") 用于圖像分類(lèi)和物體檢測(cè)的深度學(xué)習(xí)
用于圖像分類(lèi)和物體檢測(cè)的深度學(xué)習(xí)
這個(gè)Dataiku platform日常人工智能簡(jiǎn)化了深度學(xué)習(xí)。用例影響深遠(yuǎn),從圖像分類(lèi)到對(duì)象檢測(cè)和自然語(yǔ)言處理( NLP )。 Dataiku 可幫助您對(duì)代碼和代碼環(huán)境進(jìn)行標(biāo)記、模型培訓(xùn)、可解釋性、模型部署以及集中管理。
本文深入探討了用于圖像分類(lèi)和對(duì)象檢測(cè)的高級(jí) Dataiku 和 NVIDIA 集成。它還涵蓋了實(shí)時(shí)推理的深度學(xué)習(xí)模型部署以及如何使用開(kāi)源RAPIDS和 cuML 庫(kù),用于客戶支持 Tweet 主題建模用例。 NVIDIA 提供硬件 (NVIDIA A10 Tensor Core GPUs,在這種情況下)和各種 OSS(CUDA,RAPIDS) 完成工作
請(qǐng)注意,本文中的所有 NVIDIA AI 軟件都可以通過(guò)NVIDIA AI Enterprise,一個(gè)用于生產(chǎn)人工智能的安全端到端軟件套件,由 NVIDIA 提供企業(yè)支持
用于圖像分類(lèi)和物體檢測(cè)的深度學(xué)習(xí)
本節(jié)介紹使用 Dataiku 和 NVIDIA GPU 訓(xùn)練和評(píng)估用于圖像分類(lèi)或?qū)ο髾z測(cè)的深度學(xué)習(xí)模型的步驟
無(wú)代碼方法
從 Dataiku 11.3 開(kāi)始,您可以使用可視化的無(wú)代碼工具來(lái)實(shí)現(xiàn)圖像分類(lèi)或?qū)ο髾z測(cè)工作流程的核心領(lǐng)域。您可以使用本地 web 應(yīng)用程序標(biāo)記圖像、繪制邊界框和查看/管理注釋。圖像標(biāo)記是訓(xùn)練性能模型的關(guān)鍵:→ 很好的模型。
使用 Dataiku 的圖像標(biāo)記工具,您可以將所有貓標(biāo)記為“貓”,或者更精細(xì)地標(biāo)記,以適應(yīng)獨(dú)特的外表或個(gè)性特征
Dataiku 使您能夠訓(xùn)練圖像分類(lèi)和對(duì)象檢測(cè)模型,特別是使用遷移學(xué)習(xí)來(lái)微調(diào)基于自定義圖像/標(biāo)簽/邊界框的預(yù)訓(xùn)練模型。數(shù)據(jù)增強(qiáng)重新著色、旋轉(zhuǎn)和裁剪訓(xùn)練圖像是增加訓(xùn)練集大小并將模型暴露在各種情況下的常用方法。
EfficientNet (圖像分類(lèi))和 Faster R-CNN (對(duì)象檢測(cè))神經(jīng)網(wǎng)絡(luò)可以在模型再訓(xùn)練用戶界面中與預(yù)先訓(xùn)練的權(quán)重一起使用,開(kāi)箱即用。
在將模型訓(xùn)練為自定義圖像標(biāo)簽和邊界框之后,可以使用疊加的熱圖模型焦點(diǎn)來(lái)解釋模型的預(yù)測(cè)。
一旦您對(duì)模型的性能感到滿意,就將經(jīng)過(guò)訓(xùn)練的模型作為容器化推理服務(wù)部署到 Kubernetes 集群中。這是由 Dataiku API Deployer 工具管理的。
計(jì)算發(fā)生在哪里?
Dataiku 可以將深度學(xué)習(xí)模型訓(xùn)練、解釋和推理背后的所有計(jì)算推送給 NVIDIA PyTorch (圖 4 )。您甚至可以通過(guò) GPU 利用多個(gè) GPU 進(jìn)行分布式培訓(xùn)DistributedDataParallel模塊和 TensorFlowMirroredStrategy.
