") CVPR 2023 中的領(lǐng)域適應(yīng): 一種免反向傳播的TTA語義分割方法
CVPR 2023 中的領(lǐng)域適應(yīng): 一種免反向傳播的TTA語義分割方法
前言
我們已經(jīng)介紹過兩篇關(guān)于 TTA 的工作,可以在 GiantPandaCV 公眾號中找到,分別是:
Continual Test-Time 的領(lǐng)域適應(yīng)
CVPR 2023 中的領(lǐng)域適應(yīng): 通過自蒸餾正則化實現(xiàn)內(nèi)存高效的 CoTTA
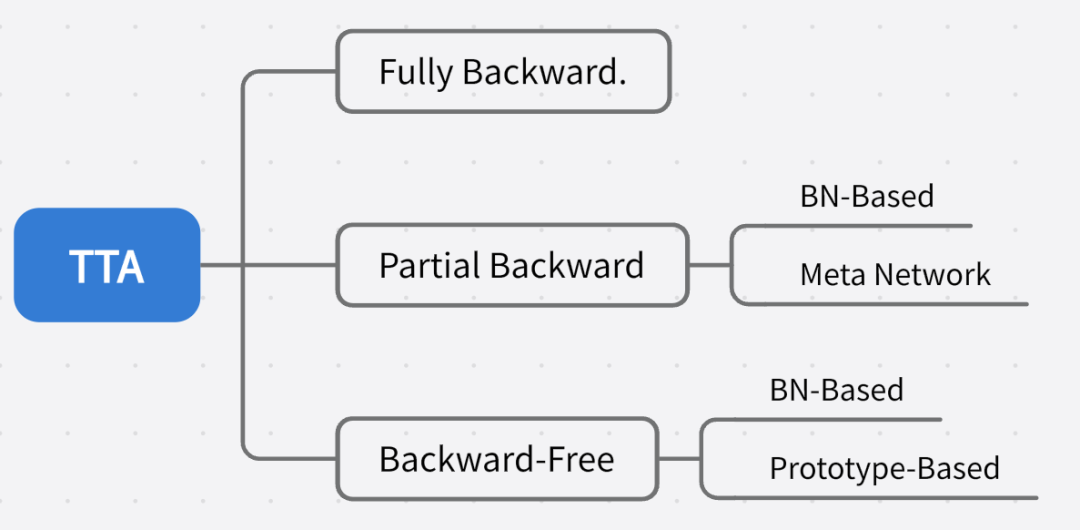
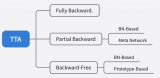
推薦對領(lǐng)域適應(yīng)不了解的同學(xué)先閱讀前置文章。目前的 TTA 方法針對反向傳播的方式可以大致劃分為:
請?zhí)砑訄D片描述
之前介紹過的 CoTTA 可以屬于 Fully Backward,EcoTTA 劃分為 Partial Backward 中的 Meta Network 類別,這次要介紹的方法屬于 Backward-Free 中的 BN-Based 和 Prototype-Based 的混合。
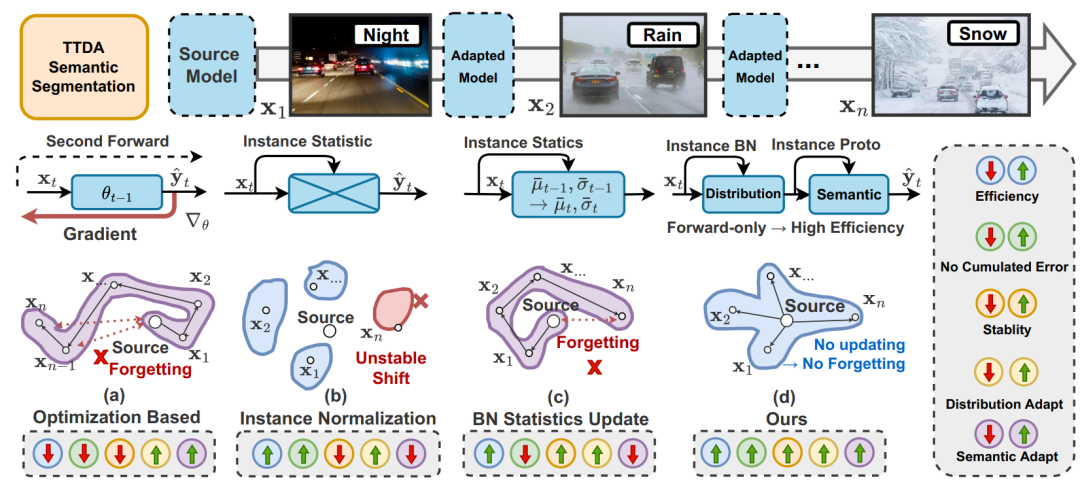
下圖是一些 TTA 語義分割方式的比較,在(a)中是最樸素的重新做反向傳播優(yōu)化目標域模型梯度的方法,效率低,存在誤差積累,且會導(dǎo)致長期遺忘。
(b)是直接用每個實例的統(tǒng)計數(shù)據(jù)替代源統(tǒng)計數(shù)據(jù)(通過修改 Instance Normalization),但由于丟棄了基本的源知識,因此對目標變化非常敏感,導(dǎo)致不穩(wěn)定。
(c)研究了通過實例統(tǒng)計數(shù)據(jù)以固定動量或動態(tài)波動動量更新歷史統(tǒng)計數(shù)據(jù)的影響(相當(dāng)于(b)的集群),然而,這種方法也容易受到誤差積累的影響。
(d)表示這篇工作提出的方法,主要思想是以非參數(shù)化的方式利用每個實例來動態(tài)地進行自適應(yīng),這種方法既高效又能在很大程度上避免誤差積累問題。
具體來說,計算 BN 層中源統(tǒng)計數(shù)據(jù)和當(dāng)前統(tǒng)計數(shù)據(jù)的加權(quán)和,以適應(yīng)目標分布,從而使模型獲得更健壯的表示,還通過將歷史原型與實例級原型混合構(gòu)建動態(tài)非參數(shù)分類頭。
下面看下具體實現(xiàn)。
DIGA 概述
