") 預(yù)測超長蛋白質(zhì)這事,CPU贏了
預(yù)測超長蛋白質(zhì)這事,CPU贏了
金磊 楊凈 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
AI模型的推理在CPU上完成加速和優(yōu)化,竟然不輸傳統(tǒng)方案?
至少在生命科學(xué)和醫(yī)療制藥方向,已經(jīng)透露出這種信號。
例如在處理AlphaFold2這類大型模型這件事上,大眾普遍的認(rèn)知可能就是堆GPU來進(jìn)行大規(guī)模計算。
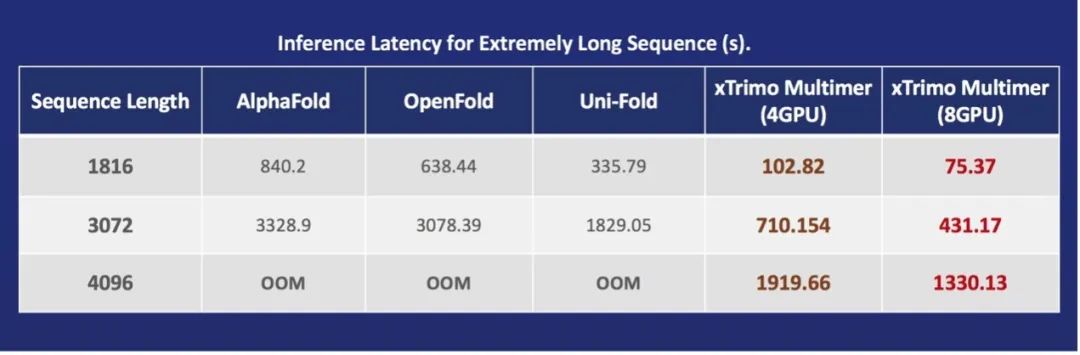
但其實(shí)從去年開始,CPU便開始苦練內(nèi)功,使端到端的通量足足提升到了原來的23.11倍。
而現(xiàn)如今,CPU讓這個數(shù)值great again——再次提升3.02倍!

不論是像抗菌肽這種較短的氨基酸序列,還是像亨氏綜合征蛋白這樣超長的序列,都可以輕松hold住。
而且所有的預(yù)測任務(wù),在不考慮最高通量、僅僅是順序執(zhí)行,8個小時就能全部搞定。

甚至國內(nèi)已經(jīng)有云服務(wù)提供商做了類似的優(yōu)化方案:
相比于GPU,基于CPU的加速方案在性價比上更為理想,而且在特定的情況下(超過300或400氨基酸),幾乎只有CPU能把它算完,而GPU的失敗率會很高。
要知道,像AlphaFold2這類任務(wù),可以說是公認(rèn)的AI for Science標(biāo)桿。
從上述的種種跡象表明,CPU不再是“你以為的你以為”,而是以一種新勢力進(jìn)軍于此,并發(fā)揮著前所未有的威力。
CPU,正在大步邁進(jìn)新時代。
英特爾自己刷新自己
事實(shí)上,此次備受關(guān)注的CPU加速方案,背后不是別人,正是發(fā)明了CPU的英特爾。
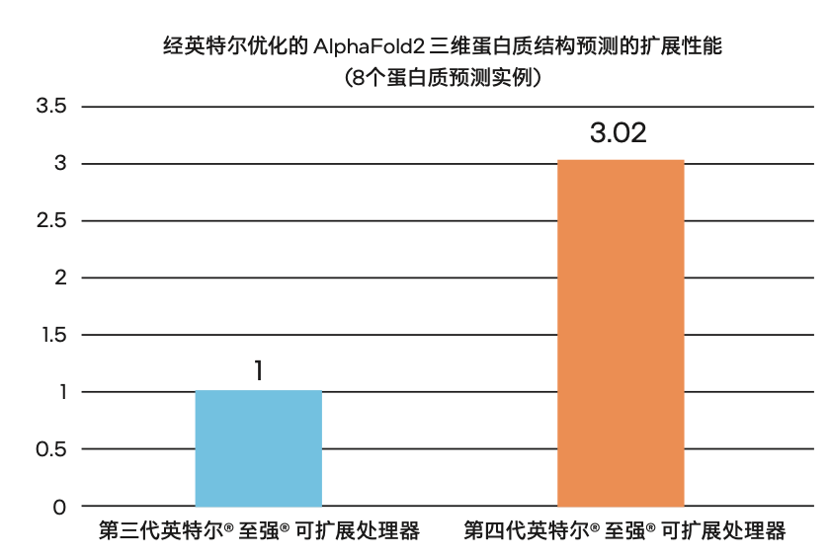
2022年,英特爾以第三代至強(qiáng)可擴(kuò)展處理器為硬件基座,使AlphaFold2通量優(yōu)化提升達(dá)23.11倍。一年后,他們在此基礎(chǔ)上,再次實(shí)現(xiàn)自我刷新。
2022年,英特爾基于第三代至強(qiáng) 可擴(kuò)展平臺,針對AlphaFold2的設(shè)計特點(diǎn),在預(yù)處理、模型推理、后處理三階段實(shí)現(xiàn)了端到端優(yōu)化。
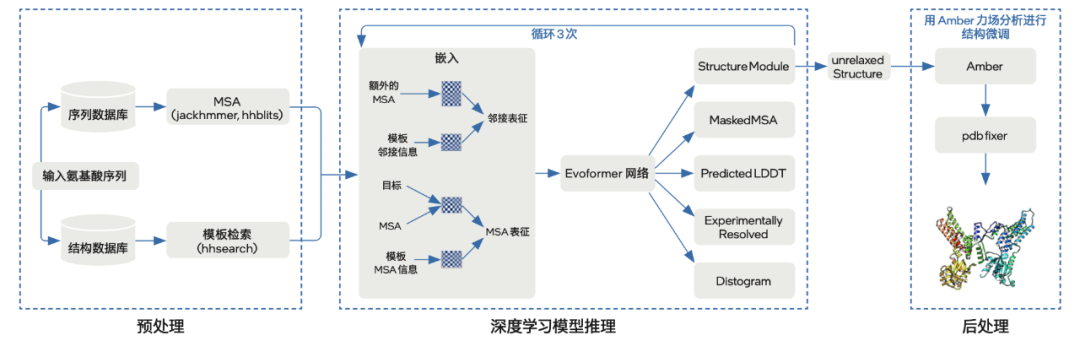
如今,原有的五大端到端基礎(chǔ)步驟之上,第四代至強(qiáng) 可擴(kuò)展處理器的加入,再次給AlphaFold2帶來整體推理性能的提升。
