毀等基本功能,使用簡單。
libco的使用方法
1、下載并編譯libco:
git clone https://github.com/Tencent/libco.git
cd libco
make
2、創建一個簡單的協程示例:
#include < stdio.h >
#include "co_routine.h"
void *routine_func(void *arg) {
printf("Start coroutine.n");
co_yield_ct(); // 讓出執行權
printf("Resume coroutine.n");
return NULL;
}
int main() {
stCoRoutine_t *co = NULL;
co_create(&co, NULL, routine_func, NULL); // 創建協程
co_resume(co); // 啟動協程
co_resume(co); // 再次恢復協程
co_release(co); // 銷毀協程
return 0;
}
3、編譯并運行示例程序:
g++ example.cpp -o example -I/path/to/libco/include -L/path/to/libco/lib -lcolib -lpthread
./example
libco的實現原理
libco的實現原理主要分為以下幾個方面:
- 協程控制塊:libco使用stCoRoutine_t結構體作為協程控制塊,保存協程的狀態、棧指針、上下文等信息。
- 協程創建:co_create函數用于創建協程,包括分配協程控制塊、棧空間,并初始化協程狀態。
- 協程切換:libco提供了co_resume和co_yield_ct兩個函數進行協程切換。co_resume用于恢復指定協程的執行,co_yield_ct用于掛起當前協程。協程切換的過程中,會保存和恢復協程的上下文。
- 協程銷毀:co_release函數用于銷毀協程,釋放協程控制塊和棧空間。
- 協程調度器:libco提供了一個默認的協程調度器,管理所有協程的創建、調度和銷毀。用戶也可以創建自定義的調度器實例,以實現更細粒度的協程管理。
通過了解libco的使用方法和實現原理,我們可以更好地應用協程技術,提高程序的并發性能。
libaco簡介
libaco是一個高性能、輕量級的C語言協程庫。它使用C11特性實現,并提供了用于協程管理的aco調度器。libaco支持跨平臺,可以在多種操作系統上運行。此外,它提供了協程共享棧和私有棧的切換功能,以節省內存空間。
libaco的使用方法
1、下載并編譯libaco:
git clone https://github.com/hnes/libaco.git
cd libaco
make
2、創建一個簡單的協程示例:
#include < stdio.h >
#include "aco.h"
void routine_func(void *arg) {
printf("Start coroutine.n");
aco_yield(); // 讓出執行權
printf("Resume coroutine.n");
}
int main() {
aco_thread_init(NULL); // 初始化協程線程環境
aco_t *main_co = aco_create(NULL, NULL, 0, NULL, NULL); // 創建主協程
aco_t *co = aco_create(main_co, NULL, 0, routine_func, NULL); // 創建子協程
aco_resume(co); // 啟動子協程
aco_resume(co); // 再次恢復子協程
aco_destroy(co); // 銷毀子協程
aco_destroy(main_co); // 銷毀主協程
return 0;
}
3、編譯并運行示例程序:
gcc example.c -o example -I/path/to/libaco/include -L/path/to/libaco/lib -laco -lpthread
./example
libaco的實現原理
libaco的實現原理主要分為以下幾個方面:
- 協程控制塊:libaco使用aco_t結構體作為協程控制塊,保存協程的狀態、棧指針、上下文等信息。
- 協程創建:aco_create函數用于創建協程,包括分配協程控制塊、棧空間,并初始化協程狀態。同時,需要創建一個主協程用于管理子協程。
- 協程切換:libaco提供了aco_resume和aco_yield兩個函數進行協程切換。aco_resume用于恢復指定協程的執行,aco_yield用于掛起當前協程。協程切換的過程中,會保存和恢復協程的上下文。
- 協程銷毀:aco_destroy函數用于銷毀協程,釋放協程控制塊和棧空間。
- 協程調度器:libaco提供了一個內置的協程調度器,可以幫助用戶在程序中方便地使用協程。協程調度器是libaco庫的核心,它負責協程的創建、調度和銷毀。使用一個基于事件循環的模型來實現協程的調度。它會不斷地從就緒隊列中獲取協程,并將其執行,直到協程被掛起或者執行完畢。當一個協程被掛起時,調度器會將其保存到掛起隊列中,等待下一次調度。
Boost.Coroutine2簡介
Boost.Coroutine2是Boost庫中提供的一個C++協程庫。它采用C++11標準,使得C++程序員能夠輕松地使用協程,而無需了解底層的實現細節。Boost.Coroutine2提供了高級的協程抽象,支持異常安全和資源管理,可以在各種平臺上運行。
Boost.Coroutine2的使用方法
1、安裝Boost庫,詳情請查看Boost官方文檔。
2、創建一個簡單的協程示例:
#include < iostream >
#include
using namespace boost::coroutines2;
void routine_func(coroutine< void >::push_type &sink) {
std::cout < < "Start coroutine." < < std::endl;
sink(); // 讓出執行權
std::cout < < "Resume coroutine." < < std::endl;
}
int main() {
coroutine< void >::pull_type co(routine_func); // 創建協程