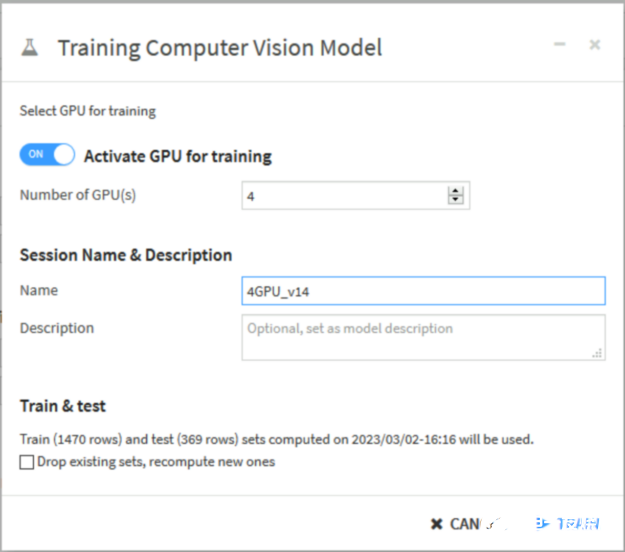 圖 4 。使用 Dataiku 接口激活 NVIDIA GPU 進(jìn)行深度學(xué)習(xí)模型訓(xùn)練
圖 4 。使用 Dataiku 接口激活 NVIDIA GPU 進(jìn)行深度學(xué)習(xí)模型訓(xùn)練
通過(guò)Dataiku Elastic AI集成。首先,將您的 Dataiku 實(shí)例連接到具有 NVIDIA GPU 資源(通過(guò) EKS 、 GKE 、 AKS 、 OpenShift 管理)的 Kubernetes 集群。然后 Dataiku 將創(chuàng)建 Docker 鏡像并在后臺(tái)部署容器
深度學(xué)習(xí)訓(xùn)練和推理作業(yè)可以在 Kubernetes 集群上運(yùn)行,也可以在任意 Python 代碼或 Apache Spark 作業(yè)上運(yùn)行。
對(duì)模型訓(xùn)練腳本進(jìn)行編碼
如果你想在 Python 中自定義你自己的深度學(xué)習(xí)模型,可以嘗試在 MLflow 實(shí)驗(yàn)跟蹤器中封裝一個(gè) train 函數(shù)。圖 6 顯示了一個(gè)基于 Python 的流程。請(qǐng)參閱中的機(jī)器學(xué)習(xí)教程Dataiku Developer Guide例如。這種方法提供了自定義代碼的完全靈活性,以及一些開(kāi)箱即用的實(shí)驗(yàn)跟蹤、模型分析可視化,以及 Dataiku 中經(jīng)過(guò)可視化訓(xùn)練的模型的點(diǎn)擊式模型部署
自定義 Python 深度學(xué)習(xí)模型可以通過(guò)容器化執(zhí)行來(lái)利用 NVIDIA GPU ,就像 Dataiku 中經(jīng)過(guò)視覺(jué)訓(xùn)練的深度學(xué)習(xí)模型一樣(圖 7 )。
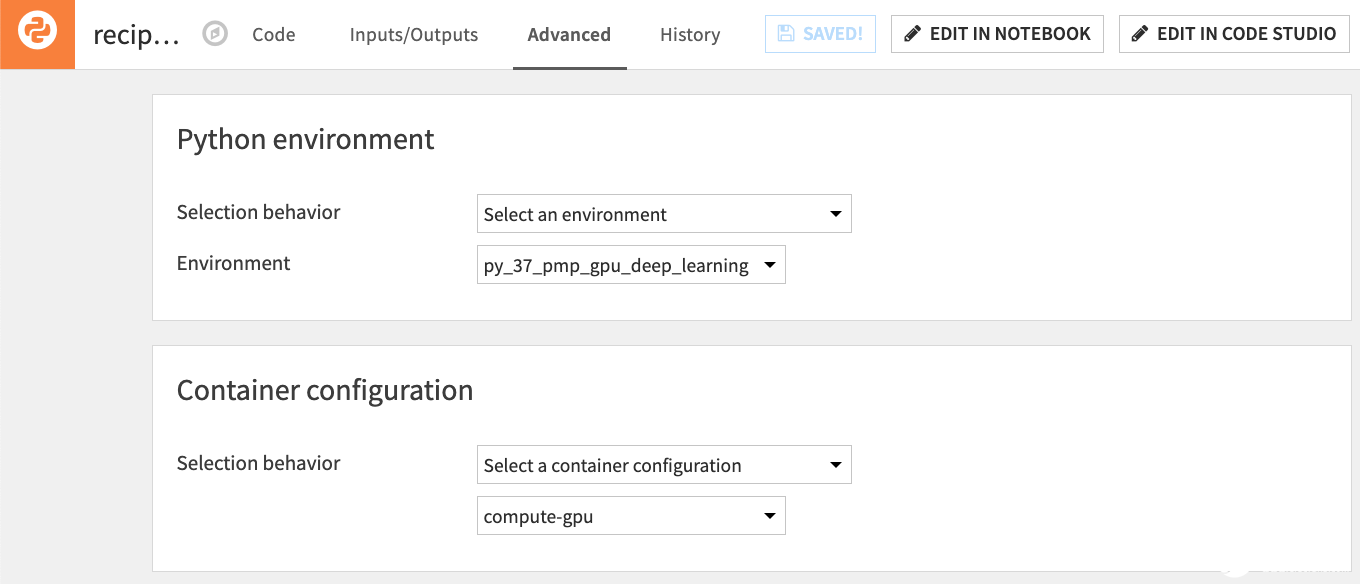 圖 7 。 Dataiku 中的任何 Python 工作負(fù)載都可以推送到具有 NVIDIA GPU 資源的 Kubernetes 集群
圖 7 。 Dataiku 中的任何 Python 工作負(fù)載都可以推送到具有 NVIDIA GPU 資源的 Kubernetes 集群
用于實(shí)時(shí)推理的模型部署
一旦模型經(jīng)過(guò)訓(xùn)練,就到了部署它進(jìn)行實(shí)時(shí)推理的時(shí)候了。如果您使用 Dataiku 的視覺(jué)圖像分類(lèi)、對(duì)象檢測(cè)或帶有 MLflow 的自定義編碼模型,然后作為 Dataiku 模型導(dǎo)入,只需單擊幾下即可在經(jīng)過(guò)訓(xùn)練的模型上創(chuàng)建容器化推理 API 服務(wù)。
首先,將 Dataiku API Deployer 工具連接到 Kubernetes 集群,以托管這些推理 API 服務(wù),同樣在集群節(jié)點(diǎn)中提供 NVIDIA GPU 。然后在負(fù)載均衡器后面部署容器化服務(wù)的 1-N 個(gè)副本。從這里開(kāi)始,邊緣設(shè)備可以向 API 服務(wù)發(fā)送請(qǐng)求,并接收來(lái)自模型的預(yù)測(cè)。圖 8 顯示了整個(gè)體系結(jié)構(gòu)。
