

ChatGPT、LLaMa等大型語言模型(LLMs)在自然語言處理領域帶來的革命性進步。通過有監督微調(SFT)的訓練方式,這些模型擁有強大的上下文學習能力,在各種任務中都展現了超凡的表現。然而,它們也有一個不小的問題——龐大的存儲空間和高昂的計算資源成本。
但現在,研究人員們為我們帶來了一項新的解決方案——SortedNet。它允許我們在一個大型模型內創建多個“子模型”,每一個都有自己專門的任務責任區。這意味著我們可以根據自己的需求和可用資源來選擇適合的子模型,從而大幅度減少存儲空間和計算資源的需求。
而這一切的背后,是一項名為Sorted Fine-Tuning(SoFT)的新訓練技術。SoFT讓我們可以在一個訓練周期內產出多個子模型,無需任何額外的預訓練步驟。此外,這項技術還揭示了模型的中間層也能夠產生高質量的輸出,這一點在之前的研究中常常被忽視。
為了證明這種方法的有效性,研究人員使用了LLaMa 2 13B和Stanford Alpaca數據集進行測試和驗證。他們不僅對比了SFT和SoFT這兩種方法,還創建了多個不同層次的子模型來確定哪些層最能產出高質量的結果。測試結果令人鼓舞——使用SoFT創建的子模型不僅運行速度更快,而且能夠保持或甚至超越原始模型的性能水平。
讓我們一起深入了解一下SortedNet和SoFT技術吧!

Paper:Sorted LLaMA: Unlocking the Potential of Intermediate Layers of Large Language Models for Dynamic Inference Using Sorted Fine-Tuning
Link:https://arxiv.org/abs/2309.08968
Many-in-One LLMs
在介紹這篇研究之前,先讓我們了解一下什么是Many-in-One。
深度神經網絡通常存在過多的參數,導致模型部署的成本增加。此外,在實際應用中,這些過度參數化的深度神經網絡需要為具有不同需求和計算預算的客戶提供服務。為了滿足這些多樣化的需求,可以考慮訓練不同大小的模型,但這將非常昂貴(涉及訓練和內存成本),或者另一種選擇是訓練Many-in-One網絡。
