 為什么GBDT用回歸樹不用分類樹?CART決策樹是怎么計算基尼值呢?
為什么GBDT用回歸樹不用分類樹?CART決策樹是怎么計算基尼值呢?
一、背景
集成學習Boosting一族將多個弱學習器(或稱基學習器)提升為強學習器,像AdaBoost, GBDT等都屬于“加性模型”(Additive Model),即基學習器的線性組合。1997年Freund和Schapire提出的AdaBoost,它是先從初始訓練集訓練出一個基學習器,然后基于基學習器的在這一輪的表現,在下一輪訓練中給預測錯的訓練樣本更大權重值,以達到逐步減少在訓練集的預測錯誤率。這種訓練機制像不像做一套卷子,有些重難點題做不出來,那下次又給你做同樣的卷子,但不同的是:之前你做錯的重難點題占有很大的分值比重,這樣你會將更多重心放在了這些難題上,從而提高你的學習表現。那除了這種方式,還有沒有其他方法攻克考題上的重難點?有,就是死磕到底,找到這題錯在哪?基于此錯誤繼續去做這道題,直到做對為止。這跟GBDT [1] 的工作機制就很像了,它是先產生一個弱學習器(CART回歸樹模型),訓練后得到輸入樣本的殘差,然后再產生一個弱學習器,基于上一輪殘差進行訓練。不斷迭代,最后加權結合所有弱學習器得到強學習器。GBDT的一個應用示意圖如下(某樣本預測值 = 它在不同弱學習器所在葉子節點輸出值的累加值):
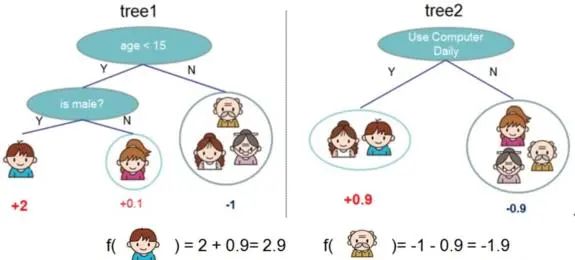
圖1:GBDT應用示意圖
二、GBDT
第二部分目錄如下:
1.背景知識
- GBDT弱學習器
- GBDT模型框架
2.GBDT回歸
3.GBDT分類
- GBDT二分類
- GBDT多分類
1. 背景知識
GBDT可用于回歸和分類任務。在深入了解它在回歸或分類任務上的訓練細節之前,我們先了解一些相關的背景知識。
(1)GBDT弱學習器
決策樹是IF-THEN結構,它學習的關鍵在于如何選擇最優劃分屬性。西瓜書 [2] 提到:“隨著劃分過程不斷進行,我們希望決策樹的分支結點所包含的樣本盡可能屬于同一類別,即結點的“純度”(Purity)越來越高”。衡量純度的指標有多種,因此對應有不同類型的決策樹算法,例如ID3決策樹 (以信息增益Information Gain作為屬性劃分標準),C4.5決策樹 (以增益率Gain Ratio選擇最優劃分屬性),CART決策樹 (使用基尼指數Gini Index)來選擇劃分屬性。
決策樹那么多種,為什么GBDT的弱學習器就限定使用CART決策樹?
A: 原因如下所示 (具體細節不展開):
- ID3決策樹只支持類別型變量,而C4.5和CART支持連續型和類別型變量。
- C4.5適用于小樣本,CART適用于大樣本。
CART決策樹是怎么計算基尼值呢?
