 JSON的使用方法
JSON的使用方法
JSON是一個標記符序列。這套標記符包括: 構造字符、字符串、數字和三個字面值 。
構造字符
JSON包括六個構造字符,分別是:左方括號、右方括號、左大括號、右大括號、冒號與逗號。
JSON值
JSON值可以是對象、數組、數字、字符串或者三個字面值(false、true、null),并且字面值必須是小寫英文字母。
對象
對象是由花括號括起來,逗號分割的成員構成,成員是字符串鍵和上面所說的JSON值構成,例如:
{"name":"jack","age":18,"address":{"country"}}
數組
數組是由方括號括起來的一組數值構成,例如:
[1,2,32,3,6,5,5]
字符串與數字想必就不用我過多敘述吧。
下面我就舉例一些合法的JSON格式的數據:
{"a":1,"b":[1.2.3]}
[1,2,"3",{"a":4}]
3.14
"json_data"
為什么要使用JSON
JSON是一種輕量級的數據交互格式,它使得人們很容易的進行閱讀和編寫。同時也方便機器進行解析和生成。適用于進行數據交互的場景,比如網站前臺與后臺之間的數據交互。
JSON的使用方法
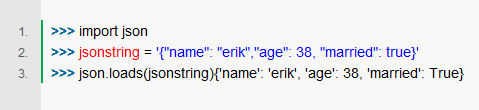
json.loads()
把JSON格式字符串解碼轉成Python對象,從JSON到Python類型轉換表如下:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number(int) | int |
| number(real) | float |
| true | True |
| false | False |
| null | None |
- 將數組轉成列表對象
import json
strList = "[1,2,3,3,4]"
print(json.loads(strList))
print(type(json.loads(strList)))
試著運行上面的代碼,你會發現已經成功的將strList轉換為列表對象。
- 將對象轉換成字典
import json
strDict = '{"city":"上海","name":"jack","age":18}'
print(json.loads(strDict))
print(type(json.loads(strDict)))
試著運行上面的代碼,你會發現已經成功的將object轉換為dict類型的數據。
json.dumps()
其實這個方法也很好理解,就是將Python類型的對象轉換為json字符串。從Python類型向JSON類型轉換的對照表如下:
| python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| False | false |
| None | null |
- 將Python列表對象轉換為JSON字符串
import json
list_str = [1,2,3,6,5]
print(json.dumps(list_str))
print(type(json.dumps(list_str)))
試著運行上面的代碼,你會發現成功的將列表類型轉換成了字符串類型。
- 將Python元組對象轉換為JSON字符串
import json
tuple_str = (1,2,3,6,5)
print(json.dumps(tuple_str))
print(type(json.dumps(tuple_str)))
試著運行上面的代碼,你會發現成功的將元組類型的數據轉換成了字符串。
- 將Python字典對象轉換為JSON字符串
import json
dict_str = {"name": "小明", "age":18, "city": "中國深圳"}
print(json.dumps(dict_str))
print(type(json.dumps(dict_str)))
輸出結果:
{"name": "u5c0fu660e", "age": 18, "city": "u4e2du56fdu6df1u5733"}
< class 'str' >
看到上面的輸出結果也許你會有點疑惑,其實不需要疑惑,這是ASCII編碼方式造成的,因為**json.dumps()**做序列化操作時默認使用的就是ASCII編碼,因此我們可以這樣寫:
import json
dict_str = {"name": "小明", "age":18, "city": "中國深圳"}
print(json.dumps(dict_str, ensure_ascii=False))
print(type(json.dumps(dict_str)))
輸出結果:
{"name": "小明", "age": 18, "city": "中國深圳"}
< class 'str' >