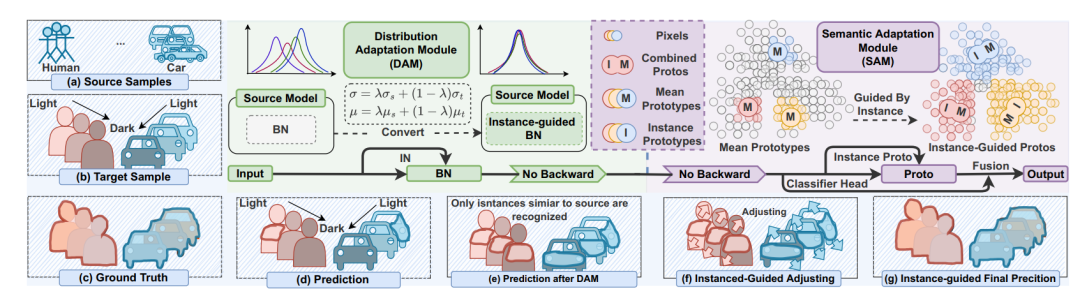
TTA 在語義分割中的應(yīng)用,效率和性能都至關(guān)重要。現(xiàn)有方法要么效率低(例如,需要反向傳播的優(yōu)化),要么忽略語義適應(yīng)(例如,分布對齊)。此外,還會受到不穩(wěn)定優(yōu)化和異常分布引起的誤差積累的困擾。為了解決這些問題,這篇工作提出了不需反向傳播優(yōu)化的 TTA 語義分割方法,被叫做稱為動態(tài)實例引導(dǎo)自適應(yīng)(DynamicallyInstance-Guided Adaptation, DIGA)。DIGA 的原則是以非參數(shù)化的方式利用每個實例動態(tài)引導(dǎo)其自身的適應(yīng),從而避免了誤差累積問題和昂貴的優(yōu)化成本(內(nèi)存)。具體而言,DIGA 由分布適應(yīng)模塊(DAM)和語義適應(yīng)模塊(SAM)組成。DAM 將實例和源 BN 層統(tǒng)計信息混合在一起,以鼓勵模型捕獲不變的表示。SAM 將歷史原型與實例級原型結(jié)合起來調(diào)整語義預(yù)測,這可以與參數(shù)化分類頭相關(guān)聯(lián)。具體細節(jié)在后文介紹。
DAM 和 SAM 兩者都由實例感知信息引導(dǎo)。如下圖所示,給定一個測試樣本,首先將其輸入到源預(yù)訓(xùn)練模型中,并通過 DAM 在每個 BN 層進行分布對齊。分布對齊是通過加權(quán)求和源統(tǒng)計和實例統(tǒng)計來實現(xiàn)的。之后,通過 SAM 在最后的特征層級上進行語義適應(yīng),通過加權(quán)混合歷史原型和實例感知原型來構(gòu)建一個動態(tài)非參數(shù)化分類頭。這使我們能夠調(diào)整語義預(yù)測。最后,我們利用原始參數(shù)化分類頭和動態(tài)非參數(shù)化分類頭之間的相互優(yōu)勢獲得最終的預(yù)測結(jié)果。
請?zhí)砑訄D片描述
Distribution Adaptation Module (DAM)
調(diào)整分布可以提高跨域測試性能,由于訓(xùn)練數(shù)據(jù)有限和反向傳播成本高,最常見的方法是對抗訓(xùn)練和分布差距最小化,但是不適合 TTA 任務(wù)。通常 BN 層中各域之間的靜態(tài)不匹配是跨域測試性能下降的主要原因。BN 層是使用可訓(xùn)練參數(shù) gamma 和 beta 進行縮放和移動。對于每個 BN 層,給定輸入特征表示 F,相應(yīng)的輸出由以下公式給出:
E[F] 和 Var[F] 分別代表輸入特征 F 的期望值和方差。在實踐中,由于批次訓(xùn)練過程,它們的值通過 running mean 在訓(xùn)練期間計算:
所以,有一種方法源域的 running mean 的最后一個值被凍結(jié),用作測試階段測試數(shù)據(jù)的預(yù)期值和方差的估計。但是,源統(tǒng)計信息仍會嚴重影響性能。還有一種方法提出了一種動態(tài)學(xué)習(xí)模塊,將 BN 層的統(tǒng)計信息 γ、β 調(diào)整為目標域(更新 γ、β)。盡管該方法具有高效性,但其性能仍然不理想。可能的原因之一是模型更新速率通常較小,并且在每個實例評估過程中沒有充分考慮實例級別的信息。
所以 DAM 考慮到了利用實例級別的信息。DAM 不是直接更新 γ、β,而是通過動態(tài)地合并(加權(quán)求和)源統(tǒng)計信息和實例級別的 BN 統(tǒng)計信息來計算 E[F] 和 Var[F] 的估計值。
其中, 和 是在測試期間使用第 t 個實例計算的均值和方差。
Semantic Adaptation Module (SAM)
DAM 是與類別無關(guān)的,如上所述,因為它僅在全局上對特征圖的分布進行調(diào)整。然而,對于分割自適應(yīng)任務(wù)來說,類別特定性也很重要,因為即使在同一張圖像中,每個類別的分布也會有很大變化。為了解決這一點,之前的工作提出了兩種直觀的方法,熵最大化和偽標簽。然而,它們都需要基于梯度的反向傳播,因此限制了測試效率,和我們的思路背道而馳。受少樣本學(xué)習(xí)和域自適應(yīng)中基于原型的方法(Prototype-Based)的啟發(fā),引入了用于類別特定自適應(yīng)的 SAM。具體做法,總結(jié)有如下幾步,我們用通俗的話解釋下,至于論文中的公式,也會貼上。
計算 Instance-aware prototypes:
根據(jù)輸入圖像中每個類別的像素,計算其在特征空間中的中心點(prototypes),稱為實例感知原型。這些原型表示了每個類別的特征分布。
通過對不同實例的原型進行平均計算,得到歷史原型。歷史原型是在大量目標實例上計算得到的,具有較高的穩(wěn)定性。
Ensemble historical prototypes:
將歷史原型與實例感知原型進行集成,以進一步提高分類的準確性和穩(wěn)定性。
Cal prototype-based classification result:
使用計算得到的實例感知原型和歷史原型,通過比較輸入像素與原型之間的相似度,進行分類預(yù)測。這種基于原型的分類方法可以更好地適應(yīng)不同類別的變化。
Classifier Association