A: 假設當前數據集D中第k類樣本所占比例為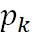 (k=1,2,…,
(k=1,2,…,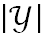 ),則基尼值為:
),則基尼值為:
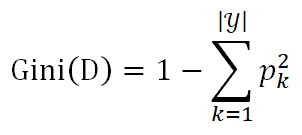
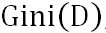 反映了從數據集D隨機抽取兩個樣本,其類別標記不一致的概念,因此越小,數據集D的純度越高。基于此,屬性a的基尼指數定義為:
反映了從數據集D隨機抽取兩個樣本,其類別標記不一致的概念,因此越小,數據集D的純度越高。基于此,屬性a的基尼指數定義為:
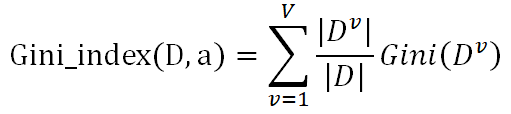
假設屬性a有V個可能的取值{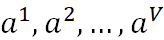 },則
},則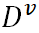 是指第v個分支結點包含D中所有在屬性a上取值為
是指第v個分支結點包含D中所有在屬性a上取值為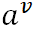 的樣本。
的樣本。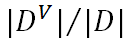 是給分支結點賦予權重,獲得樣本數更多的結點,影響更大。
是給分支結點賦予權重,獲得樣本數更多的結點,影響更大。
舉個具體計算基尼指數的例子,假如按照“芯片為高通驍龍865和非高通驍龍865進行機型檔位劃分”:
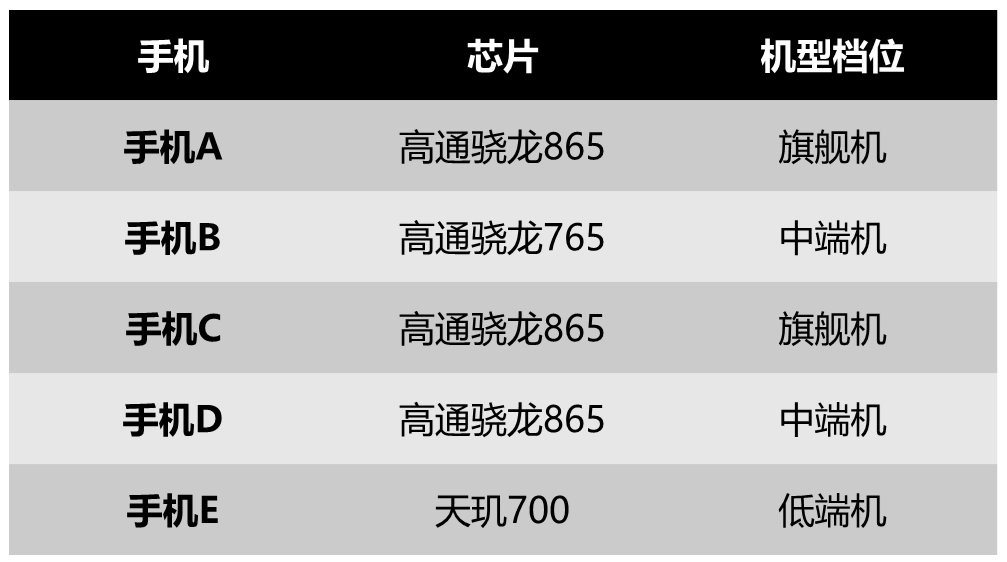
表1:基尼指數計算樣例集
當芯片為高通驍龍865時,有旗艦機2個,中端機1個:
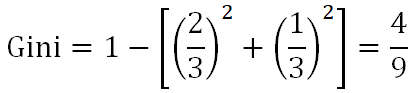
當芯片非高通驍龍865時,有中端機1個,低端機1個:
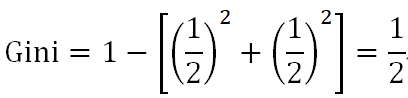
最后,特征”芯片”下數據集的基尼指數是:
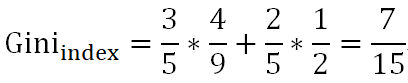
為什么GBDT用回歸樹,不用分類樹?
