 大模型背景下,AI芯片廠商面臨怎樣的機遇與挑戰?
大模型背景下,AI芯片廠商面臨怎樣的機遇與挑戰?
從2022.11.30的ChatGPT,到2023.6.13的360智腦大模型2.0,全球AI界已為大模型持續瘋狂了七個多月。ChatGPT們正如雨后春筍般涌現,向AI市場投放一個個“炸彈”:辦公、醫療、教育、制造,亟需AI的賦能。
而AI應用千千萬,把大模型打造好才是硬道理。
對于大模型“世界”來說,算法是“生產關系”,是處理數據信息的規則與方式;算力是“生產力”,能夠提高數據處理、算法訓練的速度與規模;數據是“生產資料”,高質量的數據是驅動算法持續迭代的養分。在這之中,算力是讓大模型轉動的前提。
我們都知道的是,大模型正對算力提出史無前例的要求,具體的表現是:據英偉達數據顯示,在沒有以Transformer模型為基礎架構的大模型之前,算力需求大致是每兩年提升8倍;而自利用Transformer模型后,算力需求大致是每兩年提升275倍。基于此,530B參數量的Megatron-Turing NLG模型,將要吞噬超10億FLOPS的算力。
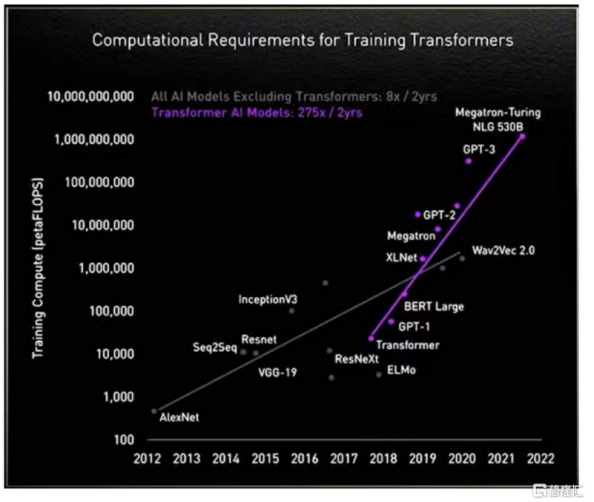
(AI不同模型算法算力迭代情況 圖源:格隆匯)
作為大模型的大腦——AI芯片,是支撐ChatGPT們高效生產及應用落地的基本前提。保證算力的高效、充足供應,是目前AI大算力芯片廠商亟需解決的問題。
GPT-4等大模型向芯片廠商獅子大開口的同時,也為芯片廠商尤其是初創芯片廠商,帶來一個利好消息:軟件生態重要性正在下降。
早先技術不夠成熟之時,研究者們只能從解決某個特定問題起步,參數量低于百萬的小模型由此誕生。例如谷歌旗下的AI公司DeepMind,讓AlphaGO對上百萬種人類專業選手的下棋步驟進行專項“學習”。
而小模型多了之后,硬件例如芯片的適配問題迫在眉睫。故,當英偉達推出統一生態CUDA之后,GPU+CUDA迅速博得計算機科學界認可,成為人工智能開發的標準配置。
現如今紛紛涌現的大模型具備多模態能力,能夠處理文本、圖片、編程等問題,也能夠覆蓋辦公、教育、醫療等多個垂直領域。這也就意味著,適應主流生態并非唯一的選擇:在大模型對芯片需求量暴漲之時,芯片廠商或許可以只適配1-2個大模型,便能完成以往多個小模型的訂單。
也就是說,ChatGPT的出現,為初創芯片廠商們提供了彎道超車的機會。這就意味著,AI芯片市場格局將發生巨變:不再是個別廠商的獨角戲,而是多個創新者的群戲。
本報告將梳理AI芯片行業發展概況、玩家情況,總結出大算力時代,玩家提高算力的路徑,并基于此,窺探AI大算力芯片的發展趨勢。
01.國產AI芯片,正走向AI3.0時代
現階段的AI芯片,根據技術架構種類來分,主要包括GPGPU、FPGA、以 VPU、TPU 為代表的 ASIC、存算一體芯片。
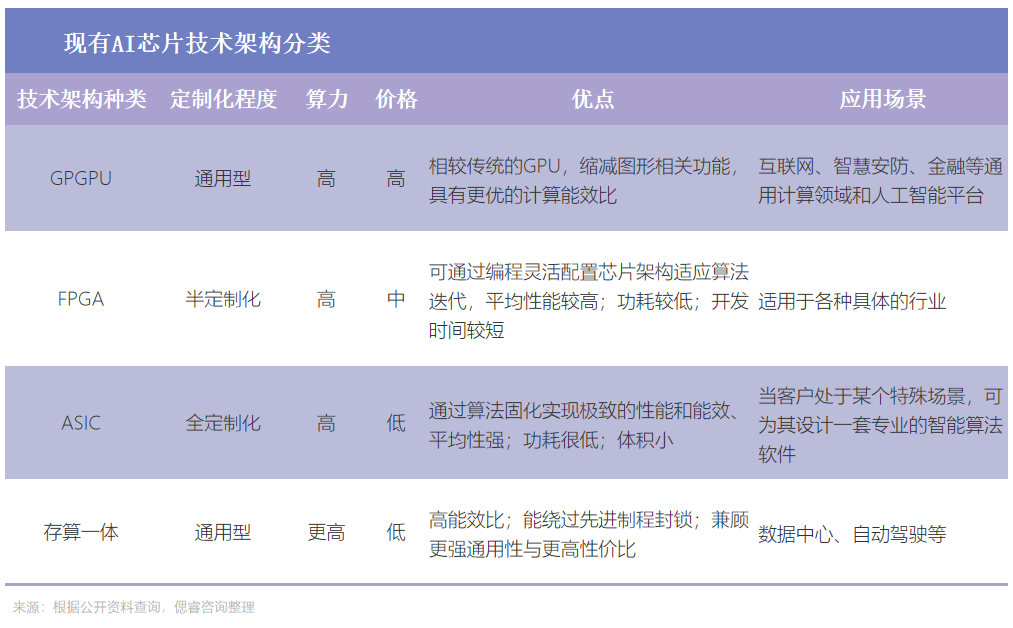
根據其在網絡中的位置,AI 芯片可以分為云端AI芯片 、邊緣和終端AI芯片;
云端主要部署高算力的AI訓練芯片和推理芯片,承擔訓練和推理任務,例如智能數據分析、模型訓練任務等;
邊緣和終端主要部署推理芯片,承擔推理任務,需要獨立完成數據收集、環境感知、人機交互及部分推理決策控制任務。
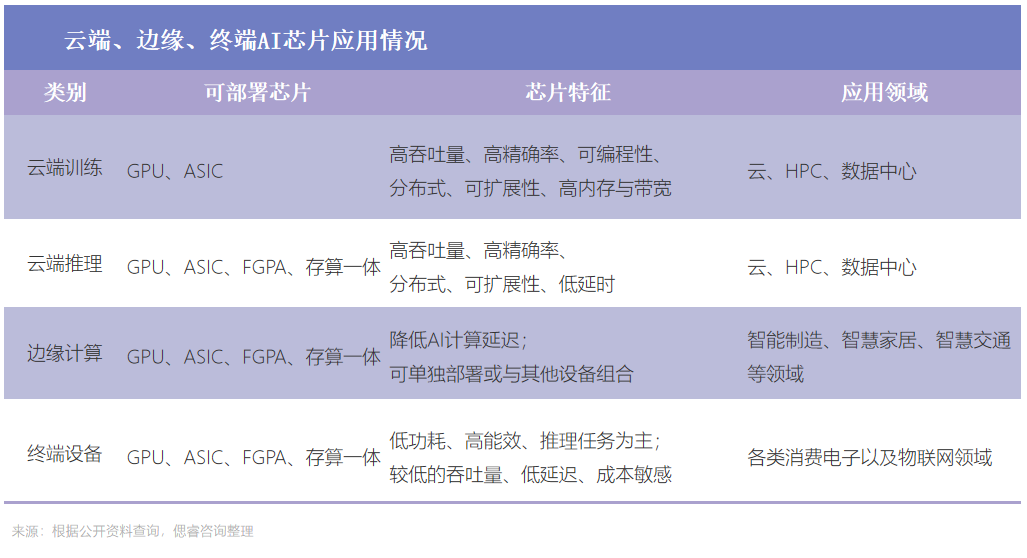
根據其在實踐中的目標,可分為訓練芯片和推理芯片:

縱觀AI芯片在國內的發展史,AI芯片國產化進程大致分為三個時代。
1.0時代,是屬于ASIC架構的時代
自2000年互聯網浪潮拉開AI芯片的序幕后,2010年前后,數據、算法、算力和應用場景四大因素的逐漸成熟,正式引發AI產業的爆發式增長。申威、沸騰、兆芯、龍芯、魂芯以及云端AI芯片相繼問世,標志著國產AI芯片正式啟航。
2016年5月,當谷歌揭曉AlphaGo背后的功臣是TPU時,ASIC隨即成為“當紅辣子雞”。于是在2018年,國內寒武紀、地平線等國內廠商陸續跟上腳步,針對云端AI應用推出ASIC架構芯片,開啟國產AI芯片1.0時代。
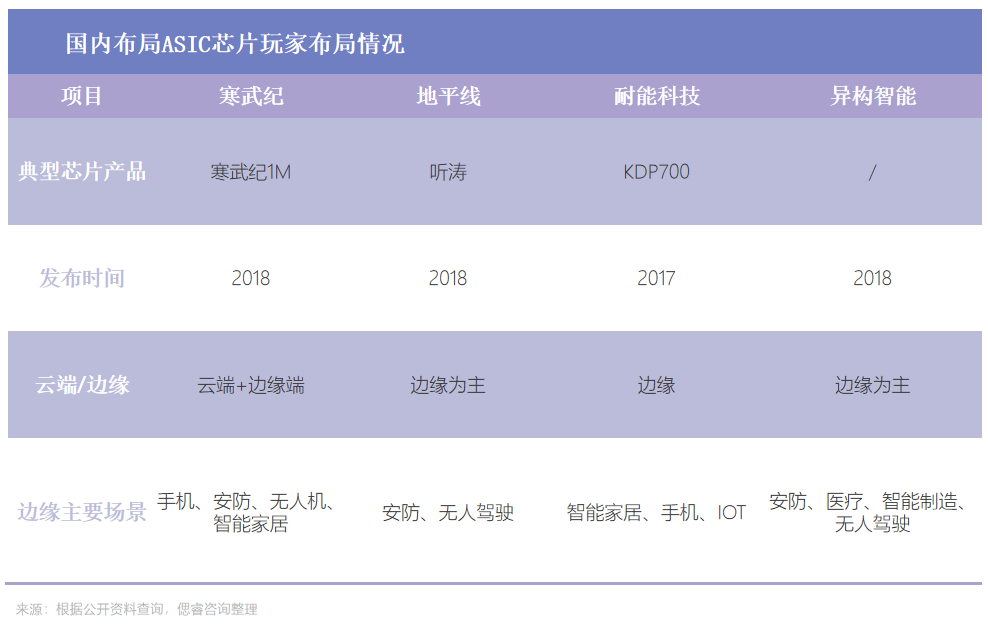
ASIC芯片,能夠在某一特定場景、算法較固定的情況下,實現更優性能和更低功耗,基于此,滿足了企業對極致算力和能效的追求。
所以當時的廠商們,多以捆綁合作為主:大多芯片廠商尋找大客戶們實現“專用場景”落地,而有著綜合生態的大廠選擇單打獨斗。
地平線、耐能科技等AI芯片廠商,分別專注AI芯片的細分領域,采用“大客戶捆綁”模式進入大客戶供應鏈。