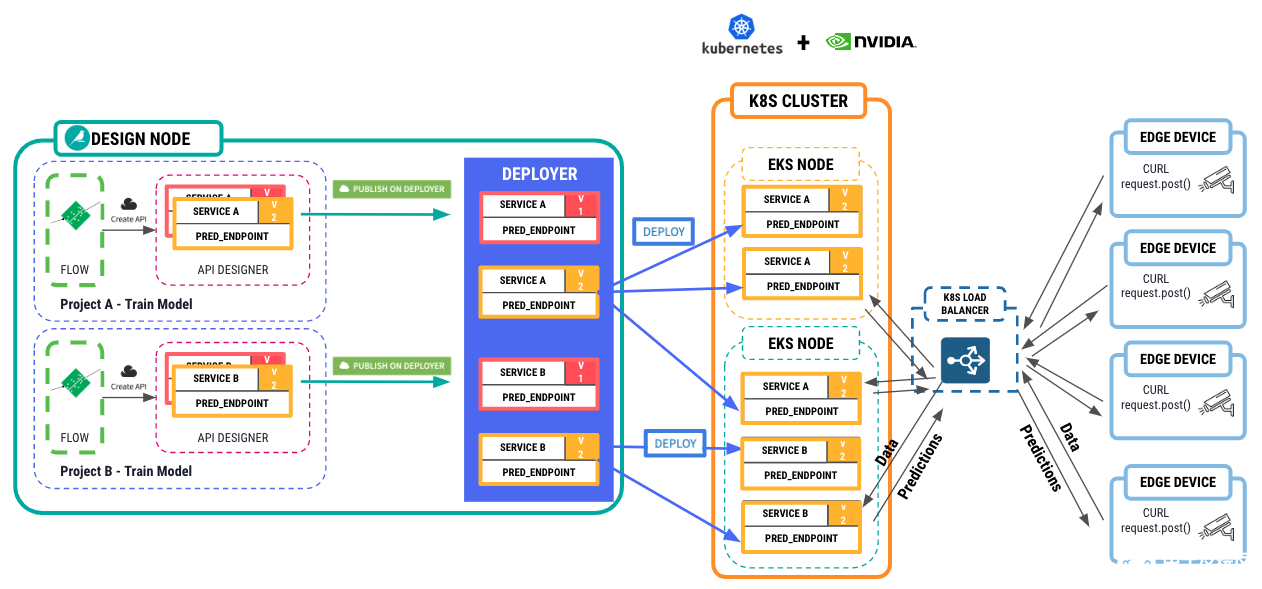 create API service in the API Designer > push the API service to the Deployer > push the API Service to a K8S cluster with NVIDIA GPU resources. From there, edge devices can submit requests to the API service with data, images, and receive predictions back.” width=”1262″ height=”589″> 圖 8 。從在 Dataiku 中訓(xùn)練的模型到托管在具有 NVIDIA GPU 的 Kubernetes 集群上的 API 服務(wù)的工作流,用于推理
create API service in the API Designer > push the API service to the Deployer > push the API Service to a K8S cluster with NVIDIA GPU resources. From there, edge devices can submit requests to the API service with data, images, and receive predictions back.” width=”1262″ height=”589″> 圖 8 。從在 Dataiku 中訓(xùn)練的模型到托管在具有 NVIDIA GPU 的 Kubernetes 集群上的 API 服務(wù)的工作流,用于推理
教程:在 Dataiku 中使用帶有 RAPIDS 的 BERT 模型加速主題建模
為了更深入地了解,本節(jié)將介紹如何在 Dataiku 中設(shè)置 Python 環(huán)境,以便將 BERTopic 與 RAPIDS 中的 GPU 加速 cuML 庫(kù)一起使用。它還強(qiáng)調(diào)了使用 cuML 獲得的性能增益
此示例使用Kaggle Customer Support on Twitter dataset以及主題建模的關(guān)鍵客戶投訴主題。
步驟 1 。準(zhǔn)備數(shù)據(jù)集
首先,通過(guò)刪除標(biāo)點(diǎn)符號(hào)、停止詞和詞尾詞來(lái)規(guī)范推文文本。還要將數(shù)據(jù)集過(guò)濾為客戶在推特上用英語(yǔ)發(fā)布的投訴。所有這些都可以使用 Dataiku 可視化配方來(lái)完成。
使用拆分配方從初始用戶推文中過(guò)濾公司的回復(fù)。接下來(lái),使用 Dataiku 的Text Preparation plugin檢測(cè)用戶推文中語(yǔ)言分布的配方。
使用過(guò)濾配方過(guò)濾掉所有非英語(yǔ)和空白的推文。一定要使用文本準(zhǔn)備方法來(lái)過(guò)濾停止詞、標(biāo)點(diǎn)符號(hào)、 URL 、表情符號(hào)等。將文本轉(zhuǎn)換為小寫(xiě)。
最后,使用分割配方來(lái)分割用于訓(xùn)練和測(cè)試的數(shù)據(jù)(簡(jiǎn)單的 80% / 20% 隨機(jī)分割)。
步驟 2 。使用 BERTopic 和 RAPIDS 庫(kù)設(shè)置 Python 環(huán)境
