 如何用機器學習模型打擊虛擬貨幣犯罪?
如何用機器學習模型打擊虛擬貨幣犯罪?
歷經十五年的發展,區塊鏈技術以完整的技術生態系統重塑千行百業,其廣泛應用也為金融、醫療、物流等多個領域帶來巨大變革。但凡事皆有兩面性,技術向善,也能為惡。
區塊鏈技術在普及應用的同時,也滋生了一系列的安全風險,尤以涉虛擬貨幣犯罪為重。此類新型科技犯罪形式,不僅對人民及社會的安全造成了嚴重威脅,也對現有法律和執法提出了全新挑戰。本文主要講述了我們如何用機器學習模型來打擊虛擬貨幣違法犯罪行為。
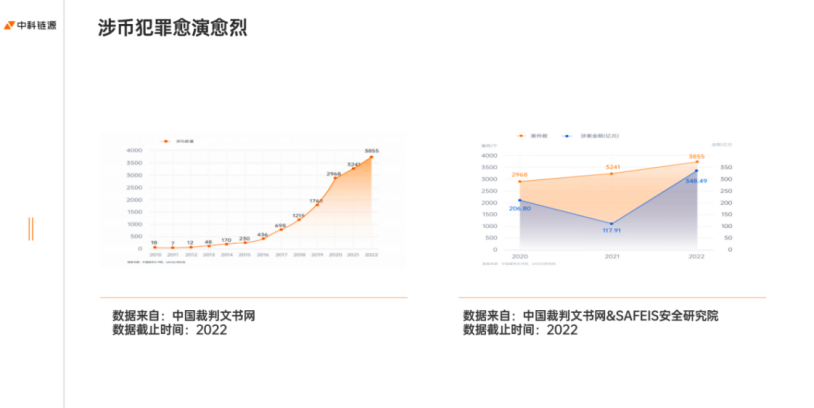
圖 1:數據顯示,涉幣犯罪愈演愈烈
區塊鏈:“黑暗森林”的形成
區塊鏈技術的核心特點是去中心化、匿名性,參與區塊鏈交易的真實主體難以追蹤,犯罪分子在鏈上自由交易,不必擔心執法小隊的追蹤獵殺。
圖 2:區塊鏈技術:去中心化、安全透明、可追溯的分布式賬本技術
虛擬貨幣具有去中心化、無法監管、無國界、跨境限制、交易無限制和交易低成本的特征。不僅如此區塊鏈技術還為犯罪分子提供了豐富的手段來隱匿蹤跡、抵擋追蹤。“混幣器、隱私幣”等的出現,進一步增強了其匿名性,為犯罪分子創造了毀滅追蹤路徑的“迷霧地帶”。違法犯罪活動多以穩定幣 USDT(泰達幣)為主要犯罪媒介,此外也常見于通過 BTC(比特幣)、ETH(以太坊)、XRP(瑞波幣)、XMR(門羅幣)等虛擬貨幣作為載體的犯罪行為。
盡管區塊鏈技術為不法分子實施犯罪帶來諸多便利,但鏈上交易數據完全公開透明的特性,也為涉幣案件的分析研判提供了海量數據。很多安全專家試圖將分析傳統法幣犯罪案件的實戰經驗,應用在鏈上交易數據分析。但鑒于區塊鏈技術的獨特性,這些傳統方法仍需與時俱進優化。
涉幣案件的偵破流程耗時很長,一個案件從獲取線索到結案,通常會超過半年。為了提升結案成果率,案件的線索階段就需廣撒網、多線跟蹤,這對于辦案人員的分析產出質量與時效要求甚高。辦案人員不僅需要具備深厚的區塊鏈技術知識,也要深刻了解犯罪分子的行為模式與作案策略,門檻較高。目前,業內優秀的辦案人員實屬稀缺。為更高效精準打擊涉幣犯罪,執法領域在招募并培養復合型涉幣案件辦案人員的同時,要不斷引進相關創新技術進行賦能,進一步提升偵破能力。
利用大數據和機器學習技術來分析海量鏈上數據,幫助發現人力難以識別的線索,從而找到犯罪分子的蹤跡”,已成為當前打擊涉虛貨幣犯罪領域創新探索與方法研究的重要而前沿的方向,并在業內釋放了巨大的應用價值與潛能。
機器學習如何用于涉幣犯罪分析
機器學習新技術已在合規領域尤其是金融犯罪風險防控方面,如金融風險評估、反洗錢等場景有了較為廣泛的應用。近年來,業內不斷布局探索圖計算技術的動作,旨在進一步提升模型表現。
相較基于人工經驗主觀判斷的風險評估系統,機器學習模型的優勢在于:
最大限度利用獲取的信息,發現人力難以找到的規律。如在反洗錢領域,機器學習技術這一優勢得到充分發揮。洗錢活動往往涉及復雜的交易鏈和隱蔽的資金流向,機器學習模型通過對大量交易數據進行分析,可自動識別出可疑的交易模式與行為,從而幫助金融機構及時發現和阻止洗錢犯罪;
判斷更加精準高效,擺脫人工經驗的主觀性。如在金融風險評估中,傳統方法十分依賴人工經驗主觀判斷,效率低下,且僅能針對劃分出的人群進行粗略判斷;機器學習技術可以自動為每位客戶甚至每筆交易進行分析推斷,生成風險評分,并且確保這些評分均基于完整和準確的信息客觀計算產出,精準度和可靠性極大提升;
數據資源是人工智能發展的驅動力之一。隨著數據量的快速增長和技術的飛速進步,機器學習模型可不斷進行迭代優化,從而確保其表現始終處于最佳狀態。
上述機器學習模型,在傳統金融安全領域發揮的優勢,同樣也可在涉幣案件偵查中發揮巨大作用。我們基于區塊鏈交易特征進行迭代完善,形成了圖計算機器學習模型,并將其應用于涉幣案件偵查平臺的實戰后,證實卓有成效。
圖計算模型:判斷涉案地址關聯度
在涉虛擬幣新型網絡犯罪案件中,起始線索地址往往是犯罪活動的初始資金歸集地址。以涉幣網絡賭博案件為例,該地址可能是用于歸集賭客充值兌換籌碼資金的地址,以此線索地址作為追蹤犯罪團伙,開展偵查工作的實戰開端,但從起始線索地址追蹤到犯罪團伙的各個核心職能地址,中間分析過程可能涉及數十萬個相關聯的地址。如何在這些大量地址中,準確又快速找到相關性最強的可疑地址,是偵查工作突破的關鍵。
傳統的人工偵查方法存在以下痛點:
主要依賴人工操作,偵查效率低下,且容易出錯。由于人本身的能力有限,即使投入大量人力成本,去追蹤覆蓋數十萬個地址的可能性也微乎其微;
展開鏈上節點數量、層級有限。由于技術與資源的限制,傳統偵查方法往往只能展開有限的節點數量和層級(最多 3 層),這樣的實戰節奏可以窺見,追蹤到犯罪團隊的核心地址并不明朗。
人力能夠并行處理的特征數量少。依靠人工經驗,往往只能綜合考慮有限的主要特征(5-10 個),無法同時考慮更多維度特征。
人為主觀因素影響巨大。優秀的涉幣案件分析師人才十分稀缺,已從業人員專業水平參差不齊,業內也并沒有形成公認的標準偵查方法并培訓普及,每個辦案人員的方法與歷史實戰經驗均不相同,便會導致結果因人而異;即使擁有培訓經歷,分析師也只能綜合考慮 5-10 個標準化的主要特征,且每個人基于自身經驗賦予各特征的權重也不一樣,也會造成結果因人而異。