因為ensure_ascii的默認值是True,因此我們可以添加參數ensure_ascii將它的默認值改成False,這樣編碼方式就會更改為utf-8了。
json.load()
該方法的主要作用是將文件中JSON形式的字符串轉換為Python類型。
具體代碼示例如下:
import json
str_list = json.load(open('position.json', encoding='utf-8'))
print(str_dict)
print(type(str_dict))
運行上面的代碼,你會發現成功的將字符串類型的JSON數據轉換為了dict類型。
代碼中的文件position.json我也會分享給大家。
json.dump()
將Python內置類型序列化為JSON對象后寫入文件。具體代碼示例如下所示:
import json
list_str = [{'city':'深圳'}, {'name': '小明'},{'age':18}]
dict_str = {'city':'深圳','name':'小明','age':18}
json.dump(list_str, open('listStr.json', 'w'), ensure_ascii=False)
json.dump(list_str, open('dictStr.json', 'w'), ensure_ascii=False)
jsonpath
XML的優點是提供了大量的工具來分析、轉換和有選擇地從XML文檔中提取數據。Xpath是這些功能強大的工具之一。
對于JSON數據來說,也出現了jsonpath這樣的工具來解決這些問題:
- 數據可以通過交互方式從客戶端上的JSON結構提取,不需要特殊的腳本。
- 客戶端請求的JSON數據可以減少到服務器的上的相關部分,從而大幅度減少服務器響應的帶寬使用。
jsonpath表達式始終引用JSON結構的方式與Xpath表達式與XML文檔使用的方式相同。
jsonpath的安裝方法
pip install jsonpath
jsonpath與Xpath
下面表格是jsonpath語法與Xpath的完整概述和比較。
| Xpath | jsonpath | 概述 |
|---|---|---|
| / | $ | 根節點 |
| . | @ | 當前節點 |
| / | .or[] | 取子節點 |
| * | * | 匹配所有節點 |
| [] | [] | 迭代器標識(如數組下標,根據內容選值) |
| // | ... | 不管在任何位置,選取符合條件的節點 |
| n/a | [,] | 支持迭代器中多選 |
| n/a | ?() | 支持過濾操作 |
| n/a | () | 支持表達式計算 |
下面我們就通過幾個示例來學習jsonxpath的使用方法。
我們先來看下面這段json數據
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
獲取符合條件的節點
假如我需要獲取到作者的名稱該怎么樣寫呢?
如果通過Python的字典方法來獲取是非常麻煩的,所以在這里我們可以選擇使用jsonpath.。
具體代碼示例如下所示:
import jsonpath
author = jsonpath.jsonpath(data_json, '$.store.book[*].author')
print(author)
運行上面的代碼你會發現,成功的獲取到了所有的作者名稱,并保存在列表中。
或者還可以這樣寫:
import jsonpath
author = jsonpath.jsonpath(data_json, '$..author')
print(author)
使用指定索引
還是使用上面的json數據,假如我現在需要獲取第三本書的價格。
third_book_price = jsonpath.jsonpath(data_json, '$.store.book[2].price')
print(third_book_price)
運行上面的代碼,你會發現成功的獲取到了第三本書的價格。
使用過濾器
isbn_book = jsonpath.jsonpath(data_json, '$..book[?(@.isbn)]')
print(isbn_book)
print(type(isbn_book))
通過運行上面的代碼,你會發現,成功的將含有isbn編號的書籍過濾出來了。
同樣的道理,根據上面的例子,我們也可以將價格小于10元的書過濾出來。
book = jsonpath.jsonpath(data_json, '$..book[?(@.price< 10)]')
print(book)
print(type(book))
通過運行上面的代碼,你會發現這里已經成功的將價格小于10元的書提取出來了。
jsonpath其實是非常適合用來獲取json格式的數據的一款工具,最重要的是這款工具輕量簡單容使用。關于jsonpath的介紹到這里就結束了,下面我們就進入實戰演練吧!