co(); // 啟動協程
co(); // 再次恢復協程
return 0;
}
3、編譯并運行示例程序
g++ example.cpp -o example -std=c++11 -lboost_context -lboost_system -lboost_coroutine
./example
Boost.Coroutine2的實現原理
Boost.Coroutine2的實現原理主要分為以下幾個方面:
- 協程控制塊:Boost.Coroutine2使用coroutine類模板作為協程控制塊,保存協程的狀態、棧指針、上下文等信息。
- 協程創建:通過coroutine類模板實例化協程對象,傳入協程函數,以創建協程。同時,協程對象會分配棧空間并初始化協程狀態。
- 協程切換:Boost.Coroutine2提供了operator()運算符用于恢復協程,而協程函數內部可以使用sink()或yield()函數讓出執行權。協程切換過程中,會保存和恢復協程的上下文。
- 協程銷毀:在協程函數執行完畢或協程對象離開作用域時,Boost.Coroutine2會自動銷毀協程并釋放資源。
通過了解Boost.Coroutine2的使用方法和實現原理,我們可以更好地應用協程技術,提高程序的并發性能。
協程庫對比與建議
對比上述三個協程庫(libco、libaco、Boost.Coroutine2)的優缺點和使用場景
libco
優點
- 騰訊開源,有大量實際應用驗證。
- 使用匯編進行協程上下文切換,性能較高。
- 輕量級,適用于需要低開銷的場景。
缺點
- 主要支持Linux和macOS平臺,不適用于跨平臺應用。
- 接口相對簡單,可能不夠靈活。
- 使用場景
適用于Linux/macOS平臺上的高性能服務端程序,如網絡編程、并行計算等。
libaco
優點
- 跨平臺,支持多種操作系統。
- 提供協程共享棧和私有棧的切換功能,節省內存空間。
- C11特性,易于在C語言項目中集成。
缺點
- 接口相對簡單,可能不夠靈活。
- 使用場景
- 適用于跨平臺的C語言項目,如嵌入式系統、網絡編程等。
Boost.Coroutine2
優點
- 使用C++11標準,易于在C++項目中集成。
- 提供高級協程抽象,支持異常安全和資源管理。
- 跨平臺,支持多種操作系統。
缺點
- 相對較重,依賴Boost庫。
- 使用場景
- 適用于跨平臺的C++項目,如桌面應用、網絡編程等。
選擇和使用建議
- 如果項目是在Linux/macOS平臺上運行的高性能服務端程序,建議選擇libco。
- 如果項目是跨平臺的C語言項目,尤其是內存有限的場景,建議選擇libaco。
- 如果項目是跨平臺的C++項目,希望使用高級協程抽象,建議選擇Boost.Coroutine2。
在選擇協程庫時,請充分考慮項目需求、平臺兼容性以及庫本身的特點。同時,遵循協程編程規范以確保程序的穩定性和可維護性。
十二、實戰案例分析
協程實現的HTTP服務器
在這個示例中,我們將使用libco協程庫實現一個簡單的HTTP服務器。
#include < arpa/inet.h >
#include < co_routine.h >
#include < errno.h >
#include < fcntl.h >
#include < netinet/in.h >
#include < stdio.h >
#include < string.h >
#include < sys/socket.h >
#include < unistd.h >
// 定義處理HTTP請求的協程函數
void* handle_http_request(void* args) {
int fd = *(int*)args;
char request[2048];
char response[] = "HTTP/1.1 200 OKrnContent-Type: text/htmlrnrnHello, Coroutine!";
read(fd, request, sizeof(request) - 1);
write(fd, response, sizeof(response) - 1);
close(fd);
return NULL;
}
int main() {
int listenfd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_addr.s_addr = htonl(INADDR_ANY);
serv_addr.sin_port = htons(8080);
bind(listenfd, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
listen(listenfd, 128);
while (1) {
struct sockaddr_in cli_addr;
socklen_t cli_addr_len = sizeof(cli_addr);
int connfd = accept(listenfd, (struct sockaddr*)&cli_addr, &cli_addr_len);
// 為每個HTTP請求創建協程
stCoRoutine_t* co = NULL;
co_create(&co, NULL, handle_http_request, &connfd);
co_resume(co);
}
return 0;
}
協程實現的生產者消費者模型
在這個示例中,我們將使用libaco協程庫實現一個簡單的生產者消費者模型。
#include < aco.h >
#include < stdio.h >
#include < unistd.h >
aco_share_stack_t* sstk;
aco_t* main_co;
aco_t* producer_co;
aco_t* consumer_co;
void producer(void) {
for (int i = 0; i < 5; i++) {
printf("Producer: %dn", i);
aco_yield();
}
}
void consumer(void) {
for (int i = 0; i < 5; i++) {
aco_yield();
printf("Consumer: %dn", i);
}
}
int main() {
aco_thread_init(NULL);
