 數據高效缺陷檢測技術有哪些
數據高效缺陷檢測技術有哪些
1. 摘要
CVPR VISION 23挑戰賽第1賽道 "數據智能缺陷檢測 "要求參賽者在數據缺乏的環境下對14個工業檢測數據集進行實例分割。本論文的方法聚焦于在有限訓練樣本的場景下提高缺陷掩模的分割質量的關鍵問題。基于混合任務級聯(HTC)實例分割算法,我們用受CBNetv2啟發的復合連接將transformer骨干(Swin-B)連接起來以增強基準結果。此外,我們提出了兩種模型集成方法來進一步增強分割效果:一種是將語義分割整合到實例分割中,另一種是采用多實例分割融合算法。最后,通過多尺度訓練和測試時數據增強(TTA),我們在數據高效缺陷檢測挑戰賽的測試集上獲得了高于48.49%的平均mAP@0.50:0.95和66.71%的平均mAR@0.50:0.95。論文鏈接:https://arxiv.org/abs/2306.14116代碼鏈接:https://github.com/love6tao/
2. 背景補充
深度學習在視覺檢測中的應用越來越廣泛,這包括如無人機巡檢電力設備、檢測工業表面上的輕微劃痕、識別深孔零件中的銅線缺陷以及檢測芯片和玻璃表面上的導電微粒等工業缺陷檢測任務。但是,在工業制造場景中獲得標注的缺陷數據是困難、昂貴和耗時的,因此使得基于視覺的工業檢測更具挑戰性。為了解決這個問題,CVPR VISION 23挑戰賽第1賽道 - 數據高效缺陷檢測競賽啟動。
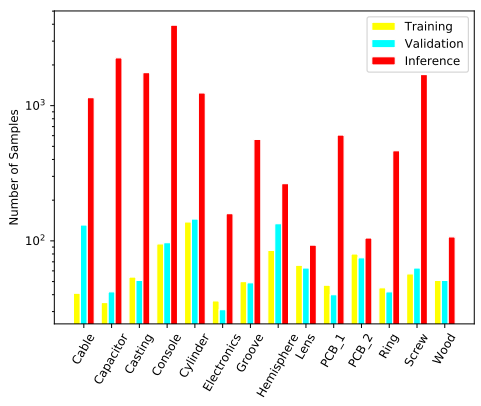
該競賽數據集由14個來自真實場景的缺陷數據集組成,最顯著的特點是測試樣本數量遠遠超過訓練樣本數量。如上圖所示,一些數據集如電容器和電子設備數據集僅包含不超過40個訓練樣本。此外,某些圖像在數據集中存在顯著的尺度變化。大多數框只覆蓋圖像的10%,而一些框可以覆蓋整個圖像。而且,14個數據集之間的背景和缺陷紋理形狀存在顯著差異,使得構建可以在每個數據集上都取得滿意結果的統一算法框架是一個巨大的挑戰。為了解決這些問題,我們訓練了一個以Swin Transformer 和CBNetV2 為骨干的強大基準模型,然后采用兩種模型集成方法來進一步提升分割性能。我們將在第2節中介紹我們的流程和詳細組件。實驗結果和消融研究顯示在第3節中。
3. 方法介紹
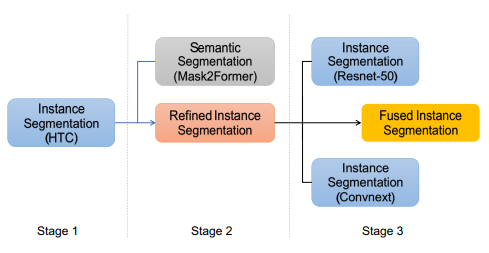
在這一節中,我們提出了一個由三部分組成的有效流程。首先訓練一個強大的單實例分割模型作為基準,使用混合任務級聯,以Swin Transformer和CBNetV2作為其骨干,如上圖所示。其次,使用Mask2Former 訓練一個強大的語義分割模型來進一步提煉分割性能,將語義分割結果與實例分割結果融合。最后,融合三個實例分割模型的結果以進一步改進分割效果用于最終提交。
3.1 基礎實例分割模型
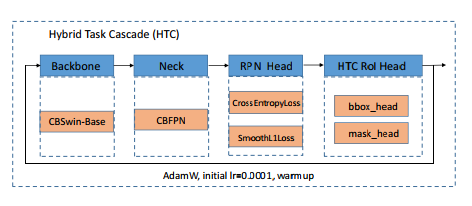
我們的基礎實例分割模型建立在混合任務級聯(HTC) 檢測器之上,使用CBSwinBase骨干和CBFPN 架構。HTC是一個用于實例分割任務的穩健的級聯架構,它巧妙地混合了檢測和分割分支進行聯合多階段處理,在每個階段逐步提取更有區分性的特征。為避免需要額外的語義分割注釋,我們從解決方案中刪除了語義頭部。最近的視覺Transformer的進步對各種視覺任務非常重要,因此我們采用Swin Transformer作為我們的骨干。Swin Transformer在分層特征架構中引入了一個高效的window注意力模塊,其計算復雜度與輸入圖像大小呈線性關系。在我們的工作中,我們采用在ImageNet-22k數據集上預訓練的Swin-B網絡作為我們的基本骨干。為進一步提高性能,我們受CBNetv2算法的啟發,通過復合連接將兩個相同的Swin-B網絡組合在一起。如上圖所示。
3.2 將語義分割整合到實例分割中
盡管單個模型可以取得很好的分割結果,但實例分割的結果通常不完整,特別是在設定IOU閾值過高時,這可能對mask mAP 產生負面影響。因此,我們使用語義分割模型的輸出來補充實例分割模型的結果。
