 知識圖譜與大模型結合方法概述
知識圖譜與大模型結合方法概述
本文作者 | 黃巍
《Unifying Large Language Models and Knowledge Graphs: A Roadmap》總結了大語言模型和知識圖譜融合的三種路線:1)KG增強的LLM,可在LLMs的預訓練和推理階段引入KGs;2)LLM增強KG,LLM可用于KG構建、KG embedding、KG補全、基于KG的文本生成、KBQA(基于圖譜的問答)等多種場景;3)LLM+KG協同使用,主要用于知識表示和推理兩個方面。該文綜述了以上三個路線的代表性研究,探討了未來可能的研究方向。
知識圖譜(KG)和大語言模型(LLM)都是知識的表示形式。KG是符號化的知識庫,具備一定推理能力,且結果可解釋性較好。但存在構建成本高、泛化能力不足、更新難等不足。LLM是參數化的概率知識庫,具備較強語義理解和泛化能力,但它是黑盒模型,可能編造子虛烏有的內容,結果的可解釋性較差。可見,將LLM和KG協同使用,同時利用它們的優勢,是一種互補的做法。
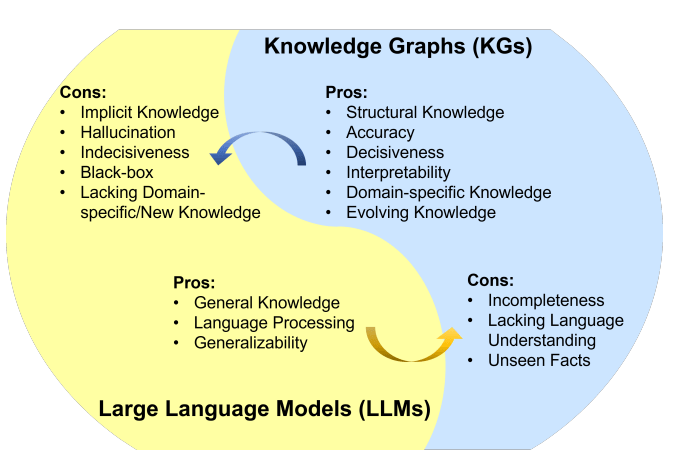
LLM和KG的融合路線,可分為以下類型:
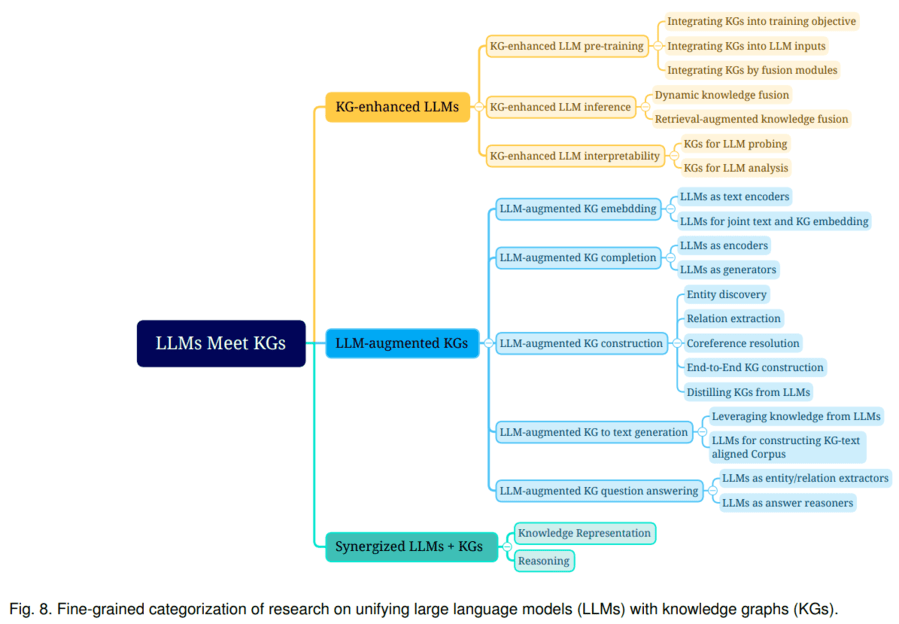
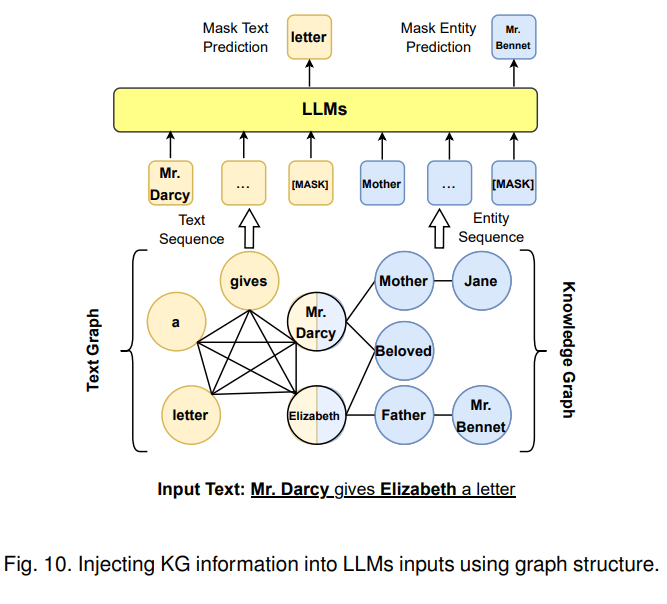