Many-in-One解決方案是在一個神經網絡模型內部包含多個子網絡,每個子網絡可以執行不同的任務或具有不同的結構。這個方法的目標是將多個任務或模型結構整合到一個統一的網絡中,從而提高模型的通用性和適應性。例如:
早期退出(Early Exit):在訓練過程中,Early Exit在除了最后的預測層之外,還在網絡的特定中間層上添加了額外的預測頭。這些預測頭在需要時提供中間預測,可以實現更快的推斷速度。
層丟棄(Drop Layer),通過在訓練期間隨機丟棄層來訓練具有任意深度的網絡。
最近,LLMs引起了廣泛的關注。為了使LLMs適應這些多樣化的需求,研究者提出了兩種適應方法:參數高效調整(PEFT)和模型壓縮。
PEFT:核心主干模型保持不變,而只更新一些適配器參數。這些適配器的作用就像是在LLMs上進行微調,使其適應不同的任務和需求。有一些PEFT的變種,比如LoRA、KRONA、Adapter、DyLoRA、Ladder Side-Tuning和Compacter等。這些方法可以讓LLMs更加靈活,但仍然無法提供動態大小的LLMs。
模型壓縮:在模型壓縮中,大型模型通過知識蒸餾、修剪和量化等壓縮方法來減小尺寸。這些方法可以生成不同尺寸的模型,但需要分別對每個壓縮模型進行訓練,而且它們也不是多合一模型。
現在,再回到Many in one LLMs的概念。這是一種非常有趣的想法,它們可以同時適應多種不同的任務和需求。但到目前為止,我們還沒有看到發布的多合一LLM模型。因此,在這項研究中,研究人員將一種SortedNet的訓練方法應用到LLaMA 13B模型上,這將成為第一個Many in one LLM。
方法
這項研究的方法涉及將大型語言模型(LLMs)轉化為多合一模型,靈感來自SortedNet方法,主要步驟如下:
形成子網絡:首先需要將LLMs劃分為多個子網絡。子網絡的深度(即前n層的子模型)用fn(x; θn)表示。在這項研究中,選擇的語言模型是LLaMA2 13B,總共包括40層。因此,定義了一系列不同層數的子網絡,如12層、16層、20層等。
計算子網絡的輸出:每個子模型的輸出將通過使用原始網絡最后一層的共享輸出預測頭來進行預測。需要注意的是,在LLaMA模型中,輸出預測頭之前存在一個RMSNorm層,該歸一化層被添加到每個子模型的共享預測頭之前。研究人員認為,這種歸一化對于Sorted LLama在所有子模型上更好地泛化至關重要。