在中廠們綁定大客戶協同發展之際,自有生態的大廠阿里成立獨資芯片公司平頭哥,著眼AI和量子計算。
2019年,平頭哥發布的第一款AI芯片含光800,便是基于ASIC架構打造,用于云端推理。據阿里介紹,1顆含光800的算力相當于10顆GPU,含光800推理性能達到78563 IPS,能效比500 IPS/W。相比傳統GPU算力,性價比提升100%。
在1.0時代,剛出世的國內芯片廠商們選擇綁定大客戶,有綜合生態的大廠選擇向內自研,共同踏上探索AI芯片算力的征途。
2.0時代,更具通用性的GPGPU“引領風騷”
盡管ASIC有著極致的算力和能效,但也存在著應用場景局限、依賴自建生態、客戶遷移難度大、學習曲線較長等問題。
于是,通用性更強的GPGPU(通用圖形處理器)在不斷迭代和發展中成為AI計算領域的最新發展方向,當上AI芯片2.0時代的指路人。
自2020年起,以英偉達為代表的GPGPU架構開始有著不錯的性能表現。通過對比英偉達近三代旗艦產品發現,從FP16 tensor 算力來看,性能實現逐代翻倍的同時,算力成本在下降。
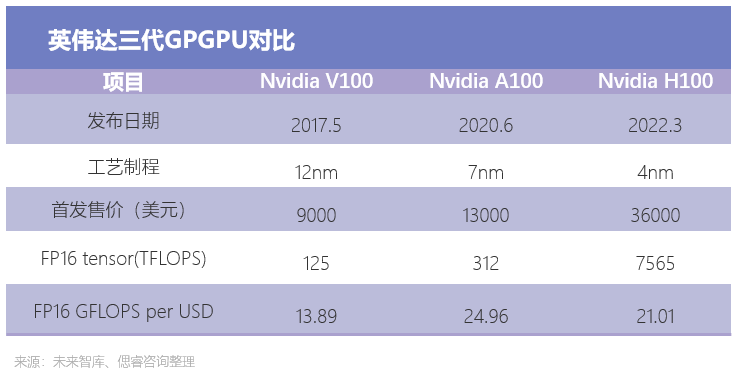
于是,國內多個廠商紛紛布局GPGPU芯片,主打CUDA兼容,試探著AI算力芯片的極限。2020年起,珠海芯動力、壁仞科技、沐曦、登臨科技、天數智芯、瀚博半導體等新勢力集結發力,大家一致的動作是:自研架構,追隨主流生態,切入邊緣側場景。
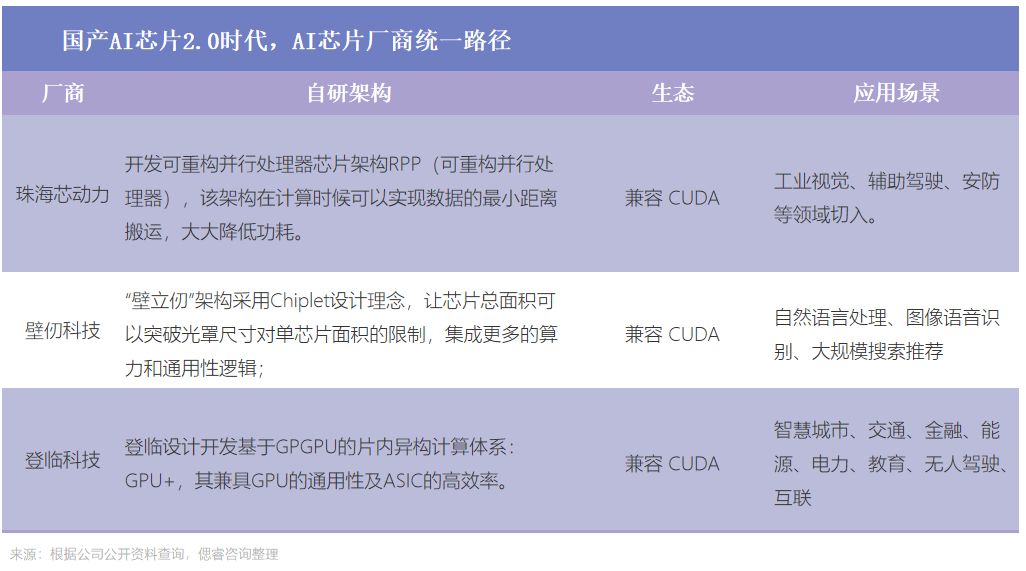
在前兩個時代中,國產AI芯片廠商都在竭力順應時代潮流,前赴后繼地跟隨國際大廠的步伐,通過研發最新芯片解決AI算力芯片的挑戰。
我們能看到的變化是,在2.0時代中,國產AI芯片廠商自主意識覺醒,嘗試著自研架構以求突破。
3.0時代,存算一體芯片或成GPT-4等大模型的最優選
ASIC芯片的弱通用性難以應對下游層出不窮的應用,GPGPU受制于高功耗與低算力利用率,而大模型又對算力提出前所未有的高要求:目前,大模型所需的大算力起碼是1000TOPS及以上。
以 2020 年發布的 GPT-3 預訓練語言模型為例,其采用的是2020年最先進的英偉達A100 GPU, 算力是624TOPS。2023年,隨著模型預訓練階段模型迭代,又新增訪問階段井噴的需求,未來模型對于芯片算力的需求起碼要破千。
再例如自動駕駛領域,根據財通證券研究所表明,自動駕駛所需單個芯片的算力未來起碼要1000+TOPS:2021年4月, 英偉達就已經發布了算力為1000TOPS的DRIVE Atlan芯片;到了今年,英偉達直接推出芯片Thor,達到2000TOPS。
由此,業界亟需新架構、新工藝、新材料、新封裝,突破算力天花板。除此之外,日漸緊張的地緣關系,無疑又給高度依賴先進制程工藝的AI大算力芯片廠商們提出新的挑戰。
在這些大背景下,從2017年到2021年間集中成立的一批初創公司,選擇跳脫傳統馮·諾依曼架構,布局存算一體等新興技術,中國AI芯片3.0時代,正式拉開帷幕。
目前存算一體,正在上升期:
學界,ISSCC上存算/近存算相關的文章數量迅速增加:從20年的6篇上漲到23年的19篇;其中數字存內計算,從21年被首次提出后,22年迅速增加到4篇。
產界,巨頭紛紛布局存算一體,國內陸陸續續也有近十幾家初創公司押注該架構:
在特斯拉2023 Investor Day預告片末尾,特斯拉的dojo超算中心和存算一體芯片相繼亮相;在更早之前,三星、阿里達摩院包括AMD也早早布局并推出相關產品:阿里達摩院表示,相比傳統CPU計算系統,存算一體芯片的性能提升10倍以上,能效提升超過300倍;三星表示,與僅配備HBM的GPU加速器相比,配備HBM-PIM的GPU加速器一年的能耗降低了約2100GWh。
目前,國內的億鑄科技、知存科技、蘋芯科技、九天睿芯等十余家初創公司采用存算一體架構投注于AI算力,其中億鑄科技、千芯科技偏向數據中心等大算力場景。
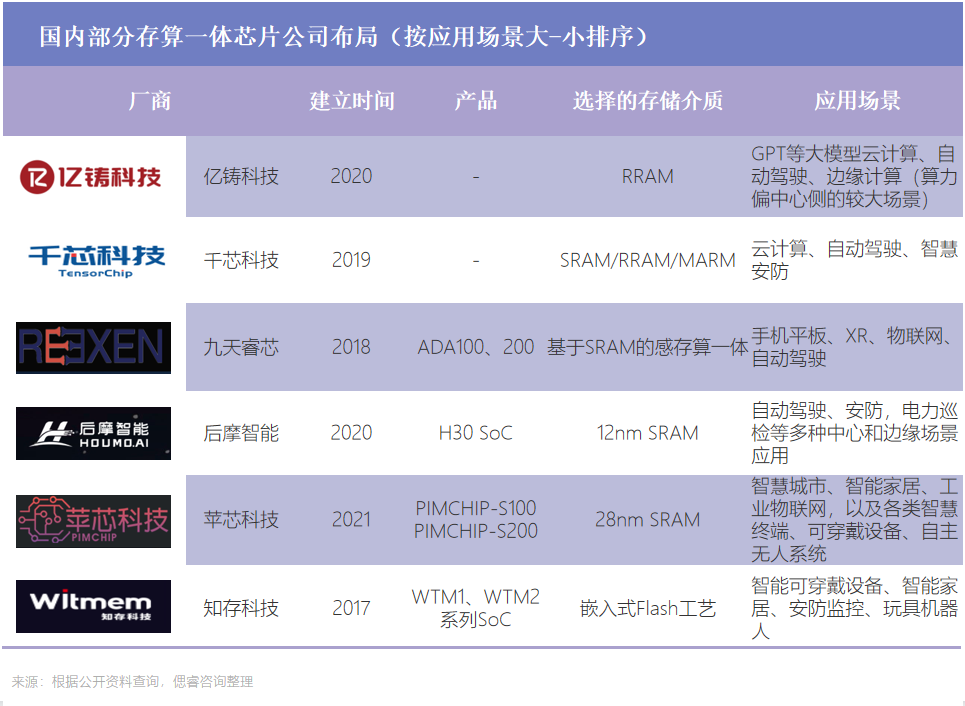
現階段,業內人士表示,存算一體將有望成為繼CPU、GPU架構之后的第三種算力架構。
該提法的底氣在于,存算一體理論上擁有高能效比優勢,又能繞過先進制程封鎖,兼顧更強通用性與更高性價比,算力發展空間巨大。
在此基礎上,新型存儲器能夠助力存算一體更好地實現以上優勢。目前可用于存算一體的成熟存儲器有NOR FLASH、SRAM、DRAM、RRAM、MRAM等。相比之下,RRAM具備低功耗、高計算精度、高能效比和制造兼容CMOS工藝等優勢:
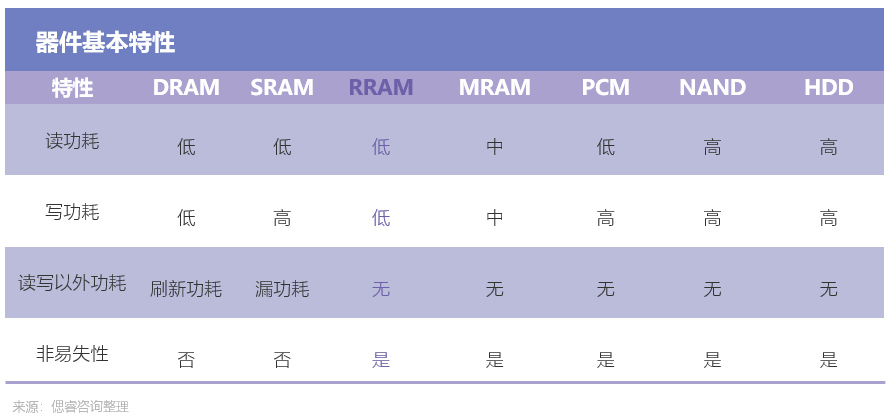
目前,新型存儲器RRAM技術已然落地:2022上半年,國內創業公司昕原半導體宣布,大陸首條RRAM 12寸中試生產線正式完成裝機驗收,并在工控領域達成量產商用。據昕原半導體CTO仇圣棻博士介紹,昕原RRAM產品的良率已經超過93%。
隨著新型存儲器件走向量產,存算一體AI芯片已經挺進AI大算力芯片落地競賽。
而無論是傳統計算芯片,還是存算一體芯片,在實際加速AI計算時往往還需處理大量的邏輯計算、視頻編解碼等非AI加速計算領域的計算任務。隨著多模態成為大模型時代的大勢所趨,AI芯片未來需處理文本、語音、圖像、視頻等多類數據。
對此,初創公司億鑄科技首個提出存算一體超異構AI大算力技術路徑。億鑄的暢想是,若能把新型憶阻器技術(RRAM)、存算一體架構、芯粒技術(Chiplet)、3D封裝等技術結合,將會實現更大的有效算力、放置更多的參數、實現更高的能效比、更好的軟件兼容性、從而抬高AI大算力芯片的發展天花板。
站在3.0時代門口,國產AI大算力芯片廠商自主意識爆發,以期為中國AI大算力芯片提供彎道超車的可能。
AI芯片市場的發展動力,大抵來源于以下幾個因素。
中央與地方政府正為提供充足算力而奔波
2023年2月,中央政府發布多個相關報告與布局規劃,強調東數西算中算力的調動,目前已落下一子:東數西算一體化服務平臺。

地方政府層面,例如成都在2023年1月,發布“算力券”,即將政府算力資源與算力中介服務機構、科技型中小微企業和創客、科研機構、高校等共享,有效提高算力利用率;北京在2023年3月,發布加快落實算力的相關意見,加快計算中心、算力中心、工業互聯網、物聯網等基礎設施建設。

基于國家與地方政府相關政策指引,AI廠商們紛紛建立起超算/智算中心,較于以往不同的是,今年算力的首個市場化運作模式誕生,智算中心算力的規模也實現質的飛躍:據國家信息中心與相關部門聯合發布的《智能計算中心創新發展指南》顯示,目前全國有超過30個城市正在建設或提出建設智算中心。

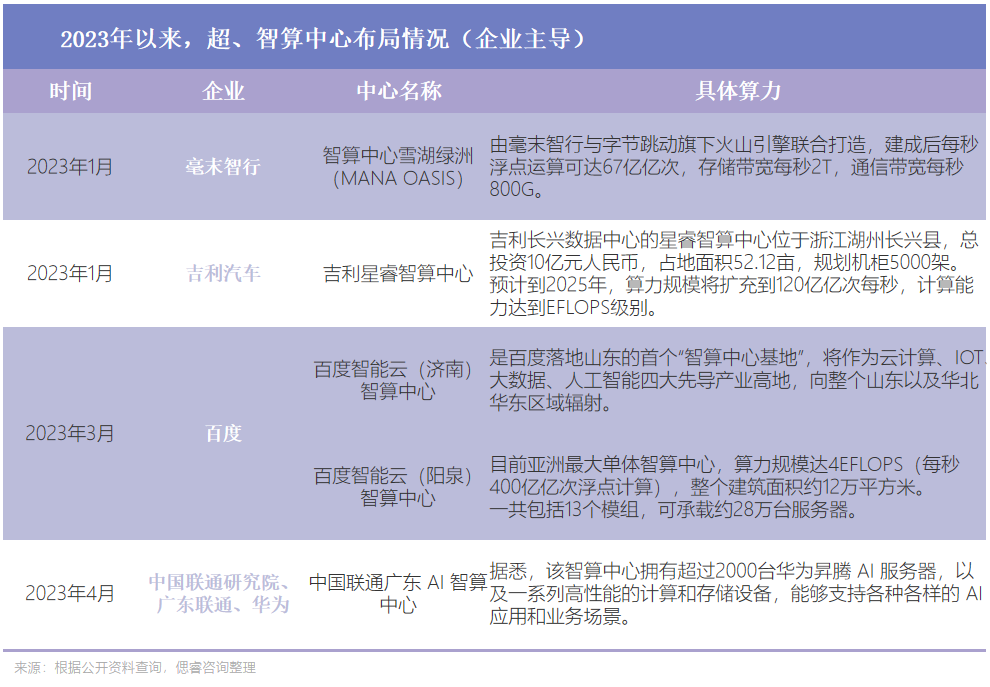
AI芯片產業布局規劃持續落地
可以看到,關于AI芯片政策已從“十三五”的規劃階段,來到“十四五”的落地階段:提高AI芯片研發技術,推廣AI應用。

同時,各地明確提出,要加強AI芯片產業布局。在這之中,浙江、廣東、江蘇等省份均提出了至2025年,人工智能芯片領域的具體發展方向。

存算一體正成為地方算力產業新機遇
存算一體,正成為深圳算力產業鏈創新發展的新機遇,并在積極落地之中。
2023年4月2日,在第二屆中國產業鏈創新發展峰會新一代信息技術產業發展論壇上,北京大學深研院信息工程學院副院長楊玉超表示,深圳將立足于相對完善的產業鏈集群,從先進工藝與封裝、創新電路與架構、EDA工具鏈、軟件與算法生態這四個方面解決存算一體在產業化應用上的挑戰。
今年4月,中國大模型正式爆發,未來,對于AI大算力芯片的需求只增不減。
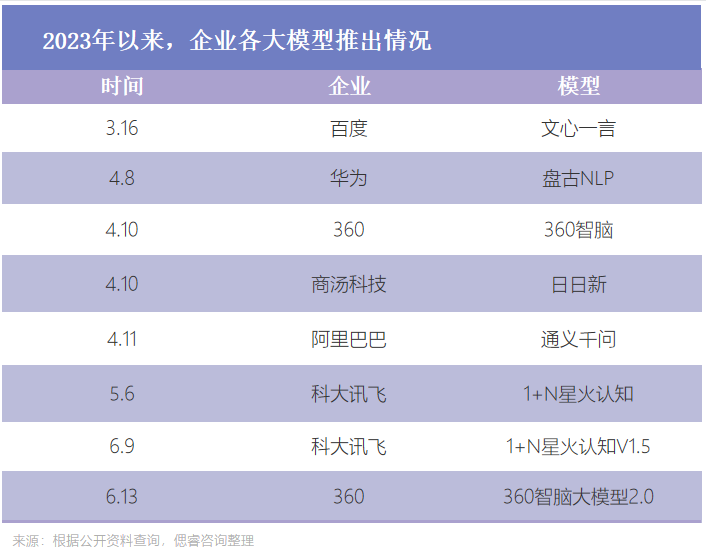
現有的大模型,正向著英偉達A100大算力芯片獅子大開口:

故例如商湯等AI廠商,正把眼光放置在國產AI大算力芯片上:2023年4月10日商湯披露,目前商湯所用的國產化AI芯片占比達到總體的10%。這無疑,將加速國內AI芯片廠商的成長。
英偉達表示,未來將從GPU架構出發,走向“GPU+DPU的超異構”:推出NVLink-C2C 、支持UCLe+芯粒+3D封裝;推出Thor“超異構”芯片2000T;
AMD表示,未來硬件創新突破更難,將走向“系統級創新”,即從整體設計的上下游多個環節協同設計來完成性能的提升。
千億美元的AI芯片市場,2023火得滾燙
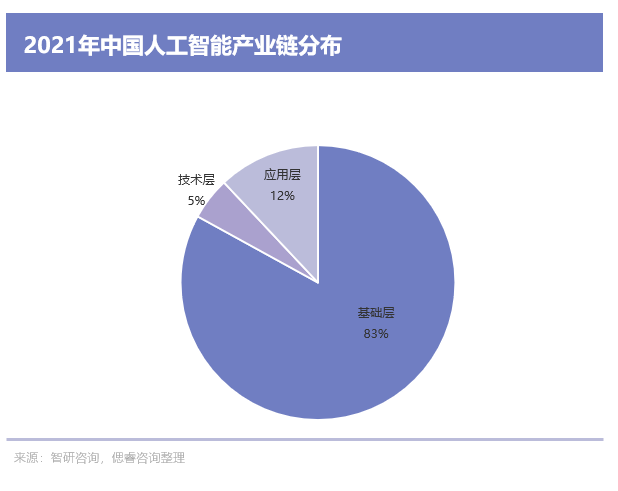
整體人工智能產業鏈,基本分為基礎層、技術層和應用層三個層面:
基礎層包括AI芯片、智能傳感器、云計算等;技術層包括機器學習、計算機視覺、自然語言處理等;應用層包括機器人、無人機、智慧醫療、智慧交通、智慧金融、智能家居、智慧教育、智慧安防等。

基礎層作為人工智能行業發展的基礎,為人工智能提供數據和算力支撐,其中,AI芯片是人工智能算力的基礎。
在AI產業尚未成熟之時,基礎層企業當前價值量最大,中國人工智能產業鏈中,基礎層企業比例達到83%,技術層企業比例為5%,應用層企業比例為12%。
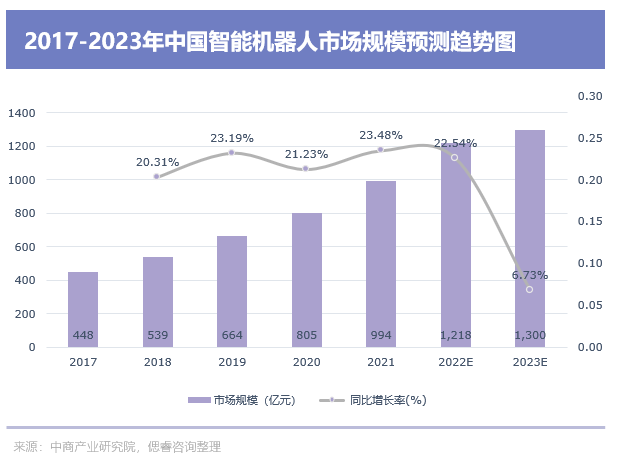
基礎層決定大樓是否穩固,而下游的應用層面決定大樓高度。在應用層,智能機器人、無人機等智慧終端潛力無限,智慧城市、智慧醫療等領域,更是有不少金子能挖。目前,我國智能機器人市場規模持續快速增長。
數據顯示,2017-2021年我國智能機器人市場規模從448億元增長至994億元,期內年均復合增長率達22.05%,預計2023年其市場規模將達1300億元。
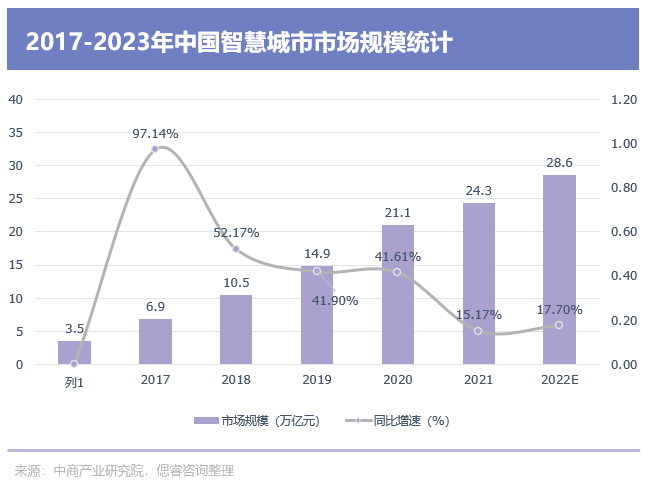
據中國信通院數據統計,中國智慧城市市場規模近幾年均保持30%以上增長,2021年市場規模達21.1萬億元,預計2023年其市場規模將達28.6萬億元。
千億美元市場,AI芯片魅力無限
在全球數字化、智能化的浪潮下,技術層的技術正不斷迭代:自動駕駛、影像辨識、運算等技術正在各領域深化應用;與此同時,應用層的物聯網設備正不斷豐富:工業機器人、AGV/AMR、智能型手機、智能音箱、智能攝影機等。
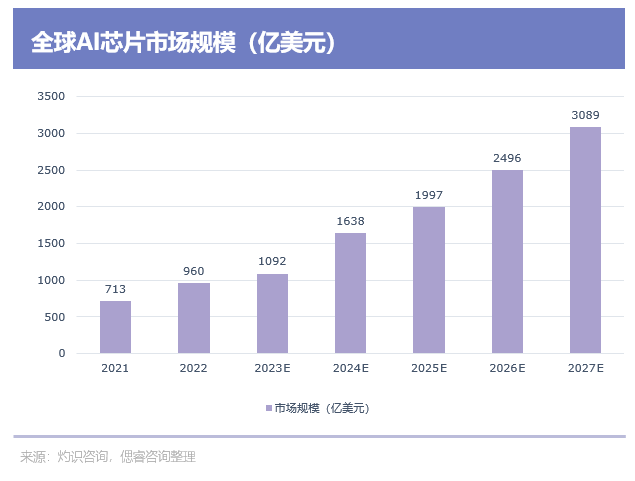
這無疑,會推動基礎層的AI芯片與技術市場迅速成長。根據灼識咨詢數據,2022年全球AI芯片市場規模達到960億美元,預計2027年達到3089億美元,2022年至2027年的復合年增長率為23%:
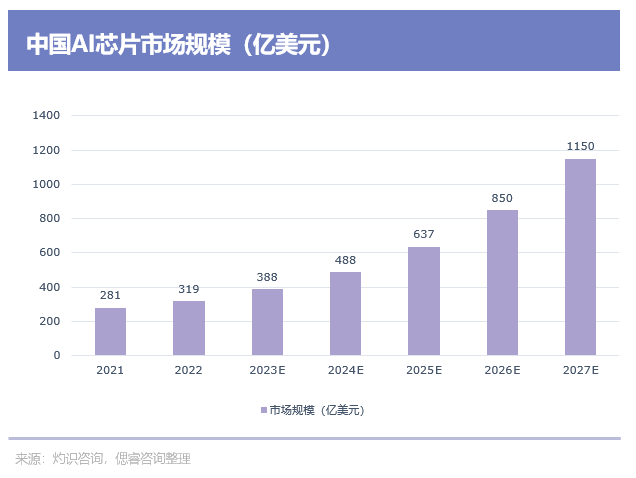
國內的AI芯片市場,更為火熱:根據灼識咨詢數據,2022年中國AI市場規模達到319億美元,預計于2027年將達到1150億美元,2022年至2027年的復合年增長率為29.2%。
2021,AI芯片賽道迎來風口
隨著下游安防、汽車等市場需求量增大,再加上2019年以來,美國持續制裁國內廠商的動作,2021年,國內AI芯片賽道迎來風口。在這一年里,資本們競相挑選屬于中國AI芯片市場的“潛力狗”,以期掌握未來芯片市場的話語權。盡管2022年投資熱度有所回落,但總體金額仍超百億元。
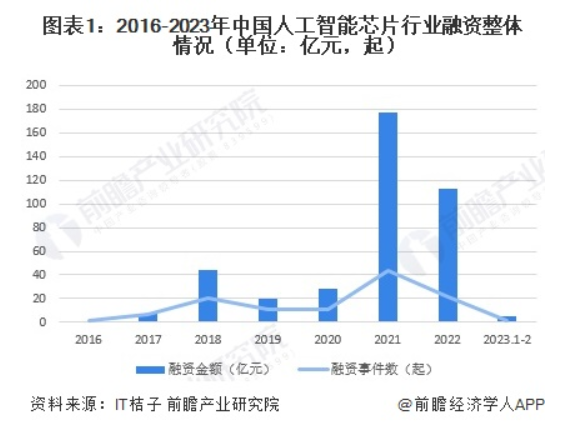
(2016-2023年中國人工智能芯片行業融資整體情況 圖源:前瞻經濟學人APP)
C輪后的融資較少,AI芯片市場仍處于萌芽期
通過分析投資輪次發現,AI芯片市場仍處于萌芽期:目前人工智能芯片行業的融資輪次仍處于早期階段,C輪后的融資數量較少。
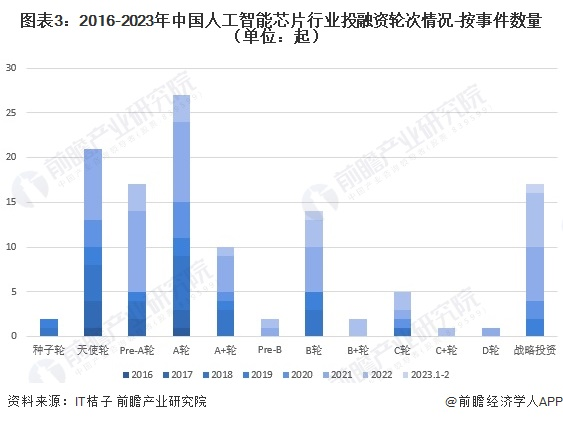
(2016-2023年中國人工智能芯片行業投融資輪次情況 圖源:前瞻經濟學人APP)
存算一體成為香餑餑
細分賽道來看,GPU是價值量最高的賽道,摩爾線程等GPU玩家融資超10億,榮獲“MVP”;
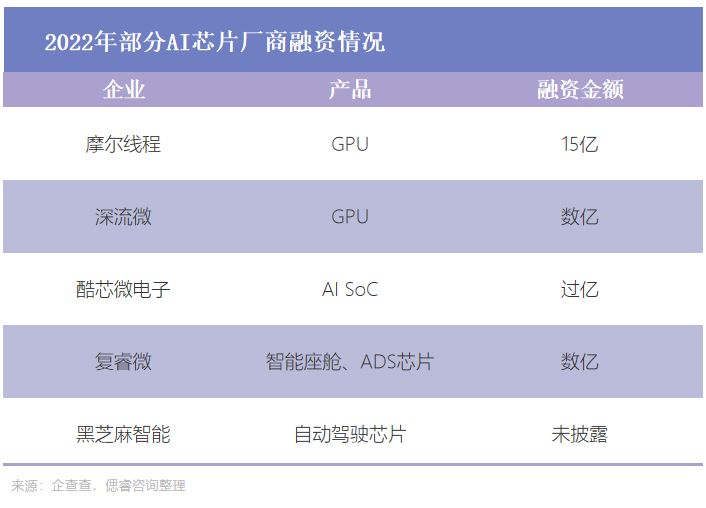
而存算一體賽道融資公司數量最多,億鑄科技、知存科技等七家存算一體玩家,備受資本青睞。值得注意的是,存算一體賽道下的四家初創公司億鑄科技、知存科技、蘋芯科技、后摩智能,已連續兩年獲得融資。
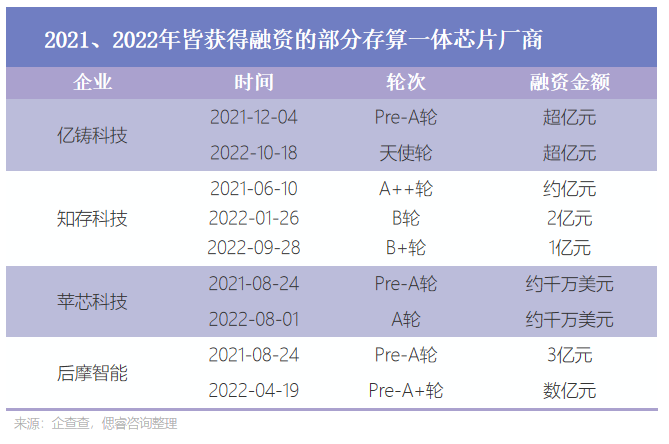
國內AI大算力賽道,玩家幾何?
目前,寒武紀、平頭哥等1.0時代玩家,現已成為優質AI算力芯片上市公司;2.0時代涌現的非上市AI算力芯片公司如壁仞科技、登臨科技、天數智芯等在產品端持續發力;3.0時代,千芯科技、億鑄科技等初創公司正在存算一體這一架構上尋求突破。
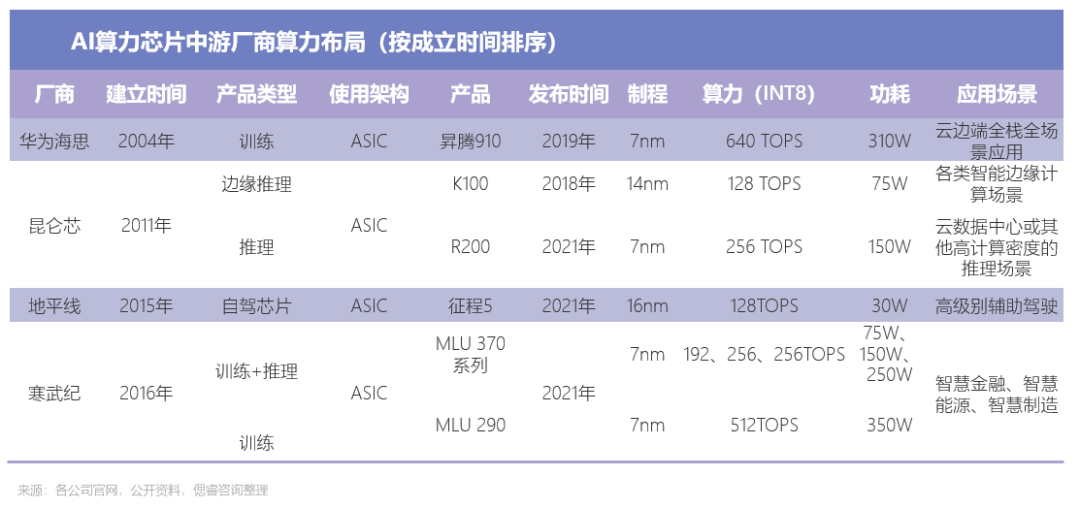
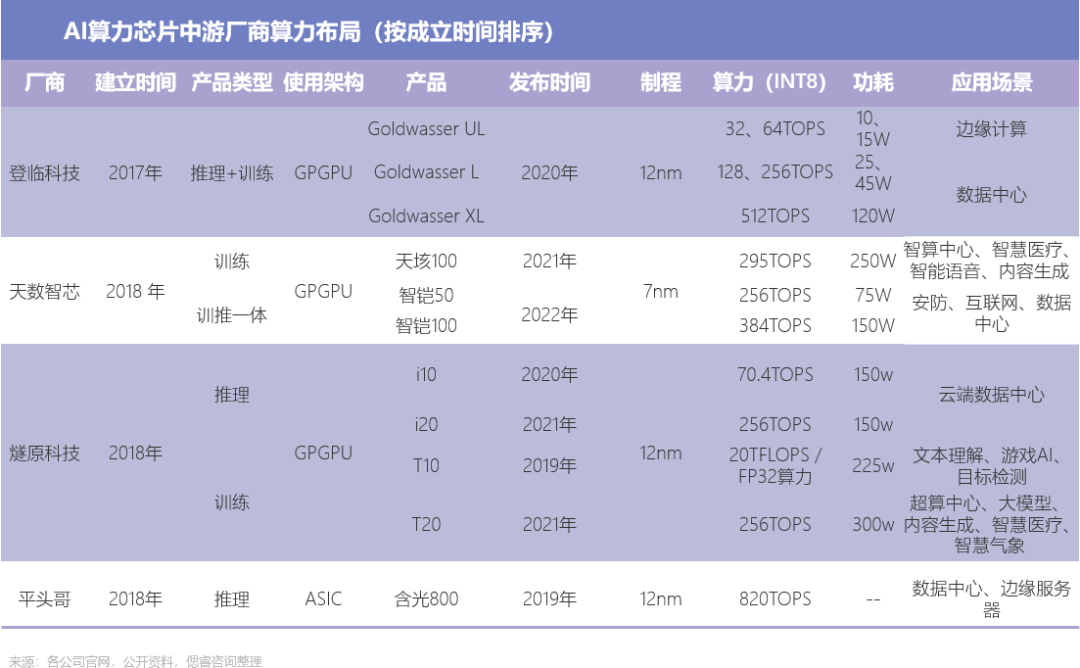
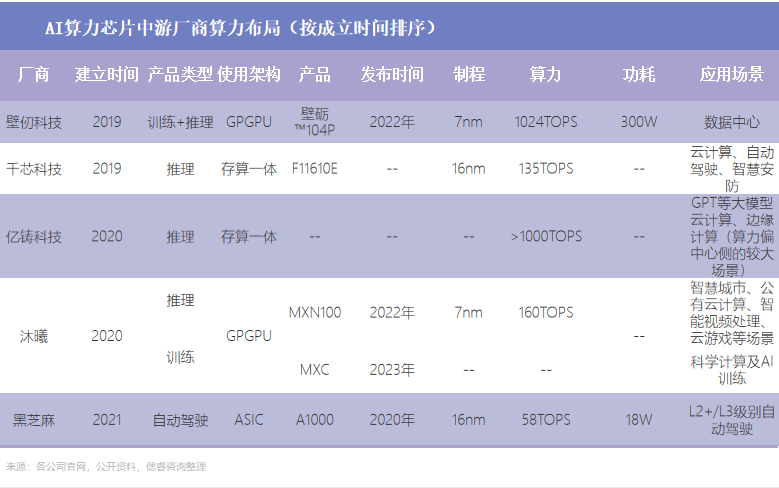
經偲睿洞察整理發現,目前,多數AI芯片公司布局邊緣側、中心側偏小算力場景,例如智慧安防、智慧城市、智慧醫療等應用場景;壁仞科技、平頭哥、億鑄科技能夠覆蓋邊緣側、中心側偏大算力場景;在新一批初創企業中,億鑄科技做出大膽的嘗試,試圖用存算一體架構去做大算力場景。
故,我們按照架構以及應用場景分類,呈現出以下AI算力芯片中游廠商全景圖:

ChatGPT火爆來襲,引發AI產業巨浪,國產AI芯片正迎來3.0時代。在大模型催生的3.0時代,亟需AI大算力芯片提供充足算力,讓日益沉重的大模型快速滾動起來。
02.大模型盛行,芯片廠商如何解決大算力難題?
算力,即國力
伴隨“元宇宙”時代開啟,GPT-4等大模型來勢洶洶,數據流量將迎來爆發增長。據IDC預測數據,預估未來五年,全球算力規模將以超過50%的速度增長,到2025年整體規模將達到3300EFlops。而2025年全球物聯網設備數將超過400億臺,產生數據量接近80ZB,且超過一半的數據需要依賴終端或者邊緣的計算能力進行處理。
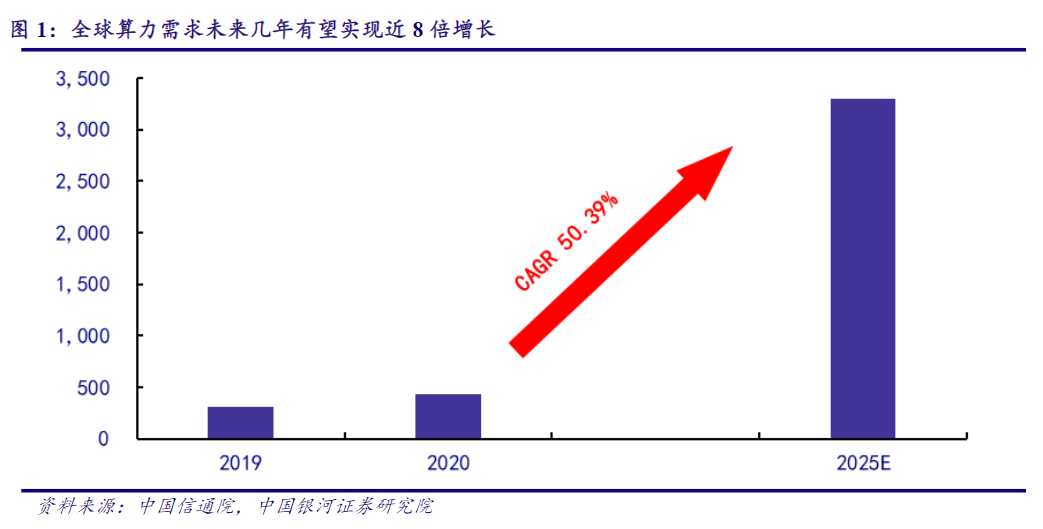
(全球算力需求未來增長情況 圖源:中國銀河證券研究院)
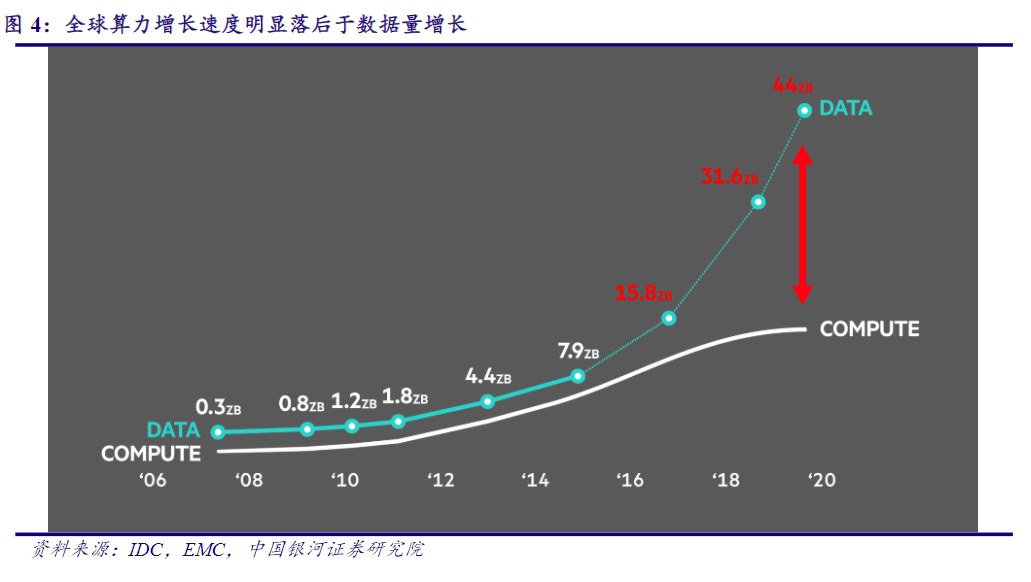
(全球算力增長速度明顯落后于數據量增長 圖源:中國銀河證券研究院)
數據量暴增,各國急需算力維系數據的正常運轉,各國之間的算力之爭,正式打響。而事實上遠不止算力之爭這么簡單,這背后,是各國國力的角逐。
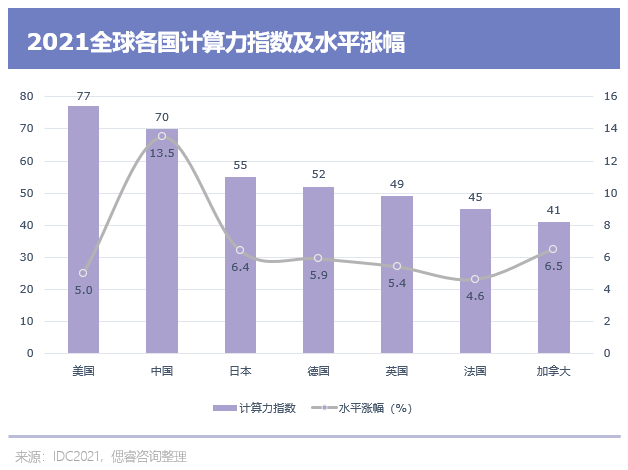
2022年3月,由IDC、浪潮信息、清華大學全球產業研究院聯合編制的《2021-2022全球計算力指數評估報告》,揭示了現如今“算力與國力”的基本關系:
全球各國算力規模與經濟發展水平顯著正相關,算力規模越大,經濟發展水平越高。計算力指數平均每提高1點,數字經濟和GDP將分別增長3.5‰和1.8‰;美國和中國的計算力指數分別為77分和70分,明顯領先其他國家的計算力指數。
場景眾多,不同的算力場景,對芯片的要求不同
小至耳機、手機、PC,大到汽車、互聯網、人工智能(AI)、數據中心、超級計算機、航天火箭等,“算力”都在其中發揮著基礎核心作用。而不同的算力場景,對芯片的要求不同:
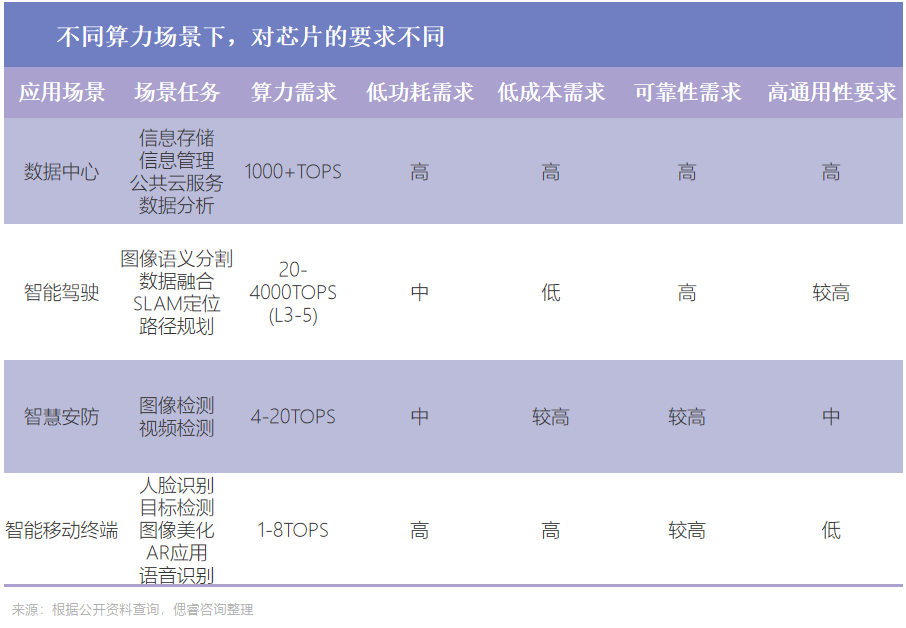
可以看到,數據中心由于其算法多樣、迭代速度更快等特性,對芯片的要求尤其高:既要其高算力、又要其低功耗、低成本、高可靠性,還要其具備更高的通用性。
數據中心建設,迫在眉睫
在眾多應用場景之中,數據中心尤為重要。作為AI基礎設施,數據中心承載著多個中心側與邊緣側算力的應用:
1、國家數據中心集群支撐工業互聯網、金融證券、災害預警、遠程醫療、視頻通話、人工智能推理。
2、城市內的數據中心作為算力“邊緣”端,服務金融市場高頻交易、VR/AR、超高清視頻、車聯網、聯網無人機、智慧電力、智能工廠、智能安防等。
現如今,算力、甚至是國力之爭,已然拉開序幕。
美國對中國數據中心、智算中心、超算中心的制裁自2021年就已開始:2021年4月,美國商務部對中國國家超級計算濟南中心、深圳中心、無錫中心、鄭州中心等中國超算實體列入“實體清單”。
基于下游市場的需求增長,地緣政治等因素,我國數據中心也快速提上日程:2021年5月,國家提出“東數西算”工程,明確圍繞8個國家算力樞紐,推進國家數據中心集群以及城市內部數據中心建設。