項目實戰
前言
每年的6月份都是高校學生的畢業季,作為計算機專業的你來說,如果剛剛畢業就可以進入大廠,想必是一個非常不錯的選擇。因此,今天我帶來的項目就是爬取騰訊招聘的網站,獲取 職位名稱、職位類別、工作地點、工作國家、職位的更新時間、職位描述 。
爬取內容一共有329頁,在前329頁的職位都是在這個月發布的,還是比較新,對大家來說更有參考的價值。
網頁鏈接:https://careers.tencent.com/search.html
準備
工欲善其事,必現利其器 。首先我們要準備好幾個庫:pandas、requests、jsonpath
如果沒有安裝,請參考下面的安裝過程:
pip install requests
pip install pandas
pip install jsonpath
需求分析與功能實現
獲取所有的職位信息
對網頁進行分析的時候,我發現想從網頁上直接獲取信息是是做不到的,該網頁的響應信息如下所示:
< !DOCTYPE html >< html >< head >< meta charset=utf-8 >< meta http-equiv=X-UA-Compatible content="IE=edge" >< meta name=viewport content="initial-scale=1,maximum-scale=1,user-scalable=no" >< meta name=keywords content="" >< meta name=description content="" >< meta name=apple-mobile-web-app-capable content=no >< meta name=format-detection content="telephone=no" >< title >搜索 | 騰訊招聘< /title >< link rel=stylesheet href=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/css/main.css >< link rel=stylesheet href=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/css/jquery-ui.min.css >< /head >< body >< div id=app >< /div >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/HeadFoot_zh-cn.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/HostMsg_zh-cn.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/careersmlr/Search_zh-cn.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/config.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/jquery.min.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/jquery.ellipsis.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/report.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/qrcode.min.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/manifest.build.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor.build.js >< /script >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/p_zh-cn_search.build.js >< /script >< /body >< script type=text/javascript src=https://cdn.multilingualres.hr.tencent.com/tencentcareer/static/js/vendor/common.js >< /script >< /html >
因此我判斷,這個是動態Ajax加載的數據,因此就要去網頁控制器上查找職位數據是否存在。
經過一番查找,果然發現是動態加載的數據,信息如下所示:
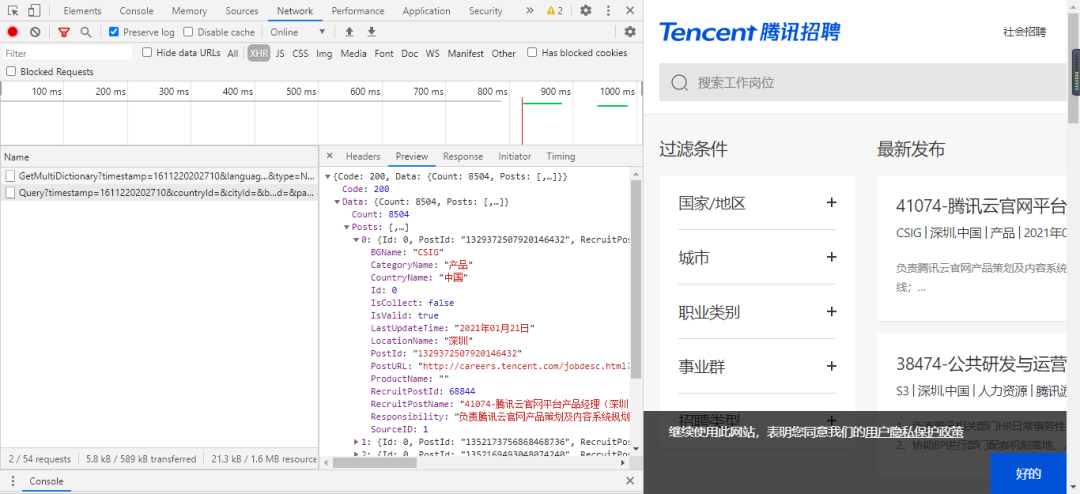
格式化之后的數據如下所示:
{
"Code":200,
"Data":{
"Count":8500,
"Posts":[
{
"Id":0,
"PostId":"1346716678288842752",
"RecruitPostId":71330,
"RecruitPostName":"41071-騰訊會議項目經理(西安)(CSIG全資子公司)",
"CountryName":"中國",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"騰訊云",
"CategoryName":"產品",
"Responsibility":"1、負責研發項目及研發效能的計劃制定、進度驅動和跟蹤、風險識別以及應對,確保項目按計劃完成;
2、負責組織項目各項評審會議及項目例會,制定并推廣項目流程規范,確保項目有序進行;
3、負責與項目外部合作伙伴進行溝通,制定流程規范雙方合作,并推動合作事宜;