SAM 本質(zhì)上是 prototype-based classification。在最后的部分,可以得到兩種類型的預(yù)測:一種來自原始的參數(shù)化分類器(p?),另一種來自引入的非參數(shù)原型分類器(p ?)。為了利用它們之間的互補性,DIGA 還是通過加權(quán)求和來獲得最終的預(yù)測結(jié)果,表示為:
實驗
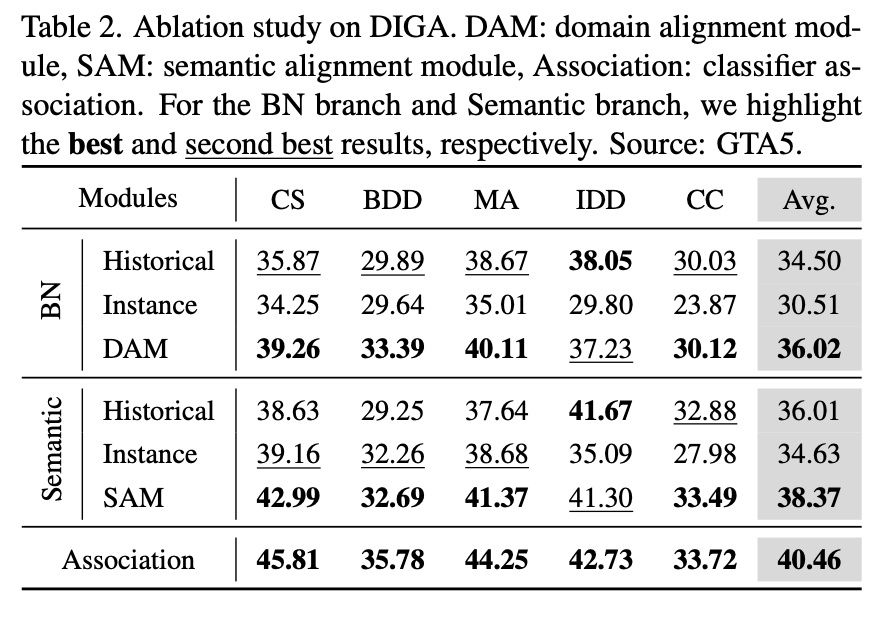
在實驗的部分,我們更關(guān)心的是這些組合的有效性。下表是對 DAM 和 SAM 的消融實驗,最后一行表示分類器關(guān)聯(lián)。對于 BN 分支和語義分支,都分別比較出最佳和次佳。
和直接使用源域模型、其他的 SOTA TTA 方法的可視化比較如下,可以發(fā)現(xiàn)在 cityscapes 上的優(yōu)化效果是最明顯的。

在這里插入圖片描述
總結(jié)
這篇工作提出了一種名為動態(tài)實例引導(dǎo)適應(yīng)(DIGA)的方法來解決 TTA 語義分割問題,該方法兼?zhèn)涓咝院陀行浴IGA 包括兩個適應(yīng)性模塊,即分布適應(yīng)模塊(DAM)和語義適應(yīng)模塊(SAM),兩者均以非參數(shù)方式受實例感知信息引導(dǎo)。此外,這是第三篇關(guān)于 TTA 的論文解讀了,后面出現(xiàn)有趣的工作還會繼續(xù)這個系列的。
-
模塊
+關(guān)注
關(guān)注
7文章
2714瀏覽量
47500 -
DAM
+關(guān)注
關(guān)注
0文章
8瀏覽量
9520
原文標題:CVPR 2023 中的領(lǐng)域適應(yīng): 一種免反向傳播的 TTA 語義分割方法
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一種使用鄰接信息的自適應(yīng)膚色檢測方法
一種帶驗證的自適應(yīng)鏡頭分割算法
一種自動生成反向傳播方程的方法

MIT提出語義分割技術(shù),電影特效自動化生成
語義分割方法發(fā)展過程
分析總結(jié)基于深度神經(jīng)網(wǎng)絡(luò)的圖像語義分割方法

語義分割模型 SegNeXt方法概述
一種免反向傳播的 TTA 語義分割方法
CVPR 2023 | 華科&MSRA新作:基于CLIP的輕量級開放詞匯語義分割架構(gòu)

CVPR 2023 | 完全無監(jiān)督的視頻物體分割 RCF

CVPR 2023 中的領(lǐng)域適應(yīng):用于切片方向連續(xù)的無監(jiān)督跨模態(tài)醫(yī)學(xué)圖像分割

基于一種用于醫(yī)學(xué)圖像分割的方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論