 自動駕駛中一直說的BEV+Transformer到底是個啥?
自動駕駛中一直說的BEV+Transformer到底是個啥?
在很多車企的自動駕駛介紹中,都會聽到一個關鍵技術,那就是BEV+Transformer,那BEV+Transformer到底是個啥?為什么很多車企在自動駕駛技術中都十分追捧這項技術?其實“BEV(Bird’s Eye View)+Transformer”是兩個方向的技術,BEV是一種全新的3D坐標系,而Transformer則是一種深度學習神經網絡模型,BEV+Transformer的組合方案在感知、理解和預測方面表現得更為強大,徹底終結了2D直視圖+CNN時代。BEV+Transformer通過鳥瞰視角與Transformer模型的結合,顯著提升了自動駕駛系統的環境感知與決策支持能力。BEV+Transformer的首次亮相是由特斯提出,高效解決了其純視覺方案下多個攝像頭的數據融合的問題,隨后國內的小鵬、理想、蔚來等車企以及毫末智行、百度Apollo、商湯、地平線等Tier 1也紛紛跟進,提出了自己的BEV+Transformer方案。
 Tier 1智能駕駛集感知模型應用,來源:億歐智庫
Tier 1智能駕駛集感知模型應用,來源:億歐智庫
BEV(鳥瞰視角)的概念
1.BEV的定義和背景
BEV即“Bird’s Eye View”(鳥瞰視角),顧名思義,它能夠將視覺信息立體化,如同一只鳥兒在車輛正上方俯瞰,周圍的環境信息以自上而下的方式展示在坐標系中,可以生成是以車輛為中心、從高空俯視車輛周圍環境的視角。與攝像頭獲取的前視圖相比,BEV視角能夠顯示更多的車輛周圍信息。這種視角在自動駕駛中十分重要,因為它為感知系統提供了更廣闊的空間視野,有助于系統更好地理解復雜交通場景中的多方位環境。
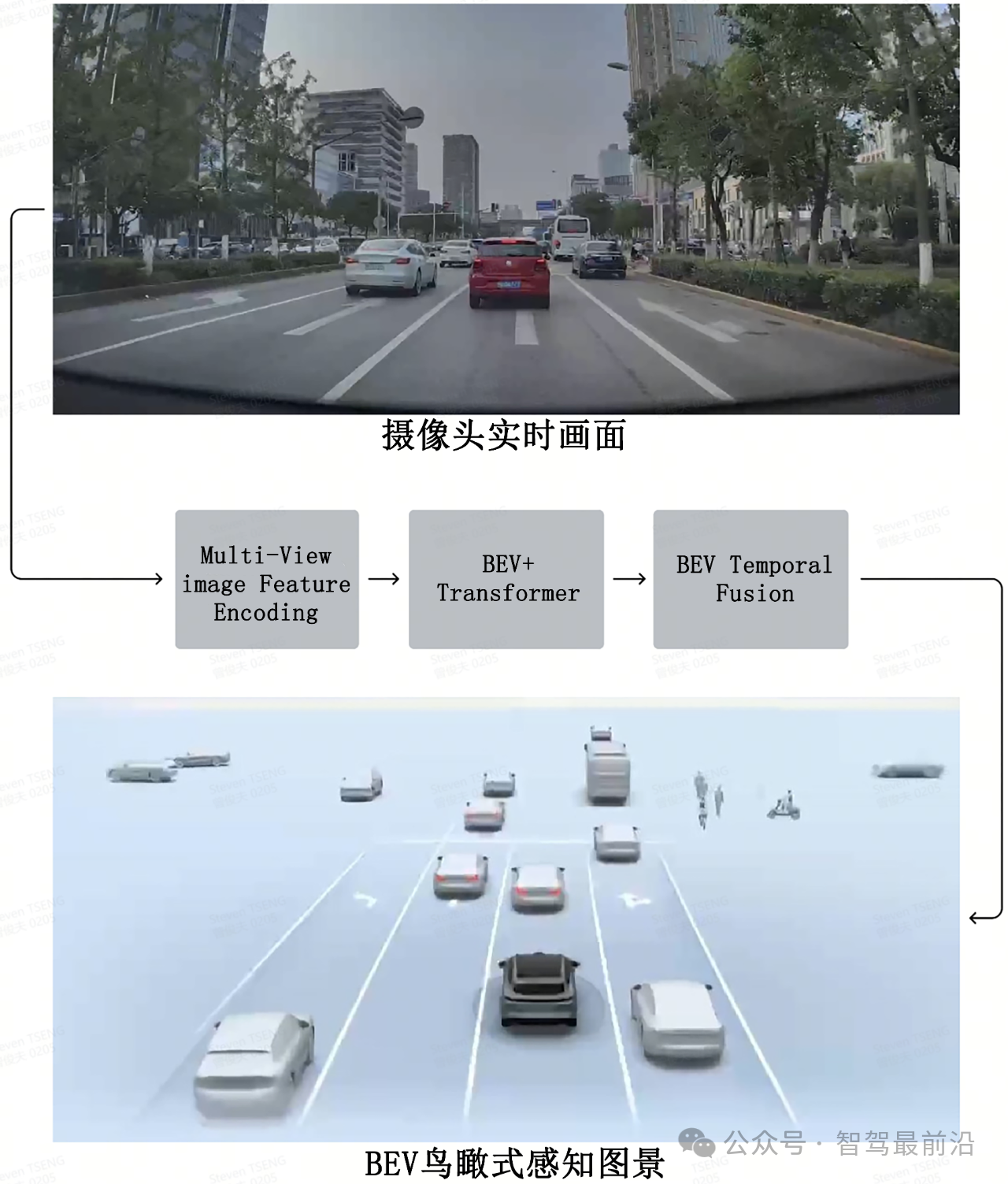
2.BEV視角的生成過程
