 從算力網絡發展,看未來十年的宏觀算力體系
從算力網絡發展,看未來十年的宏觀算力體系
編者按
三大運營商都在積極地推廣“算力網絡”的相關技術概念落地,互聯網公司有類似的概念叫“分布式云”。個人理解,兩個概念的技術實現基本相同,不同點在于:算力網絡站在基礎計算環境的視角,著眼于算力資源的整合;分布式云從業務服務的視角,著眼于計算以何種形式提供。
今天這篇文章,拋磚引玉,探討一下宏觀視角的算力網絡的底層算力體系。
1、算力網絡和分布式云的概念
Garnter 2021年發布的戰略技術趨勢,將分布式云(Distributed Cloud)列為云計算的重要戰略技術趨勢。分布式云的定義:將公有云服務分布到不同的物理位置(即邊緣),而服務的所有權、運營、治理、更新和發展仍然由原始公有云提供商負責。解決客戶讓云計算資源靠近數據和業務活動發生的物理位置的需求。分布式云是整合公有云、私有云和邊緣云在一起,核心思想是,讓公有云的全棧服務能力延伸到最靠近用戶所需的地方。分布式云,本質上是一朵云,由云負責調配計算資源。雖然中間需要網絡,但是網絡主要是承擔管道的角色。
按照運營商的觀點,算力網絡是云網協同和分布式云的升級版,指的是:在計算能力不斷泛在化發展的基礎上,通過網絡手段將計算、存儲等基礎資源在云-邊-端之間進行有效調配的方式,以此提升業務服務質量和用戶的服務體驗。算力網絡中的網絡非常關鍵:網絡是用戶去往算力資源的必經之路,也是用戶發起業務需求的入口,通過網絡調配算力。
站在用戶業務的角度,分布式云和算力網絡的目標是一致的:云網邊端從協同走向融合。算力網絡是網絡擁有者為滿足這類需求,提出的方案;分布式云是云計算廠商為滿足同樣的需求,提出的方案。從趨勢看,兩種方式是既合作又競爭的關系,隨著未來技術和業務的不斷發展,兩種方式會逐漸趨于統一。
2、從計算形態看算力網絡
2.1 計算機的資源分類
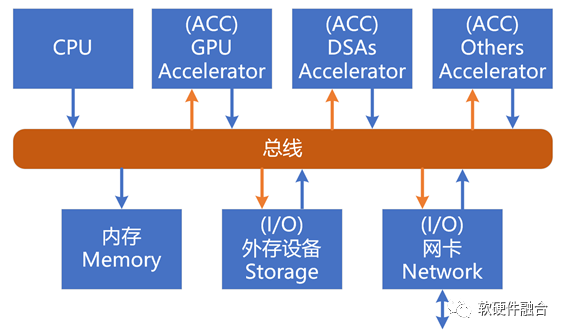
在傳統CPU的計算機架構里,計算機資源主要分為三類:CPU、內存和外設。在異構和超異構的計算體系下,計算機的硬件資源可以分為四類:
- CPU:站在控制的視角,CPU作為中央處理器,是整個系統的核心;站在計算的視角,CPU和其他加速器一樣,是用于計算的處理器之一。
- 內存:在異構或超異構計算體系下,內存的概念同經典架構下意義相同;區別在于,在異構或超異構情況下,內存的訪問者更多,訪問更加頻繁,帶寬等性能要求更高。
- I/O設備:同經典架構下意義基本相同。
- 其他的加速處理器:如GPU、AI-DSA、網絡DSA,以及各種ASIC類的加速器等。從CPU視角看,其他的加速器是和I/O設備對等的“外部設備”;而從計算的視角看,其他的加速器是和CPU對等的計算處理器。