運(yùn)行 Python 進(jìn)程需要一個(gè)具有 NVIDIA GPU 的彈性計(jì)算環(huán)境BERTopic package(及其所需的包裝),以及 RAPIDS 容器圖像。此示例使用 Amazon EKS 集群(實(shí)例類(lèi)型: g4dnNVIDIA A10 Tensor Core GPUs) ,RAPIDS Release Stable 22.12和 BERTopic ( 0.12.0 )。
首先,在 Dataiku 中啟動(dòng)一個(gè) EKS 集群。設(shè)置集群后,您可以在“管理”下的“集群”選項(xiàng)卡中檢查其狀態(tài)和配置。
BER 主題
使用 Dataiku 的托管虛擬代碼環(huán)境,使用 BERTopic 及其所需的包創(chuàng)建 Dataiku 代碼環(huán)境。
RAPIDS
使用 Docker Hub 中的 RAPIDS 映像構(gòu)建一個(gè)容器環(huán)境。在 Dataiku 中,為您的代碼環(huán)境使用 Dataiku 基本映像,或者從 DockerHub 或NGC。然后,將您的 Dataiku 代碼環(huán)境附加到它。請(qǐng)注意, NVIDIA 已經(jīng)在 PyPi 上發(fā)布了 RAPIDS ,所以您現(xiàn)在可以只使用默認(rèn)的 Dataiku 基本映像。
步驟 3 。使用默認(rèn) UMAP 運(yùn)行 BERTopic
接下來(lái),使用 BERTopic 從 Twitter 投訴中找出前五個(gè)話題。要在 GPU 上加速 UMAP 進(jìn)程,請(qǐng)使用 cuML UMAP 。默認(rèn) UMAP 如下所示:
# -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE # -*- coding: utf-8 -*- import dataiku import pandas as pd, numpy as np from dataiku import pandasutils as pdu from bertopic import BERTopic # -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE # Read the train dataset in the dataframe and the variable sample_size which defines the number of records to be used sample_size = dataiku.get_custom_variables()["sample_size"] train_data = dataiku.Dataset("train_cleaned") train_data_df = train_data.get_dataframe(sampling='head',limit=sample_size) # -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE # Create Bertopic object and run fit transform topic_model = BERTopic(calculate_probabilities=True,nr_topics=4) topics, probs = topic_model.fit_transform(train_data_df["Review Description_cleaned"]) all_topics_rapids_df = topic_model.get_topic_info() # -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE #Write