 算力技術未來發展路徑概述(2023)
算力技術未來發展路徑概述(2023)
隨著人工智能、隱私計算、AR/VR以及基因測試/生物制藥等新型高性能計算應用的不斷普及,對算力的需求也不斷持續增加。比如,以ChatGPT為代表的大模型需要巨大算力支撐。大模型對算力的需求增速遠大于摩爾定律增速。
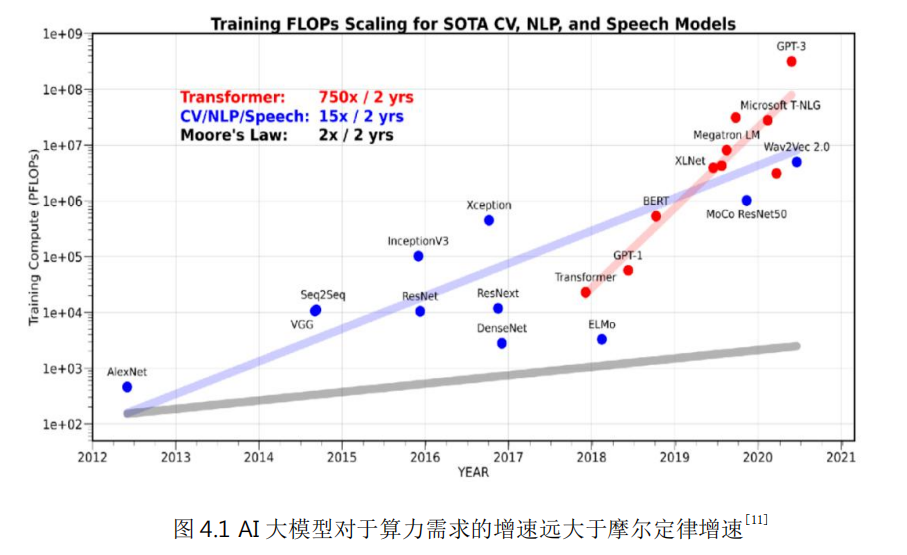
自微處理器誕生以來,算力的增長按摩爾定律發展,即通過增加單位芯片面積的門電路數量來增加處理器算力,降低處理器成本和功耗。但近年來這條路已經遇到越來越大的困難,通過持續縮微來提升性能已經無法滿足應用的需求。
1、More Moore:繼續追求更高的晶體管單位密度。比如晶體管工藝結構從鰭式結構FinFET到環形結構GAA,以及納米片、納米線等技術手段有望將晶體管密度繼續提升5倍以上。但這條路在成本、功耗方面的挑戰非常大。
2、Beyond CMOS:放棄CMOS工藝,尋求新材料和新工藝。比如使用碳納米管、二硫化鉬等二維材料的新型制備工藝,和利用量子隧穿效應的新型機制晶體管。但這條路徑的不確定性較大,離成熟還需要很長時間。
芯片架構:DSA & 3D堆疊& Chiplet
DSA針對特定領域的應用采用高效的架構,比如使用專用內存最小化數據搬移、根據應用特點把芯片資源更多側重于計算或存儲、簡化數據類型、使用特定編程語言和指令等等。與ASIC芯片(Application Specific Integrated Circuit,專用集成電路)相比,DSA芯片在同等晶體管資源下具有相近的性能和能效,并且最大程度的保留了靈活性和領域的通用性。
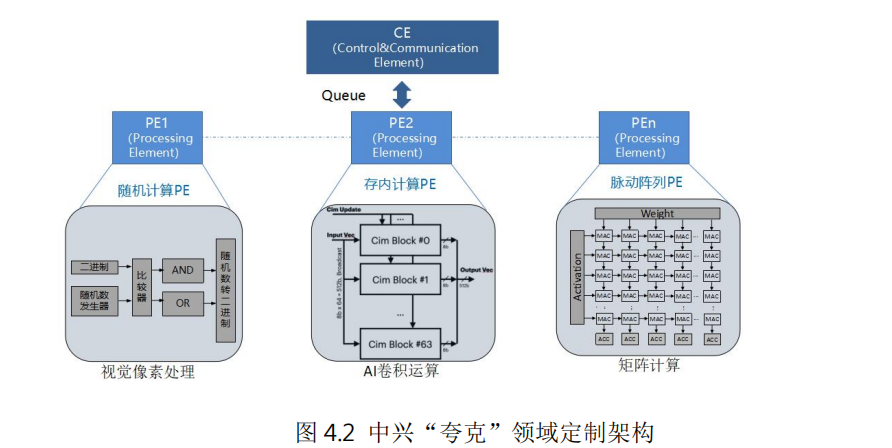
例如中興通訊提出的計算和控制分離的人工智能領域定制芯片架構“夸克”,針對深度神經網絡的計算特點,將算力抽象成張量、向量和標量引擎,通過獨立的控制引擎(CE)對各種PE引擎進行靈活編排和調度,從而可以高效實現各種深度學習神經網絡計算,完成自然語言處理、AI檢測、識別和分類等各種人工智能應用。由于采用軟硬件協同設計的定制化方案,DSA芯片在相同功耗下可以取得比傳統CPU高數十倍甚至幾百倍的性能。