所有機器學習產品功能的成功落地應用,皆是一個公司“業務、算法和工程”三方實力的綜合體現,三者相輔相成。圖計算模型的成功開發落地,首先根植于案件分析師團隊依托大量案例實踐沉淀的業務理解。在近一年多的時間里,分析師們通過借鑒大量傳統法幣案件的偵破經驗,并結合虛擬幣交易的特征,針對幾十起具體涉幣案件的情況深入分析研判,積累了極具價值的“特征判定規則”。這些規則可以幫助分析師更加準確地判斷虛擬貨幣交易是否涉及犯罪行為,以及發現和追蹤可疑交易。人力發掘出案件中的可疑涉案地址后,通過警方向交易所調取涉案地址的身份與交易信息,進一步確認了結果的準確性,并根據結果來修正“特征判定規則”。
涉案團伙分工明確,資金歸集、洗錢、收益發放、資金沉淀和兌換等各類職能劃分清晰,此類多層級的組織結構和交易行為模式形成了復雜的網絡關系。應用風險管理領域最前沿的圖計算模型,可以將涉案團伙的成員、職能以及交易活動等數據信息整合成“點和邊”的形式呈現,從而構建出復雜的不限層級的全幣種全鏈路的網狀圖,并自動學習其中包含信息;此外,網圖的拓撲結構也釋放了高價值信息,可以深入揭示出團伙內部的組織關系、資金流動路徑以及犯罪收益的分配情況等關鍵線索與證據。

圖 3:涉幣網絡賭博案件的資金流轉脈絡
模型實現步驟
圖計算模型實現的步驟如下:
1.搜索提取全量交易數據。首先獲取一個起始線索地址,通常是一個案件初始資金的歸集地址。從數據庫中搜索并提取從該地址出發的所有下游交易,可根據案件類型靈活設置向后搜索的層級。隨著搜索層級的增加,對計算資源要求也呈指數加大,但并不會發現更多高價值的涉案地址,增量價值遞減;
2.根據交易數據構建網圖(Graph)。網圖的“節點”是交易對手方的地址,“邊”是兩個地址之間的交易關系,鏈路則是一個起始地址到一個終點地址之間的交易通路。起始線索地址與任意一個終點地址之間,可能存在多條不同長度的鏈路。這將構建一個包含數十萬節點與邊的復雜網絡。
3.提取特征。生成網圖后,按照鏈路維度,從鏈路中每個地址和每筆交易中提取關鍵特征。這里,我們主要用到了 5 大類,共計超過 100 個特征,包括:
地址資金余額相關特征:比如平均賬戶余額、賬戶余額的標準差、最新余額等;
交易模式相關特征:比如平均交易頻率、交易頻率的標準差、交易總次數、交易間隔等;
交易金額相關特征:比如除了均值、中位數、標準差等,還有異常大額交易等;
交易時間特征:比如時間戳分布(是否有特定的交易活動時間段),交易時間重合度等;
社交網絡相關特征:用戶的連接度(用戶連接的其他用戶數量),用戶的社交網絡位置(中心性),用戶所屬社群的數量等。
4.模型訓練。搭建基于特征的規則模型,并用機器學習方法不斷迭代規則閾值和注意力權重。規則模型為特征進行打分,最后加權求和,得出各鏈路分數,再根據鏈路數量、各鏈路分數,綜合計算出起始線索地址與某個終點地址之間的“關聯度”。
5.結果產出。計算從起始線索地址到所有終點地址的“關聯度”并進行排序,關聯度最高的終點地址,就是高度可疑的涉案地址,用戶可以針對這些涉案地址進行下一步的分析偵查,比如發函向其所在的交易所要求調取證據。