2.2 IaaS服務分類
IaaS服務主要分為四類:計算、網絡、存儲和安全,詳細分析如下:
- 計算類:不管是裸金屬機、虛擬機或者容器的形態,云計算的主機或容器硬件平臺都是由計算機的四大大資源組件組成的:
計算的CPU處理器,不管是通用(CPU)計算,還是異構計算,CPU都是不可缺少的資源組件。
計算的加速處理器,異構計算需要有GPU、AI加速等加速處理器資源組件。
計算的內存,內存是用于計算暫存的存儲資源。
網絡和存儲I/O,是計算不可或缺的組件;在IaaS體系里,網絡和存儲通常以獨立服務的形態存在。
根據業務場景的需要,計算的硬件平臺是這些資源的不同規格不同比例的組合。
根據需要,可以通過很多種方式,實現所有資源的池化,以及實現硬件平臺計算資源的本地或(和)遠程擴展。
網絡類:狹義的網絡只是一個網卡,為計算提供網絡訪問的通道。廣義的網絡類服務,包括兩類:網絡轉發,如VPC、EIP、各類網關、LB等;網絡通信:如高性能網絡、確定性網絡等。
存儲類:從計算的角度看,外存是計算的輸入輸出,即使計算機關機,外存的數據依然存在。但從云服務器的視角看,本地外部存儲是臨時存儲,當云服務器資源被銷毀后,也會銷毀本地存儲的數據。要想長期地持久化地保存數據,則需要采用遠程的分布式存儲。本地臨時存儲和分布式的快存儲、對象存儲、歸檔存儲等都是以服務的形式,支撐計算類服務。
- 安全類:安全的計算,如可信計算;安全的網絡,如防火墻;安全的存儲,如數據加解密等。安全是個非常龐大的話題,無處不在,這里我們不再展開。
2.3 算力網絡的兩種類型
簡單介紹一下Serverless的概念。Redhat給出的Serverless定義為:“無服務器是一種云原生開發模型,可使開發人員專注構建和運行應用,而無需管理服務器。無服務器方案中仍然有服務器,但它們已從應用開發中抽離了出來。云提供商負責置備、維護和擴展服務器基礎架構等例行工作。開發人員可以簡單地將代碼打包到容器中進行部署。部署之后,無服務器應用即可響應需求,并根據需要自動擴容。公共云提供商的無服務器產品通常通過一種事件驅動執行模型來按需計量。因此,當無服務器功能閑置時,不會產生費用。”
通俗易懂地講,有服務器的服務,需要用戶自己創建服務的具體實例Instance,一個實例只能歸屬于一個用戶,一個用戶可以擁有一個或多個實例;而Serverless類型的服務則不需要創建服務實例,直接使用服務即可,很多用戶共享使用同一個服務“實例”(不是所有用戶,服務軟件在不同數據中心的部署可以是不同的服務)。至于服務所需要的各種底層資源,用戶不需要關心,服務可以根據業務使用的情況自動地擴縮容等。