A: 因為GBDT要計算殘差,且預測結果是通過累加所有樹結果得到的。因此分類樹沒法產生連續型結果滿足GBDT的需求。
(2)GBDT模型框架

圖2:GBDT算法實現流程圖及偽代碼 [3]
GBDT的偽代碼如圖2所示,假設我們有個樣本集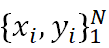 ,想用M個弱學習器加性組合成GBDT強學習器,我們得按以下步驟進行實現 (詳情參考 [4]):
,想用M個弱學習器加性組合成GBDT強學習器,我們得按以下步驟進行實現 (詳情參考 [4]):
1)初始化一個弱學習器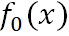 。它使損失函數
。它使損失函數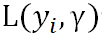 最小化,具體如下:
最小化,具體如下:
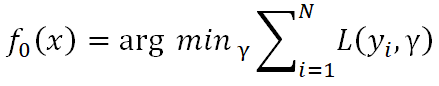
這里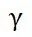 是什么呢?請接著看下去,假設這里損失函數為平方損失,則對求導:
是什么呢?請接著看下去,假設這里損失函數為平方損失,則對求導:
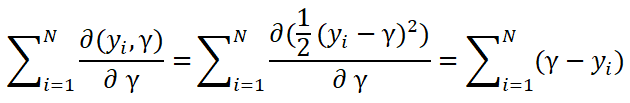
由于這里的損失函數為凸函數,所以只要令上面這個導數為0即可,那么可以求得:
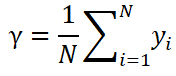
因此,是所有訓練樣本標簽值的均值,它是一個常數,所以弱學習器就只有一個根節點。
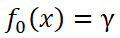
注意:因損失函數不同而不同。
2)迭代訓練m = 1, 2, … , M棵樹。
(a)對每個樣本i = 1, 2, …, N,計算負梯度:
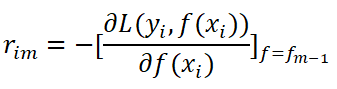
(b)將上步(a)得到的負梯度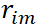 作為新樣本值,將新數據
作為新樣本值,將新數據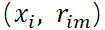 , I = 1, 2, …, N作為下顆樹的訓練數據,擬合得到新樹,新樹上的葉子節點區域為
, I = 1, 2, …, N作為下顆樹的訓練數據,擬合得到新樹,新樹上的葉子節點區域為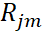 (j = 1, 2, …,
(j = 1, 2, …,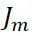 ,其中為葉子結點的個數)。
,其中為葉子結點的個數)。
(c)對每個葉子節點j = 1, 2, …, ,計算最佳擬合(即使損失函數最小,擬合葉子節點最好的輸出值):
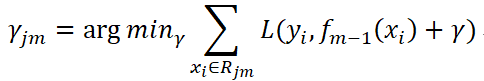
(d)更新強學習器:
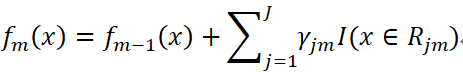
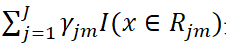 是CART回歸樹模型的表達式,其中J是指數據集被劃分為J個單元(即葉子節點),
是CART回歸樹模型的表達式,其中J是指數據集被劃分為J個單元(即葉子節點),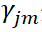 是第m輪迭代訓練下,CART樹第j個單元的輸出值。而
是第m輪迭代訓練下,CART樹第j個單元的輸出值。而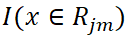 是指示函數,若
是指示函數,若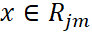 ,則I=1,否則I=0。這里第m輪下的強學習器 = 第m-1輪下的強學習器 + 第m輪的弱學習器。
,則I=1,否則I=0。這里第m輪下的強學習器 = 第m-1輪下的強學習器 + 第m輪的弱學習器。
3)輸出最終學習器GBDT:
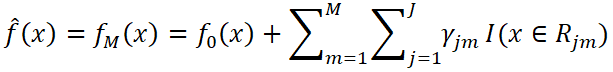
上述公式展示的就是一系列弱學習器累加后得到強學習器的結果。
負梯度和殘差的關系是什么?
