") 省成本還是省時間,AI計算上的GPU與ASIC之選
省成本還是省時間,AI計算上的GPU與ASIC之選
電子發(fā)燒友網(wǎng)報道(文/周凱揚)隨著AI計算逐漸蠶食通用計算的份額,數(shù)據(jù)中心的硬件市場已經(jīng)開始出現(xiàn)了微妙的變化。最搶手的目前已經(jīng)成了GPU,反觀CPU、ASIC和FPGA等硬件,開始成為陪襯。但高昂的售價以及強綁定的供應關(guān)系,還是讓不少企業(yè)開始探索別的出路。
仍在被瘋搶的GPU
在今年第一季度AI熱潮高漲下,全球已經(jīng)開啟了一波GPU搶購。無論是借助GPU開發(fā)各自大模型應用的互聯(lián)網(wǎng)廠商,還是想借此發(fā)展其AI服務器業(yè)務的云服務廠商,都在搶購英偉達目前主推的A100和H100兩大GPU。
就連臺積電哪怕第一季度業(yè)績下滑明顯,其CEO魏哲家在法說會上也表示在AI相關(guān)的需求上觀察到了增量上行,將幫助其在今年實現(xiàn)可觀的庫存消化。

H100 GPU / 英偉達
在美國商務部半導體出口新規(guī)剛推出不久,A100在非正常渠道的單價就飆升至20000美元,是原價的兩倍左右。為此英偉達僅僅面向中國市場推出了A800和H800,只不過將高速互聯(lián)總線NVLink限制在了400GB/s,但好歹仍足以滿足大部分AI計算的需求。
可好景不長,隨著緊缺和搶購的趨勢很快蔓延到了A800和H800上,據(jù)了解,國內(nèi)市場的A800單價一周上漲了30%,從原來9萬元上升至13萬元,甚至連帶使得搭載該卡的服務器現(xiàn)貨同樣漲價,頗有當年礦潮期顯卡漲價整機一并漲價的趨勢。
使其狀況更加惡化的是,英偉達據(jù)傳大量削減了A800的供應,而是轉(zhuǎn)為推廣更高端也更昂貴的H800,單價在25萬元左右。高端的GPU無疑能夠帶來更高的性能,但性價比相對較低,大規(guī)模部署的成本也會更加難以承受。所以從全球市場的購買表現(xiàn)上來看,互聯(lián)網(wǎng)公司和云服務廠商顯然覺得A100或A800更香一點。
可為了更高的利潤轉(zhuǎn)化,英偉達決心調(diào)整A800和H800的供應比例的話,也就說得過去了。A100的市場流通率較高,而A800這種面世不久的特供產(chǎn)品,也更方便在供應上加以限制。
省時和省錢
既然GPU困人已久,為何不打破這一限制,轉(zhuǎn)用大規(guī)模量產(chǎn)成本更低的ASIC產(chǎn)品呢?事實上,很多廠商早就有類似的心思,只不過執(zhí)行起來卻是寸步難行。首先對于大模型這樣的AI應用來說,硬件性能只是一個方面,擁有優(yōu)質(zhì)的軟件生態(tài)也很重要。
英偉達的CUDA成了任何進軍AI產(chǎn)業(yè)的公司在軟件生態(tài)上的一頭攔路虎,遲遲沒法突破。固然ASIC的方案可以省下不少硬件成本,但在軟件上仍有不小的障礙。初創(chuàng)公司ASIC硬件的軟件生態(tài)不成熟,巨頭自研的產(chǎn)品又難以與第三方開發(fā)結(jié)合起來,或者說能打造出爆品應用的概率更低。
反觀CUDA,發(fā)展這么多年積累的各種library已經(jīng)逐漸趨于成熟,甚至在英偉達的GPU上優(yōu)化到了最佳狀態(tài),開發(fā)者只需要調(diào)用API即可實現(xiàn)所需的效果。這堵墻就連同為GPU廠商的AMD等競爭對手都未能攻破,因為AI時代下省時才能搶占先機,省錢是之后采取考慮的事。
話雖如此,相關(guān)的嘗試依舊沒有停止,諸如谷歌的TPU、亞馬遜的Trainium以及微軟最近在研究的Chiplet Cloud等等,都是廠商們對ASIC持續(xù)看好的表現(xiàn)。可以看出,讓互聯(lián)網(wǎng)企業(yè),尤其是芯片設計能力欠缺的企業(yè),去走ASIC這條路線是很難的。而托管了諸多第三方芯片設計平臺、大模型和AI計算負載的云服務廠商,有這個技術(shù)積累,也有實力組建或已組建達標的芯片設計隊伍,最終做到省時又省錢。
寫在最后
ASIC固然前景可觀,但目前廠商們在購置GPU上花的錢多半是多于自研投入的,這也就是GPU作為通用計算硬件的future proofing性質(zhì)。可能在GPT爆火的今年,這款ASIC提供了遠超GPU的性能或成本優(yōu)勢,但未來保不齊會出現(xiàn)其他的爆品應用。GPU可以很快調(diào)轉(zhuǎn)勢頭,但ASIC就可能會被淘汰。所以對這些公司來說,無論是購買A100還是A800,不僅是對現(xiàn)在的投資,也是對未來的投資。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
asic
+關(guān)注
關(guān)注
34文章
1205瀏覽量
120634 -
gpu
+關(guān)注
關(guān)注
28文章
4766瀏覽量
129189 -
AI
+關(guān)注
關(guān)注
87文章
31410瀏覽量
269817
發(fā)布評論請先 登錄
相關(guān)推薦
ASIC和GPU的原理和優(yōu)勢
? 本文介紹了ASIC和GPU兩種能夠用于AI計算的半導體芯片各自的原理和優(yōu)勢。 ASIC和GPU
GPU是如何訓練AI大模型的
在AI模型的訓練過程中,大量的計算工作集中在矩陣乘法、向量加法和激活函數(shù)等運算上。這些運算正是GPU所擅長的。接下來,AI部落小編帶您了解
《CST Studio Suite 2024 GPU加速計算指南》
《GPU Computing Guide》是由Dassault Systèmes Deutschland GmbH發(fā)布的有關(guān)CST Studio Suite 2024的GPU計算指南。涵蓋GP
發(fā)表于 12-16 14:25
使用瑞薩AnalogPAK SLG47001/03節(jié)省開發(fā)時間
在當今快速發(fā)展的技術(shù)市場中,對更快、更高效的產(chǎn)品開發(fā)的需求比以往任何時候都高。企業(yè)一直在尋找簡化流程和縮短上市時間的方法。有助于節(jié)省時間、簡化設計和降低成本的產(chǎn)品對于保持競爭力至關(guān)重要。
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
CPU、GPU的演進歷程,AI專用芯片或?qū)⒁I(lǐng)未來計算平臺的新方向。正如愛因斯坦所說:\"想象力比知識更重要\" —— 在芯片設計領(lǐng)域,創(chuàng)新思維帶來的突破往往令人驚嘆。
發(fā)表于 11-24 17:12
華迅光通AI計算加速800G光模塊部署
。骨干交換機,相當于核心層交換機,直接連接到葉交換機,每個骨干交換機連接到所有葉交換機。
AI計算和800G光模塊
與傳統(tǒng)的三層拓撲結(jié)構(gòu)相比,脊葉結(jié)構(gòu)需要大量的端口。因此,無論是服務器還是交換機
發(fā)表于 11-13 10:16
FPGA和ASIC在大模型推理加速中的應用
隨著現(xiàn)在AI的快速發(fā)展,使用FPGA和ASIC進行推理加速的研究也越來越多,從目前的市場來說,有些公司已經(jīng)有了專門做推理的ASIC,像Groq的LPU,專門針對大語言模型的推理做了優(yōu)化,因此相比

