 怎樣使用FHE實現加密大語言模型?
怎樣使用FHE實現加密大語言模型?
近來,大語言模型 (LLM) 已被證明是提高編程、內容生成、文本分析、網絡搜索及遠程學習等諸多領域生產力的可靠工具。
大語言模型對用戶隱私的影響
盡管 LLM 很有吸引力,但如何保護好 輸入給這些模型的用戶查詢中的隱私 這一問題仍然存在。一方面,我們想充分利用 LLM 的力量,但另一方面,存在向 LLM 服務提供商泄露敏感信息的風險。在某些領域,例如醫療保健、金融或法律,這種隱私風險甚至有一票否決權。
一種備選解決方案是本地化部署,LLM 所有者將其模型部署在客戶的計算機上。然而,這不是最佳解決方案,因為構建 LLM 可能需要花費數百萬美元 (GPT3 為 460 萬美元),而本地部署有泄露模型知識產權 (intellectual property, IP) 的風險。
Zama 相信有兩全其美之法: 我們的目標是同時保護用戶的隱私和模型的 IP。通過本文,你將了解如何利用 Hugging Face transformers 庫并讓這些模型的某些部分在加密數據上運行。完整代碼見 此處。
全同態加密 (Fully Homomorphic Encryption,FHE) 可以解決 LLM 隱私挑戰
針對 LLM 部署的隱私挑戰,Zama 的解決方案是使用全同態加密 (FHE),在加密數據上執行函數。這種做法可以實現兩難自解,既可以保護模型所有者知識產權,同時又能維護用戶的數據隱私。我們的演示表明,在 FHE 中實現的 LLM 模型保持了原始模型的預測質量。為此,我們需要調整 Hugging Face transformers 庫 中的 GPT2 實現,使用 Concrete-Python 對推理部分進行改造,這樣就可以將 Python 函數轉換為其 FHE 等效函數。
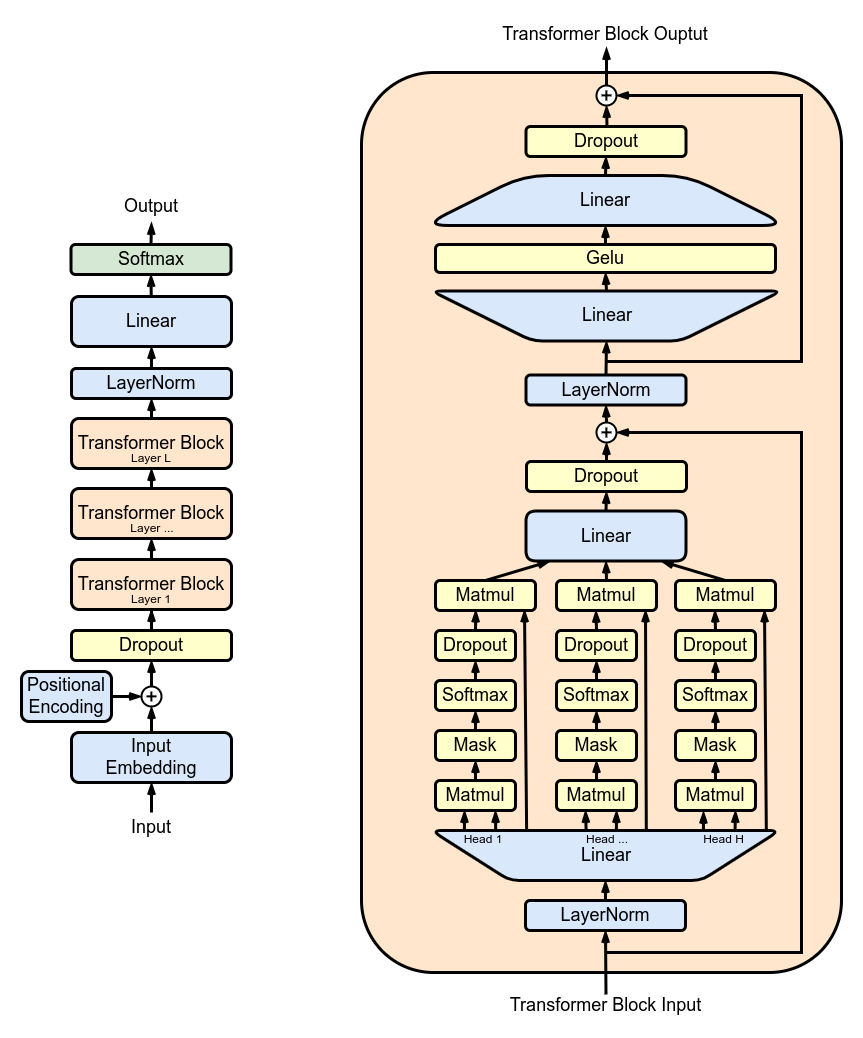
圖 1. GPT2 架構;
圖 1 展示了由多個 transformer block 堆疊而成的 GPT2 架構: 其中最主要的是多頭注意力 (multi-head attention,MHA) 層。每個 MHA 層使用模型權重來對輸入進行投影,然后各自計算注意力,并將注意力的輸出重新投影到新的張量中。
在 TFHE 中,模型權重和激活均用整數表示。非線性函數必須通過可編程自舉 (Programmable Bootstrapping,PBS) 操作來實現。PBS 對加密數據實施查表 (table lookup,TLU) 操作,同時刷新密文以支持 任意計算。不好的一面是,此時 PBS 的計算時間在線性運算中占主導地位。利用這兩種類型的運算,你可以在 FHE 中表達任何子模型的計算,甚至完整的 LLM 計算。
使用 FHE 實現 LLM 的一層
接下來,你將了解如何加密多頭注意力 (MHA) 中的一個注意力頭。你可以在 此處 找到完整的 MHA 實現代碼。

圖 2. 在 FHE 中運行 LLM 模型的某些部分
圖 2 概述了一個簡化的底層實現。在這個方案中,模型權重會被分成兩個部分,分別存儲在客戶端和服務端。首先,客戶端在本地開始推理,直至遇到已第一個不在本地的層。用戶將中間結果加密并發送給服務端。服務端對其執行相應的注意力機制計算,然后將結果返回給客戶端,客戶端對結果進行解密并繼續在本地推理。
量化
首先,為了對加密值進行模型推理,模型的權重和激活必須被量化并轉換為整數。理想情況是使用 訓練后量化,這樣就不需要重新訓練模型了。這里,我們使用整數和 PBS 來實現 FHE 兼容的注意力機制,并檢查其對 LLM 準確率的影響。