A: 負梯度是函數下降最快的方向,也是GBDT目標函數下降最快的方向,所以,我們用負梯度去擬合模型。而殘差只是一個負梯度的特例,當損失函數為均方損失時,負梯度剛好是殘差(這點在上面 "對求導" 處有做假設展示)。
2. GBDT回歸
上面”GBDT通用框架”就是以平方損失為損失函數的一種GBDT回歸模型學習過程,不同損失函數導致使用的負梯度不同,因此也就產生了不同的GBDT回歸算法,總結了下GBDT回歸模型所用的損失和負梯度如下:

表2:GBDT回歸樹常用損失函數及負梯度 [5]
這里特別說下Huber損失,它對于中間附近的點 (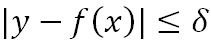 )采用均方誤差,對遠離中心的異常點 (
)采用均方誤差,對遠離中心的異常點 (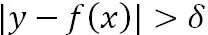 ),采用絕對損失。邊界點δ的值受絕對損失函數而不是平方誤差損失控制,定義了這些被認為是“離群點”的殘差值。總的來說,Huber結合了均方差和絕對損失,在抵抗長尾誤差分布和異常值的同時,還保持了對正態分布誤差的高效率。它和分位數損失一樣,適用于穩健回歸,用于減少異常點對損失函數的影響。
),采用絕對損失。邊界點δ的值受絕對損失函數而不是平方誤差損失控制,定義了這些被認為是“離群點”的殘差值。總的來說,Huber結合了均方差和絕對損失,在抵抗長尾誤差分布和異常值的同時,還保持了對正態分布誤差的高效率。它和分位數損失一樣,適用于穩健回歸,用于減少異常點對損失函數的影響。
3. GBDT分類
由于分類有二分類和多分類任務,所以GBDT分類有所區別,這里分開對它們進行展開解釋:
** (1) GBDT二分類**
我們上面也講到了,GBDT本質上就是一系列弱學習器之和:
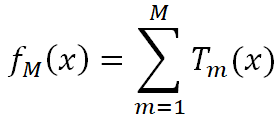
而GBDT分類跟邏輯回歸的思路是類似的,將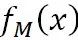 的作為下列函數的輸入,便可以得到類別概率值:
的作為下列函數的輸入,便可以得到類別概率值:
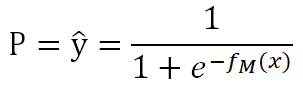
假設樣本獨立且同分布,極大似然估計(即選取合適的參數使被選取的樣本在總體中出現的可能性最大)的損失函數為:
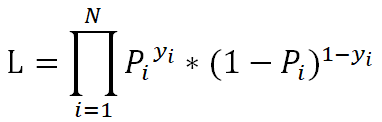
為了方便對損失函數求導,會加入對數,求最大對數似然估計:
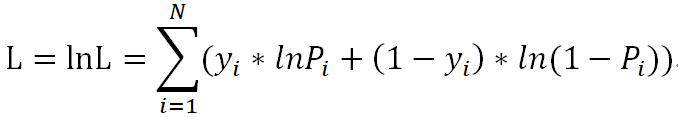