現如今,中國數據中心建設較于美國仍有一定差距:
《2021-2022全球計算力指數評估報告》指出,目前世界上大約有600個超大規模的數據中心,每個都擁有超過5000臺服務器,其中約39%在美國,是中國的4倍,而中國、日本、英國、德國和澳大利亞的服務器數量總和約占總數的30%。
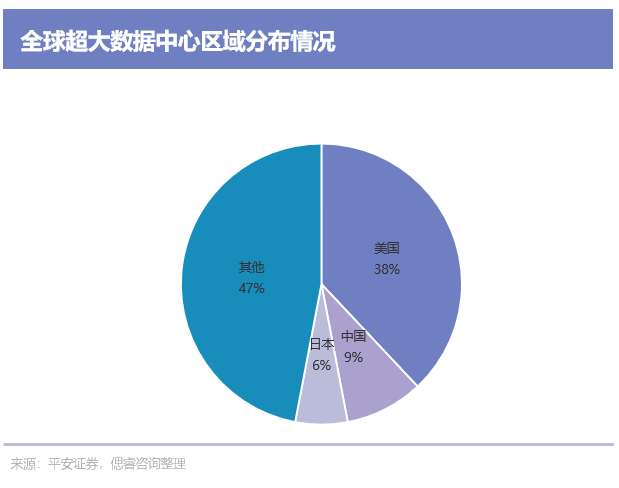
截至2021年底,我國在用數據中心機架總規模達 520 萬標準機架,在用數據中心服務器規模1900萬臺,算力總規模超過140 EFLOPS。
在算力即國力的大背景下,大模型的催化下,低成本、低功耗的大算力一定會成為剛需。中國,亟需能夠承載算力的自主可控的數據中心,而數據中心的算力,依賴著芯片的國產替代進度。
數據中心場景下,國產主流AI芯片,仍有差距
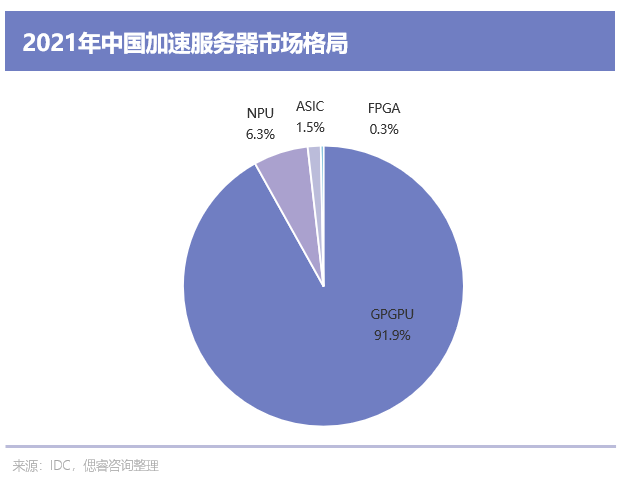
在數據中心這一基礎設施中,服務器占據69%。現如今,在數據中心加速服務器市場,GPGPU憑借著更高性能、更高通用性占主導地位:
根據IDC數據,2021年,GPU/GPGPU服務器以91.9%的份額占我國加速服務器市場的主導地位;而前面我們提到過的ASIC、FPGA等非GPU加速服務器僅占比8.1%。
而現階段,在云端數據中心場景下,國產GPGPU芯片較于國際頂尖水平,仍有差距。
在進行對比之前,我們需要明確的是,在云端(服務器端),對于訓練芯片、推理芯片的要求不全然相同:
訓練芯片需通過海量數據訓練出復雜的神經網絡模型,使其適應特定的功能,相應地,對性能和精度有較高的要求,并需具備一定的通用性;
推理芯片則是利用神經網絡模型進行推理預測,對峰值計算性能要求較低,則更加注重單位能耗算力、時延、成本等綜合指標。

AI訓練芯片,國產仍有差距
目前,壁仞科技、平頭哥、昆侖芯、沐曦、天數智芯等玩家對于云端數據中心皆有布局,其中,昆侖芯、平頭哥等大多廠商推出推理芯片;寒武紀、沐曦、天數智芯則推出訓推一體芯片。
近年來,國內廠商訓練芯片產品硬件性能不斷取得突破,但與市場主流英偉達A100產品仍存在一定差距:
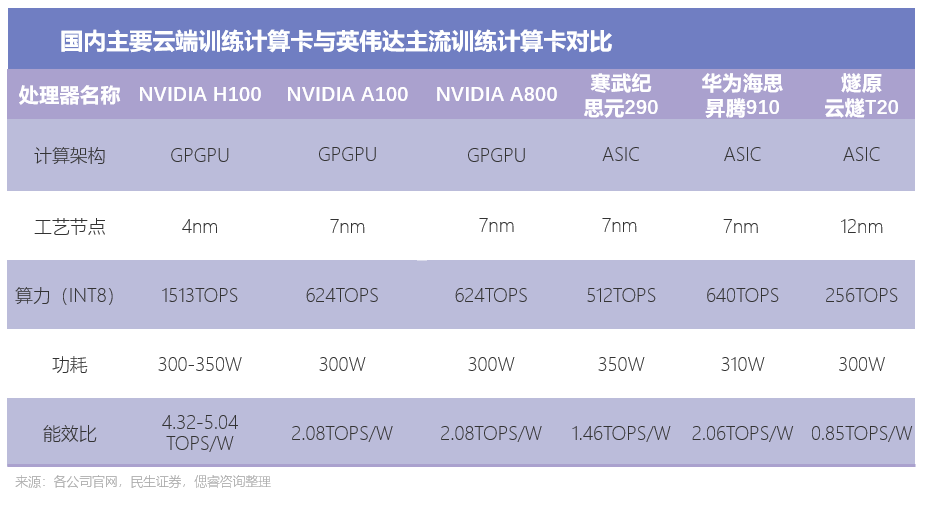
以燧原云邃T20產品為例,其32位單精度浮點性能達32TFLOPS,高于A100的19.5TFLOPS,且在功耗上更具優勢,但內存寬帶不足A100的1/3,在應對機器學習和深度學習的帶寬需求上仍有差距。
同時據浙商證券分析,寒武紀去年年底推出的思元590系列可能在部分模型上由于其ASIC專用性表現出更優異的性能,但由于其通用性不足,仍需要后期適配和技術支持。對比之下,中國AI訓練芯片仍與英偉達在性能、生態(兼容)有一定差距。
AI推理芯片,國產有望追平
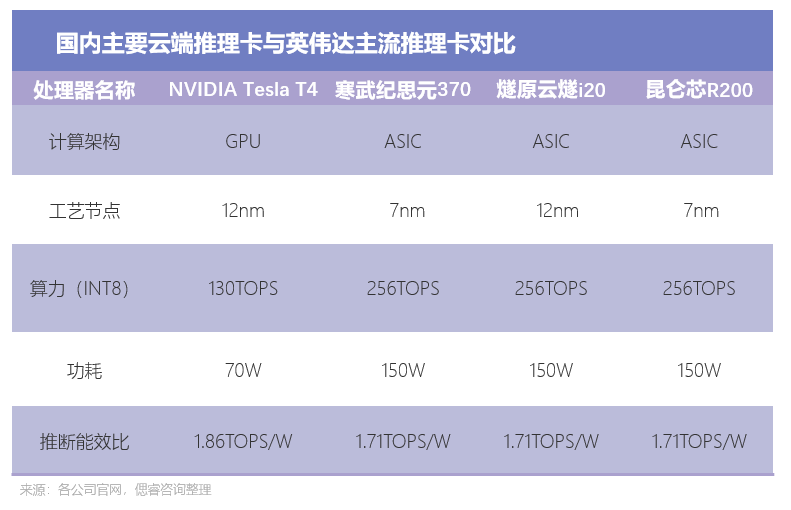
目前,寒武紀、燧原、昆侖芯等國內廠商產品已具備與市場主流的Tesla T4 正面競爭能力:其能效比為1.71TOPS/W,與T4的1.86TOPS/W差距較小。
算力優化路徑
差距猶在,國產AI廠商亟需趕上國際速度。大家提升芯片性能的第一步,都是卷先進制程。
現階段,先進制程芯片設計成本高昂:單位面積成本在14/16nm后陡增。
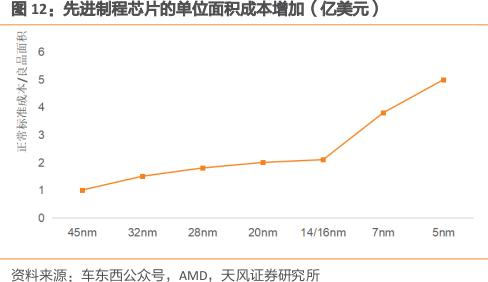
(先進制程芯片的單位面積成本增加 圖源:天風證券)
1、根據奇異摩爾數據,隨著制程從28nm制程演變到5nm,研發投入也從5130萬美元劇增至5.42億美元,2nm的開發費用接近20億美元,先進制程已然成了全球巨頭的燒錢競賽。
2、根據EETOP公眾號數據,在7nm節點,設計一款芯片的費用高達3億美元。且伴隨摩爾定律不斷放緩,晶體管同時逼近物理極限、成本極限。
由此,芯片上游企業也在瘋狂漲價:供貨商臺積電的先進制程晶圓價格每年都在漲,越漲越離譜。
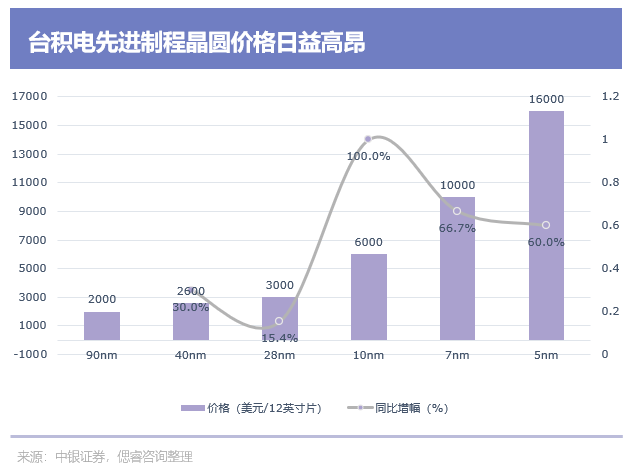
3、先前還是分制程漲價:2021年,臺積電在8月25日中午通知客戶全面漲價,即日起7nm及5nm先進制程將漲價7%至9%,其余的成熟制程漲價約20%;
4、而在2023年初,臺積電全線大幅度漲價:根據《電子時報》報道,臺積電12英寸5nm晶圓價格高達1.6萬美元/片,較上一代7nm晶圓漲價60%。
成本上漲將成為常態,更令人遺憾的是,在國內廠商已經把制程卷到7nm的情況下,性能也并沒有趕超英偉達。
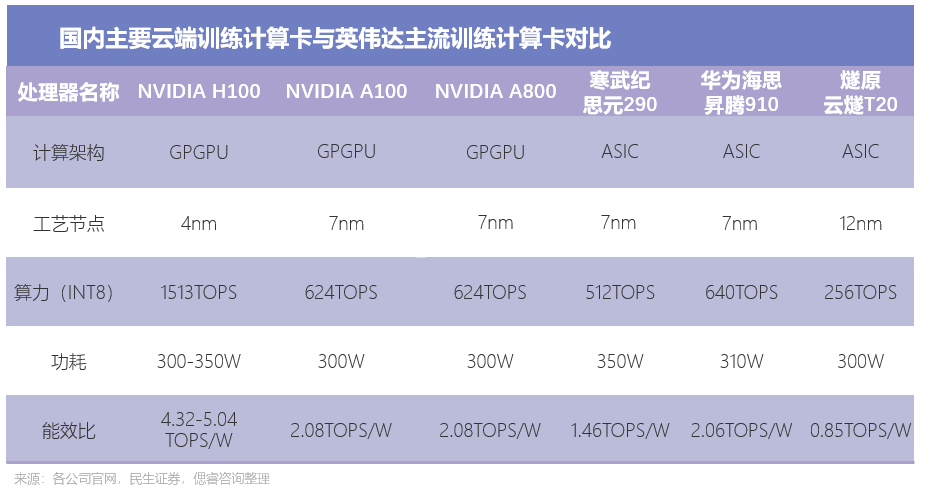
若是卷到5nm以達到更高的性能,芯片廠商得不償失:
首先是成本難以負擔,英偉達在GPGPU的護城河,是靠著錢砸出來的。據英偉達黃仁勛表示,光是A100芯片的研發成本,就是20-30億美元(百億元級別)以及4年時光。短期之內,國內初創企業沒有如此大的體量,也付不起時間成本。
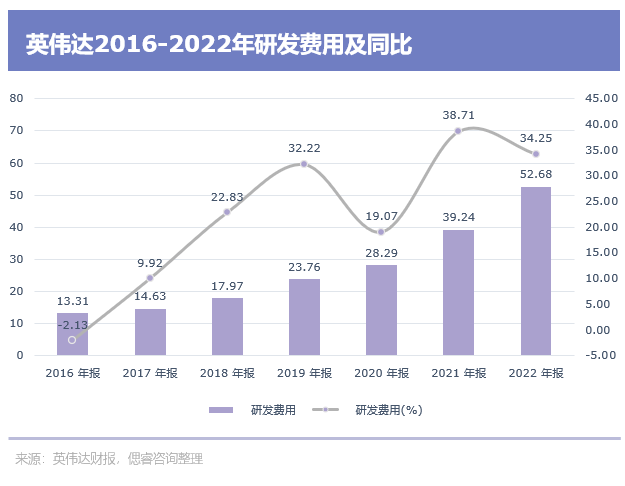
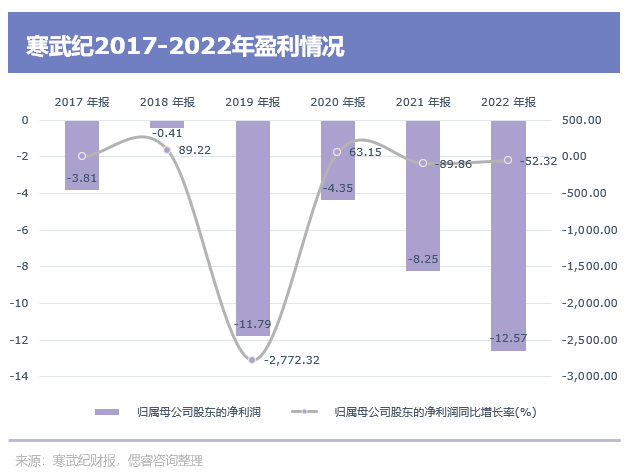
目前,高昂的研發成本已讓寒武紀等廠商,仍未盈利。
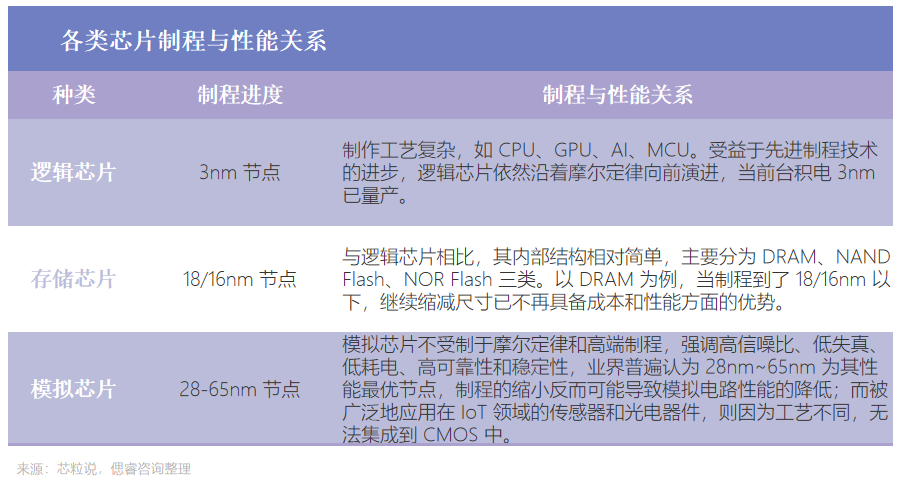
其次是錢花了,沒效果:性能并非保持“正增長”。邏輯芯片依然沿著摩爾定律向前演進,存儲芯片繼續縮減尺寸已不再具備成本和性能方面的優勢,模擬芯片制程的縮小反而可能導致模擬電路性能的降低。
同時,長期來看,7nm芯片比5nm成本效益更高:
美國喬治城大學發布了一份AI芯片研究報告,其中對采用不同工藝節點的AI芯片進行經濟效益分析。該報告通過量化模型揭示出,相比5nm工藝節點,7nm工藝芯片的成本收益更優。
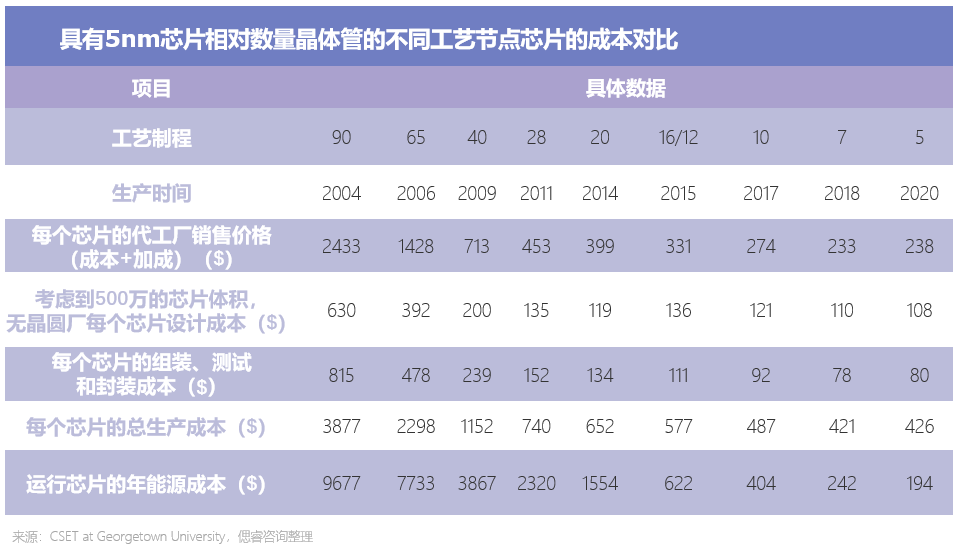
研究人員從該成本分析模型,得出兩個結論:
1、在正常運營兩年內,先進工藝(7/5nm)芯片的能耗成本就超過了其生產成本,采用舊工藝的芯片(10nm及以上)能耗成本增長更快。若綜合考慮生產成本和運營成本,先進工藝芯片的成本效益是舊工藝芯片的33倍。
2、對比7nm和5nm芯片,當正常運營使用8.8年時,二者的成本相當。這意味著,如果在8.8年以內更換芯片,7nm更劃算。鑒于數據中心AI訓練和推理所用的AI加速器大都是3年更換一次,單從成本效益來看7nm芯片比5nm更劃算。
除此之外,還有著地緣政治影響,國內的先進制程研發屢屢受阻。芯片苦于先進制程久矣,而提升芯片算力,絕非只是提升單芯片的性能,而是要考慮芯片的宏觀總算力。
宏觀總算力 = 性能*數量(規模)*利用率,而目前在CPU、GPU、AI等大算力芯片身上,我們能看到的是,很多方案不能兼顧這三大因素:
1、有的算力芯片,可以做到性能狂飆,但較少考慮芯片的通用性易用性,導致芯片銷量不高、落地規模小。例如通過FPGA定制,便是規模太小,成本和功耗太高。
2、有的算力提升方案,重在規模投入,但解決不了未來算力需求數量級提升的根本。
3、有的解決方案,通過各種資源池化和跨不同的邊界算力共享,來提升算力利用率,但改變不了目前算力芯片性能瓶頸的本質。
而想要達到大算力,需要兼顧性能、規模、利用率三大影響因子的、具備大局觀的方案。
算力解決方案,蓄勢待發
以AI云端推理卡為例,我們能看到的是,2018-2023年,算力由于工藝制程“卷不動”等種種原因,成本、功耗、算力難以兼顧。
但國力之爭已然打響,ChatGPT已然到來,市場亟需兼顧成本、功耗、算力的方案。
目前國際大廠、國內主流廠商、初創企業都在謀求計算架構創新,試圖找出兼顧性能、規模、利用率的方案,突破算力天花板。
對于架構創新,業內給出不少技術及方案:量子計算(量子芯片)、光子芯片、存算一體、芯粒(Chiplet)、3D封裝、HBM······

