 重新審視Transformer:倒置更有效,真實世界預測的新SOTA出現了
重新審視Transformer:倒置更有效,真實世界預測的新SOTA出現了
考慮到基于 Transformer 的預測器的爭議,研究者們正在思考為什么 Transformer 在時間序列預測中的表現甚至不如線性模型,而在許多其他領域卻發揮著主導作用。
近日,來自清華大學的一篇新論文提出了一個不同的視角 ——Transformer 的性能不是固有的,而是由于將架構不當地應用于時間序列數據造成的。

論文地址:https://arxiv.org/pdf/2310.06625.pdf
基于 Transformer 的預測器的現有結構可能并不適合多變量時間序列預測。如圖 2 左側所示,同一時間步長的點基本上代表了完全不同的物理意義,但測量結果卻不一致,這些點被嵌入到一個 token 中,多變量相關性被抹去。而且,在現實世界中,由于多變量時間點的局部感受野和時間戳不對齊,單個時間步形成的標記很難揭示有益信息。此外,雖然序列變化會受到序列順序的極大影響,但在時間維度上卻沒有適當地采用變體注意力機制。因此,Transformer 在捕捉基本序列表征和描繪多元相關性方面的能力被削弱,限制了其在不同時間序列數據上的能力和泛化能力。
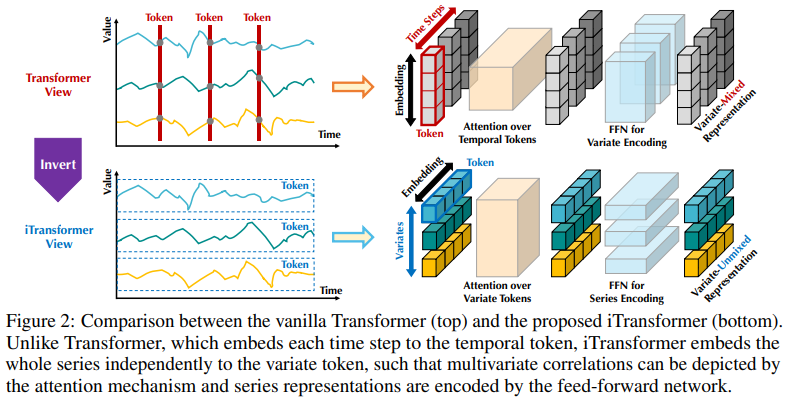
關于將每個時間步的多變量點嵌入一個(時間)token 的不合理性,研究者從時間序列的反向視角出發,將每個變量的整個時間序列獨立嵌入一個(變量)token,這是擴大局部感受野的 patching 的極端情況。通過倒置,嵌入的 token 聚集了序列的全局表征,可以更加以變量為中心,更好地利用注意力機制進行多變量關聯。同時,前饋網絡可以熟練地學習任意回溯序列編碼的不同變量的泛化表征,并解碼以預測未來序列。
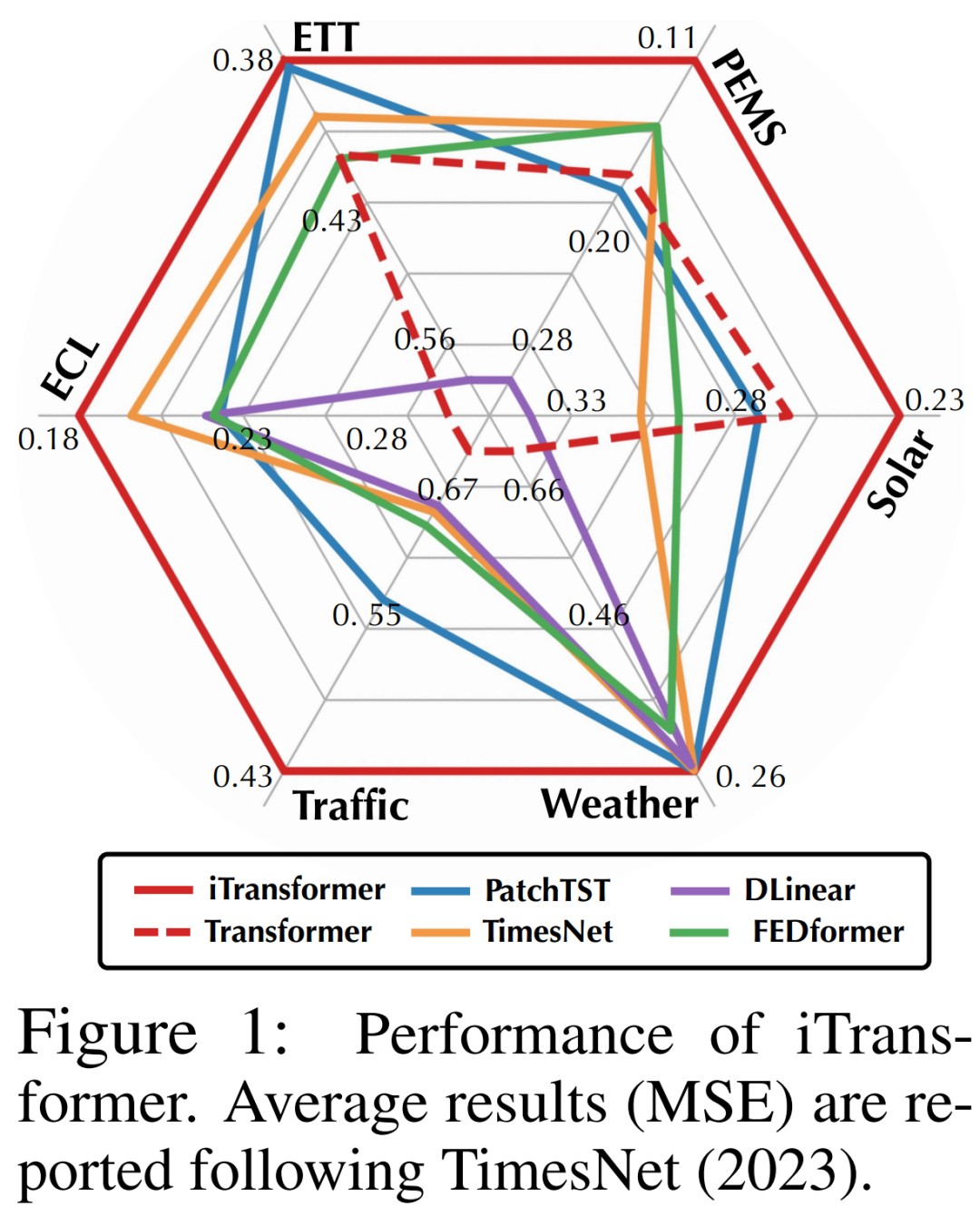
研究者認為 Transformer 對時間序列預測并非無效,而是使用不當。在文中,研究者重新審視了 Transformer 的結構,并提倡將 iTransformer 作為時間序列預測的基本支柱。他們將每個時間序列嵌入為變量 token,采用多變量相關性關注,并使用前饋網絡進行序列編碼。實驗結果表明,本文所提出的 iTransformer 在圖 1 所示的實際預測基準上達到了 SOTA 水準,并出人意料地解決了基于 Transformer 的預測器的痛點。