此次優(yōu)化方案主要圍繞預(yù)處理和模型推理兩個方面,基本劃分為五個步驟。
第一步:預(yù)處理階段,借助第三代或第四代至強(qiáng) 可擴(kuò)展處理器的多核優(yōu)勢及其內(nèi)置AVX-512技術(shù),實(shí)現(xiàn)針對性的高通量優(yōu)化。
第二步到第五步模型推理階段的優(yōu)化,與2022年方案類似。
第二步,將深度學(xué)習(xí)模型遷移至面向英特爾 架構(gòu)優(yōu)化的PyTorch,并逐模塊地從JAX/haiku完成代碼遷移。
第三步,引入JIT圖編譯技術(shù),將網(wǎng)格轉(zhuǎn)化為靜態(tài)圖,以提高模型推理速度。
第四步,切分注意力模塊和算子融合,即對注意力模塊進(jìn)行大張量切分的優(yōu)化思路;與此同時,使用IPEX(英特爾 擴(kuò)展優(yōu)化框架,建議版本為IPEX-2.0.100+cpu或更高)對Einsum和Add兩種算子進(jìn)行融合。
第五步,借助至強(qiáng) 可擴(kuò)展平臺的計算和存儲優(yōu)勢實(shí)施針對性優(yōu)化。比如基于NUMA架構(gòu)技術(shù),挖掘多核心優(yōu)勢,破解多實(shí)例運(yùn)算過程中的計算和內(nèi)存瓶頸。
不過除了提供更強(qiáng)的基礎(chǔ)算力,第四代至強(qiáng) 可擴(kuò)展平臺還帶來了諸多針對AI工作負(fù)載的優(yōu)化加速技術(shù)。
具體可以拆分為四項:(詳細(xì)優(yōu)化方案可點(diǎn)擊閱讀原文獲取)
一、TPP技術(shù)降低推理過程中的內(nèi)存消耗
TPP(Tensor Processing Primitives)相當(dāng)于是一種虛擬的張量指令集架構(gòu),能讓英特爾 AVX-512等物理指令集予以抽象,生成經(jīng)過優(yōu)化的平臺代碼。
具體到計算執(zhí)行上,TPP能實(shí)現(xiàn)兩種優(yōu)化方式:以單指令多數(shù)據(jù)方式處理數(shù)據(jù);優(yōu)化內(nèi)存訪問模式,提升緩存命中率來提高數(shù)值計算和訪存效率。
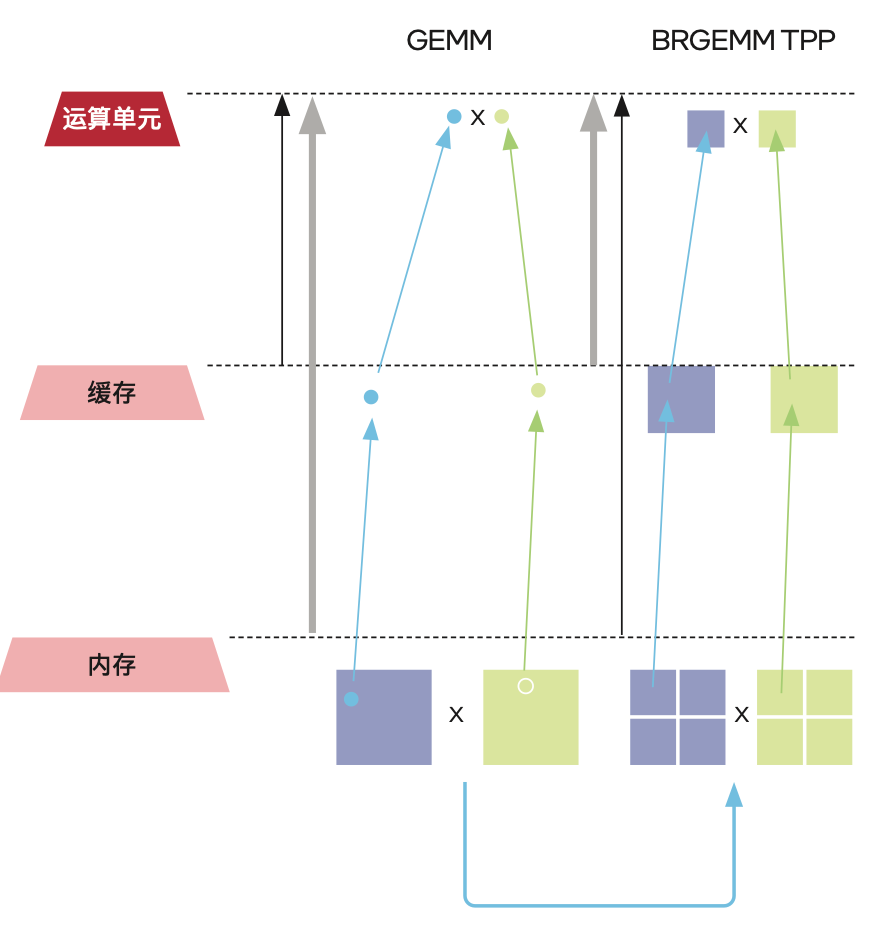
這樣一來,狹長矩陣乘法的空間復(fù)雜度從 O (n^2) 降為 O (n) ,運(yùn)算內(nèi)存峰值也將大幅降低,更有助于處理長序列蛋白結(jié)構(gòu)預(yù)測的問題。
二、支持DDR5內(nèi)存與大容量緩存帶來張量吞吐提升
AlphaFold2中大量的矩陣計算過程需要內(nèi)存來支撐,因此內(nèi)存性能影響著整個模型運(yùn)行性能。