the List of Topics output as a DSS Dataset Topic_Model_df = all_topics_rapids_df Topic_Model_w_Rapids = dataiku.Dataset("Topic_Model") Topic_Model_w_Rapids.write_with_schema(Topic_Model_df) RAPIDS cuML UMAP: # -*- coding: utf-8 -*- import dataiku import pandas as pd, numpy as np from dataiku import pandasutils as pdu from bertopic import BERTopic from cuml.manifold import UMAP from cuml.cluster.hdbscan.prediction import approximate_predict # -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE # Read the train dataset in the dataframe and the variable sample_size which defines the number of records to be used sample_size = dataiku.get_custom_variables()["sample_size"] train_data = dataiku.Dataset("train_cleaned") train_data_df = train_data.get_dataframe(sampling='head',limit=sample_size) # -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE # Create a cuML UMAP Obejct and pass it in the Bertopic object and run fit transform umap_model = UMAP(n_components=5, n_neighbors=15, min_dist=0.0) cu_topic_model = BERTopic(calculate_probabilities=True,umap_model=umap_model,nr_topics=4) cu_topics, cu_probs = cu_topic_model.fit_transform(train_data_df["Review Description_cleaned"]) all_topics_rapids_df = cu_topic_model.get_topic_info() # -------------------------------------------------------------------------------- NOTEBOOK-CELL: CODE # Write the List of Topics output as a DSS Dataset Topic_Model_w_Rapids_df = all_topics_rapids_df Topic_Model_w_Rapids = dataiku.Dataset("Topic_Model_w_Rapids") Topic_Model_w_Rapids.write_with_schema(Topic_Model_w_Rapids_df)
UMAP 對(duì)整個(gè)計(jì)算時(shí)間有很大貢獻(xiàn)。在帶有 cuML RAPIDS 的 NVIDIA GPU 上運(yùn)行 UMAP 可實(shí)現(xiàn) 4 倍的性能提升。可以通過(guò)在 GPU 上運(yùn)行更多的算法來(lái)實(shí)現(xiàn)額外的改進(jìn),例如使用 cuML HDBSCAN 。