總結來說,本文的貢獻有以下三點:
-
研究者對 Transformer 的架構進行了反思,發現原生 Transformer 組件在時間序列上的能力尚未得到充分開發。
-
本文提出的 iTransformer 將獨立時間序列視為 token,通過自注意力捕捉多變量相關性,并利用層歸一化和前饋網絡模塊學習更好的序列全局表示法,用于時間序列預測。
-
通過實驗,iTransformer 在真實世界的預測基準上達到了 SOTA。研究者分析了反轉模塊和架構選擇,為未來改進基于 Transformer 的預測器指明了方向。
iTransformer
在多變量時間序列預測中,給定歷史觀測:
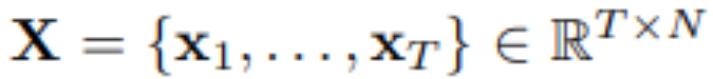
用 T 個時間步長和 N 個變量,研究者預測未來的 S 個時間步長: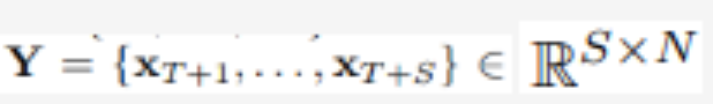 。為方便起見,表示為
。為方便起見,表示為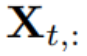 為時間步 t 同時記錄的多元變量,
為時間步 t 同時記錄的多元變量,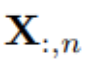 為每個變量由 n 索引的整個時間序列。值得注意的是,在現實世界中,由于監視器的系統延遲和松散組織的數據集,
為每個變量由 n 索引的整個時間序列。值得注意的是,在現實世界中,由于監視器的系統延遲和松散組織的數據集,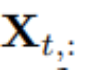 可能不包含本質上相同時間戳的時間點。
可能不包含本質上相同時間戳的時間點。
的元素可以在物理測量和統計分布中彼此不同,變量通常共享這些數據。
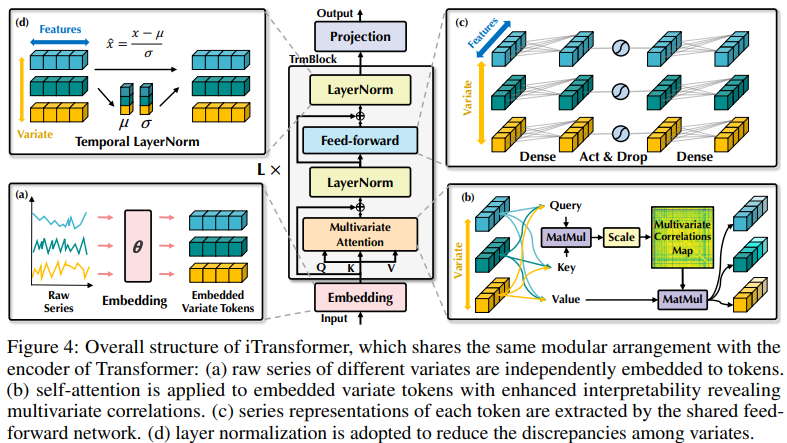