摩爾定律本身是在2D空間進行評估的,隨著芯片微縮愈加困難,3D堆疊技術被認為是提升集成度的一個重要技術手段。3D堆疊就是不改變原本封裝面積情況下,在垂直方向進行的芯片疊放。這種芯片設計架構有助于解決密集計算的內存墻問題,具有更好的擴展性和能效比。
Chiplet技術被認為是延續摩爾定律的關鍵技術。首先Chiplet技術將芯片設計模塊化,將大型芯片小型化,可以有效提升芯片良率,降低芯片設計的復雜程度。其次,Chiplet技術可以把不同芯粒根據需要來選擇合適的工藝制程分開制造(比如核心算力邏輯使用新工藝提升性能,外圍接口仍采用成熟工藝降低成本),再通過先進封裝技術進行組裝,可以有效降低制造成本。
與傳統芯片方案相比,Chiplet模式具有設計靈活性、成本低、上市周期短三方面優勢。Chiplet技術面臨的最大挑戰是互聯技術,2022年3月2日,“UCIe產業聯盟”成立,致力于滿足客戶對可定制封裝互聯互通要求。Chiplet產業會逐漸成熟,并將形成包括互聯接口、架構設計、制造和先進封裝的完整產業鏈。
存算一體使得計算和存儲從分離走向聯合優化
存算一體技術就是從應用需求出發,進行計算和存儲的最優化聯合設計,減少數據的無效搬移、增加數據的讀寫帶寬、提升計算的能效比,從而突破現有內存墻和功耗墻的限制。
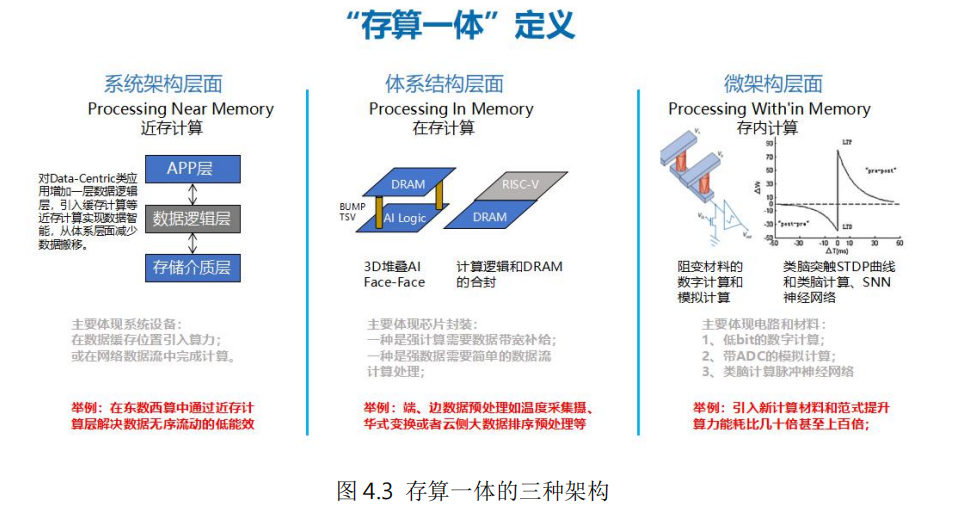
存算一體包含系統架構、體系結構和微架構多個層面。系統架構層面,在傳統計算和存儲單元中間增加數據邏輯層,實現近存計算,減少數據中心內、外數據低效率搬移,從系統層面提升計算能效比;體系架構層面,利用3D堆疊、異構集成等先進技術,將計算邏輯和存儲單元合封,實現在存計算,從而增加數據帶寬、優化數據搬移路徑、降低系統延時;微架構層面,進行存儲和計算的一體化設計,實現存內計算,基于傳統存儲材料和新型非易失存儲材料,在存儲功能的電路內同時實現計算功能,取得最佳的能效比。
