 數據湖真的能取代數據倉庫嗎?【SNP SAP數據轉型 】
數據湖真的能取代數據倉庫嗎?【SNP SAP數據轉型 】
數據湖和數據倉庫的存在并不沖突,也并不是取代的關系,而是相互的融合關系。
數據湖是近兩年中比較新的技術在大數據領域中,對于一個真正的數據湖應該是什么樣子,現在對數據湖認知還是處在探索的階段,像現在代表的開源產品有iceberg、hudi、Delta Lake。
那對于數據湖應該是什么樣子,先來看數據湖的作者AWS來說明數據湖是什么東西,比如下圖:
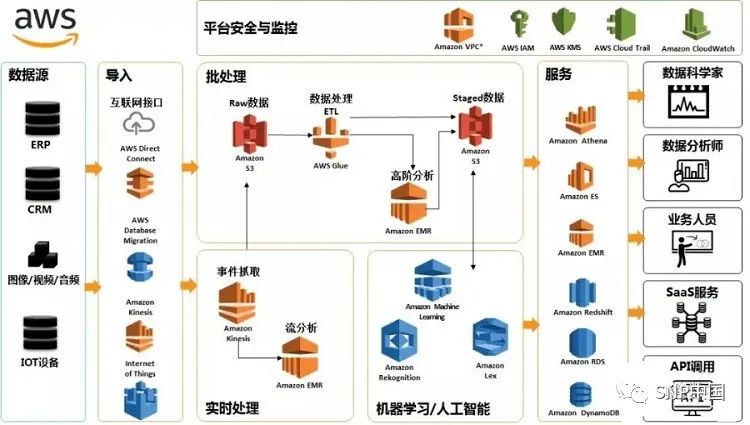
圖片來源:談數據-探秘AWS數據湖
不懂數據的人也許會覺得數據湖很厲害,而懂數據的人也許會覺得僅是一堆數據倉庫技術的堆砌包裝而已,你看上面那張框架圖,哪個專業詞匯數據人士會不懂?憑什么數據湖被炒作成了一個新概念?
而對于數據湖的定義則是:
數據湖是一個集中式存儲庫,允許您以任意規模存儲所有結構化和非結構化數據。您可以按原樣存儲數據(無需先對數據進行結構化處理),并運行不同類型的分析 – 從控制面板和可視化到大數據處理、實時分析和機器學習,以指導做出更好的決策。
那么數據湖和我們早先的數據倉庫究竟有什么樣的區別呢:
數據倉庫是一個優化的數據庫,用于分析來自事務系統和業務線應用程序的關系數據。事先定義數據結構和 Schema 以優化快速 SQL 查詢,其中結果通常用于操作報告和分析。數據經過了清理、豐富和轉換,因此可以充當用戶可信任的“單一信息源”。
數據湖有所不同,因為它存儲來自業務線應用程序的關系數據,以及來自移動應用程序、IoT 設備和社交媒體的非關系數據。捕獲數據時,未定義數據結構或 Schema。這意味著您可以存儲所有數據,而不需要精心設計也無需知道將來您可能需要哪些問題的答案。您可以對數據使用不同類型的分析(如 SQL 查詢、大數據分析、全文搜索、實時分析和機器學習)來獲得見解。
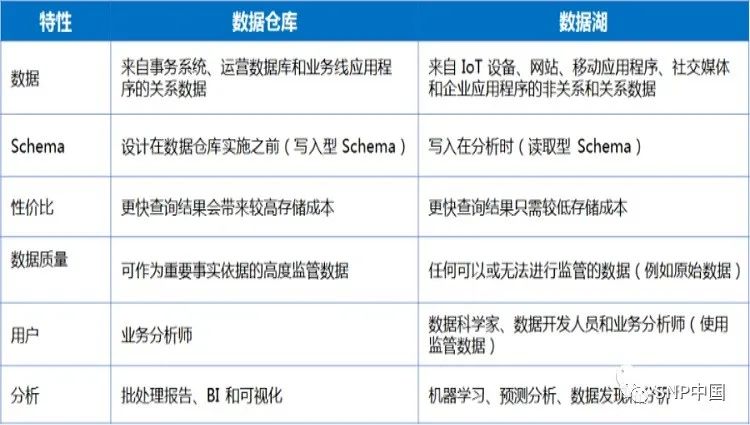
從介紹來看好像數據倉庫和數據湖的最主要的區別就是對結構化的數據和非結構化數據的存儲,但是真的僅僅是這樣嗎?