本文所提出架構配備的 Transformer 變體,稱為 iTransformer,基本上沒有對 Transformer 變體提出更具體的要求,只是注意力機制應適用于多元相關性建模。因此,一組有效的注意力機制可以作為插件,降低變量數量增加時關聯的復雜性。
圖 4 中所示的 iTransformer 利用了更簡單的 Transformer 純編碼器架構,包括嵌入、投影和 Transformer 塊。
實驗及結果
研究者在各種時間序列預測應用中對所提出的 iTransformer 進行了全面評估,驗證了所提出框架的通用性,并進一步深入研究了針對特定時間序列維度反轉 Transformer 組件職責的效果。
研究者在實驗中廣泛納入了 6 個真實世界數據集,包括 Autoformer 使用的 ETT、天氣、電力、交通數據集、LST5 Net 提出的太陽能數據集以及 SCINet 評估的 PEMS 數據集。更多關于數據集的信息,請閱讀原文。
預測結果
如表 1 所示,用紅色表示最優,下劃線表示最優。MSE/MAE 越低,預測結果越準確。本文所提出的 iTransformer 實現了 SOTA 性能。原生 Transformer 組件可以勝任時間建模和多元關聯,所提出的倒排架構可以有效解決現實世界的時間序列預測場景。

iTransformer 通用性
研究者將該框架應用于 Transformer 及其變體來評估 iTransformers,這些變體通常解決了 self-attention 機制的二次復雜性問題,包括 Reformer、Informer、Flowformer 和 FlashAttention。研究者發現了簡單的倒置視角可以提高基于 Transformer 的預測器的性能,從而提高效率、泛化未見變量并更好地利用歷史觀測數據。
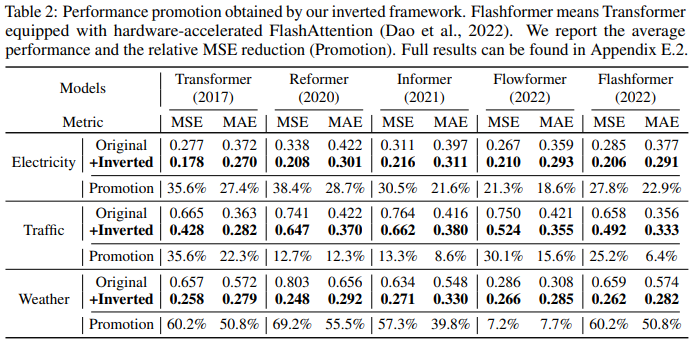
表 2 對 Transformers 和相應的 iTransformers 進行了評估。值得注意的是,該框架持續改進了各種 Transformer。總體而言,Transformer 平均提升了 38.9%,Reformer 平均提升了 36.1%,Informer 平均提升了 28.5%,Flowformer 平均提升了 16.8%,Flashformer 平均提升了 32.2%。
