 SQL常用語句篇
SQL常用語句篇
一、所謂SQL
SQL (Structured Query Language) 是具有數據操縱和數據定義等多種功能的數據庫語言,這種語言具有交互性特點,能為用戶提供極大的便利,數據庫管理系統應充分利用SQL語言提高計算機應用系統的工作質量與效率...巴拉巴拉。相信大家對SQL語言都有一定的認知,這里就不多贅述了。
二、常用語句
1、SELECT all columns with LIMIT
數據分析過程中,我們常常會有對數據的內容或格式做預覽的需求,在不明確查詢要求的情況下,通常會做SELECT *操作來執行全部結果,LIMIT n命令可以幫助我們獲取到之行結果的前n條,減少執行時間和內存。

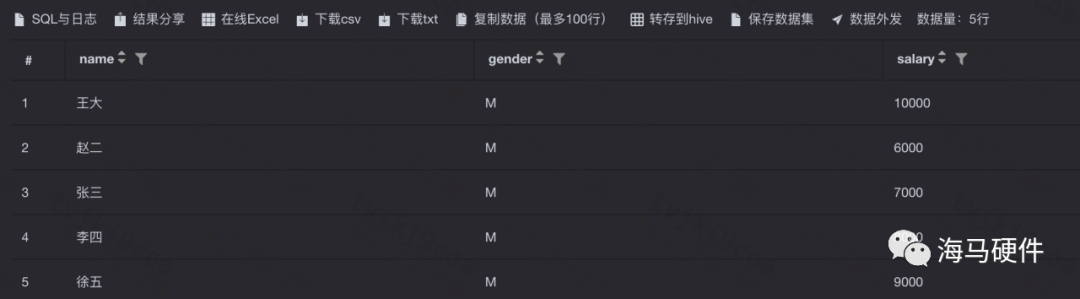
2、Distinctclause
Distinct可以對查詢字段的執行結果Unique,如下
未執行Distinctclause:

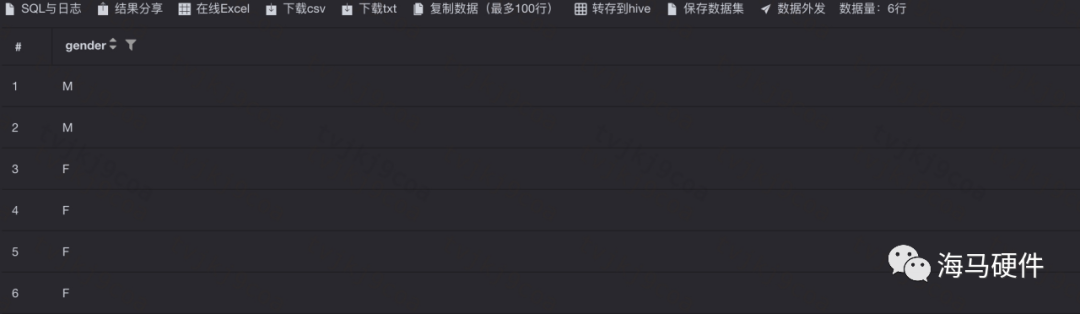
執行Distinctclause:


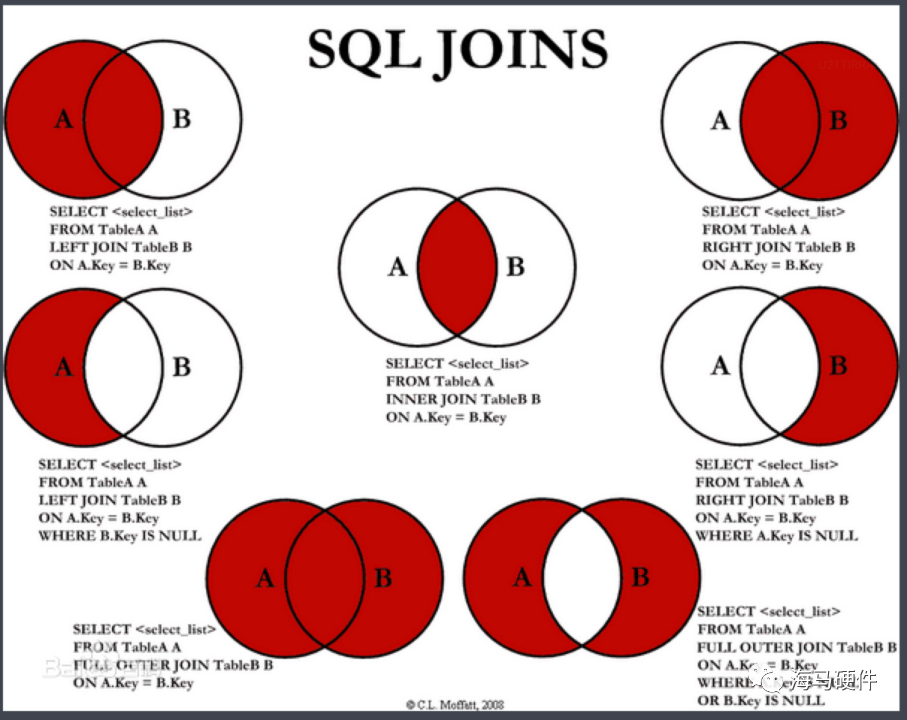
3、joins
包括笛卡爾積、內積、外積、Self Join等。具體使用方法如下
linner join可以輸出兩個表或者更多表中共同的行,類似數學中的韋恩圖,取兩個集合的交集
lLeft join僅僅輸出左邊表中的所有行,輸出結果中右邊表不存在的值為Null
lRight join僅僅輸出右邊表中的所有行,輸出結果中左邊表不存在的值為Null
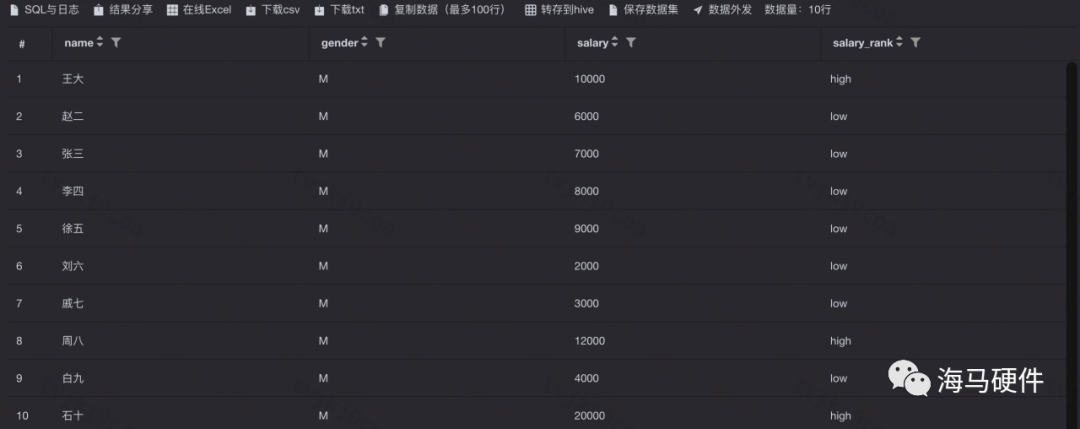
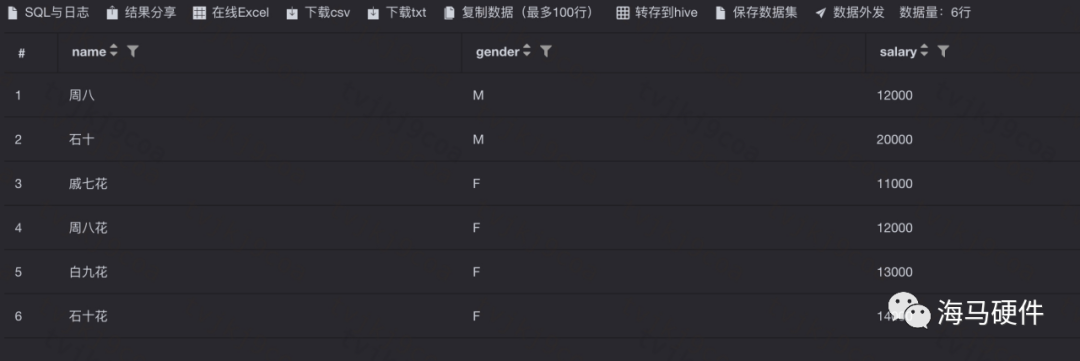
4、Case When clause
可以讓我們根據現有的數據生成一些新的列,類似于Python中的if-else語法。
例如,基于salary字段條件生成新列”salary_rank”