在這之中,現在能夠兼容CMOS工藝又能盡快量產的,有HBM、芯粒、3D封裝、存算一體。而存算一體、芯粒(Chiplet)是目前業內普遍認為,能夠突破 AI 算力困境,進行架構創新的兩條清晰路線。
用存算一體消除數據隔閡
從傳統馮·諾依曼架構到存算一體架構,通俗來講,就是消除數據與數據的隔閡,讓其更高效地工作。
在傳統馮·諾伊曼架構之下,芯片的存儲、計算區域是分離的。計算時,數據需要在兩個區域之間來回搬運,而隨著神經網絡模型層數、規模以及數據處理量的不斷增長,數據已經面臨“跑不過來”的境況,成為高效能計算性能和功耗的瓶頸,也就是業內俗稱的“存儲墻”。
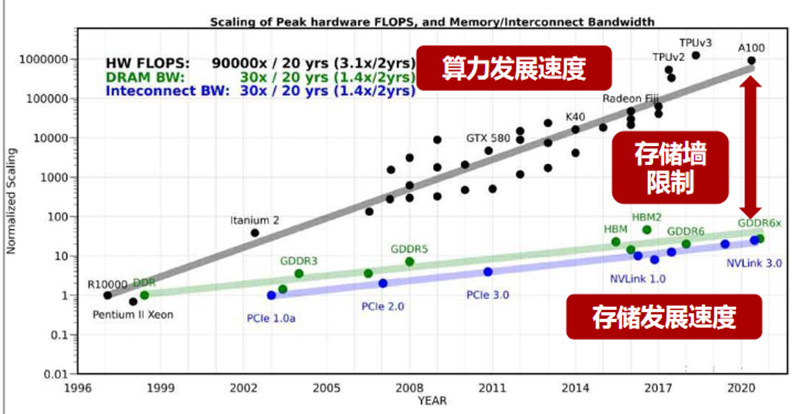
(存儲墻限制具體表現 圖源:浙商證券)
存儲墻相應地也帶來了能耗墻、編譯墻(生態墻)的問題。例如編譯墻問題,是由于大量的數據搬運容易發生擁塞,編譯器無法在靜態可預測的情況下對算子、函數、程序或者網絡做整體的優化,只能手動、一個個或者一層層對程序進行優化,耗費了大量時間。
這“三堵墻”會導致算力無謂浪費:據統計,在大算力的AI應用中,數據搬運操作消耗90%的時間和功耗,數據搬運的功耗是運算的650倍。
而存算一體能夠將存儲和計算融合,徹底消除了訪存延遲,并極大降低了功耗。基于此,浙商證券報告指出,存算一體的優勢包括但不限于:具有更大算力(1000TOPS以上)、具有更高能效(超過10-100TOPS/W)、降本增效(可超過一個數量級)······
如下圖所示,相較于GPGPU,存算一體芯片能夠實現更低能耗、更高能效比,在應用落地方面能夠助力數據中心降本增效,賦能綠色算力。
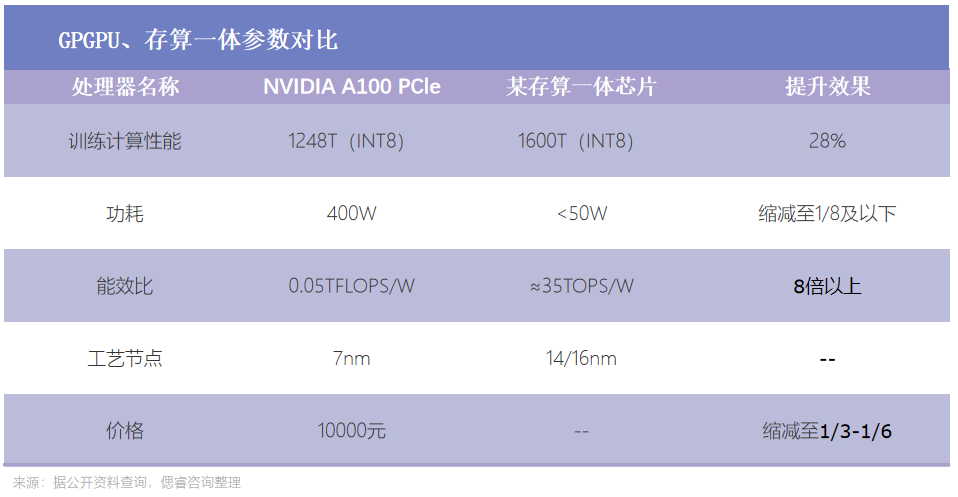
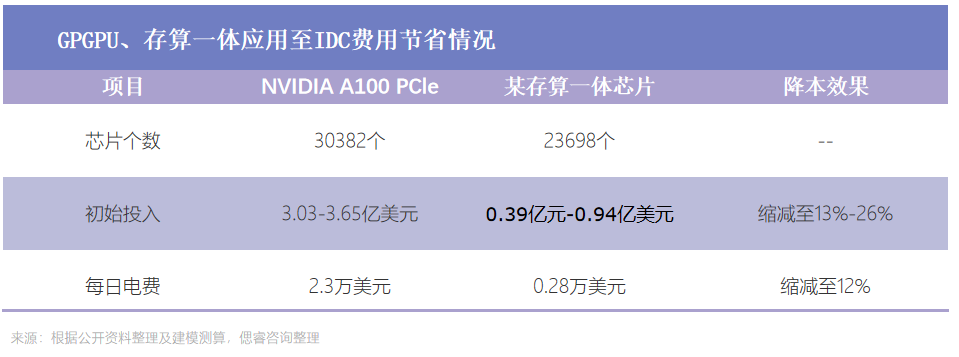
基于此,若是處理一天的咨詢量,存算一體芯片在初始投入上,是A100的13%-26%,在每日電費上,是A100的12%。
用Chiplet賦予芯片更多能力
除了打破數據之間的墻,芯片設計廠商試圖賦予芯片更多的能力:把任務分發給不同架構的硬件計算單元(比如CPU、GPU、FPGA),讓他們各司其職,同步工作,提高效率。
回顧計算機發展史,AI芯片處理器從單核—多核,計算從串行—并行,從同構并行到異構并行。
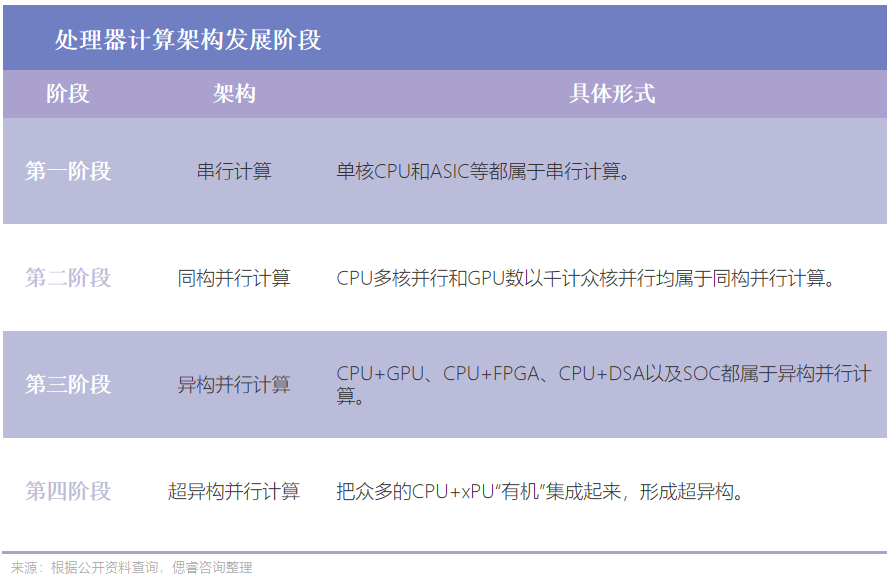
當摩爾定律還是行業的鐵律,也就是第一階段時,計算機編程幾乎一直都是串行的。絕大多數的程序只存在一個進程或線程。
此時,性能依賴于硬件工藝。而2003年以后,因為工藝達到了瓶頸,光是靠硬件提升行不通了。隨后,即便迎來了同構計算(疊加多個核,強行提升算力),但總體的天花板仍然存在。
異構并行計算的到來,開辟了新的技術變革:把任務分發給不同架構的硬件計算單元(比如說CPU、GPU、FPGA),讓他們各司其職,同步工作,提高效率。
異構的好處,從軟件的角度來講,異構并行計算框架能夠讓軟件開發者高效地開發異構并行的程序,充分使用計算平臺資源。
從硬件角度來講,一方面,多種不同類型的計算單元通過更多時鐘頻率和內核數量提高計算能力;另一方面,各種計算單元通過技術優化提高執行效率。
在這之中,Chiplet是關鍵技術。
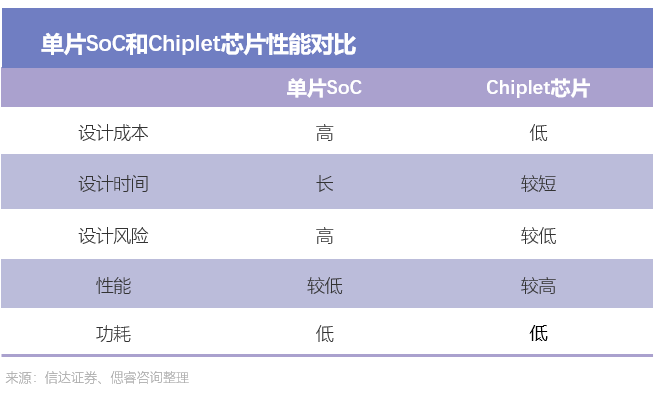
在當前技術進展下,Chiplet方案能夠實現芯片設計復雜度及設計成本降低。IC設計階段將SoC按照不同功能模塊分解為多個芯粒,部分芯粒實現模塊化設計并在不同芯片中重復使用,能夠實現設計難度降低,且有利于后續產品迭代,加速產品上市周期。
用HBM技術拓寬“數據通道”
由于半導體產業的發展和需求的差異,處理器和存儲器二者之間走向了不同的工藝路線,這也就意味著,處理器與存儲器的工藝、封裝、需求大不相同。
這就導致,從1980年開始至今,二者之間的性能差距越來越大。數據顯示,從1980年到2000年,處理器和存儲器的速度失配以每年50%的速率增加。
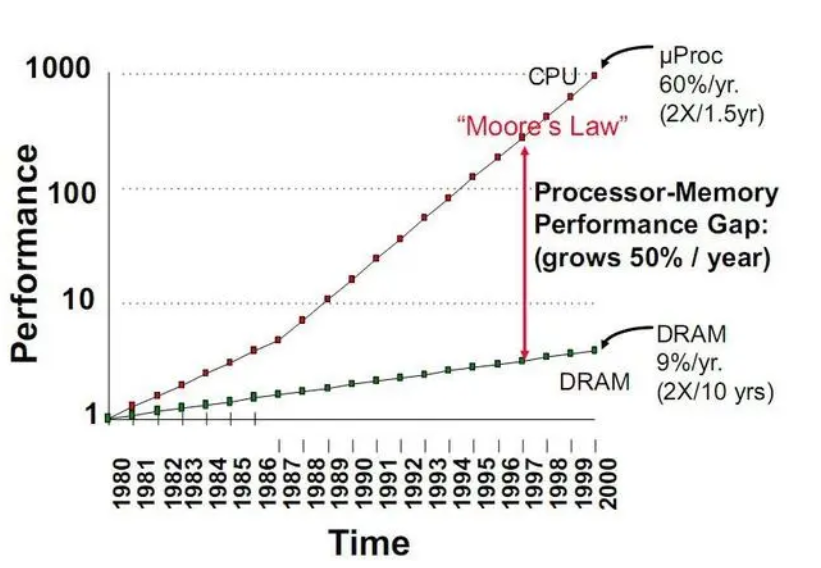
(1980-2000年,處理器和存儲器兩者的速度失配以每年50%的速率增加 圖源:電子工程專輯)
存儲器數據訪問速度跟不上處理器的數據處理速度,兩者之間數據交換通路狹窄以及由此引發的高能耗兩大難題,在存儲與運算之間筑起了一道“內存墻”。
為了減小內存墻的影響,提升內存帶寬一直是存儲芯片關注的技術問題。黃仁勛曾表示計算性能擴展最大的弱點就是內存帶寬。
HBM,便是該難題的解法。
高帶寬存儲器(High Bandwidth Memory),是一種硬件存儲介質。基于其高吞吐高帶寬的特性,受到工業界和學術界的關注。
HBM其中一個優勢就是通過中介層縮短內存與處理器之間的距離,通過先進的3D封裝方式把內存和計算單元封裝在一起,提高數據搬運速度。
超異構,兼顧性能、規模、利用率的新興方案
超異構計算,是能夠把更多的異構計算整合重構,從而能讓各類型處理器間充分地、靈活地進行數據交互而形成的計算。
簡單來說,就是聚合DSA、GPU、CPU、CIM等多個類型引擎的優勢,同時結合Chiplet、3D封裝等新興架構,實現性能的飛躍:
√ DSA負責相對確定的大計算量的工作;
√ GPU負責應用層有一些性能敏感的并且有一定彈性的工作;
√ CPU啥都能干,負責兜底;
√ CIM就是存內計算,超異構和普通異構的主要區別就是加入了CIM,由此可以實現同等算力,更低能耗;同等能耗,更高算力。另外,CIM由于器件的優勢,能負擔比DSA更大的算力。
超異構計算能夠很好解決性能、規模、利用率問題。
在性能層面,由于存算一體的加入,能夠實現同等算力,更低能耗;同等能耗,更高算力;
在規模層面,由于超異構基于一個計算平臺能夠聚合多個類型引擎,能夠兼顧靈活性與通用性,也就沒有因為不夠通用導致規模過小;又由于該方案較為全能,能夠應付各類型的任務,利用率也能夠得到提升。
超異構未來研究方向
而現實是,僅僅是異構計算,便面臨著編程很難的困境,NVIDIA經過數年的努力,才讓CUDA的編程對開發者足夠友好,形成主流生態。
超異構就更是難上加難:超異構的難,不僅僅體現在編程上,也體現在處理引擎的設計和實現上,還體現在整個系統的軟硬件能力整合上。
對于更好地駕馭超異構,軟硬件融合給出了方向:
1、兼顧性能和靈活性。從系統的角度,系統的任務從CPU往硬件加速下沉,如何選擇合適的處理引擎,達到最優性能的同時,有最優的靈活性。并且不僅僅是平衡,更是兼顧。
2、編程及易用性。系統逐漸從硬件定義軟件,轉向了軟件定義硬件。如何利用這些特征,如何利用已有軟件資源,以及如何融入云服務。
3、產品。用戶的需求,除了需求本身之外,還需要考慮不同用戶需求的差異性,和單個用戶需求的長期迭代。該如何提供給用戶更好的產品,滿足不同用戶短期和長期的需求。授人以魚不如授人以漁,該如何提供用戶沒有特定的具體功能的、性能極致的、完全可編程的硬件平臺。
算力即國力,數據中心是各國開展國力之爭的“根據地”。數據中心亟需大算力芯片,滿足各大中心側、邊緣側應用場景的需求。
然而在數據中心應用場景下,國內現有云端AI訓練、推理芯片仍與尖子生英偉達A100芯片有較大差距。同時,現階段工藝制程已達到物理極限、成本極限,尋求更高效的計算架構,才是上上之選。
現如今,存算一體,Chiplet,3D封裝等技術現已成熟,超異構等解決方案可實施性較高。傳統架構上,各國差距明顯,而在新型技術上,各國難分伯仲。
算力之爭的格局,正悄然發生變化。
03.國內AI芯片,百舸爭流,勝局未定
傳統架構下,英偉達一家獨大
按照市場格局來分,在AI芯片領域,目前有三類玩家。
一種是以 Nvidia、AMD 為代表的老牌芯片巨頭,這些企業積累了豐富的經驗,產品性能突出。根據上文可知,在云端場景下,無論是推理芯片還是訓練芯片,國內廠商皆與其有差距。
另一種是以 Google、百度、華為為代表的云計算巨頭,這些企業紛紛布局通用大模型,并自己開發了 AI 芯片、深度學習平臺等支持大模型發展。如 Google 的 TensorFlow 以及 TPU,華為的鯤鵬、昇騰,阿里平頭哥的含光800。
最后是AI 芯片獨角獸,如寒武紀、壁仞科技、地平線等,憑借雄厚的技術實力、資金基礎、研發團隊,闖進AI芯片賽道。
目前,英偉達占據80%以上中國加速卡市場份額,國產 AI 芯片亟待發展:根據 IDC 的數據顯示,2021 年中國加速卡的出貨數量已經超過 80 萬片,其中 Nvidia 占據了超過 80%的市場份額。剩下的份額被 AMD、百度、寒武紀、燧原科技、新華三、華為等品牌占據。
技術路徑背后,暗藏玄機
按照計算架構分類,目前國內大抵分為三大陣營:ASIC、GPGPU、存算一體玩家。
通過梳理各廠商使用架構、應用場景、資源稟賦,可以發現以下幾條線索:
大廠與自動駕駛專業芯片廠商們,偏愛ASIC。
國內大廠華為海思、百度、平頭哥皆選擇ASIC作為自己的芯片架構:
1、華為選擇部署端到端的完整生態,例如使用昇騰910必須搭配華為的大模型支持框架MindSpore、盤古大模型。
2、阿里在該方面的定位是系統集成商和服務商,運用自身芯片產品搭建加速平臺中,對外輸出服務。
3、百度昆侖芯主要在自身智算集群和服務器上以及國內企業、研究所、政府中使用。
ASIC盡管集成度非常高,性能可以充分發揮、功耗可以得到很好的控制,但缺點也很明顯:應用場景局限、依賴自建生態、客戶遷移難度大、學習曲線較長等問題。
而大廠皆擁有多個特定場景,ASIC“應用場景局限、客戶遷移難度大”的弊端在大廠場景下便不復存在,同時選擇ASIC在量產制造供應鏈上的難度顯著低于GPU。
專注于自動駕駛場景的AI芯片廠商例如地平線、黑芝麻,由于手握多家訂單,同樣避免了ASIC的弊端:截止2023年4月23日,地平線征程芯片出貨量突破了300萬片,與超過20家車企,共計120多款車型達成量產定點合作。
2017年后,AI芯片獨角獸們,加入GPGPU陣營。
由于ASIC只能在特定場景、固有算法之下發揮極致性能,廠商們要么需要自身有特定場景(例如華為等大廠),要么綁定大客戶(例如耐能科技)。而更為通用的GPGPU展現出該有的性能之后,成為國產AI芯片公司的首選。
可以看到,選擇GPGPU的登臨科技、天數智芯、燧原科技已經把訓練與推理都全面覆蓋,而ASIC大多芯片例如平頭哥,只能專注于推理或是訓練場景。
2019年前后,新一批AI芯片獨角獸們,押注存算一體
AI算力芯片發展至2019年前后,國內AI芯片廠商們發現,在傳統架構下,CPU、GPU、FPGA已被國外壟斷,且高度依賴先進工藝制程,缺乏一定先進制程技術儲備的國內AI廠商,紛紛尋找新的解法——存算一體芯片。目前,存算一體格局未定,或將成為國內廠商破局關鍵。存算一體主流的劃分方法是依照計算單元與存儲單元的距離,將其大致分為近存計算(PNM)、存內處理(PIM)、存內計算(CIM)。