我們的語義分割模型基于Mask2Former,使用Swin-L作為骨干,其網絡輸入圖像大小為512×512。預訓練權重來自ADE20K數據集。為了訓練語義分割網絡,我們將多缺陷標簽轉換為表示背景和缺陷的二進制標簽。
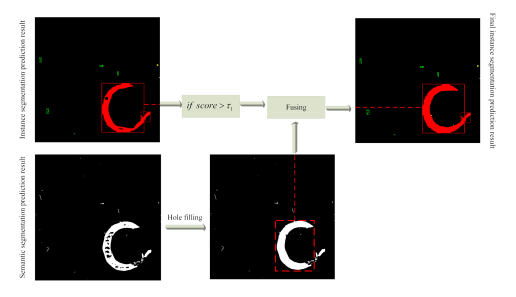
對于融合策略,我們在相同的像素位置組合實例分割結果和語義分割結果,生成新的實例分割結果,如上圖所示。由于語義分割任務將像素劃分為兩類:缺陷和背景,所以實例分割任務中的預測邊界框(bbox)類確定了像素的實際類。值得注意的是,只有預測實例與bbox置信度大于閾值才會與語義分割結果進行融合。在競賽中,我們將設置為0.5以獲得最佳的分割性能。
3.3 多個實例分割的融合
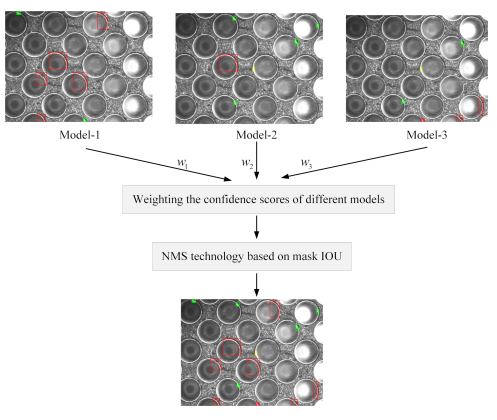
我們的實驗結果表明,不同的實例分割骨干可以產生互補的結果。這意味著融合不同骨干的實例分割結果可以提高模型的召回率。但是,提高召回率往往以犧牲檢測精度為代價。為解決這個問題,我們設計了一個融合策略,如上圖所示。
在我們的實驗中,我們將model-1、model-2和model-3分別稱為HTC、Cascade Mask rcnn-ResNet50和Cascade Mask rcnn-ConvNext模型。這些模型的設計目的是在它們之間增加多樣性。
Mask2Former是一個經過驗證的高效語義分割架構,已經被證明在各種應用中都能實現最先進的結果,如語義、實例和全景分割。通過將語義分割與實例分割相結合,我們在測試數據集上取得了顯著的48.38%的mask mAP。最后,通過平均模型包中這些模型的預測,我們的模型集成在競賽中實現了卓越的性能,mAP達到48.49%,mAR達到66.71%。
4. 未來改進方向
半監督學習:在我們的實驗中,我們僅關注在訓練和驗證集上訓練實例分割模型。我們嘗試使用基于soft-teacher的半監督學習方法來改進實例分割的性能。然而,由于數據集的差異,無法為半監督模型提供統一的訓練策略。由于競賽時間的限制,以后的研究將半監督方法作為一個更可行的方向。
SAM: Meta提出了通用分割模型(SAM)作為解決分割任務的基礎模型。我們通過在線演示網站評估了其有效性,并確定該模型在工業數據上的泛化性能也很出色。但是,根據競賽規則,我們不能使用SAM。盡管如此,大模型或基礎模型仍有可能為工業缺陷檢測帶來重大變化,從而為未來工作提供了另一個改進方向。
5. 結論
在論文中,我們介紹了CVPR VISION 23挑戰賽第1賽道亞軍解決方案"數據高效缺陷檢測"技術細節。作者的方法包括三個主要組成部分:基礎實例分割模型、將語義分割整合到實例分割中的方法以及融合多個實例分割的策略。通過一系列實驗,我們證明了我們的方法在測試集上的競爭力,在mAP@0.50:0.95上獲得48.49%以上,在mAR@0.50:0.95上獲得66.71%以上。
責任編輯:彭菁
-
數據
+關注
關注
8文章
7048瀏覽量
89073 -
檢測技術
+關注
關注
2文章
355瀏覽量
29079 -
分割
+關注
關注
0文章
17瀏覽量
11904
原文標題:CVPR VISION 23挑戰賽第1賽道亞軍解決方案 - 數據高效缺陷檢測
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
高效液相色譜儀的檢測器有哪些
基于AI深度學習的缺陷檢測系統
外觀缺陷檢測原理

產品標簽OCR識別缺陷檢測系統方案

磁粉檢測的特點及應用有哪些?
無損檢測的方法有哪些?其原理分別是什么?
想要高效檢測O型圈外觀缺陷?必看攻略!

蔡司工業ct內部瑕疵缺陷檢測機

如何應對工業缺陷檢測數據短缺問題?

洞察缺陷:精準檢測的關鍵

基于深度學習的芯片缺陷檢測梳理分析

2023年工業視覺缺陷檢測經驗分享

無紡布缺陷在線檢測儀怎么用

描繪未知:數據缺乏場景的缺陷檢測方案






 工商網監
工商網監
評論