 如何使用Kubernetes實現零停機應用程序
如何使用Kubernetes實現零停機應用程序
我在本地和托管 Kubernetes 集群方面工作了七年多。我能說的是,容器已經徹底改變了托管格局!它帶來了許多需要復雜設置的設施。擁有多個實例,具有滾動重啟、零停機、健康檢查等功能。以前真是費時費力(實現 VRRP 解決方案、使用 monit 之類的應用程序監控重啟、負載均衡 haproxy 之類的)!
因此,現在使用 Kubernetes 可以更輕松地訪問一切,但如果您想為應用程序的生命周期構建完美的設置,您仍然必須了解它的工作原理以及根據您的情況應遵循哪種策略。
在本文中,我將解釋為什么以及如何使用 Kubernetes 實現零停機應用程序。
容器鏡像位置
如果您已經使用Docker一段時間,那么這看起來很簡單。拉取和使用容器鏡像非常簡單。但是,在生產環境中,如果您不是映像所有者,您通常不想依賴遠程且不受控制的映像注冊表。為什么?
注冊表可能會消失,并且您無法再拉取鏡像( Kubernetes 上出現ImagePullBackOff錯誤)
您正在使用的圖像標簽已被刪除(相同的ImagePullBackOff錯誤)
圖像標簽沒有改變,但圖像內容不再相同(非不可變圖像,因此圖像哈希值不同)。集群的不同節點上的圖像之間的行為不相同(取決于標簽何時更改并在集群節點上拉取)
它不符合您要求控制這些圖像的安全要求(SOC2、HIPPA…)。
存在多種解決方案。一種是將容器映像從源注冊表同步到您自己的注冊表。
Pod 數量(應用程序實例)
這聽起來很明顯,但如果您正在尋求高可用性,則您的應用程序至少需要2 個 Kubernetes 副本(2 個 Pod)。例子:
apiVersion:apps/v1 kind:Deployment metadata: name:nginx spec: replicas:2#tellsdeploymenttorun2podsmatchingthetemplate template: ..
我多次聽到的關于 Kubernetes 的一個常見錯誤是:“我不需要兩個實例,因為 Kubernetes 執行滾動更新,因此它將在關閉當前實例之前啟動一個新實例”。確實如此,但它僅適用于部署更新!
以下是不適用此規則的其他場景:
當您丟失運行應用程序的節點時(節點崩潰、硬件故障......)。您的應用程序pod 必須從頭開始:
1/鏡像拉取(如果節點上尚未存在):拉取時間取決于鏡像大小
2/磁盤附件(如果有):需要幾秒鐘(通常觀察到最多 1 分鐘)
3/應用程序啟動:可能會有所不同,具體取決于受影響的資源和應用程序類型(Java 應用程序通常需要更長的時間才能啟動)
4 / probes:它們正在等待您的應用程序準備好提供服務,并增加了幾秒鐘的時間
當集群請求節點耗盡時(例如在 EKS 升級或節點類型更改期間):
要替換的節點上的 Pod 會收到SIGTERM信號以正常停止。Pod 正在從RUNNING狀態切換到TERMINATING狀態。此處,Kubernetes 服務已更新,以停止向TERMINATING pod 發送流量。因此,您不會再收到流量并且會出現停機時間。然后創建一個新的 Pod(請參閱上面的場景),在此期間,您不會收到任何流量。不幸的是,Kubernetes 在殺死一個 pod 之前不會啟動一個新的 pod。
這就是為什么設置兩個實例是避免停機的最低要求(另請參閱 Pod 反關聯性部分)。
Pod 中斷預算
PodDisruptionBudget (PDB) 是一個 Kubernetes 對象,它指定在部署、維護或任何給定時間不可用的 Pod 數量。這有助于確保您的應用程序保持可用,即使某些 pod 被終止或驅逐也是如此。
讓我們舉一個例子,我的應用程序有三個 pod(實例);我總是希望始終擁有至少兩個running;我可以應用一個 PDB 對象,這將保證我始終有至少兩個正在運行的 pod!