特斯拉、阿里達摩院、三星等大廠所選擇的,是近存計算。
據Dojo項目負責人Ganesh Venkataramanan介紹,特斯拉Dojo(AI訓練計算機)所用的D1芯片相比于業內其他芯片,同成本下性能提升4倍,同能耗下性能提高1.3倍,占用空間節省5倍。具體來說,在D1訓練模塊方面,每個D1訓練模塊由5x5的D1芯片陣列排布而成,以二維Mesh結構互連。片上跨內核SRAM達到驚人的11GB,由于用上近存計算架構,能效比為0.6TFLOPS/W@BF16/CFP8。業內人士表示,對于CPU架構來說,這一能效比非常不錯。
阿里達摩院在2021年發布采用混合鍵合(Hybrid Bonding)的3D堆疊技術——將計算芯片和存儲芯片face-to-face地用特定金屬材質和工藝進行互聯。據阿里達摩院測算,在實際推薦系統應用中,相比傳統CPU計算系統,存算一體芯片的性能提升10倍以上,能效提升超過300倍。
三星基于存內處理架構,發布存儲器產品HBM-PIM(嚴格意義上是PNM)。三星表示該架構實現了更高性能與更低能耗:與其他沒有HBM-PIM芯片的GPU加速器相比,HBM-PIM芯片將AMD GPU加速卡的性能提高了一倍,能耗平均降低了約50%。與僅配備HBM的GPU加速器相比,配備HBM-PIM的GPU加速器一年的能耗降低了約2100GWh。
國內知存科技選擇的是,存內處理:2022年3月,知存科技量產的基于PIM的SoC芯片WTM2101正式投入市場。距今未滿1年,WTM2101已成功在端側實現商用,提供語音、視頻等AI處理方案并幫助產品實現10倍以上的能效提升。
而存內計算,便是國內大部分初創公司所說的存算一體:
億鑄科技,基于CIM框架、RRAM存儲介質的研發“全數字存算一體”大算力芯片,通過減少數據搬運提高運算能效比,同時利用數字存算一體方法保證運算精度,適用于云端AI推理和邊緣計算。
智芯科微,于2022年底推出業界首款基于SRAM CIM的邊緣側AI增強圖像處理器。
在存算一體陣營之中,大廠與初創公司同樣因為技術路徑,走了不同的路。
大公司與初創公司“自覺”分為兩個陣營:特斯拉、三星、阿里巴巴等擁有豐富生態的大廠以及英特爾,IBM等傳統的芯片大廠,幾乎都在布局PNM;而知存科技、億鑄科技、智芯科等初創公司,在押注PIM、CIM等“存”與“算”更親密的存算一體技術路線。
綜合生態大廠思量的是,如何快速攻破算力和功耗的瓶頸,讓自己豐富的應用場景快速落地;芯片大廠們針對客戶所提出的高效算力和低功耗需求,開發出符合客戶需求的技術。
也就是說,大廠對存算一體架構提出的需求是“實用、落地快”,近存計算作為最接近工程落地的技術,成為大廠們的首選。
而中國初創公司們,由于成立時間較短、技術儲備薄弱:缺乏先進2.5D和3D封裝產能和技術,為打破美國的科技壟斷,中國初創企業聚焦的是無需考慮先進制程技術的CIM。
云端場景下,玩家由淺入深
不同的業務場景均已呈現出各自的優勢,在商業模式上國內外都在探索階段。而不論是國內外公司,先云端推理是大家一致的方向。
業界普遍認為,訓練芯片的研發難度和商業化落地更難,訓練芯片可以做推理,但推理芯片不能做訓練。
原因是,在AI訓練的過程中,神經網絡模型并沒有固定,所以對芯片的通用性有很高的需求。而推理則更簡單,增速更快,故而訓練芯片對于芯片公司的設計能力考驗更高。
從全球AI芯片市場來看,先推理后訓練是主流路徑,英特爾收購的AI芯片公司Habana、國內諸多AI初創公司皆是如此。
如此選擇,也是下游市場的催化作用:
隨著近年來 AI 模型訓練逐漸成熟,AI 應用逐漸落地,云端推理的市場已經逐漸超過了訓練的市場:
根據IDC與浪潮聯合發布的《2020-2021中國人工智能計算力發展評估報告》顯示,2021 年中國市場 AI 服務器的推理負載超過訓練負載,并且隨著 AI 進入應用期,數據中心推理算力需求的復合增長率是訓練側的2倍以上,預計到2026年用于推理的加速器占比將超過 60%。
AI芯片“新星”存算一體門檻奇高
2019年后,新增的AI芯片廠商,多數在布局存算一體:據偲睿洞察不完全統計,在2019-2021年新增的AI芯片廠商有20家,在這之中,有10家選擇存算一體路線。
這無一不說明著,存算一體將成為繼GPGPU、ASIC等架構后的,一顆冉冉升起的新星。而這顆新星,并不是誰都可以摘。
在學界、產界、資本一致看好存算一體的境況下,強勁的技術實力、扎實的人才儲備以及對遷移成本接受度的精準把控,是初創公司在業內保持競爭力的關鍵,也是擋在新玩家面前的三大門檻。
存算一體,打破了三堵墻,能夠實現低功耗、高算力、高能效比,但想要實現如此性能,挑戰頗多:
首先是存算一體涉及到芯片制造的全環節:從最底層的器件,到電路設計,架構設計,工具鏈,再到軟件層的研發;
其次是,在每一層做相應改變的同時,還要考慮各層級之間的適配度。
我們一層一層來看,一顆存算一體芯片被造出來,有怎樣的技術難題。
首先,在器件選擇上,廠商就“如履薄冰”:存儲器設計決定芯片的良率,一旦方向錯誤將可能導致芯片無法量產。
其次是電路設計層面。電路層面有了器件之后,需要用其做存儲陣列的電路設計。而目前在電路設計上,存內計算沒有EDA工具指導,需要靠手動完成,無疑又大大增加了操作難度。
緊接著,架構層面有電路之后,需要做架構層的設計。每一個電路是一個基本的計算模塊,整個架構由不同模塊組成,存算一體模塊的設計決定了芯片的能效比。模擬電路會受到噪聲干擾,芯片受到噪聲影響后運轉起來會遇到很多問題。
這種情況下,需要架構師了解模擬存內計算的工藝特點,針對這些特點去設計架構,同時也要考慮到架構與軟件開發的適配度。
軟件層面架構設計完成后,需要開發相應的工具鏈。