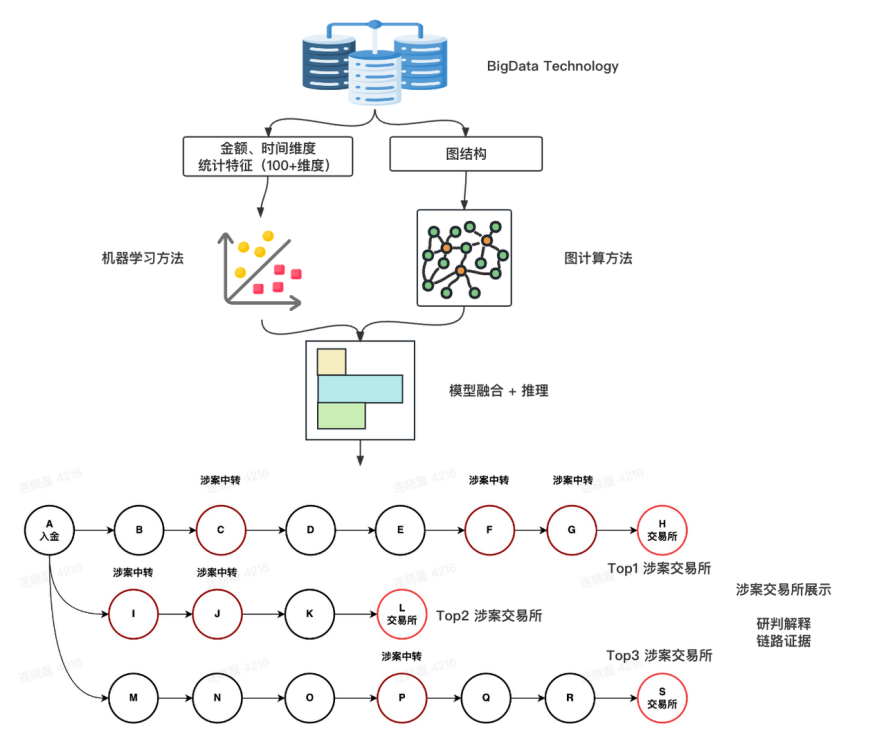
圖 4:多特征圖計算模型
能快速實現上述大規模計算,主要依賴區塊鏈大數據積累。區塊鏈 AI 安全廠商中科鏈源自建了三大區塊鏈(以太坊、幣安智能鏈和波場鏈)的全節點,并實時將交易數據解析處理,以確保數據的及時性和準確性,同時,為提高數據的安全性與可靠性,將數據存儲到實時和離線兩套數據庫中,便于后續的數據分析和挖掘,這樣就擁有了從鏈的創世區塊到最新的所有完整交易數據的優勢;并且根據模型特征計算需求,在數倉中建立了按天更新的業務中間表,以確保數據的新鮮度和準確性,同時提高計算效率,在接到用戶發出的計算任務后,調用中間表,在 30 分鐘內完成計算并產出結果。
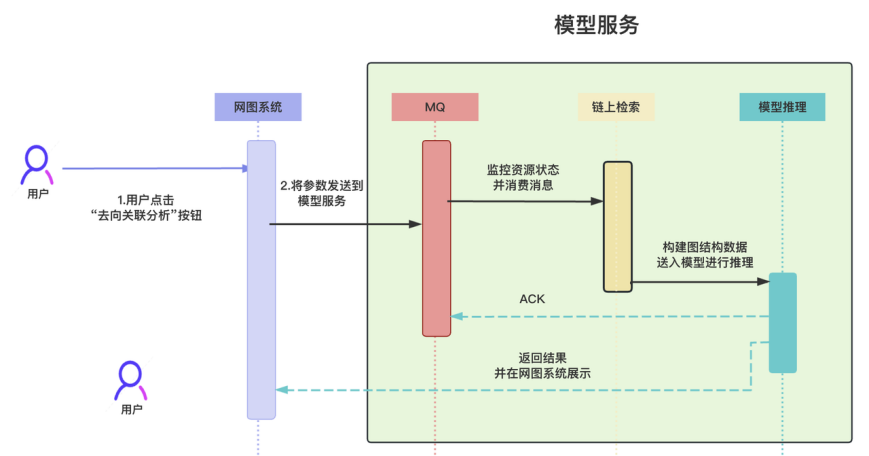
圖 5:用戶使用去向關聯分析功能,體驗多特征圖計算模型服務
模型結果計算完畢后,中科鏈源自研的 SAFEIS 安士區塊鏈 AI 信息作戰系統會為用戶呈現計算結果。作戰系統的核心組件是以區塊鏈交易資金流向形成的網狀分析視圖,在這里,用戶可以點擊任意地址,對其有交易關聯的相關地址進行展開,從而形成巨大的網狀圖,便于追蹤分析。該組件的使用場景與圖計算模型的功能高度匹配,所以模型功能便深度融合到此數智執法產品的核心組件中。用戶通過右鍵菜單,可以對任意地址調用模型,來計算其資金關聯高的涉案地址,并將結果也展示在網狀圖上,直觀揭示出犯罪行為的動態演變過程,方便進一步研判分析。
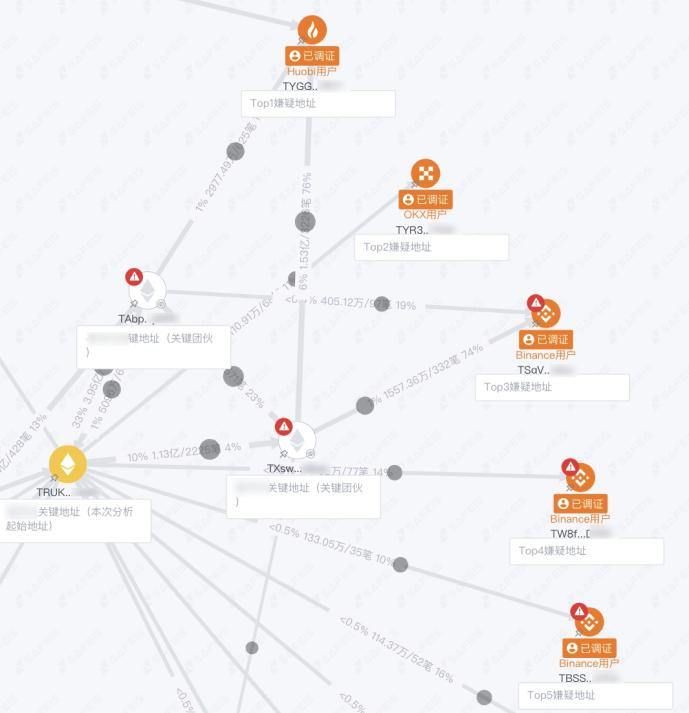
圖 6:調用模型功能計算資金關聯高的涉案地址
機器學習模型在涉幣資金分析中的優勢和效果
機器學習模型可以自動快速處理和分析海量鏈上數據,減少人工參與的需求,極大提高效率。模型可以突破人類能夠處理的信息極限,分析范圍可覆蓋到數十萬的下游節點,并自動從數據中提取有用的特征,同時綜合考慮多種特征進行分析,如統計特征、圖特征等,進而提供相較于單純依賴人工分析更為全面和準確的分析結果。最后,模型的決策基于數據和算法,如此避免了人工由于能力、經驗參差不齊或主觀判斷等因素造成的結果不穩定。
功能上線后,我們與幾位資深分析師合作,將模型投入到新案件的實戰中驗證效果。針對每個起始線索地址,我們用模型計算出 Top30 的可疑涉案地址,相關度從高到低排列。同時由分析師自行通過人工分析,再對比雙方結果。
偵查案件對準確性與時效性的要求很高,關鍵在于快速找到一定數量的高質量線索進行突破,而無需費時找齊所有涉案線索,因此我們在評估中重點關注準確率,忽略了召回率。由于網絡復雜,人工也難以窮盡所有節點,評估召回率則異常困難。