獲取BEV視角通常依賴于多種傳感器的數據融合,如攝像頭、激光雷達和毫米波雷達。這些傳感器以不同角度捕獲環境數據,然后通過深度估計、幾何投影(尤其是透視投影變換)和坐標轉換等步驟,將各視角的圖像或點云數據整合為一個鳥瞰圖。特別是在攝像頭生成BEV視角的過程中,這種投影轉換需要考慮到圖像的畸變和透視效果,以確保視角的準確性。
3.BEV視角的實際應用
BEV視角在自動駕駛中的應用主要體現在復雜交通場景下的環境理解,如多車道并行、十字路口和環形交叉路口等。通過BEV視角,系統不僅可以識別前方物體,還能準確檢測車輛四周的障礙物、行人、非機動車和建筑物,從而為安全行駛提供更全面的環境信息。
Transformer的基本概念與作用
1.Transformer模型的起源
Transformer模型最早由谷歌在2017年的“Attention is all you need”一文中提出,最初用于自然語言處理(NLP)領域的翻譯和文本生成任務。與傳統的RNN、LSTM模型不同,Transformer的自注意力機制(Self-Attention)允許其處理任意長度的輸入序列,且并行計算性能強,因此在大規模數據處理和高效計算方面有顯著優勢。隨著AI深度學習的興起,Transformer被應用在BEV空間轉換、時間序列上,形成了一個端到端的模型。
2.Transformer在視覺任務中的擴展
Transformer模型逐步被應用于計算機視覺(CV)任務,如目標檢測、語義分割和物體跟蹤等。其自注意力機制能夠在圖像上捕捉全局信息并分析不同位置特征之間的關系,幫助系統建立物體之間的空間關系。這在復雜場景下尤其重要,例如城市道路中需要理解不同車輛、行人之間的動態交互。
3.Transformer在BEV視角中的作用
在BEV+Transformer架構中,Transformer模型負責將BEV視角中的特征圖信息轉化為高層次的語義信息。通過自注意力機制,Transformer能夠在特征圖上找到重要物體之間的相對位置關系,并分析它們的行為趨勢。例如,Transformer可以識別車道內外車輛的距離和速度關系,有助于預測其他車輛的運動軌跡。