(一)系統架構層面的近存計算(Processing Near Memory)
近存計算在數據緩存位置引入算力,在本地產生處理結果并直接返回,可以減少數據移動,加快處理速度,并提升安全性。通過對Data-Centric類應用增加一層數據邏輯層,整合原系統架構中的數據邏輯布局功能和應用服務數據智能功能,并引入緩存計算,從而減少數據搬移。在“東數西算”工程中,可以通過設置近存計算層,解決數據無序流動的低能效問題。
(二)體系架構層面的在存計算(Processing In Memory)
在存計算主要在存儲器內部集成計算引擎,這個存儲器通常是DRAM。其目標是直接在數據讀寫的同時完成簡單處理,而無需將數據拷貝到處理器中進行計算。例如攝氏和華氏溫度的轉換。在存計算本質上還是計算、存儲分離架構,只是將存儲和計算靠近設計,從而減少數據搬移帶來的開銷。目前主要是存儲器廠商在推動其產業化。
(三)微架構層面的存內計算(Processing Within Memory)
存內計算是把計算單位嵌入到存儲器中,特別適合執行高度并行的矩陣向量乘積,在機器學習、密碼學、微分方程求解等方面有較好的應用前景。
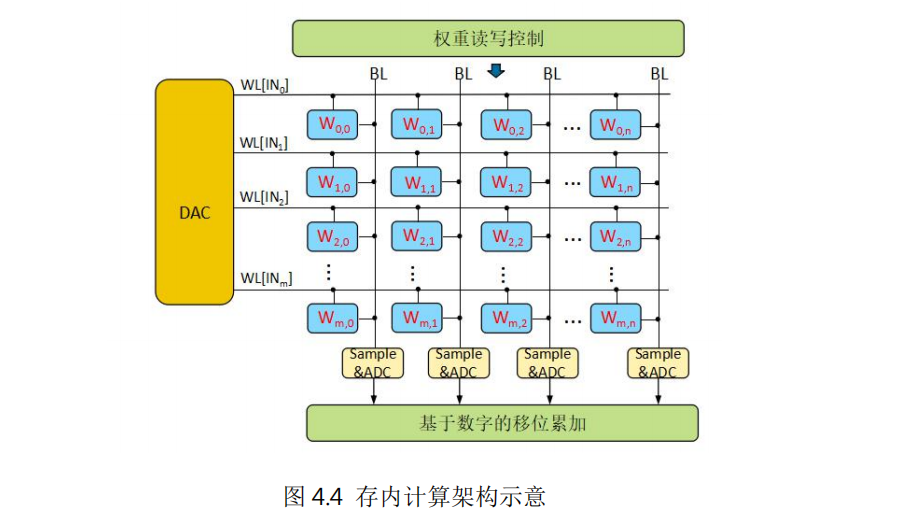
存內計算采用計算、存儲統一設計的架構。以深度神經網絡的矩陣向量乘加操作為例,由輸入端的DAC、單元陣列、輸出端的ADC以及其他輔助電路組成。存儲單元中存放權重數據,輸入經過DAC轉換后變成對存儲數據的讀寫操作,利用歐姆定律和基爾霍夫定律,不同的存儲單元輸出電流自動累加后輸出到ADC單元進行采樣,轉換成輸出的數字信號,這樣就完成了矩陣向量乘加操作。
基于對等系統的分布式計算架構
傳統的計算系統以CPU為中心進行搭建,業務的激增對于系統處理能力要求越來越高,摩爾定律放緩,CPU的處理能力增長越來越困難,出現了算力墻。通過領域定制(DSA)和異構計算架構可以提升系統的性能,但是改變不了以CPU為中心的架構體系,加速器之間的數據交互通常還是需要通過CPU來進行中轉,CPU容易成為瓶頸,效率不高。