第一種融合路線是KG增強LLM,可在LLM預訓練、推理階段引入KG。以KG增強LLM預訓練為例,一個代表工作是百度的ERNIE 3.0將圖譜三元組轉換成一段token文本作為輸入,并遮蓋其實體或者關系來進行預訓練,使模型在預訓練階段直接學習KG蘊含的知識。
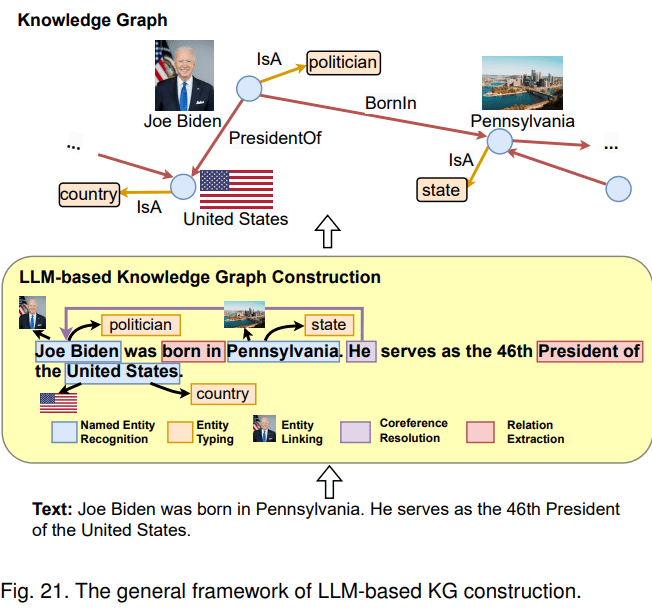
第二種融合路線是LLM增強KG。LLM可用于KG構建、KG embedding、KG補全、基于KG的文本生成、KBQA(基于圖譜的問答)等多種場景。以KG構建為例,這是一項成本很高的工作,一般包含1) entity discovery 實體挖掘 2) coreference resolution 指代消解 3) relation extraction 關系抽取任務。LLM本身蘊含知識,且具備較強的語義理解能力,因此,可利用LLM從原始數據中抽取實體、關系,進而構建知識圖譜。
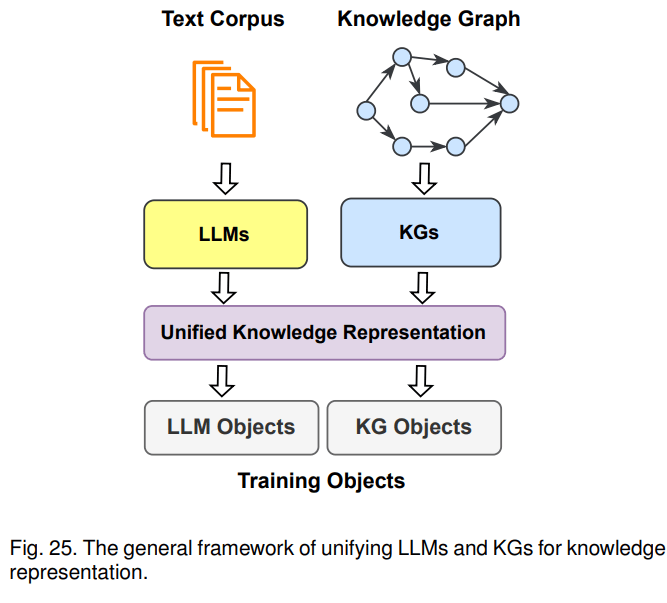
第三種融合路線是KG+LLM協同使用,主要用于知識表示和推理兩個方面。以知識表示為例,文本語料庫和知識圖譜都蘊含了大量的知識,文本中的知識通常是非結構化的,圖譜里的知識則是結構化的,針對一些下游任務,需要將其對齊進行統一的表示。比如,KEPLER是一個統一的模型來進行統一表示,它將文本通過LLM轉成embedding表示,然后把KG embedding的優化目標和語言模型的優化目標結合起來,一起作為KEPLER模型的優化目標,最后得到一個能聯合表示文本語料和圖譜的模型。示意圖如下:

小結
上述方法都在嘗試打破LLM和KG兩類不同知識表示的邊界,促使LLM這種概率模型能利用KG靜態的、符號化的知識;促使KG能利用LLM參數化的概率知識。從現有落地案例來看,大模型對知識的抽象程度高,泛化能力強,用戶開箱即用,體驗更好。且如果采用大模型+搜索的方案,用戶更新知識的成本也較低,往知識庫加文檔即可。在實際業務場景落地時,如果條件允許,優先考慮使用大模型。當前chatGPT火爆,也印證了其可用性更好。如遇到以下場景時,可以考慮將LLM和KG結合使用:
?對知識可信度和可解釋性要求高的場景,比如醫療、法律等,可以考慮再建設知識圖譜來降低大模型回答錯誤知識的概率,提高回答的可信度和可解釋性。
?已經有一個蘊含豐富知識的圖譜,再做大模型建設時。可以參考KG增強LLM的方法,將其知識融合到LLM中。
?涉及基于圖譜的多條推理能力的場景。
?涉及基于圖譜可視化展示的場景,比如企查查、天眼查等。
參考文獻:
1.Unifying Large Language Models and Knowledge Graphs: A Roadmaphttps://arxiv.org/abs/2306.08302
原文標題:知識圖譜與大模型結合方法概述
文章出處:【微信公眾號:華為DevCloud】歡迎添加關注!文章轉載請注明出處。
-
華為
+關注
關注
216文章
34530瀏覽量
252603
原文標題:知識圖譜與大模型結合方法概述
文章出處:【微信號:華為DevCloud,微信公眾號:華為DevCloud】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
微軟發布《GraphRAG實踐應用白皮書》助力開發者
利智方:驅動企業知識管理與AI創新加速的平臺
傳音旗下人工智能項目榮獲2024年“上海產學研合作優秀項目獎”一等獎

三星自主研發知識圖譜技術,強化Galaxy AI用戶體驗與數據安全
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
三星電子將收購英國知識圖譜技術初創企業
知識圖譜與大模型之間的關系
Al大模型機器人
大模型應用之路:從提示詞到通用人工智能(AGI)
澳鵬入選億歐大模型基礎層圖譜,以優質數據賦能AGI智能涌現

【大語言模型:原理與工程實踐】大語言模型的應用
利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(下)

利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(上)





 工商網監
工商網監
評論