4、及時發現并跟蹤解決項目問題,有效管理項目風險。
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346716678288842752",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1346716729744564224",
"RecruitPostId":71331,
"RecruitPostName":"41071-騰訊會議產品策劃(平臺方向)(CSIG全資子公司)",
"CountryName":"中國",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"騰訊云",
"CategoryName":"產品",
"Responsibility":"1、負責騰訊會議企業管理平臺的產品策劃工作,包括企業運營平臺、運維、會控平臺和工具的產品設計和迭代優化;
2、協調和推動研發團隊完成產品開發、需求落地,并能在需求上線后進行持續數據分析和反饋跟進,不斷提升產品競爭力;
3、根據行業場景抽象用戶需求,沉淀面向不同類型客戶的云端管控平臺解決方案;
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346716729744564224",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1346062593894129664",
"RecruitPostId":71199,
"RecruitPostName":"41071-騰訊會議產品策劃(CSIG全資子公司)",
"CountryName":"中國",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"騰訊云",
"CategoryName":"產品",
"Responsibility":"負責騰訊會議的產品策劃工作:
1、研究海外用戶辦公習慣及SaaS市場動態,調研海外相關SaaS產品并輸出產品調研結論,綜合市場情況和用戶需求輸出高質量的產品需求或解決方案;
2、負責騰訊會議各產品線的英文版的功能同步和產品設計工作,把關產品功能同步和國際版需求改造等;
3、協調和推動研發團隊完成產品開發、需求落地,并能在需求上線后進行持續數據分析和反饋跟進,不斷提升產品競爭力; ",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1346062593894129664",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352161575309418496",
"RecruitPostId":72134,
"RecruitPostName":"CSIG16-推薦算法高級工程師",
"CountryName":"中國",
"LocationName":"北京",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技術",
"Responsibility":"1. 參與地圖場景下推薦算法優化,持續提升轉化效果和用戶體驗;
2. 負責地圖場景下推薦引擎架構設計和開發工作;
3. 跟進業界推薦領域最新進展,并推動其在地圖場景下落地。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352158432852975616",
"RecruitPostId":72133,
"RecruitPostName":"41071-騰訊云SDK 終端研發工程師(CSIG全資子公司)",
"CountryName":"中國",
"LocationName":"西安",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技術",
"Responsibility":"1. 負責騰訊云 GME SDK(游戲多媒體引擎)的開發和優化工作,并配套開發相應的場景解決方案業務流程,以滿足不同場景和不同行業的客戶需求;
2. 全流程參與客戶需求咨詢、需求評估、方案設計、方案編碼實施及交付工作;
3. 負責優化騰訊云GME產品易用性,并跟蹤客戶的接入成本、完善服務體系,解決客戶使用產品服務和解決方案過程中的技術問題,不斷完善問題處理機制和流程。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1352155053116366848",
"RecruitPostId":72131,
"RecruitPostName":"40931-智慧交通數據平臺前端開發工程師(北京)",
"CountryName":"中國",
"LocationName":"北京",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"技術",
"Responsibility":"負責騰訊智慧交通領域的平臺前端開發工作;
負責規劃與制定前端整體發展計劃與基礎建設;
負責完成前端基礎架構設計與組件抽象。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=0",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1306860769169645568",
"RecruitPostId":66367,
"RecruitPostName":"35566-HRBP(騰訊全資子公司)",
"CountryName":"中國",
"LocationName":"武漢",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力資源",