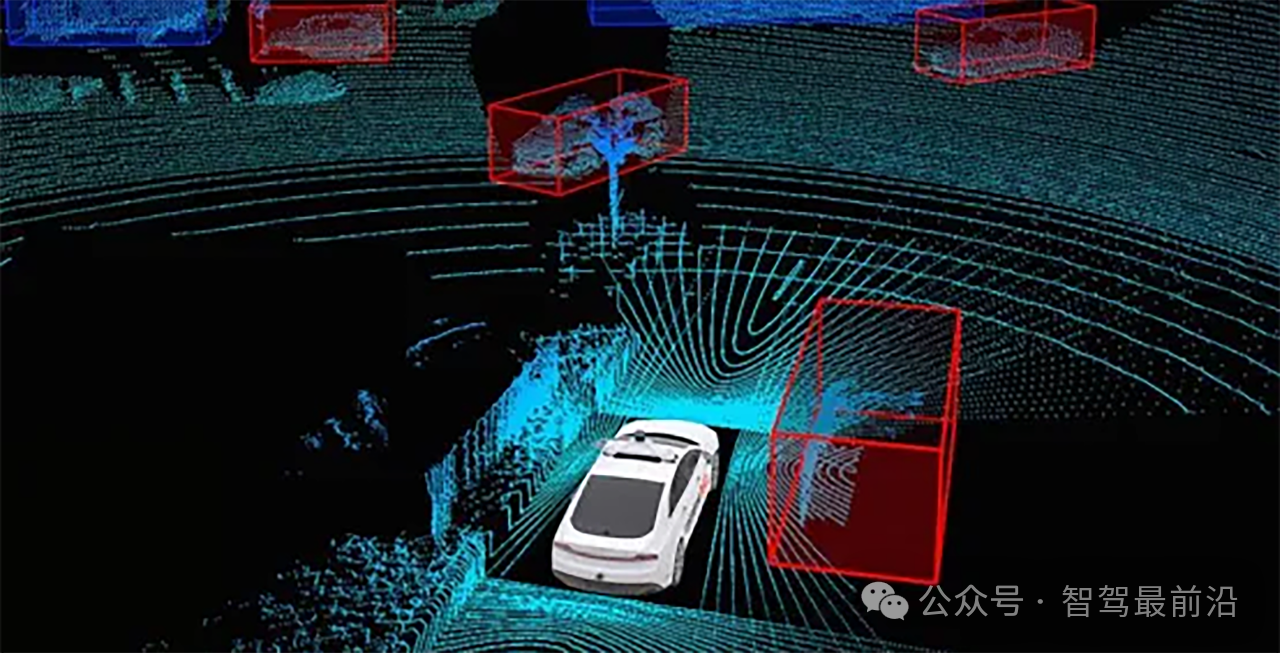
BEV+Transformer的技術原理
1.多傳感器數據融合與轉換
BEV+Transformer的核心在于將來自不同傳感器的數據統一轉換為BEV視角的特征圖,再利用Transformer進行深度分析。首先,通過卷積神經網絡(CNN)對攝像頭和雷達數據提取特征,并進行投影轉換生成BEV視角的特征圖。這樣就能在車身上方生成完整的俯視圖,為Transformer模型提供豐富的環境信息。
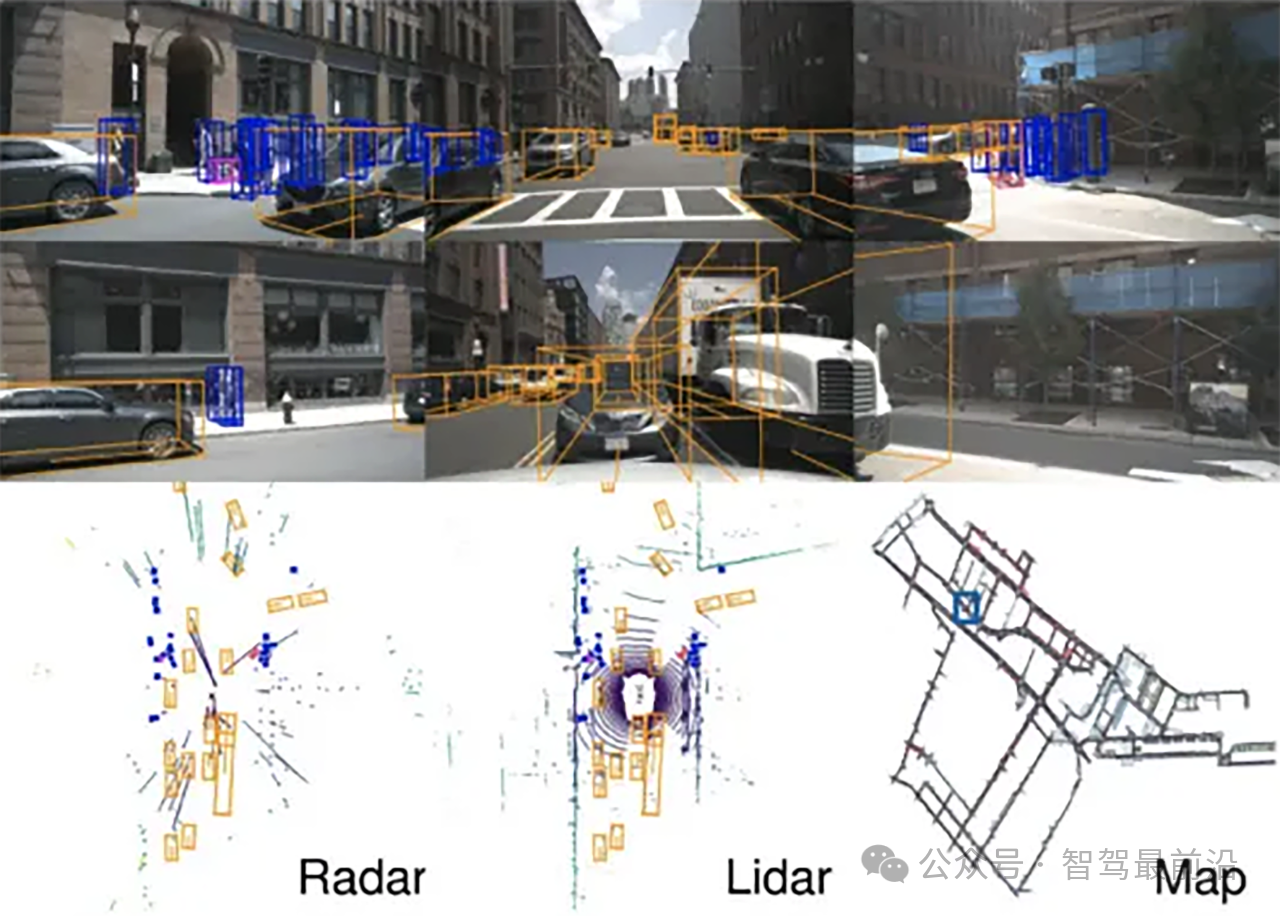
2.自注意力機制的全局關系分析
Transformer模型利用自注意力機制分析BEV特征圖中的不同位置特征,建立物體與物體之間的相關性。例如,系統可以分析道路上的車輛、行人、障礙物的分布及其相對速度,預測他們的行為變化趨勢。這種全局關系的分析使得系統對復雜場景的環境理解更加深刻和準確。
3.高層次語義信息的輸出與決策支持
Transformer處理完BEV視角特征后,生成的輸出包含環境的高層次語義信息,包括物體類別、位置、運動趨勢等。這些信息不僅可以用于路徑規劃,還能輔助車輛進行避障和動態調整。在自動駕駛決策模塊中,這些高層信息與其他預測結果結合,生成更加智能的駕駛策略。
BEV+Transformer的實際應用案例
1.障礙物檢測與識別
BEV+Transformer架構可在復雜交通場景中識別各類障礙物,包括車輛、行人和道路設施等。通過自注意力機制,系統能夠在特征圖中捕捉到環境中關鍵物體的位置和運動方向,并對潛在的障礙物進行跟蹤檢測,有助于及時生成避障方案。
2.路徑預測與動態規劃