也因此,算力網絡的實現形態,我們大體上可以分為兩個類型:有服務器型和無服務器型。
類型1,有服務器型
有服務器的形態,更接近算力網絡的概念。通過網絡等方式實現數據中心的以及跨數據中心的各類資源的池化,然后再通過云裸金屬機、云虛擬機、云容器等方式組合出供用戶業務運行的硬件的計算平臺。
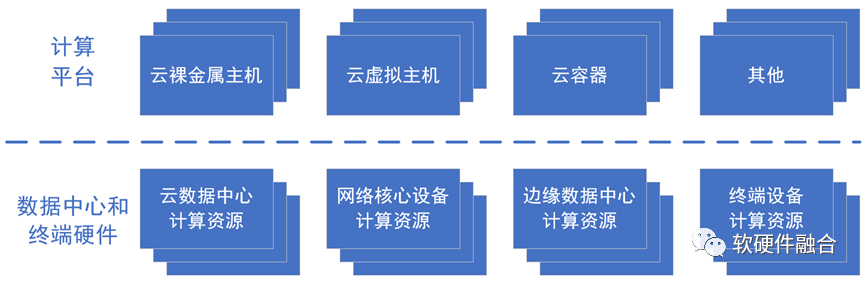
可以根據用戶的需求,在云、網、邊、端的任何位置,組合出規格和形態各異的計算平臺,給用戶提供最優的算力服務,實現算力的無處不在。
類型2,Serverless無服務器型
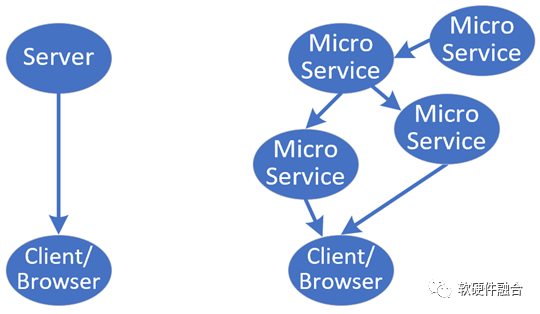
業務軟件,經典的C/S或B/S架構,一切皆(微)服務的架構下,可以簡單地理解成客戶端和多個微服務組成的分布式軟件。
Serverless無服務器型,更接近分布式云的概念。類似分布式云的早期經典案例是CDN,當用戶訪問加入CDN服務的網站時,域名解析請求將最終交給全局負載均衡DNS進行處理。全局負載均衡DNS通過一組預先定義好的策略,將當時最接近用戶的節點地址提供給用戶,使用戶能夠得到快速的服務。CDN只是一些靜態內容,而分布式云則需要把服務分布式的放置在邊緣等節點。
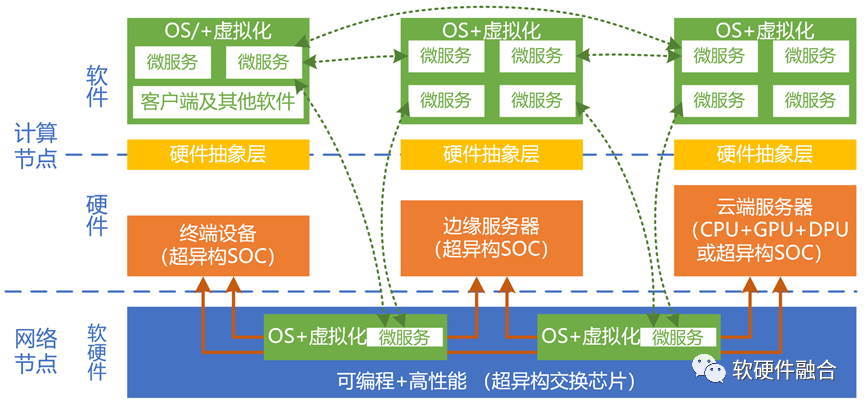
在分布式云的體系下,用戶不需要關心底層的主機和容器,只需要關注自己的業務邏輯。通常情況下,客戶端可以運行在終端本地(不排除有的系統只在服務器運行,客戶端也運行在服務器側),具體的運行位置用戶不需要關心。云服務供應商可以根據微服務所需的帶寬、時延、性能、成本等要求,選擇最優的運行環境,它可以是終端本地,也可以是邊緣、網絡或者云端。并且,這些服務還可以根據環境的變化,動態地調整運行的位置。
3、面向未來十年的宏觀計算系統特征
3.1 需求的未知
首先,系統場景一直在快速變化:上層軟件場景層出不窮,兩年一個新熱點,已有熱點仍在快速演進。并且,宏觀大系統,計算資源是預先準備好的。購買和部署相關資源時,并不知道具體的計算資源會分配給哪個用戶,也不知道用戶在此資源上會運行什么任務。此外,資源分配和任務運行會一直動態變化。傳統芯片和系統設計,需要先理解場景,然后根據場景需求來設計芯片和系統。未來的挑戰是,系統的場景需求是不確定的;不但芯片公司不了解,客戶自己也“不了解”。因此,復雜計算系統的設計,需要“無的放矢”。
3.2 全面而綜合
不管是云計算數據中心系統,還是云網邊端萬物互聯系統,亦或是云宇宙虛實融合系統,宏觀的計算系統,只有“一個”。然而,千千萬不同用戶的需求多種多樣;并且,用戶的需求一直處于快速的變化中;此外,還會不斷有新增用戶和新增需求。因此,系統需要有包羅萬象的能力,即面對已知的和未知的各種各樣的需求,系統都要能夠支持。