"Responsibility":"負責區域研發公司的HR政策、制度、體系與重點項目在部門內部的落地與推動執行;
深入了解所負責領域業務與人員發展狀況,評估并明確組織與人才發展對HR的需求;
驅動平臺資源提供HR解決方案,并整合內部資源推動執行;提升管理干部的人力資源管理能力,關注關鍵人才融入與培養,確保持續的溝通與反饋;
協助管理層進行人才管理、團隊發展、組織氛圍建設等,確保公司文化在所屬業務領域的落地;
負責所對接部門的人才招聘工作;
",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1306860769169645568",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1351353005709991936",
"RecruitPostId":71981,
"RecruitPostName":"35566-招聘經理(騰訊云全資子公司)",
"CountryName":"中國",
"LocationName":"武漢",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力資源",
"Responsibility":"1、負責CSIG區域研發公司相關部門的社會招聘及校園招聘工作,制定有效的招聘策略并推動落地執行,保障人才開源、甄選和吸引;
2、負責相關部門人力資源市場分析,有效管理并優化招聘渠道;
3、參與招聘體系化建設,甄選相關優化項目,有效管理及優化招聘渠道。",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1351353005709991936",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1351838518279675904",
"RecruitPostId":72081,
"RecruitPostName":"35566-雇主品牌經理(騰訊云全資子公司)",
"CountryName":"中國",
"LocationName":"武漢",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"人力資源",
"Responsibility":"1、負責騰訊云區域研發公司雇主品牌的規劃和建設工作,結合業務招聘需求,制定有效的品牌方案;
2、負責訊云區域研發公司的公眾號、媒體賬號的內容策劃、撰寫,協調相關資源完成高質量內容輸出;
3、負責招聘創意項目的策劃和項目統籌,借助各種平臺渠道,完成創意內容的傳播觸達,提升人選對騰訊云區域研發公司的認知和意向度;",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1351838518279675904",
"SourceID":1,
"IsCollect":false,
"IsValid":true
},
{
"Id":0,
"PostId":"1199244591342030848",
"RecruitPostId":55432,
"RecruitPostName":"22989-數據庫解決方案架構師(北京/上海/深圳)",
"CountryName":"中國",
"LocationName":"上海",
"BGName":"CSIG",
"ProductName":"",
"CategoryName":"產品",
"Responsibility":"支持客戶的應用架構設計,了解客戶的業務邏輯和應用架構,給出合理的產品方案建議;
支持客戶的數據庫方案設計,從運維、成本、流程等角度主導云數據庫產品落地;
梳理客戶的核心訴求,提煉為普適性的產品能力,推動研發團隊提升產品體驗;
根據客戶的行業屬性,定制行業場景的解決方案,提升云數據庫的影響力;",
"LastUpdateTime":"2021年01月21日",
"PostURL":"http://careers.tencent.com/jobdesc.html?postId=1199244591342030848",
"SourceID":1,
"IsCollect":false,
"IsValid":true
}
]
}
}
經過對比發現上面的json數據與網頁信息是完全相同的。
看到json數據你有沒有一絲的驚喜,終于到了可以大顯身手的時候了。
你會發現,上面每一個節點的參數都是獨立的,不會存在重復,那我們可以這樣寫:
def get_info(data):
recruit_post_name = jsonpath.jsonpath(data, '$..RecruitPostName')
category_name = jsonpath.jsonpath(data, '$..CategoryName')
country_name= jsonpath.jsonpath(data, '$..CountryName')
location_name = jsonpath.jsonpath(data, '$.Data.Posts..LocationName')
responsibility = jsonpath.jsonpath(data, '$..Responsibility')
responsibility = [i.replace('n', '').replace('r', '') for i in responsibility]
last_update_time = jsonpath.jsonpath(data, '$..LastUpdateTime')
運行上面的代碼,你會發現成功的獲取到了每一組數據。
關于翻頁
打開網頁之后你會發現騰訊的職位信息一共有850頁,但是前面的json數據僅僅只有第一頁的數據怎么辦呢?