| 不帶 RAPIDS 的主題建模過(guò)程 | 運(yùn)行時(shí) |
| 不帶 RAPIDS | 12 分 21 秒 |
| 帶 RAPIDS | 2 分 59 秒 |
表 1 。使用 RAPIDS AI 進(jìn)行配置可實(shí)現(xiàn) 4 倍的性能提升
步驟 4 。投訴聚類(lèi)儀表板
最后,您可以在 Dataiku 中的輸出數(shù)據(jù)集(帶有干凈的 Tweet 文本和主題)上構(gòu)建各種看起來(lái)很酷的圖表,并將其推送到儀表板上進(jìn)行執(zhí)行團(tuán)隊(duì)審查(圖 13 )。
圖 13 。 Dataiku 儀表板在一個(gè)中心位置顯示各種指標(biāo)
把它們放在一起
如果您希望將深度學(xué)習(xí)用于圖像分類(lèi)、對(duì)象檢測(cè)或 NLP 用例, Dataiku 可以幫助您標(biāo)記、模型訓(xùn)練、可解釋性、模型部署以及集中管理代碼和代碼環(huán)境。與最新的 NVIDIA 數(shù)據(jù)科學(xué)庫(kù)和計(jì)算硬件的緊密集成構(gòu)成了一個(gè)完整的堆棧。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5075瀏覽量
103537 -
人工智能
+關(guān)注
關(guān)注
1794文章
47642瀏覽量
239671
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
華為云ModelArts入門(mén)開(kāi)發(fā)(完成物體分類(lèi)、物體檢測(cè))

深度學(xué)習(xí)DeepLearning實(shí)戰(zhàn)
深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
基于深度學(xué)習(xí)和3D圖像處理的精密加工件外觀缺陷檢測(cè)系統(tǒng)
設(shè)計(jì)一個(gè)紅外物體檢測(cè)設(shè)備
討論紋理分析在圖像分類(lèi)中的重要性及其在深度學(xué)習(xí)中使用紋理分析
基于運(yùn)動(dòng)估計(jì)的運(yùn)動(dòng)物體檢測(cè)技術(shù)研究
圖像分類(lèi)的方法之深度學(xué)習(xí)與傳統(tǒng)機(jī)器學(xué)習(xí)
深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)上的四大應(yīng)用
傳統(tǒng)檢測(cè)、深度神經(jīng)網(wǎng)絡(luò)框架、檢測(cè)技術(shù)的物體檢測(cè)算法全概述
深度學(xué)習(xí)中圖像分割的方法和應(yīng)用
詳解深度學(xué)習(xí)之圖像分割
基于PyTorch的深度學(xué)習(xí)入門(mén)教程之PyTorch的安裝和配置
淺析FPGA的圖像采集和快速移動(dòng)物體檢測(cè)
分享使用圖像分割來(lái)做缺陷檢測(cè)的一個(gè)例子





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論