事實上,這種比較有較大邏輯漏洞:即是從結果出發來看差異,然后又用這個差異來說明區別,顛倒了因果。比如AWS的數據湖能夠處理非結構化數據,而數據倉庫無法處理非結構化數據,就認為這是數據湖與數據倉庫的本質區別之一。
下面的文章中將來探索數據湖和數據倉庫究竟有什么樣的區別,學習一個新的事物要一步步的發現這個事物的本質是什么。

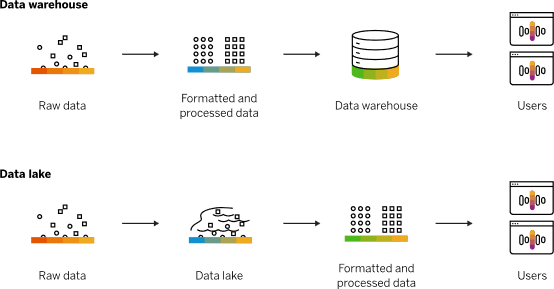
數據倉庫和數據湖的處理流程可以用下圖來示意,其中用紅圈標出了5個對標的流程節點。
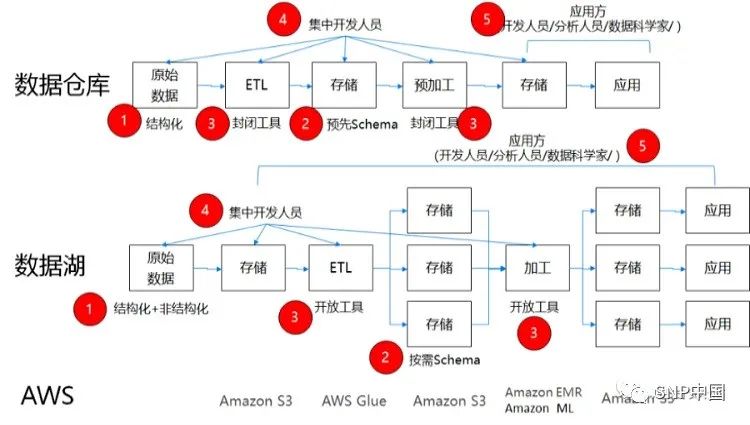
從圖中可以看出來數據湖并不比數據倉庫在處理流程上多出了什么內容,更多的在于結構性的變化,下面就從數據存儲、模型設計、加工工具、開發人員和消費人員五個方面來進行比較。
數據存儲
數據倉庫采集、處理過程中存儲下來的數據一般是以結構化的形式存在的,即使原始數據是非結構化的,但這些非結構化數據也只是在源頭暫存一下,它通過結構化數據的形式進入數據倉庫,成了數據倉庫的基本存儲格式,這個跟數據倉庫的模型(維度或關系建模)都是建立在關系型數據基礎上的特點有關。
事實上,是傳統的數據建模負擔讓數據倉庫只處理結構化數據,其實誰都沒規定過數據倉庫只處理和存儲結構化數據。
數據湖包羅萬象,輕裝上陣,結構化與非結構化數據都成為了數據湖本身的一部分,這體現了數據湖中“湖”這個概念。因為沒有數據倉庫建模的限制,當然什么東西都可以往里面扔,但這為其變成數據沼澤埋下了伏筆。
模型設計
數據倉庫中所有的Schema(比如表結構)都是預先設計并生成好的,數據倉庫建設最重要的工作就是建模,其通過封裝好的、穩定的模型對外提供有限的、標準化的數據服務,模型能否設計的高內聚、松耦合成了評估數據倉庫好壞的一個標準,就好比數據中臺非常強調數據服務的復用性一樣。
你會發現,數據倉庫很像數據領域的計劃經濟,所有的產品(模型)都是預先生成好的,模型可以變更,但相當緩慢。
數據湖的模型不是預先生成的,而是隨著每個應用的需要即時設計生成的,其更像是市場經濟的產物,犧牲了復用性卻帶來了靈活性,這也是為什么數據湖的應用更多強調探索分析的原因。
加工工具
數據倉庫的采集、處理工具一般是比較封閉的,很多采取代碼的方式暴力實現,大多只向集中的專業開發人員開放,主要的目的是實現數據的統一采集和建模,它不為消費者(應用方)服務,也沒這個必要。
數據湖的采集和處理工具是完全開放的,因為第(2)點提到過:數據湖的模型是由應用即席設計生成的,意味著應用必須具備針對數據湖數據的直接ETL能力和加工能力才能完成定制化模型的建設,否則就沒有落地的可能,更無靈活性可言。
工具能否開放、體驗是否足夠好是數據湖能夠成功的一個前提,顯然傳統數據倉庫的一些采集和開發工具是不行的,它們往往不可能向普通大眾開放。
開發人員
數據倉庫集中開發人員處理數據涵蓋了數據采集、存儲、加工等各個階段,其不僅要管理數據流,也要打造工具流。