第四代至強(qiáng) 可擴(kuò)展處理器帶來兩種解決思路——支持DDR5內(nèi)存,以及大容量末級緩存:
一方面,與上個方案DDR4內(nèi)存帶寬25.6GBps (3,200MHz)相比,DDR5內(nèi)存帶寬提升了超50%,達(dá)到38.4GBps (4,800MHz)以上 ;另一方面,末級緩存也由上一代的最高 60MB提升至現(xiàn)在最高112.5MB,幅度87.5%。
三、內(nèi)置AI加速引擎AMX
英特爾在第四代至強(qiáng) 可擴(kuò)展處理器中創(chuàng)新內(nèi)置了AI加速器——英特爾 AMX,類似GPU里的張量核心,加速深度學(xué)習(xí)推理過程并減少存儲空間。
它支持INT8、BF16等低精度數(shù)據(jù)類型,尤其BF16數(shù)據(jù)類型在精度上的表現(xiàn)不遜于FP32數(shù)據(jù)類型,AlphaFold2使用AMX_BF16后,推理時間可縮短數(shù)倍之多。
四、高帶寬內(nèi)存HBM2e增加訪存通量
每個英特爾 至強(qiáng) CPU Max系列,都擁有4個基于第二代增強(qiáng)型高帶寬內(nèi)存 (HBM2e) 的堆棧,總?cè)萘繛?4GB (每個堆棧的容量為16GB)。
由于能同時訪問多個DRAM芯片,它可提供高達(dá)1TB/s的帶寬。而且配置更靈活,有三種不同模式與DDR5內(nèi)存一起協(xié)同工作:HBM Only、HBM Flat以及HBM Cache。
綜上,第四代英特爾 至強(qiáng) 可擴(kuò)展處理器所帶來的四種優(yōu)化技術(shù)讓AlphaFold2的端到端通量得到了再進(jìn)一步提升,與第三代相比實(shí)現(xiàn)了高達(dá)3.02倍的多實(shí)例通量提升。
當(dāng)然,除了CPU之外,英特爾在探索驗證AlphaFold2優(yōu)化方案、步驟和經(jīng)驗過程中,同樣也能提供其他AI加速芯片,給產(chǎn)業(yè)鏈上的生態(tài)伙伴提供強(qiáng)勁支持。
甚至已經(jīng)給出了行業(yè)備受認(rèn)可的解決方案。
就在前段時間,英特爾聯(lián)合Github上知名的AI+科學(xué)計算的開源項目——Colossal-AI的團(tuán)隊潞晨科技,成功優(yōu)化了AlphaFold2蛋白質(zhì)結(jié)構(gòu)預(yù)測的性能,并將其方案開源。
基于AI專用加速芯片Habana Gaudi,他們成功將端到端推理速度最高提升3.86倍(相較于此前使用的方案),應(yīng)用成本相較于GPU方案最多降低39%。