在路徑預測方面,BEV+Transformer架構通過學習環境中各參與者的運動特征,預測車輛和行人等的行駛軌跡。這種全局化預測在車流密集的場景中尤為重要,能夠幫助自動駕駛系統提前分析其他交通參與者的行為趨勢,從而制定更安全、順暢的行駛路徑。
3.車道線識別與輔助駕駛
在高速公路或復雜路口,車輛需要精準識別車道線以保持在車道內行駛。傳統攝像頭的識別易受光線和視角影響,而BEV+Transformer結合了全方位的鳥瞰圖,確保了在惡劣條件下也能穩定識別車道線,使車輛在變道或急轉彎時更安全。
BEV+Transformer的優勢
1.全局視角與空間理解能力
BEV視角帶來了全局性的環境感知能力,能夠減少車輛周圍盲區。Transformer的自注意力機制則增強了系統的空間理解能力,在BEV特征圖中識別出場景內物體的長距離關系,使得自動駕駛系統對復雜環境的認知更全面。
2.多模態數據的統一融合
BEV+Transformer架構能夠在統一的特征圖中處理多傳感器信息,提升了感知的精度。例如,圖像與點云數據經過前期融合后,再經由Transformer分析,大大減少了因多傳感器不一致而產生的誤差,從而提升了模型的魯棒性。
3.有效的預測能力
Transformer在視覺任務中展現出的強大預測能力,使BEV+Transformer架構可以更準確地預測其他車輛、行人的行為。尤其在動態交通場景中,Transformer結合BEV信息能提供精細的路徑預測,幫助自動駕駛系統提前識別潛在風險。
BEV+Transformer的局限性與挑戰
1.計算資源需求與實時性挑戰
Transformer的自注意力機制對計算資源需求較大,尤其是在處理多傳感器融合數據時,可能會導致推理延遲問題。自動駕駛系統需要達到毫秒級響應速度,這對計算資源提出了高要求。一些優化技術(如分塊自注意力)可以減小負擔,但實現高效實時推理仍是挑戰。
2.傳感器精度和同步性依賴