目標函數:為了訓練這些子網絡,定義了每個子模型的損失函數Ln(x; θn)。總損失L是所有子模型和主模型的損失之和。
訓練數據集:在這項研究中,使用了Stanford Alpaca數據集,該數據集包含了5.2萬個指令跟隨示例的演示。
評估:除了評估最后一層的嵌入質量外,還評估了從第1到第n個塊的中間輸出的嵌入質量。Panda-LM基準用于比較不同子模型的輸出。Panda-LM使用一個大型語言模型來評估來自兩個源的生成文本的質量。最終的評估結果包括勝利次數、失敗次數和驗證集中的平局次數。最終得分是通過特定的公式計算出來,表示模型在指令跟隨任務上的性能,得分范圍在-1到1之間。
Baseline:作者對LLama2 13B模型進行了微調,采用了兩種不同的設置作為基線:常規監督微調(SFT)和排序微調(SoFT)。其中,常規監督式微調是常見做法,主要關注網絡的最后一層的訓練。在這種情況下,只對網絡的最后一層進行微調。排序微調(SoFT)下,計算從第12層到第40層(最后一層)的多個輸出的損失,分為四個間隔,并同時訓練多個模型,就像在前面的部分中解釋的那樣。
實驗結果
對于生成模型的不同層排序信息的影響是什么?
研究者首先關注了在不同層次的生成模型中對信息進行排序的效果。他們進行了一系列實驗,生成了不同層次的響應,并使用PandaLM評估器進行了成對比較。結果顯示,Sorted Fine-Tuning對于將學到的知識傳遞到中間層具有顯著影響。在自動評估中,Sorted LLaMA在幾乎所有層次上都表現出色,遠遠超過了常規微調(SFT)。
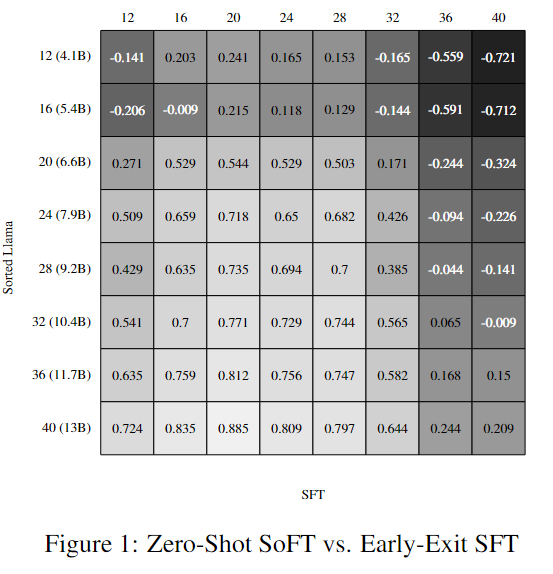
需要注意的是,盡管對SoFT的性能進行了zero-shot評估,但為了更好地理解SFT層次的結果,研究者進行了額外的訓練——對每個子模型的分類層進行訓練。可以注意到,與Sorted LLaMA的第12層相比,SFT的第12層性能略好。下表是一個生成的回復例子,可以看到SFT中較早層的生成文本大多是亂碼的。當我們進入SFT中的較高層時,生成的文本變得越來越有意義,這使得與Sorted LLAMA層的比較更加合理。
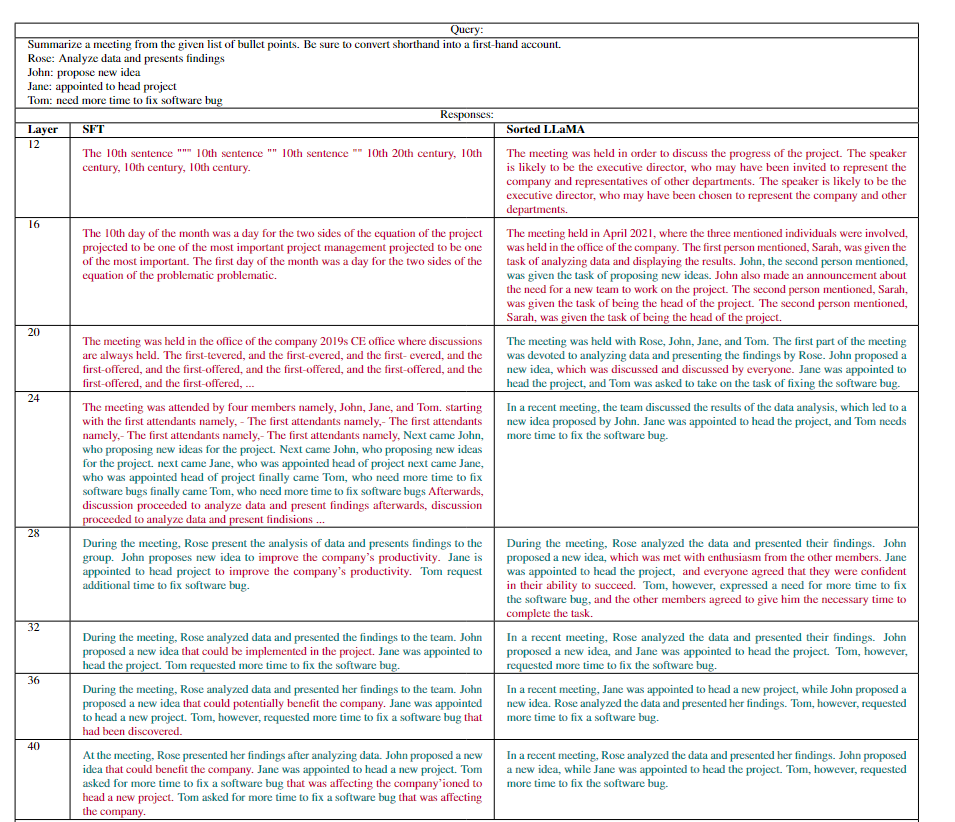