要評估量化的影響,我們運行完整的 GPT2 模型,并讓其中的一個 LLM 頭進行密態計算。然后我們基于此評估權重和激活的量化比特數對準確率的影響。
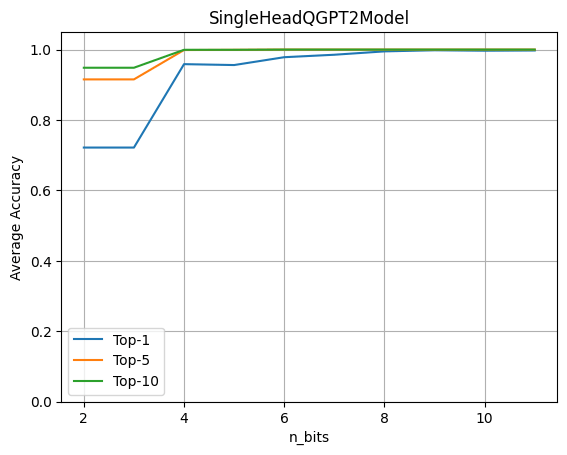
單注意力頭量化的平均 top-k 準確率
上圖表明 4 比特量化保持了原始精度的 96%。該實驗基于含有約 80 個句子的數據集,并通過將原始模型的 logits 預測與帶有量化注意力頭的模型的 logits 預測進行比較來計算最終指標。
在 Hugging Face GPT2 模型中使用 FHE
我們需要在 Hugging Face 的 transformers 庫的基礎上重寫加密模塊的前向傳播,以使其包含量化算子。首先通過加載 GPT2LMHeadModel 構建一個 SingleHeadQGPT2Model 實例,然后手動使用 QGPT2SingleHeadAttention 替換第一個多頭注意力模塊,代碼如下。你可以在 這里 找到模型的完整實現。
self.transformer.h[0].attn=QGPT2SingleHeadAttention(config,n_bits=n_bits)
至此,前向傳播已被重載成用 FHE 算子去執行多頭注意力的第一個頭,包括構建查詢、鍵和值矩陣的投影。以下代碼中的 QGPT2 模塊的代碼見 此處。
classSingleHeadAttention(QGPT2): """Classrepresentingasingleattentionheadimplementedwithquantizationmethods.""" defrun_numpy(self,q_hidden_states:np.ndarray): #ConverttheinputtoaDualArrayinstance q_x=DualArray( float_array=self.x_calib, int_array=q_hidden_states, quantizer=self.quantizer ) #Extracttheattentionbasemodulename mha_weights_name=f"transformer.h.{self.layer}.attn." #Extractthequery,keyandvalueweightandbiasvaluesusingtheproperindices head_0_indices=[ list(range(i*self.n_embd,i*self.n_embd+self.head_dim)) foriinrange(3) ] q_qkv_weights=... q_qkv_bias=... #ApplythefirstprojectioninordertoextractQ,KandVasasinglearray q_qkv=q_x.linear( weight=q_qkv_weights, bias=q_qkv_bias, key=f"attention_qkv_proj_layer_{self.layer}", ) #Extractthequeries,keysandvales q_qkv=q_qkv.expand_dims(axis=1,key=f"unsqueeze_{self.layer}") q_q,q_k,q_v=q_qkv.enc_split( 3, axis=-1, key=f"qkv_split_layer_{self.layer}" ) #Computeattentionmechanism q_y=self.attention(q_q,q_k,q_v) returnself.finalize(q_y)