上面的損失函數并非最終的函數,而是最大似然估計函數(數值越大越好),由于損失函數應該使越小越好,所以要對上面的L取相反數,同時為了得到平均到每個樣本的損失值,要除以樣本數N,這樣得到了最終的損失函數:
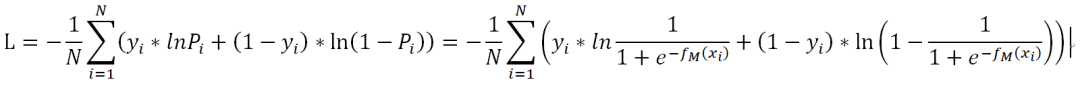
對損失函數計算負梯度:
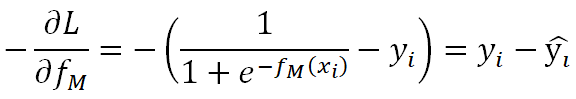
由此看來,GBDT負梯度即為殘差,表示真實概率和預測概率的差值。接下來計算過程跟著GBDT通用框架進行就好了。
** (2) GBDT多分類**
GBDT多分類原理跟Softmax一樣的,假設我們有k個類別,將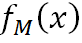 作為以下函數的輸入,便可以類別q對應的概率值:
作為以下函數的輸入,便可以類別q對應的概率值:
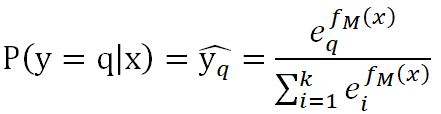
其損失函數為:
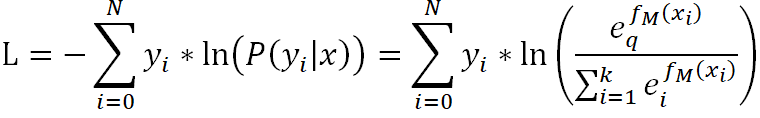
多類別任務下,只有一個類別是1,其余為0,假設這不為0的一類為q,我們對它Softmax的損失函數求負梯度得:
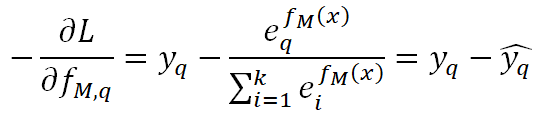
跟二分類一樣,本質上負梯度就是真實概率和預測概率的插值。
三、其它
第三部分講下GBDT的其它內容:
1. 正則化
2. 優缺點
3. 與RF的對比
1. 正則化
GBDT采用了三種正則化手段:
(1)學習率v和樹數量M的平衡
我們前面得到,第m輪下的強學習器 = 第m-1輪下的強學習器 + 第m輪的弱學習器,如下:
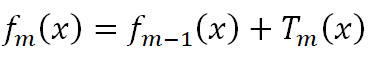
GBDT原論文提到,樹數量越多,越容易過擬合,所以限制樹數量可以避免過擬合,但歷史研究又給出:通過收縮 (即學習率v減少) 實現的正則化比通過限制項 (即樹數量M減少) 實現的正則化效果更好。這是什么意思呢?請先看下面的公式:
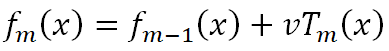
該公式加入了學習率v,這里跟神經網絡的學習率相反,如果我們學習率下降,每個樹的貢獻就會減低,反而還實現了正則化,但如果我們放開訓練(即不固定樹數量),只減低學習率的話,GBDT還是會過擬合,因為產生了更多的樹。因此,GBDT作者建議,我們要實現v-M之間的權衡,理想的應該是在正則效果合適下,學習率降低的同時,也能盡可能保證樹數量少些。這里當然也有出于對計算資源的考慮,增加M會帶來計算開銷。