GPU加速計算平臺是什么
GPU加速計算平臺,簡而言之,是利用圖形處理器(GPU)的強大并行計算能力來加速科學計算、數(shù)據(jù)分析、機器學習等復雜
如何計算上拉電阻的值
,但在對性能有更高要求或特定條件下,則需要通過更為精確的計算來確定電阻值。本文將詳細介紹如何計算上拉電阻的值。 首先,我們需要理解上拉電阻在I2C總線中的基本作用。在I2C的開漏輸出設計中,上拉電阻負責在無設備驅(qū)動總線時,將SC
人工智能在項目管理中的應用:Atlassian Intelligence六大自動化任務方法詳解,讓Jira與Confluence效率翻倍
的情況下節(jié)省時間和金錢的有效方法之一。無論是設置提醒還是改進寫作,AI都可以幫助您高效地完成工作。AtlassianIntelligence將AI的強大功能與At

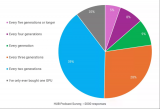
AI服務器異構(gòu)計算深度解讀
AI服務器按芯片類型可分為CPU+GPU、CPU+FPGA、CPU+ASIC等組合形式,CPU+GPU是目前國內(nèi)的主要選擇(占比91.9%)。
發(fā)表于 04-12 12:27
?684次閱讀

FPGA在深度學習應用中或?qū)⑷〈?b class='flag-5'>GPU
基礎設施,人們?nèi)匀粵]有定論。如果 Mipsology 成功完成了研究實驗,許多正受 GPU 折磨的 AI 開發(fā)者將從中受益。
GPU 深度學習面臨的挑戰(zhàn)
三維圖形是 GPU 擁有如此
發(fā)表于 03-21 15:19
GPU理想成本揭秘,性價比之選
如果新的 GPU 能夠為頻繁和不頻繁升級的玩家提供最佳性能提升,從而滿足最廣泛的 PC 游戲玩家的需求,那么這一代將被認為更加成功。
發(fā)表于 03-15 11:15
?738次閱讀
到底什么是ASIC和FPGA?
?
最后,我們還是要繞回到AI芯片的話題。
上一期,小棗君埋了一個雷,說AI計算分訓練和推理。訓練是GPU處于絕對領(lǐng)先地位,而推理不是。我
發(fā)表于 01-23 19:08





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論