不用擔心,直接點擊第二頁看看網絡數據有什么變化。
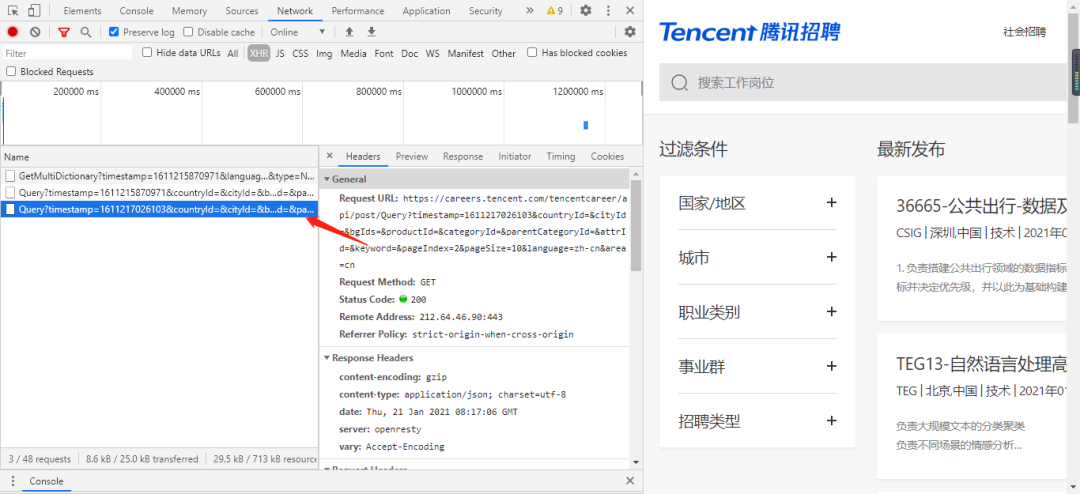
如上圖所示,當點擊第二頁的時候,又加載出來了一個數據,點擊進去之后你就會發現,這個數據剛好就是第二頁的職位信息。
那接下來就是發現規律的時候了,第一頁與第二頁保存JSON數據的URL如下所示:
# 第一頁
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1611215870971&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
# 第二頁
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1611217026103&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=2&pageSize=10&language=zh-cn&area=cn
經過測試發現,可以將URL地址進行簡化,簡化后的URL如下所示:
# 第一頁
https://careers.tencent.com/tencentcareer/api/post/Query?pageIndex=1&pageSize=10
# 第二頁
https://careers.tencent.com/tencentcareer/api/post/Query?pageIndex=1&pageSize=10
數據保存
將爬取下來的數據保存至csv文件,核心代碼如下所示:
df = pd.DataFrame({
'country_name': country_name,
'location_name': location_name,
'recruit_post_name':recruit_post_name,
'category_name': category_name,
'responsibility':responsibility,
'last_update_time':last_update_time
})
if __name__ == '__main__':
tengxun = TengXun()
df = pd.DataFrame(columns=['country_name', 'location_name', 'category_name','recruit_post_name', 'responsibility', 'last_update_time'])
for page in range(1, 330):
print(f'正在獲取第{page}頁')
url = tengxun.get_url(page)
data = tengxun.get_json(url)
time.sleep(0.03)
df1 = get_info(data)
df = pd.concat([df, df1])
df = df.reset_index(drop=True)
# pprint.pprint(data)
df.to_csv('../data/騰訊招聘.csv', encoding='utf-8-sig')
最后結果
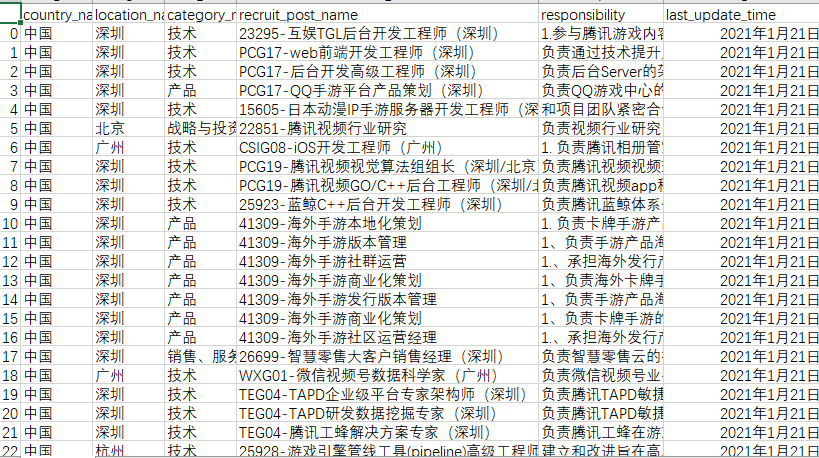
-
網站
+關注
關注
2文章
259瀏覽量
23213 -
字符串
+關注
關注
1文章
585瀏覽量
20578 -
數組
+關注
關注
1文章
417瀏覽量
26004 -
JSON
+關注
關注
0文章
119瀏覽量
6999
發布評論請先 登錄
相關推薦


在Python中高效使用JSON的四種方法
示波器的使用方法(三):示波器的使用方法詳解
什么是JSON劫持 JSON和XML的區別
什么是JSON JSON的語法規則
JSON工具簡介及安裝使用方法說明
645儀表以JSON格式上發方法





 工商網監
工商網監
評論