3.3 專業而高效
通常情況下,“專業的人做專業的事”。言下之意是:專才只能做本領域的事情,其他領域的事情幾乎做不了。與此同時,通才什么事情都能做,但在每個領域都不夠高效。但對宏觀的復雜計算系統來說,系統不僅僅要能干幾乎所有事情,并且干任何事情都要足夠的專業而且高效,達到既通又專。
3.4 超級并發
數以億計的用戶,數以萬億計的用戶任務,而系統只有“一個”。千千萬用戶的計算需求需要及時響應,用戶的工作任務需要快速地處理。
因此,同一時刻,系統并發處理數以億計的各種類型的用戶任務。
3.5 無處不在
系統覆蓋非常廣泛的地域,實現算力無處不在,使得算力資源唾手可得。即在任何地方,任何時刻,為用戶的任何工作任務,都能提供算力和相關資源支撐。并且,需要以最合適的形態,最合適的方式,給用戶更好的體驗,為用戶創造更大的價值。
3.6 快速演進
上層軟件應用層出不窮,系統需求快速變化。并且,同一領域,不同用戶的需求具有差異性;與此同時,同一用戶的業務需求仍會快速迭代。宏觀地看,用戶以及用戶需要運行的任務,一直處于不斷地變化狀態。復雜而融合的系統,需要持續快速演進,才能適應上層業務需求的不斷變化。
4、體系結構視角看算力網絡
4.1 算力資源的多樣性
隨著CPU的性能瓶頸,我們需要通過GPU、FPGA、DSA等各種形態的加速處理器,來持續不斷地提升性能和算力。也因此,計算的資源,就不僅僅是CPU了,而是多種架構多種類型處理器的組合:
- CPU:包括x86、ARM和RISC-v等各種架構的CPU,并且每種CPU還有Vector、Matrix、Tensor等各種加速的協處理器。
- GPU:GPU作為通用的并行計算平臺,是使用最廣泛的加速計算處理器。并且,目前的GPU除了支持通用計算的CUDA外,還集成了更高效加速處理的Tensor Core,進一步提升了GPU的加速能力。
- FPGA:通過各種硬件編程設計,實現各種形態各種架構的計算引擎。
- DSA:計算有很多領域,每種領域還有很多公司的很多DSA,甚至同一家公司同域但不同代的DSA架構也有可能不同。
- ASIC:ASIC完全面向特定場景,不同領域的不同場景,都有形態和架構各異的各種ASIC引擎。
這么多的處理器類型,這么多的處理器架構,造就了算力網絡計算資源的多樣性特征。
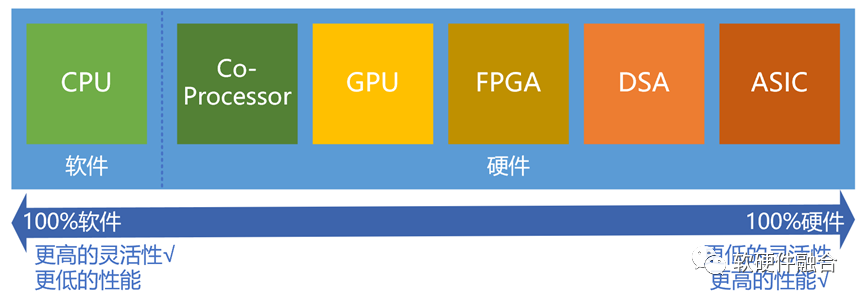
性能和靈活性是一對矛盾,對單個處理器引擎來說,如果要性能就必須損失靈活性,如果要靈活性必然損失性能。然而,支撐算力網絡的宏觀計算系統,既要“全面而綜合”,又要“專業而高效”。怎么辦?