從準確率來看,模型計算的 Top3 中,有 60% 左右的地址與人工分析的結果匹配,準確率符合預期;此外,另有 15% 的地址,沒有通過人工找到,但經驗證后發現相關度很高,這部分是模型的增量價值,可以發現人力難以察覺的信息。
模型功能開發難點攻堅
在模型的開發過程中,我們遇到以下主要難點:
1.源數據查詢性能壓力。
隨著模型搜索分析覆蓋的范圍增加(深入到 5 層就有幾十萬個地址節點、千萬級別的交易數據),導致查詢性能壓力劇增,對性能優化和分析策略提出較高要求。
對此,我們優化了 SQL 查詢邏輯,首先基于對案件特點的理解,合理設置了數據查詢的限制條件,盡可能在數據源頭提前篩除信息價值不高的數據。此外,我們還建立了精簡高效的臨時表,從根本上改進了查詢性能。
2.特征計算壓力。
在獲取了幾十萬個地址節點、千萬級別的交易數據后,需要構建出網狀圖,并且需根據這些數據計算出上百個特征,包括統計特征和圖特征,這使得數據處理和分析計算量巨大。
對此,我們引入了 Numpy 矩陣計算庫和 Networkx 圖特征計算庫。通過此類高效的計算庫,我們實現了高達 10 倍的計算速度提升。
3.不斷挖掘新特征,提升模型效果。
僅使用傳統的交易數據的統計特征,已很難達到理想效果,需要根據案件特征,來發掘更多的高質量特征,以提高模型的推斷能力。
對此,我們引入了圖特征,通過將網絡拓撲結構與數據融合,為模型提供了更多的高價值信息。此外,根據資深分析師的經驗,地址之間 gas fee 的流通也是其潛在關系的重要特征,在增加這一關鍵特征后,模型效果也得到了較大提升。
未來:模型迭代方向
目前,我們仍在積極與資深分析師團隊展開密切合作,試圖將該模型更多用于實戰,并在實踐中探索改進點。未來,我們探索的主要方向是挖掘尋找更多特征,提高模型的準確性和泛化能力,同時形成更完整的規則進行判斷,以幫助構建更強大的模型。
模型產品優化后,鑒于更多用戶的持續使用,并給模型結果進行評分,我們進而可以拿到更多有價值的標注數據,用來優化特征計算,優化機器學習方法,進一步迭代模型,提高模型性能與質量,賦能數智執法產品,從而為用戶提供更好的需求服務。
-
模型
+關注
關注
1文章
3298瀏覽量
49065 -
機器學習
+關注
關注
66文章
8438瀏覽量
132928 -
虛擬貨幣
+關注
關注
5文章
309瀏覽量
13355
原文標題:如何用機器學習模型打擊虛擬貨幣犯罪?
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
【「具身智能機器人系統」閱讀體驗】+數據在具身人工智能中的價值
NPU與機器學習算法的關系
具身智能與機器學習的關系
AI大模型與深度學習的關系
AI大模型與傳統機器學習的區別
構建語音控制機器人 - 線性模型和機器學習





 工商網監
工商網監
評論