apiVersion:policy/v1 kind:PodDisruptionBudget metadata: name:my-pdb spec: maxUnavailable:1 selector: matchLabels: app:my-app
部署策略
Kubernetes 部署有兩種策略:
RollingUpdate:默認更新,部署順利。重新創建:在啟動較新版本的應用程序之前強制應用程序完全關閉。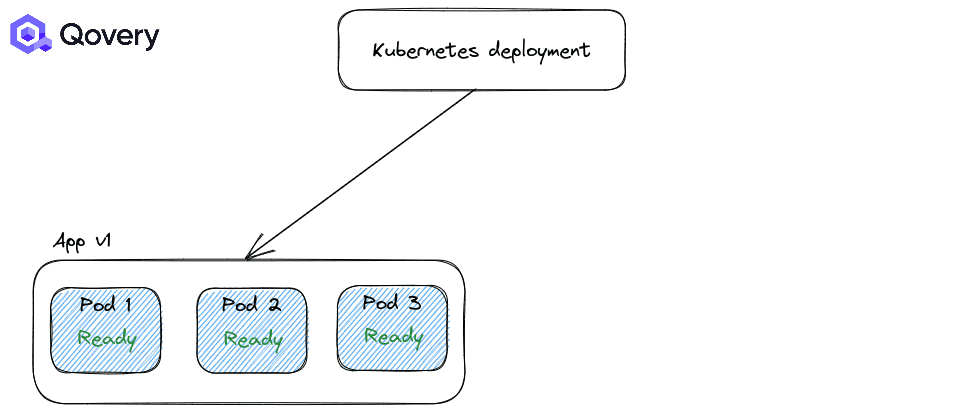
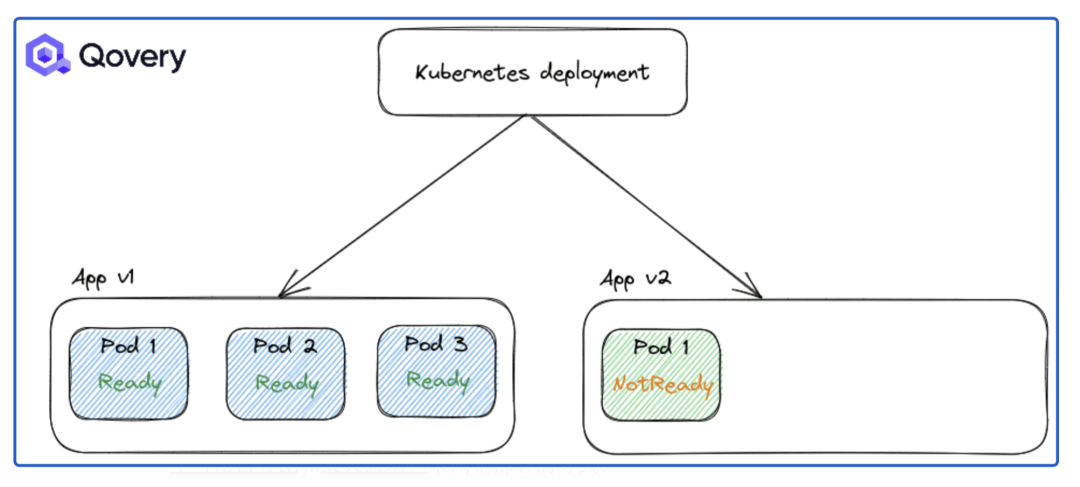
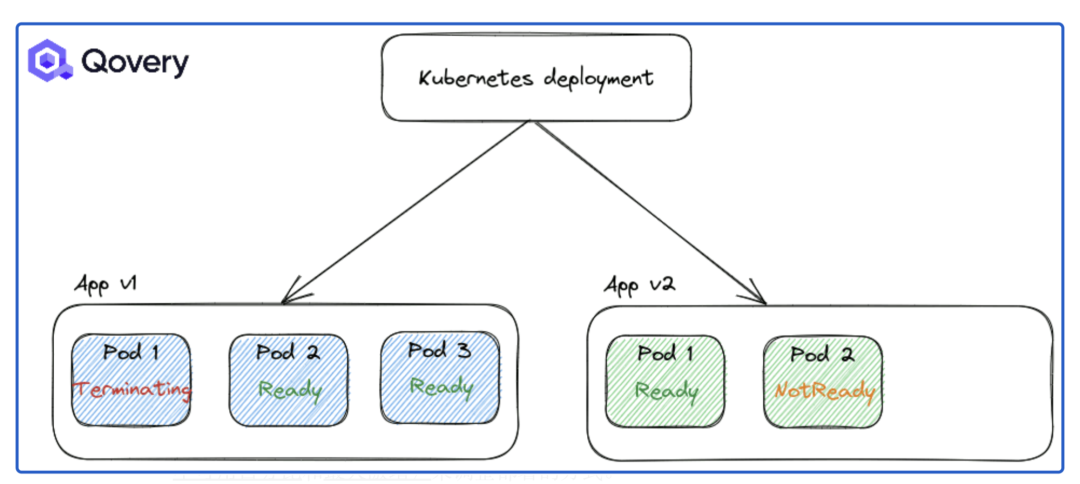
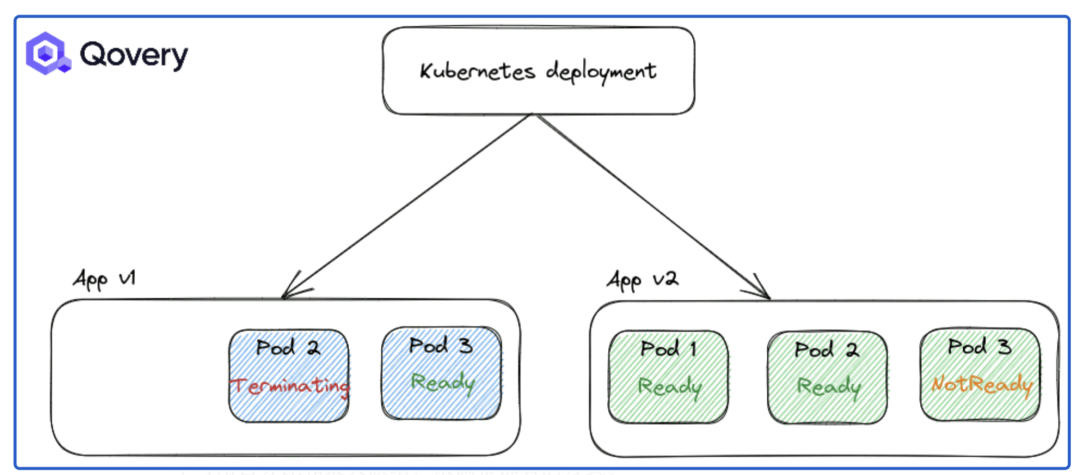
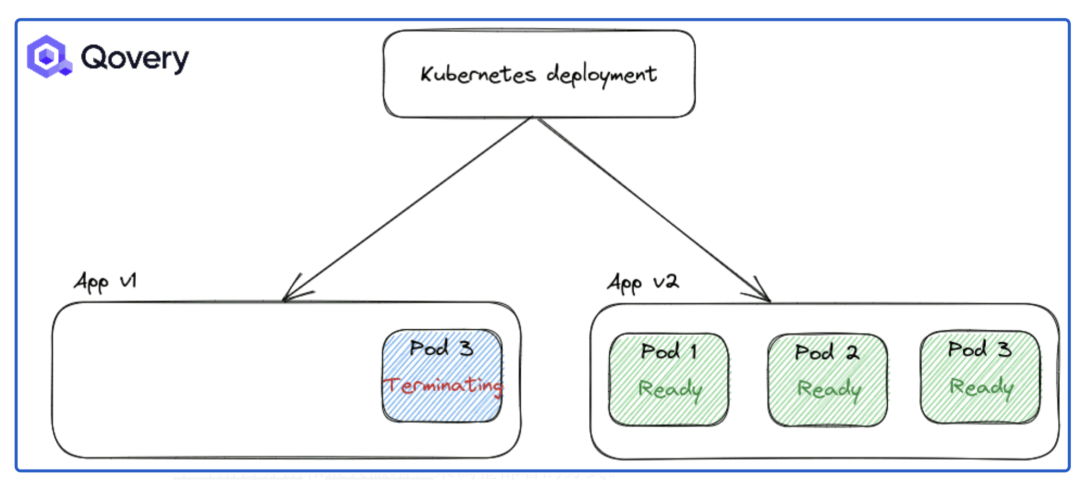
默認情況下,應用 RollingUpdate 策略。但是您可以使用其他選項(例如最大不可用百分比和最大激增)來調整部署的方式。當您面臨繁重的流量負載并且想要控制部署速度以最大程度地減少性能影響時,這些選項非常有用。
自動回滾部署
不幸的是,自動回滾并不是 Kubernetes 默認提供的功能。一般來說,您必須使用 Helm、ArgoCD、Spinnaker 等第三方工具才能實現自動回滾。
大多數人想要的很簡單:如果我的應用程序無法正常啟動,不要向其發送流量并回滾。
例如,對于 Helm,使用 Helm 實現它的一些選項很有趣:
— wait
— wait-for-jobs
— atomic
為了獲得運行良好的解決方案,必須設置并正確配置探針(請參閱下一節)。如果 pod 沒有通過其活性探針正常啟動,則會自動回滾。
Probe 探針
不幸的是,探針經常被低估,但它們對于實現零停機非常重要!