5、Sub-queries
即子查詢,如下查詢所有工資高于‘王大’的人的全部字段

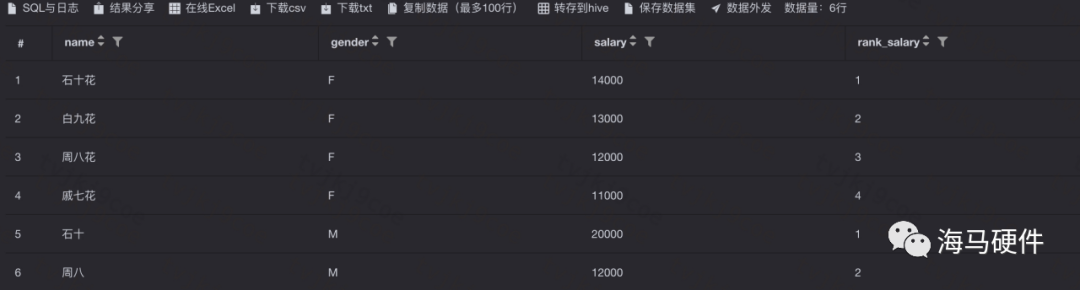
6、Ranking functions
lrow_nubmer(),這個排序函數的特點是相同數據,先查出的排名在前,沒有重復值。先查出來的數據的rank排名優先。partition by相當于分組查詢。desc是降序
lBTW-說下rank()和row_nubmer()的區別,rank()函數是跳躍排序,相同數據排名相同,比如并列第1,則兩行數據都標為1,下一位將是第3名.中間的2會被直接跳過。排名會有重復值

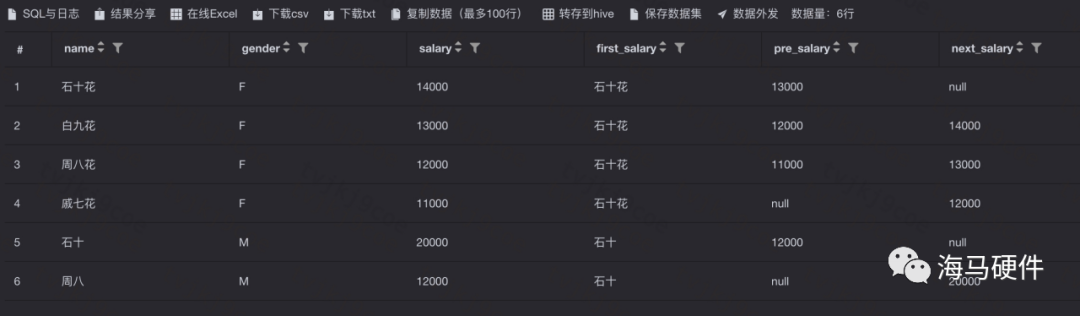
7、Analytic functions
即分析函數,常用的有:
lfirst_value和last_value取的是排序后的數據截止當前行的第一行數據和最后一行數據
lLag和Lead分析函數可以在一次查詢中取出當前行后N行和前N行的數據。第一個參數為列名,第二個參數為往后/前第n行(可選,默認為1),第三個參數為默認值(當往上第n行為NULL時候,取默認值,如不指定,則為NULL)

8、Aggregate functions
即聚合函數,SUM, AVG, MAX, MIN, COUNT等。
需要注意的是聚合函數需要通過‘group by’分組,確定最小聚合維度


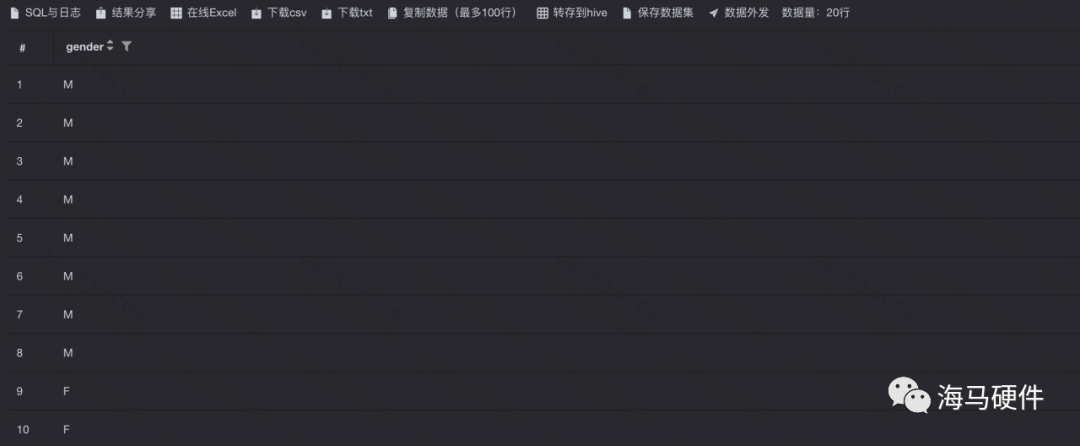
9、Union & union all
lUnion & union all二者都是對多個列數、列名、列字段類型相同的數據集進行組合,產出成一個數據集的function
l區別是union會對結果數據集進行去重,相當于distinct,而union all會做全部結果集并集產出,不會去除重復行
union示例:


union all示例:

審核編輯:劉清
-
SQL
+關注
關注
1文章
773瀏覽量
44219 -
python
+關注
關注
56文章
4807瀏覽量
84959
原文標題:SQL速成秘籍-常用語句篇
文章出處:【微信號:海馬硬件,微信公眾號:海馬硬件】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論