由于數據流最終要為應用服務,因此其特別關注數據模型的質量,而工具流只要具備基本的功能、滿足性能要求就可以了,反正是數據倉庫團隊人員自己用,導致的后果是害苦了運營人員。
數據湖完全不一樣,集中開發人員在數據流階段只負責把原始數據扔到數據湖,更多的精力花在對工具流的改造上,因為這些工具是直接面向最終使用者的,假如不好用,數據湖就不能用了。
應用人員
數據倉庫對于應用人員暴露的所有東西就是建好的數據模型,應用方的所有角色只能在數據倉庫限定好的數據模型范圍內倒騰,這在一定程度上限制了應用方的創新能力。比如原始數據有個字段很有價值,但數據倉庫集中開發人員卻把它過濾了。
這種問題在數據倉庫中很常見,很多取數人員只會取寬表,對于源端數據完全不清楚,所謂成也數據倉庫,敗也數據倉庫。
數據湖的應用方則可以利用數據湖提供的工具流接觸到最生鮮的原始數據,涵蓋了從數據采集、抽取、存儲、加工的各個階段,其可以基于對業務的理解,壓榨出原始數據的最大價值。
可以看到,數據倉庫和數據湖,代表著兩種數據處理模式和服務模式,是數據技術領域的一次輪回。
早在ORACLE的DBLINK時代,我們就有了第一代的數據湖,因為那個時候ORACLE一統天下,ORALCE的DBLINK讓直接探索原始數據有了可能。
隨著數據量的增長和數據類型的不斷豐富,我們不得不搞出一種新的“數據庫”來集成各種數據。
但那個時候搞出的為什么是數據倉庫而不是數據湖呢?
主要還是應用驅動力的問題。
因為那個時候大家關注的是報表,而報表最核心的要求就是準確性和一致性,標準化、規范化的維度和關系建模正好適應了這一點,集中化的數據倉庫支撐模式就是一種變相的計劃經濟。
隨著大數據時代到來和數字化的發展,很多企業發現,原始數據的非結構化比例越來越高,前端應用響應的要求越來越高,海量數據挖掘的要求越來越對,報表取數已經滿足不了數據驅動業務的要求了。
一方面企業需要深挖各種數據,從展示數據為主(報表)逐步向挖掘數據(探索預測)轉變,另一方面企業也需要從按部就班的支撐模式向快速靈活的方向轉變,要求數據倉庫能夠開放更多的靈活性給應用方,這個時候數據倉庫就有點撐不住了。
數據湖就是在這種背景下誕生的。
其實早在數據湖出來之前,很多企業就在做類似數據湖的工作了,但是只不過大家更多的集中在數據倉庫結構化的數據處理中,對于非結構化的數據日志等更多的則是將其存儲起來,對于需要的時候再通過應用程序進行處理獲取到自己想要的結果,只不過是沒有系統化的處理而已。
ETL之所以不開放,主要是驅動力不夠,其實我們沒有那么多類型的數據要定制化抽取。
很多企業不搞可視化開發平臺也是容易理解的,報表就能活得很好,干嘛業務人員要自己開發和挖掘。現在數據湖叫的歡的,大多是互聯網公司,比如亞馬遜,這是很正常的。
而最近比較新的概念湖倉一體,阿里提出的概念,下面這張圖來看一下
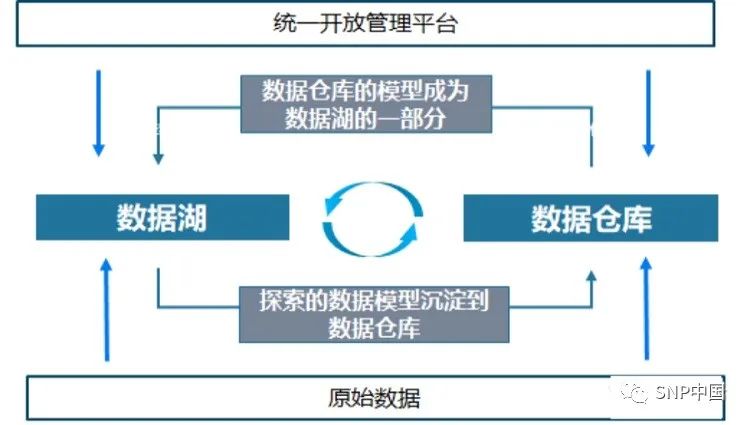
何謂湖倉一體?