醫(yī)藥和生命科學(xué)領(lǐng)域,AI還有何作為?
大模型,毋庸置疑是近來科技圈最為火爆的技術(shù)之一。
它憑借自身強(qiáng)算法、多數(shù)據(jù)、大算力的結(jié)合所帶來的泛用性,在醫(yī)藥和生命科學(xué)領(lǐng)域同樣大步發(fā)展著。
這一過程,AI宛如從破解人類的自然語言,躍進(jìn)到了破解生命的自然語言:
-
人類自然語言大模型:從26個字母,到詞/句/段。
-
生命自然語言大模型:從21個氨基酸字母,到蛋白質(zhì)/細(xì)胞/生命體。
那么具體而言,現(xiàn)在AI大模型可能會讓醫(yī)藥和生命科學(xué)領(lǐng)域產(chǎn)生怎樣的變革?
我們不妨以百圖生科推出的,世界首個AI大模型驅(qū)動的AI生成蛋白平臺AIGP(AI Generated Protein)為例來了解一番。
AIGP背后所依靠的,是一個千億參數(shù)的跨模態(tài)生命科學(xué)大模型,通過“挖掘公開數(shù)據(jù)和獨(dú)特自產(chǎn)數(shù)據(jù)”、“跨模態(tài)預(yù)訓(xùn)練和科學(xué)計算”,以及“蛋白質(zhì)讀寫系統(tǒng)和細(xì)胞讀寫系統(tǒng)”,三大步驟實(shí)現(xiàn)對蛋白質(zhì)空間及生命體的建模。
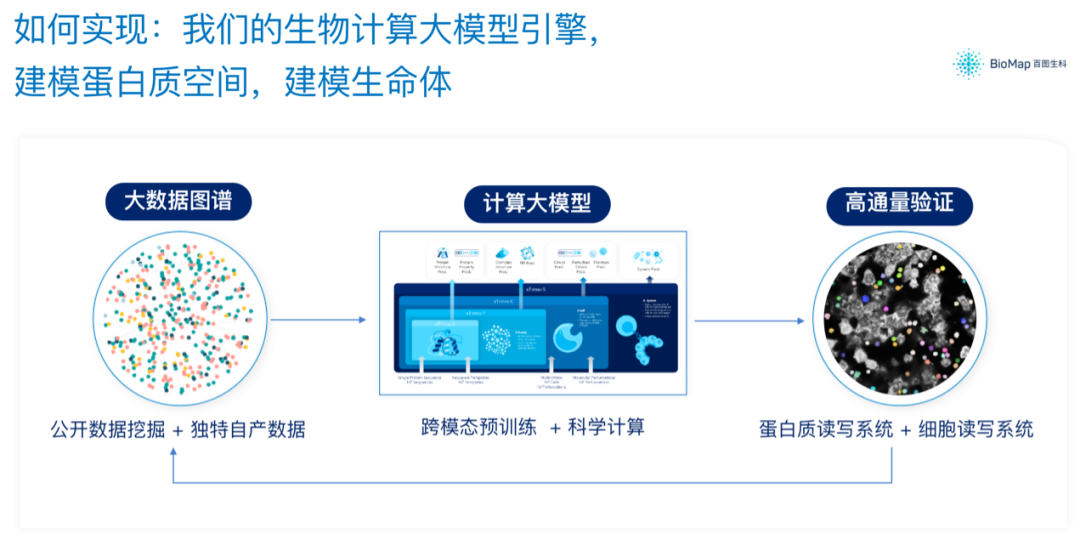
如此大模型能力之下,百圖生科便具備了一系列給定Protein(抗原),設(shè)計與之以特定方式結(jié)合的Protein(抗體)的能力。
也因此參與到了一系列前沿藥物的開發(fā),包括高性能免疫調(diào)控彈頭設(shè)計、難成藥靶點(diǎn)精準(zhǔn)設(shè)計、定表位抗體彈頭設(shè)計、可溶性TCR設(shè)計等。
除此之外,百圖生科也具備對給定細(xì)胞/細(xì)胞組合,發(fā)現(xiàn)調(diào)控細(xì)胞的有效蛋白靶點(diǎn)/組合,并繼而快速設(shè)計調(diào)控蛋白的能力。
這就為多種疾病的靶點(diǎn)發(fā)現(xiàn)、耐藥/不響應(yīng)患者改善、靶點(diǎn)科學(xué)線索轉(zhuǎn)化帶來新的可能。
不過有一說一,百圖生科的例子也是只是AI之于醫(yī)藥、生命科學(xué)領(lǐng)域變革的一隅。
但今年生物醫(yī)學(xué)領(lǐng)域的著名獎項(加拿大蓋爾德納獎)史無前例地頒給了人工智能科學(xué)家、DeepMind創(chuàng)始人Demis Hassabis等人。
這也從側(cè)面反映了生命科學(xué)、醫(yī)藥領(lǐng)域?qū)τ贏I的認(rèn)可,以及更多的期待。