此外,由于倒置結構在變量維度上采用了注意力機制,因此引入具有線性復雜性的高效注意力從根本上解決了因 6 個變量而產生的效率問題,這一問題在現實世界的應用中十分普遍,但對于 Channel Independent 來說可能會消耗資源。因此,iTransformer 可廣泛應用于基于 Transformer 的預測器。
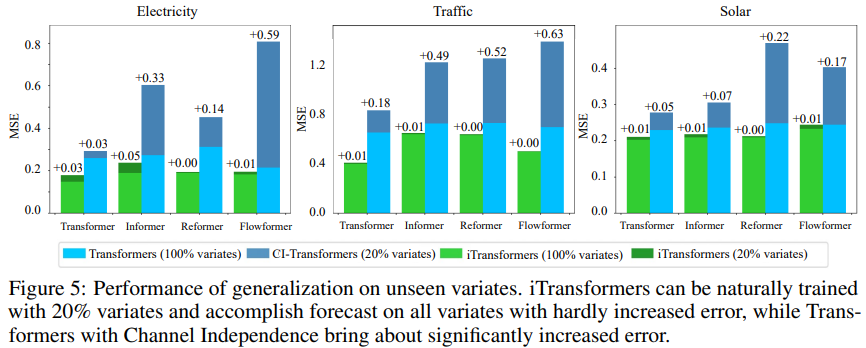
為了驗證假設,研究者將 iTransformer 與另一種泛化策略進行了比較:Channel Independent 強制采用一個共享 Transformer 來學習所有變體的模式。如圖 5 所示, Channel Independent(CI-Transformers)的泛化誤差可能會大幅增加,而 iTransformer 預測誤差的增幅要小得多。
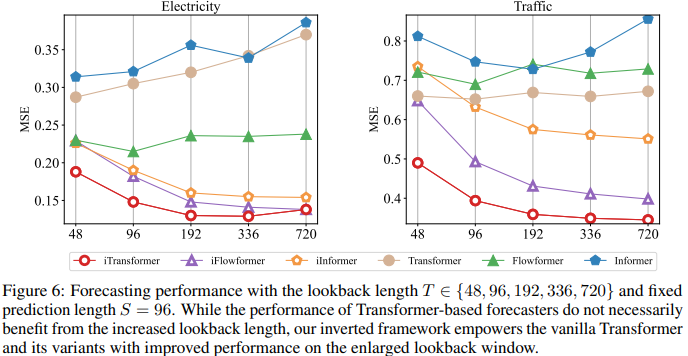
由于注意力和前饋網絡的職責是倒置的,圖 6 中評估了隨著回視長度的增加,Transformers 和 iTransformer 的性能。它驗證了在時間維度上利用 MLP 的合理性,即 Transformers 可以從延長的回視窗口中獲益,從而獲得更精確的預測。
模型分析
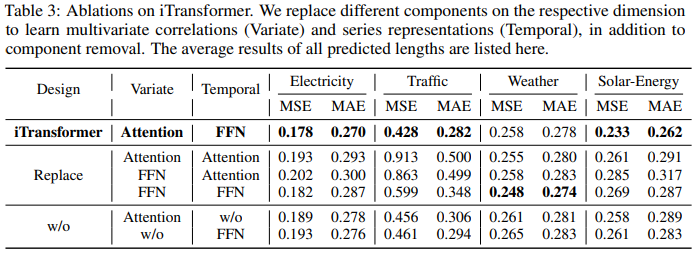
為了驗證 Transformer 組件的合理性,研究者進行了詳細的消融實驗,包括替換組件(Replace)和移除組件(w/o)實驗。表 3 列出了實驗結果。
更多詳細內容,請參考原文。
-
物聯網
+關注
關注
2913文章
44918瀏覽量
376869
原文標題:重新審視Transformer:倒置更有效,真實世界預測的新SOTA出現了
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
SOLIDWORKS 2025更有效的協作和數據管理
transformer專用ASIC芯片Sohu說明

Mamba入局圖像復原,達成新SOTA


自動駕駛中一直說的BEV+Transformer到底是個啥?






 工商網監
工商網監
評論