模型中的其他計算仍以浮點形式進行,未加密,并由客戶端在本地執行。
將預訓練的權重加載到修改后的 GPT2 模型中,然后調用 generate 方法:
qgpt2_model=SingleHeadQGPT2Model.from_pretrained( "gpt2_model",n_bits=4,use_cache=False ) output_ids=qgpt2_model.generate(input_ids)
舉個例子,你可以要求量化模型補全短語 “Cryptography is a” 。在 FHE 中運行模型時,如果量化精度足夠,生成的輸出為:
“Cryptography is a very important part of the security of your computer”
當量化精度太低時,您會得到:
“Cryptography is a great way to learn about the world around you”
編譯為 FHE
現在,你可以使用以下 Concrete-ML 代碼編譯注意力頭:
circuit_head=qgpt2_model.compile(input_ids)
運行此代碼,你將看到以下打印輸出: “Circuit compiled with 8 bit-width”。該配置與 FHE 兼容,顯示了在 FHE 中執行的操作所需的最大位寬。
復雜度
在 transformer 模型中,計算量最大的操作是注意力機制,它將查詢、鍵和值相乘。在 FHE 中,加密域中乘法的特殊性加劇了成本。此外,隨著序列長度的增加,這些乘法的數量還會呈二次方增長。
而就加密注意力頭而言,長度為 6 的序列需要 11622 次 PBS 操作。我們目前的實驗還很初步,尚未對性能進行優化。雖然可以在幾秒鐘內運行,但不可否認它需要相當多的計算能力。幸運的是,我們預期,幾年后,硬件會將延遲提高 1000 倍到 10000 倍,使原來在 CPU 上需要幾分鐘的操作縮短到 ASIC 上的低于 100 毫秒。有關這些估算的更多信息,請參閱 此博文。
總結
大語言模型有望使能大量應用場景,但其實現引發了用戶隱私的重大關切。在本文中,我們朝著密態 LLM 邁出了第一步,我們的最終愿景是讓整個模型完全在云上運行,同時用戶的隱私還能得到充分尊重。
當前的做法包括將 GPT2 等模型中的特定部分轉換至 FHE 域。我們的實現利用了 transformers 庫,用戶還能評估模型的一部分在加密數據上運行時對準確率的影響。除了保護用戶隱私之外,這種方法還允許模型所有者對其模型的主要部分保密。你可在 此處 找到完整代碼。
Zama 庫 Concrete 和 Concrete-ML (別忘了給我們的 github 代碼庫點個星星 ) 允許直接構建 ML 模型并將其轉換至等價的 FHE 域,從而使之能夠對加密數據進行計算和預測。
審核編輯:劉清
-
計算機
+關注
關注
19文章
7532瀏覽量
88437 -
python
+關注
關注
56文章
4807瀏覽量
84940 -
GPT
+關注
關注
0文章
358瀏覽量
15462 -
pbs
+關注
關注
0文章
10瀏覽量
14922
原文標題:使用FHE實現加密大語言模型
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應用
c語言實現des加密算法詳細過程





 工商網監
工商網監
評論