如果您對本文涉及的基于Habana Gaudi與英特爾 至強(qiáng) 可擴(kuò)展處理器對AlphaFold2進(jìn)行端到端優(yōu)化的技術(shù)細(xì)節(jié)感興趣,如果您也想了解百圖生科在AIGP領(lǐng)域的最新進(jìn)展,英特爾《至強(qiáng)實(shí)戰(zhàn)課》之《AI驅(qū)動的生命科學(xué)與醫(yī)藥創(chuàng)新》將為您帶來更加全面且詳細(xì)的真人講解,歡迎大家注冊收看~
以及想要了解更多第四代至強(qiáng)可擴(kuò)展平臺對AlphaFold2的優(yōu)化方案,請點(diǎn)擊【閱讀原文】。

-
英特爾
+關(guān)注
關(guān)注
61文章
9974瀏覽量
171818 -
cpu
+關(guān)注
關(guān)注
68文章
10870瀏覽量
211878
原文標(biāo)題:預(yù)測超長蛋白質(zhì)這事,CPU贏了
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
AI先驅(qū)榮獲諾貝爾物理學(xué)獎和化學(xué)獎
“天鶩科技”完成超億元A輪融資
AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第4章-AI與生命科學(xué)讀后感
AI實(shí)火!諾貝爾又把化學(xué)獎頒給AI大模型
差示掃描量熱儀測試蛋白質(zhì)的應(yīng)用案例

創(chuàng)客中國AIGC專題賽冠軍天鶩科技:AI蛋白質(zhì)設(shè)計引領(lǐng)者

EvolutionaryScale推出基于NVIDIA GPU模型的新型蛋白質(zhì)研究方案
利用微流控探針誘導(dǎo)的化學(xué)質(zhì)膜穿孔,實(shí)現(xiàn)單細(xì)胞胞內(nèi)蛋白質(zhì)遞送
一種基于可拉伸光子晶體的熒光傳感陣列,用于卵巢癌早期診斷
基于熵驅(qū)動鏈置換策略的高靈敏mRNA檢測與細(xì)胞內(nèi)成像研究
洪亮團(tuán)隊在生信期刊JCIM發(fā)布最新成果,蛋白質(zhì)工程邁入通用人工智能時代
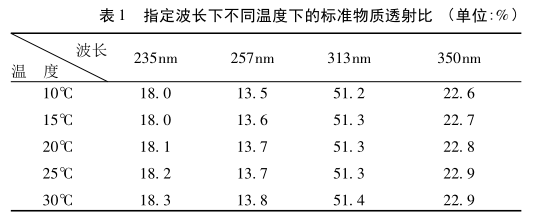
超微量分光光度計檢測方法研究
天府錦城實(shí)驗室在生物傳感與蛋白質(zhì)測序領(lǐng)域取得重要進(jìn)展

一種基于分子編程和液滴微流控的替代性技術(shù)用于數(shù)字檢測






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論