基于xPU(以數據為中心的處理單元)為中心的對等系統可以構建一個新型的分布式計算架構。如圖4.5所示,對等系統由多個結構相似的節點互聯而成,每個節點以xPU為核心,包含多種異構的算力資源,如CPU、GPU及其它算力芯片。xPU主要功能是完成節點內異構算力的接入、互聯以及節點間的互聯,xPU內部的通用處理器核可以對節點內的算力資源進行管理和二級調度。節點內不再以CPU為中心,CPU、GPU及其它算力芯片作為節點內的算力資源處于完全對等的地位,xPU根據各算力芯片的特點及能力進行任務分配。
對等系統的節點內部和節點之間采用基于內存語義的新型傳輸協議,即,采用read/write等對內存操作的語義,實現對等、無連接、授權空間訪問的通信模式,通過多路徑傳輸、選擇性重傳、集合通信等技術提高通信效率。與TCP、RoCE等現有傳輸協議相比,基于內存語義的傳輸協議基于低延時、高擴展性的優勢。節點內xPU、CPU、GPU及其他算力芯片之間通過基于內存語義的低延時總線直接進行數據交互。節點間通過xPU內部的高性能轉發面實現基于內存語義的低延時Fabric,從而構建以節點為單位的分布式算力系統。同時xPU內置安全、網絡、存儲加速模塊,降低了算力資源的消耗,提高了節點的性能。
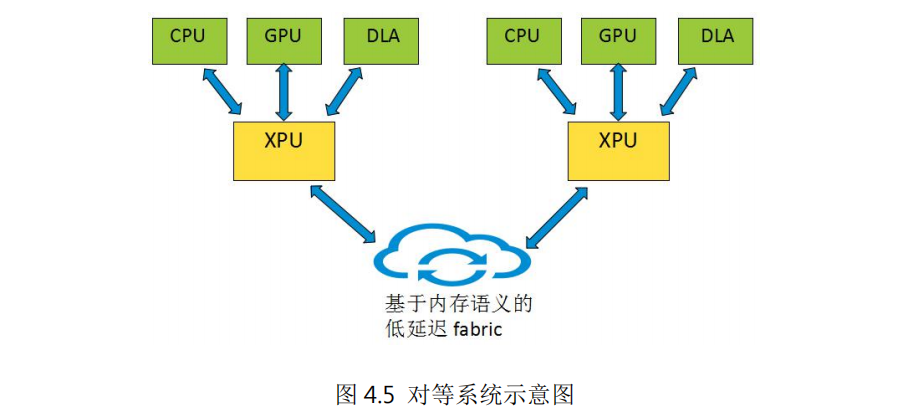
基于對等系統架構的服務器可以看成一個“分布式計算系統”,有利于產業鏈上各節點獨立規劃開發,發揮各自優勢。比如xPU卸載+庫/外OS演進+ APP direct模式解決公共能力(存儲、網絡),整體性能的提升不再依賴于先進工藝;基于對等內存語義互聯實現系統平滑擴展,將龐大分布式算力視為一臺單一的“計算機”。
支撐算網融合的IP網絡技術實現算力資源高效調度