這一部分的實驗結果呈現出了Sorted Fine-Tuning對于LLama2模型性能的積極影響,尤其是在中間層次的性能上,這為后續的研究提供了重要基準。
此外,結果還突顯了Sorted Fine-Tuning能夠生成性能強大且尺寸較小的子模型,這些子模型與原始模型的性能相媲美。在接下來的圖表中,研究者進行了SFT和SoFT在不同條件下的評估,結果顯示,無論是零-shot還是Early-Exit,兩種方法的結果幾乎沒有變化。這些實驗證明了Sorted Fine-Tuning的魯棒性和有效性。
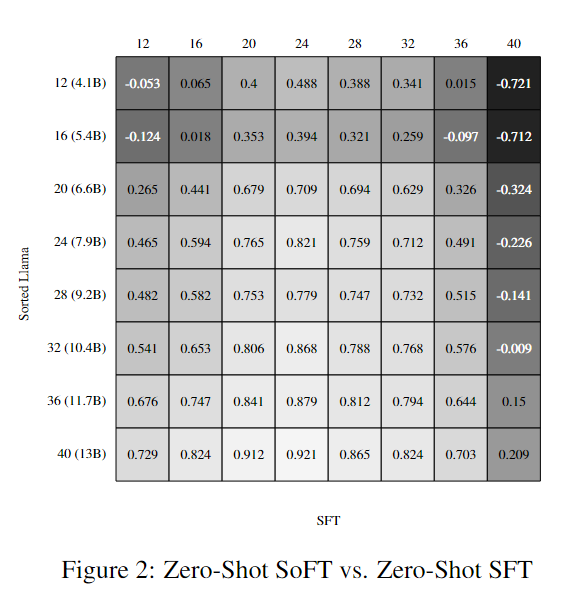
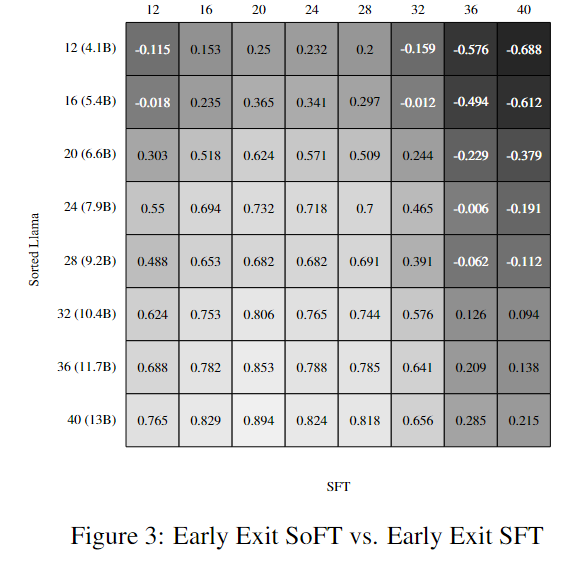
結果分析
SoFT和SFT學習到的概率分布對比
研究者使用Kullback-Leibler(KL)散度作為度量標準來衡量兩個概率分布之間的相似性。
下圖(a)比較了Sorted LLaMA和SFT子模型在不同輸出位置上的概率分布。首先,圖(a)左展示了與SFT模型的最后一層以及從第12層到第36層的層次之間的比較。可以明顯看出,與生成初始標記后的最后一層相比,即使在較高的層次,如36和32,輸出分布迅速發散。需要注意的是,這種評估是在zero-shot方式下生成的,沒有調整分類器頭。
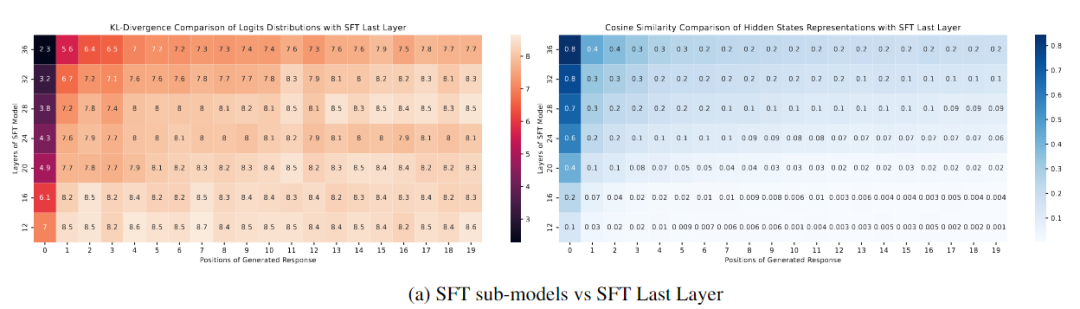
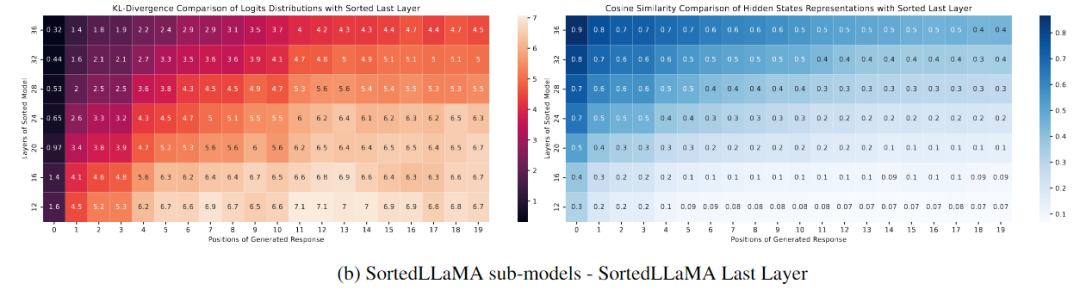
下圖(b)顯示了在Sorted LLaMA中,隨著我們靠近最后一層,生成結果的可能性分布越來越接近完整尺寸子模型,至少在生成文本的初始位置上是如此。
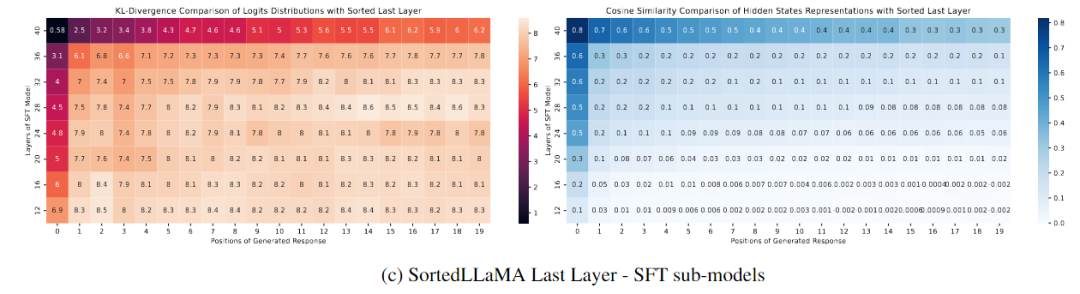
下圖(c)展示了不同SFT層次與最后一個Sorted LLaMA層次之間的比較。圖中顯示,只有SFT的完整尺寸輸出分布接近排序的完整尺寸模型,而其他層次的分布在生成文本的初始步驟中與SoFT相比迅速發散。
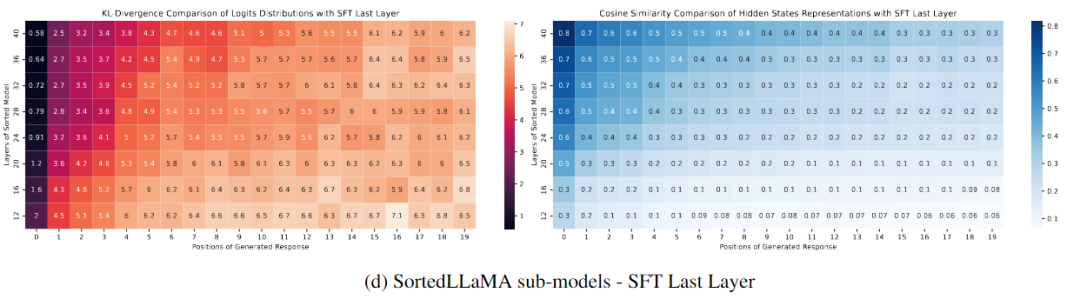
圖(d)比較了所有排序層次的輸出分布與最后一個SFT層次的輸出分布。與圖4c(左)相比,圖4d(左)顯示Sorted LLaMA甚至在較低層次的初始輸出標記上也能保持與SFT完整尺寸模型接近的輸出分布。