main_co = aco_create(NULL, NULL, 0, NULL, NULL);
sstk = aco_share_stack_new(0);
producer_co = aco_create(main_co, sstk, 0, producer, NULL);
consumer_co = aco_create(main_co, sstk, 0, consumer, NULL);
while (1) {
aco_resume(producer_co);
aco_resume(consumer_co);
}
return 0;
}
使用協程優化現有同步代碼
在這個示例中,我們將使用Boost.Coroutine2協程庫優化現有的同步代碼。
#include
#include < chrono >
#include < iostream >
#include < thread >
using namespace std;
using namespace boost::coroutines2;
typedef coroutine< void >::pull_type pull_coro_t;
typedef coroutine< void >::push_type push_coro_t;
void long_running_task(push_coro_t& yield) {
for (int i = 0; i < 5; ++i) {
cout < < "Running task: " < < i < < endl;
this_thread::sleep_for(chrono::seconds(1));
yield();
}
}
void optimized_sync_code(pull_coro_t& task) {
while (task) {
task();
// 在此處處理其他任務或執行其他邏輯
}
}
int main() {
pull_coro_t long_task(long_running_task);
optimized_sync_code(long_task);
return 0;
}
在這個例子中,我們使用Boost.Coroutine2實現了一個長時間運行任務的協程。通過在optimized_sync_code函數中周期性地恢復協程,我們可以有效地在等待長時間運行任務的間隙執行其他任務或邏輯,從而優化了同步代碼的執行效率。
epoll服務器協程示例
此示例中省略了實際處理文件描述符的邏輯。如接受新的TCP連接、讀取UDP數據報文、處理標準輸入、讀取管道、處理消息隊列和處理ZeroMQ套接字等。在實現處理邏輯時,請使用協程庫中提供的協程化.
#include < arpa/inet.h >
#include < co_routine.h >
#include < errno.h >
#include < fcntl.h >
#include < netinet/in.h >
#include < signal.h >
#include < stdio.h >
#include < stdlib.h >
#include < string.h >
#include < sys/epoll.h >
#include < sys/socket.h >
#include < unistd.h >
#include < zmq.h >
#define MAX_EVENTS 10
// 以下函數均為處理各類文件描述符的協程函數
void* handle_tcp(void* args);
void* handle_udp(void* args);
void* handle_stdin(void* args);
void* handle_pipe(void* args);
void* handle_msg_queue(void* args);
void* handle_zmq(void* args);
int main() {
// 初始化epoll和各類文件描述符
int epollfd = epoll_create1(0);
if (epollfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
struct epoll_event ev, events[MAX_EVENTS];
int tcpfd = create_tcp_fd();
int udpfd = create_udp_fd();
int stdinfd = fileno(stdin);
int pipefd[2];
pipe(pipefd);
int msg_queue_fd = create_msg_queue_fd();
int zmqfd = create_zmq_fd();
// 添加文件描述符到epoll實例
add_fd_to_epoll(epollfd, tcpfd, EPOLLIN | EPOLLET);
add_fd_to_epoll(epollfd, udpfd, EPOLLIN | EPOLLET);
add_fd_to_epoll(epollfd, stdinfd, EPOLLIN | EPOLLET);
add_fd_to_epoll(epollfd, pipefd[0], EPOLLIN | EPOLLET);
add_fd_to_epoll(epollfd, msg_queue_fd, EPOLLIN | EPOLLET);
add_fd_to_epoll(epollfd, zmqfd, EPOLLIN | EPOLLET);
// 創建處理各類文件描述符的協程
stCoRoutine_t* tcp_co;
stCoRoutine_t* udp_co;
stCoRoutine_t* stdin_co;
stCoRoutine_t* pipe_co;
stCoRoutine_t* msg_queue_co;
stCoRoutine_t* zmq_co;
co_create(&tcp_co, NULL, handle_tcp, &tcpfd);
co_create(&udp_co, NULL, handle_udp, &udpfd);
co_create(&stdin_co, NULL, handle_stdin, &stdinfd);
co_create(&pipe_co, NULL, handle_pipe, &pipefd[0]);
co_create(&msg_queue_co, NULL, handle_msg_queue, &msg_queue_fd);