BEV+Transformer的表現高度依賴傳感器的精度與同步性。在復雜環境中,天氣、遮擋、反射等因素可能導致傳感器獲取的信息出現偏差,從而影響BEV視角的準確性。傳感器誤差會使Transformer的分析結果不可靠,影響系統的整體表現。
3.復雜交通場景的魯棒性
BEV+Transformer在高動態交通場景下(如城市密集路段)可能受到影響,因為這些場景包含大量動態物體及不確定因素。在應對惡劣天氣、光線變化及不同國家的道路標志差異時,BEV+Transformer的魯棒性仍需進一步驗證和優化,以保證系統能適應多樣化的場景。
結語
BEV+Transformer架構為自動駕駛領域帶來了新的技術突破。通過結合鳥瞰視角的全局信息和Transformer的自注意力機制,該架構顯著提升了感知精度和決策支持能力。然而,要在實際道路場景中實現其廣泛應用,還需克服計算資源、傳感器同步性等方面的挑戰。未來,隨著硬件技術的進步和算法優化,BEV+Transformer有望成為自動駕駛系統的重要組成部分,為完全自動駕駛奠定堅實的技術基礎。
審核編輯 黃宇
-
自動駕駛
+關注
關注
784文章
13844瀏覽量
166573 -
Transformer
+關注
關注
0文章
144瀏覽量
6017
發布評論請先 登錄
相關推薦
自動駕駛中常提的魯棒性是個啥?
淺析基于自動駕駛的4D-bev標注技術

一文聊聊自動駕駛測試技術的挑戰與創新

自動駕駛中常提的SLAM到底是個啥?
自動駕駛汽車安全嗎?



FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
黑芝麻智能開發多重亮點的BEV算法技術 助力車企高階自動駕駛落地

自動駕駛已成現實?賽思時間同步服務器賦能北京市高級別自動駕駛示范區,為自動駕駛提供中國方案

端到端自動駕駛的基石到底是什么?
BEV和Occupancy自動駕駛的作用

自動駕駛領域中,什么是BEV?什么是Occupancy?






 工商網監
工商網監
評論