通過CPU、GPU、DSA等多種類型的處理器相互協作,實現團隊作戰。每個處理器引擎各司其職,發揮各自的性能/靈活性優勢,從而實現宏觀意義上的性能和靈活性的兼顧和微觀上的每個處理的高效和高性能。
4.2 算力資源的融合
算力資源的多樣性,其實也就是算力資源的碎片化,并不是一個好的現象。
4.2.1 算力資源的池化
如果每個處理器核是一個孤島式的計算資源,那么就沒有意義。算力網絡的價值本就在涓涓小溪流匯聚成大海,這是算力網絡的基礎。這樣,把宏觀的不同云/邊緣數據中心、不同終端設備的計算資源匯聚在一起,形成算力的統一的大資源池。
網絡本身更多承擔的是連接和總線的角色,網絡設備中也會有一些計算和存儲的資源,可以歸屬到計算或存儲資源類型。

池化雖然可以把不同服務器不同設備上的相同計算資源連成一個資源池,但受限于算力資源的多樣性,不同類型不同架構的資源仍然是無法整合到一起的。因此,算力資源的池不是一個,而是很多很多個。比如x86和ARM、RISC-v的CPU資源就無法整合到一個池里;不同廠家的GPU也無法整合到一個資源池里;甚至存儲或網絡I/O設備,因為接口的不同,也可能無法整合到一個資源池;包括各種DSA/FPGA/ASIC,更是無法整合。
當有多達上百個不同類型不同架構的資源池的時候,其實已經弱化了資源池化的價值。4.2.2 算力資源的聚合
ChatGPT等AI模型對算力的需求,每2個月翻一倍。如此快速的算力增長,目前只能通過Scale out的方式來提升整個計算集群的性能。但隨著集群規模的擴展,集群的損耗變得越來越不可承受:集群內部東西向的網絡流量會占到90%以上,真正外部交互的流量只有不到10%。這個現象也符合阿姆達爾規律,受限于系統中串行部分的影響,隨著并行計算的節點越來越多,通過提升并行數量來提升系統性能的方式會逐漸遇到瓶頸。
也因此,在Scale out方式無法進一步提升系統性能的情況下,提升性能的方式只能通過Scale up。也就是要提升單個計算節點的性能。也因此,單個計算節點的計算架構需要從現在的異構計算逐步過渡到多個異構融合的超異構計算架構。
4.2.3 軟件需要跨硬件移動
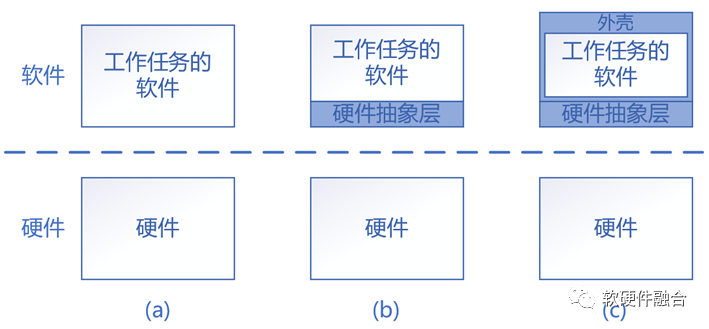
傳統場景下,軟件通常附著在硬件之上,兩者是綁定的。可以通過如HAL一樣的抽象層來實現平臺的標準化,然后再部署操作系統和應用軟件。而在系統越來越復雜的情況下,軟件的實體,如虛擬機、容器等,需要在不同的硬件上遷移,這就使得軟件和硬件逐漸分開了。
通常來說,可以通過虛擬化實現硬件架構的屏蔽,軟件不需要太多關注硬件的架構和接口。但隨著虛擬化技術的完全硬件化,硬件的架構和接口完全地暴露給了上層的虛擬機或容器。這就對硬件的架構和接口提出了更加嚴苛的要求。4.2.4 開放架構和生態,讓架構收斂
CPU、GPU、AI-DSA等只有單個類型架構的處理器,一家公司只做私有的架構,如果公司的產品成功,那么就可以獨占整個生態。這里的成功案例如Intel的x86,NVIDIA的CUDA。
在同構和異構時代,這種做法是可能成功的;但到了處理器架構非常多的超異構時代,這種做法幾乎不可行。因為沒有任何一家公司能做到,在所有的計算架構上都能夠做到最好。并且“百花齊放”的做法,其實在進一步分裂整個計算生態,與算力網絡資源池化和云網邊端融合的發展趨勢相悖。
在超異構時代,唯一能成功的方式是,大家都遵循一定的架構規范,從而形成開放的架構和生態,讓計算的架構逐漸收斂,從而能發揮算力資源池化的優勢,真正實現算力無所不在。
-
互聯網
+關注
關注
54文章
11184瀏覽量
103695 -
網絡
+關注
關注
14文章
7597瀏覽量
89117
發布評論請先 登錄
相關推薦

算智算中心的算力如何衡量?

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
中國算力大會召開,業界首個算力高質量評估體系發布

名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
中科曙光入選2024算力服務產業圖譜及算力服務產品名錄
中國算力中心市場持續增長,智能算力規模快速崛起

算力系列基礎篇——算力101:從零開始了解算力

廣東:到2025年,算力規模38E,智算50%,國產算力70%






 工商網監
工商網監
評論