總結
這項工作提出了Sorted LLaMA,它是一種基于Sorted Fine-Tuning而不是監督微調獲得的多合一LLaMA模型,用于動態推理。Sorted LLaMA釋放了中間層的潛在表示能力,提供了無需預訓練或與模型壓縮相關的額外開銷的動態自適應能力。它為NLP領域中生成語言模型的優化提供了有前途的途徑。
SoFT使這些模型的部署更加高效。由于所有子模型仍然是原始模型的組成部分,因此存儲要求和不同計算需求之間的過渡成本最小化,使得在推理期間管理多個模型成為現實。
這些分析結果揭示了Sorted Fine-Tuning對于生成模型的輸出分布的影響,特別是在不同的模型層次上,以及Sorted LLaMA在保持輸出分布方面的能力。這些結果有助于更深入地理解Sorted Fine-Tuning方法的效果。
-
華為
+關注
關注
216文章
34824瀏覽量
254213 -
模型
+關注
關注
1文章
3440瀏覽量
49621 -
語言模型
+關注
關注
0文章
552瀏覽量
10512 -
ChatGPT
+關注
關注
29文章
1580瀏覽量
8440
原文標題:華為提出Sorted LLaMA:SoFT代替SFT,訓練多合一大語言模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【飛騰派4G版免費試用】仙女姐姐的嵌入式實驗室之五~LLaMA.cpp及3B“小模型”OpenBuddy-StableLM-3B
【大語言模型:原理與工程實踐】大語言模型的預訓練
Multilingual多語言預訓練語言模型的套路
一種基于亂序語言模型的預訓練模型-PERT
基于預訓練模型和語言增強的零樣本視覺學習

Meta發布一款可以使用文本提示生成代碼的大型語言模型Code Llama

大語言模型(LLM)預訓練數據集調研分析

大語言模型簡介:基于大語言模型模型全家桶Amazon Bedrock
Meta推出最強開源模型Llama 3 要挑戰GPT
Llama 3 語言模型應用

用Ollama輕松搞定Llama 3.2 Vision模型本地部署






 工商網監
工商網監

評論