湖倉一體是一種新的數據管理模式,將數據倉庫和數據湖兩者之間的差異進行融合,并將數據倉庫構建在數據湖上,從而有效簡化了企業數據的基礎架構,提升數據存儲彈性和質量的同時還能降低成本,減小數據冗余。
湖和倉的數據/元數據無縫打通,互相補充,數據倉庫的模型反哺到數據湖(成為原始數據一部分),湖的結構化應用知識沉淀到數據倉庫。
湖倉一體架構主要的一點是實現“湖里”和“倉里”的數據能夠無縫打通,對數據倉庫的彈性和數據湖的靈活性進行有效集成,在該架構中,主要將數據湖作為中央存儲庫,將機器學習、數據倉庫、日志分析、大數據等技術進行整合,形成一套數據服務環,更好地分析、整合數據,讓數據倉庫和數據湖中的數據可以自由流動,用戶可以更便捷地調取其中的數據,讓數據“入湖”、“出湖”更為便捷。
湖倉一體化,是將數據倉庫和數據湖的價值進行疊加,克服數據重力,讓數據在服務之間流動起來,減少重復建設,讓湖中的數據可以”流到“數據倉中,并能直接進行數據調用;而數據倉中的數據也可以保存于數據湖中,供未來數據挖掘使用。借助湖倉一體化,可快速處理數倉內的熱數據與數據湖中的歷史數據,并生成豐富的數據集,但無需在執行中做任何數據移動操作。
那數據湖究竟應該是什么樣子,需要在接下來的發展中獲取到答案,但是以目前來看,典型的組織都需要數據倉庫和數據湖,因為它們可滿足不同的需求和使用訴求。所以數據湖和數據倉庫的存在并不沖突,也并不是取代的關系,而是相互的融合關系。
如何將ERP數據集成到數據倉庫、數據湖?
現在大家了解了數據湖與數據倉庫的區別,以及湖倉一體新的數據管理模式。那么如何將ERP系統數據實時并大批量地導出至數據湖、數據倉庫進行商業分析?SNP Glue軟件應運而生,它旨在通過實施先進的SAP數據集成,將客戶的數據平臺提升到一個新的水平。
Glue允許您將SAP數據如ERP(ECC 、S4/HANA)、BW、CRM/SCM、客戶ABAP應用程序、HANA數據等引入數據倉庫,幫助您實現實時復制提取SAP數據并放入您所期待的目標環境,無論是數據庫、數據湖、BI數據分析工具、或云解決方案。支持用例,將數據流實時傳輸到數據湖中以提供數據產品或支持基于事件的客戶應用程序。SNP Glue避免了供應商鎖定的風險。通過SAP、Google、Amazon、Microsoft、Snowflake和Cloudera認證。
如想查看Glue如何將數據集成到數據平臺的Demo演示可以聯系SNP公司
審核編輯 黃宇
-
SAP
+關注
關注
1文章
385瀏覽量
21703 -
數據管理
+關注
關注
1文章
300瀏覽量
19646 -
數據倉庫
+關注
關注
0文章
61瀏覽量
10464
發布評論請先 登錄
相關推薦
戴爾數據湖倉助力企業數字化轉型
內部創新驅動:SNP啟動AI人工智能和云創新實驗室
強強聯合,生態合力 SNP TDO軟件成功入駐SAP應用商店
SNP Meta研究:SAP S/4HANA遷移的深度分析與洞察
SNP在迪拜設立新辦事處:專注中東市場的SAP轉型支持
解鎖SAP數據的潛力:SNP Glue與SAP Datasphere的協同作用
SNP亮相 2024 SAP高科技行業峰會:科技新引擎 智領新增長

SNP亮相2024 SAP裝備制造化工零售建筑與地產行業峰會

數據倉庫與數據庫的主要區別
工業數據中臺的功能和應用場景
什么是數據湖?數據湖和數據倉庫有什么區別?
數據中臺、數據倉庫、數據治理與主數據的定位與差異
企業如何使用SNP Glue將SAP與Snowflake集成?

SNP干貨分享:SAP數據脫敏的具體實施步驟





 工商網監
工商網監
評論