co_create(&zmq_co, NULL, handle_zmq, &zmqfd);
// 事件循環
while (1) {
int nfds = epoll_wait(epollfd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
for (int i = 0; i < nfds; i++) {
if (events[i].data.fd == tcpfd) {
co_resume(tcp_co);
} else if (events[i].data.fd == udpfd) {
co_resume(udp_co);
} else if (events[i].data.fd == stdinfd) {
co_resume(stdin_co);
} else if (events[i].data.fd == pipefd[0]) {
co_resume(pipe_co);
} else if (events[i].data.fd == msg_queue_fd) {
co_resume(msg_queue_co);
} else if (events[i].data.fd == zmqfd) {
co_resume(zmq_co);
}
}
}
// 清理資源
co_release(tcp_co);
co_release(udp_co);
co_release(stdin_co);
co_release(pipe_co);
co_release(msg_queue_co);
co_release(zmq_co);
close(tcpfd);
close(udpfd);
close(pipefd[0]);
close(pipefd[1]);
close(msg_queue_fd);
close(zmqfd);
return 0;
}
// 以下為處理各類文件描述符的協程函數實現
// 在此只提供了簡化版代碼,請根據實際需求實現詳細功能
void* handle_tcp(void* args) {
int tcpfd = (int)args;
// TODO: 實現處理TCP連接的邏輯
return NULL;
}
void* handle_udp(void* args) {
int udpfd = (int)args;
// TODO: 實現處理UDP連接的邏輯
return NULL;
}
void* handle_stdin(void* args) {
int stdinfd = (int)args;
// TODO: 實現處理標準輸入的邏輯
return NULL;
}
void* handle_pipe(void* args) {
int pipefd = (int)args;
// TODO: 實現處理管道的邏輯
return NULL;
}
void* handle_msg_queue(void* args) {
int msg_queue_fd = (int)args;
// TODO: 實現處理消息隊列的邏輯
return NULL;
}
void* handle_zmq(void* args) {
int zmqfd = (int)args;
// TODO: 實現處理ZeroMQ的邏輯
return NULL;
}
// 以下為輔助函數,創建文件描述符并添加到epoll實例中
int create_tcp_fd() {
// TODO: 創建TCP套接字并返回文件描述符
}
int create_udp_fd() {
// TODO: 創建UDP套接字并返回文件描述符
}
int create_msg_queue_fd() {
// TODO: 創建消息隊列并返回文件描述符
}
int create_zmq_fd() {
// TODO: 創建ZeroMQ套接字并返回文件描述符
}
void add_fd_to_epoll(int epollfd, int fd, uint32_t events) {
struct epoll_event ev;
ev.events = events;
ev.data.fd = fd;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &ev) == -1) {
perror("epoll_ctl");
exit(EXIT_FAILURE);
}
}
十三、結語
在本博客中,我們詳細介紹了C/C++協程編程的相關概念和技巧。首先,我們解釋了協程的定義、背景以及協程與線程、進程的區別。然后,我們探討了協程的優勢與局限性,并通過實例展示了C/C++協程編程的基本概念和操作。
在協程實踐部分,我們深入討論了創建和使用協程、協程切換與恢復、協程的結束和清理等方面。此外,我們還介紹了同步和異步協程操作,包括協程鎖、信號量和事件驅動編程。
我們也討論了協程池的實現和應用,以及協程在實際項目中的應用場景,如網絡編程、并行計算和嵌入式系統等。為了提高協程性能,我們探討了協程棧調優,如調度策略優化、協程與線程池的結合等。
在博客后半部分,我們詳細介紹了協程的調試技巧,包括協程堆棧跟蹤、調試工具與技巧、異常處理和性能剖析等。最后,我們深入分析了libco、libaco和Boost.Coroutine2三個協程庫,討論了它們的優缺點、使用場景和選擇建議。
總之,本博客旨在幫助讀者輕松掌握C/C++協程編程的技巧,以便在實際項目中應用協程來提高程序的并發性能。希望讀者在了解這些概念和技巧后,能夠在適當的場景下選擇和使用合適的協程庫,并遵循協程編程規范,確保程序的穩定性和可維護性。
-
寄存器
+關注
關注
31文章
5363瀏覽量
120952 -
編程
+關注
關注
88文章
3637瀏覽量
93911 -
函數
+關注
關注
3文章
4345瀏覽量
62882 -
C/C++
+關注
關注
1文章
57瀏覽量
4638
發布評論請先 登錄
相關推薦
如何選擇C/C++開發方向
運用Visual C++ 5.0或6.0的高級編程技巧,內容涉及MFC程序設計的最新概念

如何進行高質量的C、C++編程?高質量C++、C編程指南詳細資料免費下載

C++ coroutine generator實現筆記
C與C++混合編程是什么
C++20無棧協程超輕量高性能異步庫開發實戰
何選擇一個合適的協程來獲得CPU執行權





 工商網監
工商網監
評論