驗證應用程序健康狀況的兩個最重要的探測器是“Liveness”和“Readiness”探測器。比長篇大論更好的是,這里有一個解釋目標的模式:
Kubernetes 探針工作流程
Liveness探針可確保您的應用程序處于活動狀態,并將決定 pod 是存活還是死亡!
如果活性探測未成功:
Pod 停止接收流量
Pod 重新啟動,嘗試恢復健康狀態。任何進一步的重新啟動都會應用指數退避(指數延遲)
Readiness 探針決定是否將流量發送到您的 Pod。
如果您的流量出現突發(并且活性探針正在響應),但您的應用程序開始變慢,則就緒狀態可以決定停止向您的應用程序發送流量。讓它恢復到更加健康的狀態。
如果就緒探針沒有響應,則不會重新啟動您的 Pod。它僅請求負載均衡器停止向該 Pod 發送流量。
在什么情況下配置自定義活躍度和就緒度探測器有用?
答案是“永遠”!當然,您可以使用簡單的 TCP 檢查,但它永遠不會像您自己在應用程序中構建的自定義探針(例如,REST API 上的專用端點)那樣可靠。
初始啟動時間延遲
初始啟動時間可能需要延遲。它可能發生在不同的情況下:
您的應用程序使用大量 CPU 來啟動(例如 SpringBoot 應用程序)。
您的應用程序需要在啟動時執行比以前更多的操作(由于新功能),并且您沒有升級分配的 CPU 資源。
您的應用程序必須加載數據庫中的架構和其中的數據,并且在數據庫準備就緒之前它才可用。
還存在其他幾個例子……
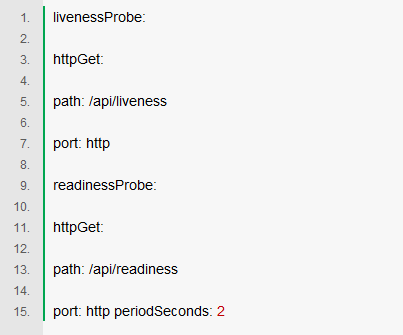
但這是可能發生片狀啟動的示例。如果您遇到這種情況或想要預見它,您應該像這樣更新initialDelaySeconds :
livenessProbe: initialDelaySeconds:60 httpGet: ...
注意:存在專用啟動探測器,但在大多數情況下可能沒有用。一般來說,initialDelaySeconds選項就足夠了。
優雅終止期 GrancePeriodSeconds
這個 Kubernetes 選項并不直接與零停機功能相關,而是更多地涉及忽略應用程序正常關閉的重要性的缺點效應。
僅當應用程序能夠攔截 SIGTERM時,優雅終止期才能起作用!如果應用程序未編碼為攔截 SIGTERM,則它只會硬終止應用程序,無論是否存在大于 30 秒的優雅終止期,這都可能導致數據丟失。
不管理 SIGTERM 可能會帶來幾個問題:
糟糕的用戶體驗:用戶遇到錯誤、空白頁面或更糟的情況
丟失數據:數據尚未提交,用戶事務丟失
不可恢復的數據:刷新磁盤上的數據突然停止,您的應用程序無法處理它
還存在其他原因,但您會看到讓應用程序足夠快地關閉是多么重要。
硬件故障總是有可能的,因此您的應用程序應該始終能夠在此類故障后恢復。然而,類似的常規故障不應頻繁發生。
多給你一點時間讓你的應用程序正常停止通常是很好的做法(<5 分鐘)。Kubernetes 默認值為 30 秒,但您可以使用終止GracePeriodSeconds 選項進行調整。
Pod 反親和力
Pod 反關聯性可讓您避免同一節點上存在同一應用程序 (Pod) 的多個實例。當所有實例都位于同一節點上時發生節點崩潰時,您可以想象會發生停機。
為了避免這種情況,您可以要求 Kubernetes 避免所有 pod 都位于同一節點上。存在兩個版本:
軟反親和性Soft Anti-Affinity
PreferredDuringSchedulingIgnoredDuringExecution:它將盡最大努力避免它,但如果它不能(缺乏資源),它將在同一節點上添加兩個實例。這個版本具有成本效益,并且在 95% 的情況下都能發揮作用。
Hard Anti-Affinity
requiredDuringSchedulingIgnoredDuringExecution:這將是一個硬性要求,不能在同一節點上有兩個 pod。但如果您要求同一應用程序有 50 個 pod,則需要 50 個節點。這很快就會變得非常昂貴。
這是它在 Kubernetes 上的樣子:
affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: -labelSelector: matchExpressions: -key:security operator:In values: -S1 topologyKey:topology.kubernetes.io/zone podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: -weight:100 podAffinityTerm: labelSelector: matchExpressions: -key:security operator:In values: -S2 topologyKey:topology.kubernetes.io/zone
資源
資源是最常見的問題之一。當設置的資源不足時,您的應用程序可以:
內存不足 (OOM) 并被內核驅逐。所以你會遇到停機、連接嚴重關閉等情況……
你設置的CPU夠用了嗎?您的應用程序可能需要很長時間才能響應,甚至有時在活動檢查成功之前無法啟動。運行 100% 的 CPU 可能會強制自動縮放程序添加過多的實例。而您只需要利用當前的 CPU 數量即可。除非您知道自己在做什么,否則低于 100m 通常不好。
自動縮放Autoscaling
自動縮放是避免流量負載下停機的好方法。默認基于CPU(可以使用其他自定義指標)。這是自動部署更多實例(Pod)的簡單方法。
自動縮放并不是魔法!您必須在 Kubernetes 上正確配置您的應用程序。
因此,例如,當您的 pod 短時間內運行超過 60% 的 CPU 時,Kubernetes 會觸發一個新的 pod 來處理負載并減少當前正在運行的應用程序的使用率。
以下是 Kubernetes 上的示例:
apiVersion:autoscaling/v2 kind:HorizontalPodAutoscaler spec: ... minReplicas:1 maxReplicas:10 metrics: -type:Resource resource: name:cpu target: type:Utilization averageUtilization:50
結論
Kubernetes 確實有神奇的作用,但只有當應用程序盡可能是云原生且配置正確時,它才能發揮神奇作用。
總之,當您想將應用程序引入 Kubernetes 時,您至少應該注意:
最少兩個實例
添加健康檢查(探針)
您的應用程序必須處理 Sigterm
配置自動縮放器
給予足夠的資源
使用 pod 反親和力
添加 PDB
如果一切設置正確,Kubernetes 體驗將令人難以置信,您將不會再遭受任何停機。
審核編輯:湯梓紅
-
容器
+關注
關注
0文章
499瀏覽量
22094 -
應用程序
+關注
關注
38文章
3292瀏覽量
57849 -
負載均衡
+關注
關注
0文章
113瀏覽量
12384 -
Docker
+關注
關注
0文章
492瀏覽量
11921 -
kubernetes
+關注
關注
0文章
227瀏覽量
8738
原文標題:結論
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Kubernetes 網絡模型如何實現常見網絡任務
用Delphi實現基于SAPI的電腦語音控制應用程序
利用FTP實現應用程序的遠程更新
在Windows 10上創建單節點的Kubernetes實施示例
首次部署 Kubernetes 應用程序需注意的“陷阱”
新版本Portworx PX-Backup助力Kubernetes有狀態應用程序實現跨云數據保護與遷移

Kubernetes網絡模型介紹以及如何實現常見網絡任務
KUBERNETES開源平臺的定義、工作原理及重要意義
Kubernetes網絡模型的基礎知識
跟蹤Kubernetes的網絡流量路徑
Commvault宣布擴展面向Kubernetes工作負載的保護
如何從零開發Kubernetes Operator?
探討使用YAML文件定義Kubernetes應用程序
Awesome 工具如何更好地管理Kubernetes
Jenkins pipeline是如何連接Kubernetes的呢?





 工商網監
工商網監
評論