算網深度融合有兩大驅動力,一是需求側,實現算力和網絡的協同調度,滿足業務對算力資源和網絡連接的一體化需求。比如,高分辨率的VR云游戲,既需要專用圖形處理器(GPU)計算資源完成渲染,又需要確定性的網絡連接來滿足10 ms以內的端到端時延要求。二是供給側,借助于網絡設施天生的無處不在的分布式特點,算網深度融合可以助力算力資源也實現分布化部署,滿足各類應用對于時延、能耗、安全的多樣化需求。
算網融合給IP網絡技術提出了挑戰。在互聯網整個技術架構中,通常來說算對應著上層的應用,網對應著底層的連接,IP技術作為中間層,起到承上啟下的樞紐作用。傳統的IP網絡遵循的端到端和分層解耦的架構設計,使得業務可以脫離網絡而獨立發展,極大降低了互聯網業務的創新門檻,增加了業務部署的便利。但是在這樣的設計架構之下,業務和網絡處于“去耦合“的狀態,最終絕大多數業務只能按照“盡力而為”的模式運行。
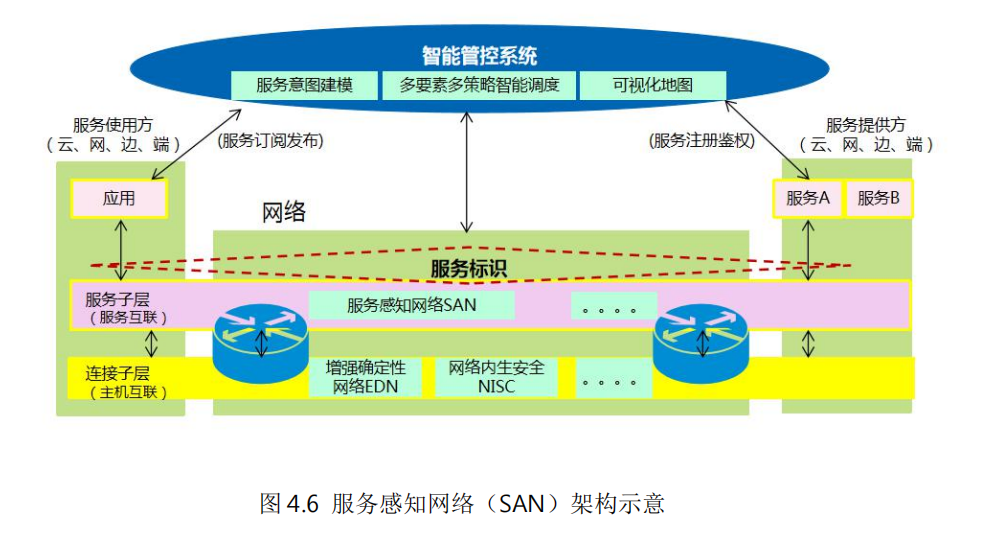
如何建立業務和網絡之間的橋梁,實現算力資源、網絡資源的協同和精細化管理,是未來IP網絡面臨的一大挑戰。中興通訊提出的“服務感知網絡(SAN,Service AwarenessNetwork)”是在這個方面的創新嘗試
服務感知網絡實現了算力服務和網絡服務的一體化供給,實現算網資源的高效調度,既保障了服務質量,又能將節能減排的要求落到實處。
-
晶體管
+關注
關注
77文章
9744瀏覽量
138821 -
算力
+關注
關注
1文章
1012瀏覽量
14939 -
ChatGPT
+關注
關注
29文章
1566瀏覽量
8022
原文標題:算力技術未來發展路徑概述(2023)
文章出處:【微信號:架構師技術聯盟,微信公眾號:架構師技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦


英碼科技精彩亮相火爆的IOTE 2023,多面賦能AIoT產業發展!
《大規模光電集成賦能智能算力網絡白皮書》概述

AI算力研究框架(2023)

從算力網絡發展,看未來十年的宏觀算力體系






 工商網監
工商網監
評論