(2)子采樣比例
子采樣是將原數據集中抽樣一定的樣本去擬合GBDT。與隨機森林不同的是,GBDT采樣不放回抽樣,因為GBDT串行訓練要求所有弱學習器使用同一套樣本集,不然在不同抽樣樣本空間計算的殘差,缺乏一致性。
(3)決策樹常用正則化手段
這塊的參數都涉及到弱學習器樹本身的正則化,例如:決策樹最大深度、劃分所需最少樣本數、葉子節點最少樣本數、葉子節點最小樣本權重、最大葉子節點數、節點劃分最小不純度等。
2. 優缺點
優點:
- 采用基于“殘差”(嚴格來說是負梯度)的Boosting集成手段。
- 適用于回歸、二分類和多分類任務。
- 預測精度比RF高。
- 對異常值的魯棒性強(采用了Huber損失和分位數損失)。
缺點:
- 串行方式的模型訓練,難并行,造成計算開銷。
- 不適合高維稀疏離散特征。這是決策樹的痛點,比如動物類別采用one-hot編碼后,會產生是否為狗,是否為貓一系列特征,而若這一系列特征中大量樣本為狗,其它動物很少,那么樹在劃分屬性時,很容易就劃分為“是否為狗”,從而產生過擬合,它不像LR等線性模型f(w,x)的正則化權重是對樣本懲罰(可以實現對狗樣本給與更大的懲罰項),而樹的懲罰項往往是樹結構相關的,因此樣本層面的懲罰較小,使得在高維稀疏特征時,GBDT表現不好。
3. 與RF的對比
[4] 總結的很好,我就不重復造輪子了:
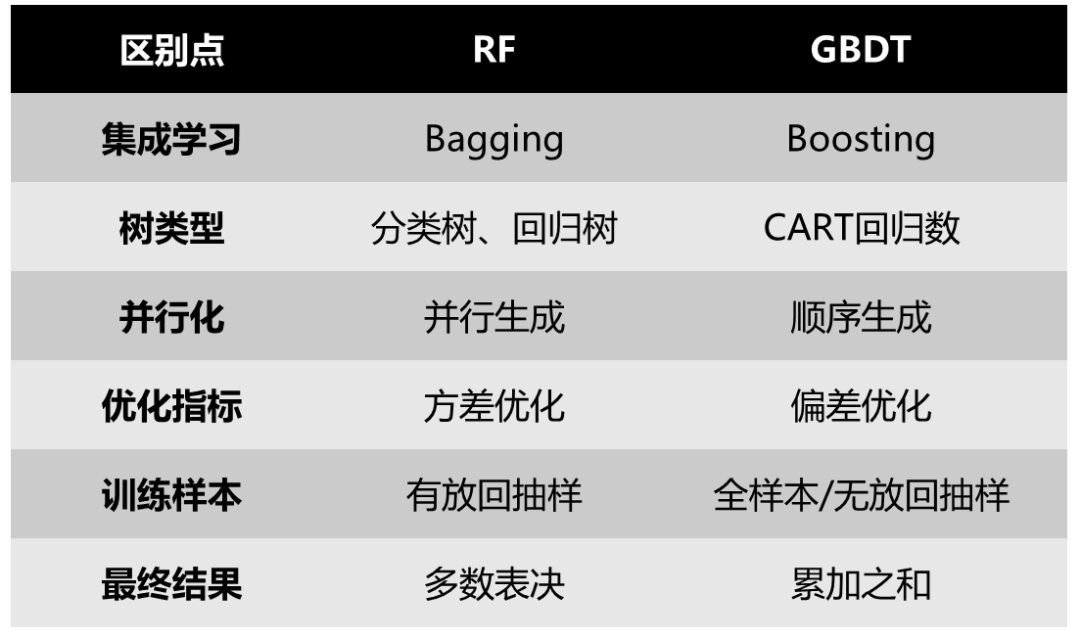
圖3:GBDT與RF的區別 [4]
四、代碼參考
scikit-learn已提供封裝好的庫直接調用就好了,受限于篇幅,這里不詳細展開,詳見官方文檔 [6]。
from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(X_train, y_train)
reg.predict(X_test[1:2])
reg.score(X_test, y_test)
-
決策樹
+關注
關注
3文章
96瀏覽量
13564 -
累加器
+關注
關注
0文章
50瀏覽量
9471 -
GBDT
+關注
關注
0文章
13瀏覽量
3906
發布評論請先 登錄
相關推薦
關于決策樹,這些知識點不可錯過
決策樹的生成資料
一個基于粗集的決策樹規則提取算法
數據挖掘算法:決策樹算法如何學習及分裂剪枝
決策樹的原理和決策樹構建的準備工作,機器學習決策樹的原理
使用基尼不純度拆分決策樹的步驟

什么是決策樹模型,決策樹模型的繪制方法





 工商網監
工商網監
評論