而由于存算一體的原始模型與傳統架構下的模型不同,編譯器要適配完全不同的存算一體架構,確保所有計算單元能夠映射到硬件上,并且順利運行。
一條完整的技術鏈條下來,考驗著器件、電路設計、架構設計、工具鏈、軟件層開發各個環節的能力,與協調各個環節的適配能力,是耗時耗力耗錢的持久戰。
根據以上環節操作流程可以看到,存算一體芯片亟需經驗豐富的電路設計師、芯片架構師。
除此之外,鑒于存算一體的特殊性,能夠做成存算一體的公司在人員儲備上需要有以下兩點特征:
1、帶頭人需有足夠魄力。在器件選擇(RRAM、SRAM等)、計算模式(傳統馮諾依曼、存算一體等)的選擇上要有清晰的思路。
這是因為,存算一體作為一項顛覆、創新技術,無人引領,試錯成本極高。能夠實現商業化的企業,創始人往往具備豐富的產業界、大廠經驗和學術背景,能夠帶領團隊快速完成產品迭代。
2、在核心團隊中,需要在技術的各個層級中配備經驗豐富的人才。例如架構師,其是團隊的核心。架構師需要對底層硬件,軟件工具有深厚的理解和認知,能夠把構想中的存算架構通過技術實現出來,最終達成產品落地;
3、此外,據量子位報告顯示,國內缺乏電路設計的高端人才,尤其在混合電路領域。存內計算涉及大量的模擬電路設計,與強調團隊協作的數字電路設計相比,模擬電路設計需要對于工藝、設計、版圖、模型pdk以及封裝都極度熟悉的個人設計師。
落地,是第一生產力。在交付時,客戶考量的并不僅僅是存算一體技術,而是相較于以往產品而言,存算一體整體SoC的能效比、面效比和易用性等性能指標是否有足夠的提升,更重要的是,遷移成本是否在承受范圍內。
如果選擇新的芯片提升算法表現力需要重新學習一套編程體系,在模型遷移上所花的人工成本高出購買一個新GPU的成本,那么客戶大概率不會選擇使用新的芯片。
因此,存算一體在落地過程中是否能將遷移成本降到最低,是客戶在選擇產品時的關鍵因素。
目前來看,英偉達憑借著更為通用的GPGPU霸占了中國AI加速卡的市場。
然而,存算一體芯片憑借著低功耗但高能效比的特性,正成為芯片賽道,冉冉升起的一顆新星。
而存算一體市場,風云未定,仍處于“小荷才露尖尖角”階段。但我們不可否認的是,存算一體玩家已然構筑了三大高墻,非技術實力雄厚,人才儲備扎實者,勿進。
04.行業發展趨勢
存算一體,算力的下一級
隨著人工智能等大數據應用的興起,存算一體技術得到國內外學界與產界的廣泛研究與應用。在2017年微處理器頂級年會(Micro 2017)上,包括英偉達、英特爾、微軟、三星、加州大學圣塔芭芭拉分校等都推出他們的存算一體系統原型。
自此,ISSCC上存算/近存算相關的文章數量迅速增加:從20年的6篇上漲到23年的19篇;其中數字存內計算,從21年被首次提出后,22年迅速增加到4篇,23年有6篇。

(ISSCC2023存算一體相關文章 圖源:ISSCC2023)
系統級創新,嶄露頭角
系統級創新正頻頻現身半導體TOP級會議,展露著打破算力天花板的潛力。
在 AMD 的總裁兼CEO Lisa Su(蘇姿豐)帶來的主旨演講“Innovation for the next decade of compute efficiency“(下一個十年計算效率的創新)中,她提到了AI應用的突飛猛進,以及它給芯片帶來的需求。
Lisa Su表示,根據目前計算效率每兩年提升2.2倍的規律,預計到2035年,如果想要算力達到十萬億億級,則需要的功率可達500MW,相當于半個核電站能產生的功率,“這是極為離譜、不切合實際的”。
而為了實現這樣的效率提升,系統級創新是最關鍵的思路之一。
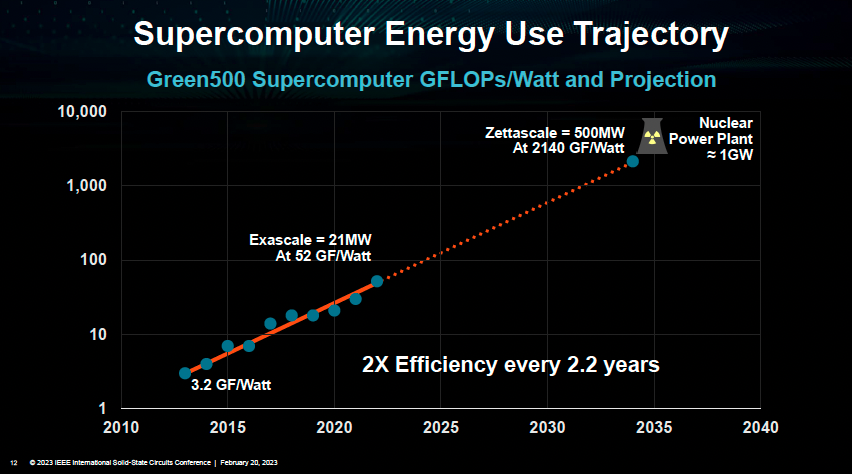
(算力與功耗關系 圖源:ISSCC2023大會)
在另一個由歐洲最著名三個的半導體研究機構IMEC/CEA Leti/Fraunhofer帶來的主旨演講中,系統級創新也是其核心關鍵詞。
該演講中提到,隨著半導體工藝逐漸接近物理極限,新的應用對于芯片的需求也必須要從系統級考慮才能滿足,并且提到了下一代智能汽車和AI作為兩個尤其需要芯片從系統級創新才能支持其新需求的核心應用。
“從頭到腳”打破算力天花板
系統級創新,是協同設計上中下游多個環節,實現性能的提升。還有一種說法是,系統工藝協同優化。
系統工藝協同優化為一種“由外向內”的發展模式,從產品需支持的工作負載及其軟件開始,到系統架構,再到封裝中必須包括的芯片類型,最后是半導體制程工藝。
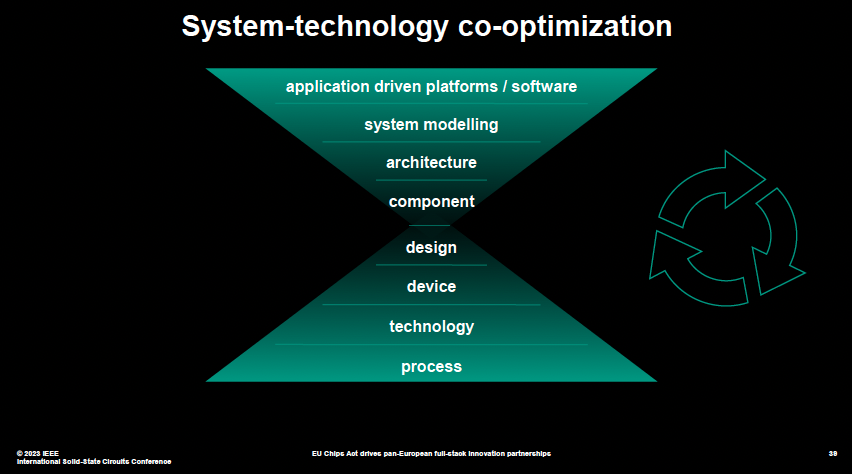
(系統工藝協同優化 圖源:ISSCC2023大會)
簡單來說,就是把所有環節共同優化,由此盡可能地改進最終產品。
對此,Lisa Su給出了一個經典案例:在對模型算法層面使用創新數制(例如8位浮點數FP8)的同時,在電路層對算法層面進行優化支持,最終實現計算層面數量級的效率提升:相比傳統的32位浮點數(FP32),進行系統級創新的FP8則可以將計算效率提升30倍之多。而如果僅僅是優化FP32計算單元的效率,無論如何也難以實現數量級的效率提升。
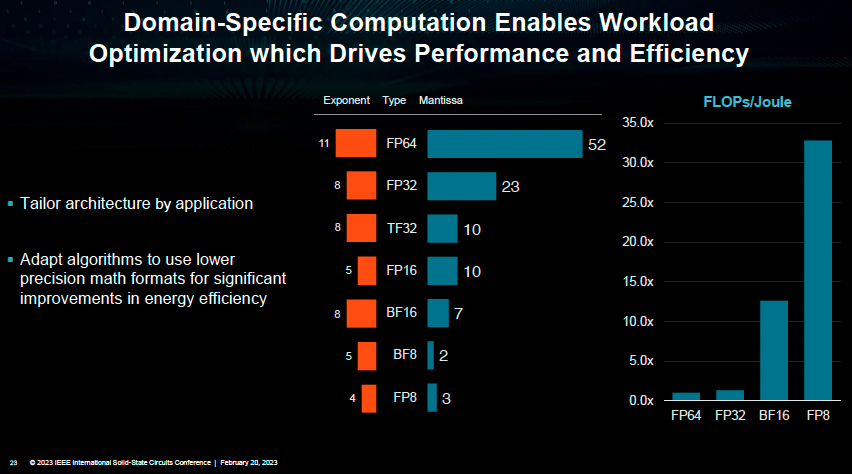
(特定域計算支持工作負載優化,從而提高性能和效率 圖源:ISSCC2023大會)
這便是系統級創新成為關鍵路徑的原因所在:如果電路設計僅僅停留在電路這一層——只是考慮如何進一步優化FP32計算單元的效率,無論如何也難以實現數量級的效率提升。
對此,在未來發展機會模塊的演講中,Lisa Su給出了未來系統級封裝架構的大致模樣:包含異構計算叢集,特定加速單元,先進封裝技術,高速片間UCIe互聯,存算一體等內存技術。
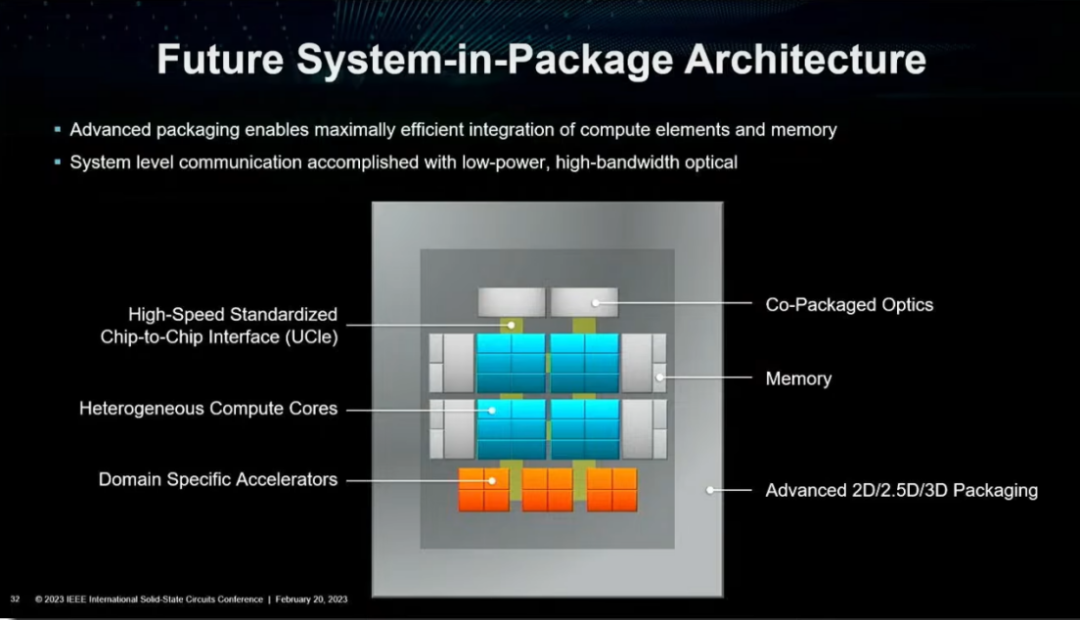
(未來的系統級封裝架構 圖源:ISSCC2023大會)
百舸爭流,創新者先
技術路徑、方案已然明確,接下來就是拼魄力的階段。
每一個新興技術的研發廠商,在前期無疑要面臨技術探索碰壁,下游廠商不認同等各個層面的問題。而在早期,誰先預判到未來的發展趨勢,并用于邁出探索的腳步,鋪下合理的資源去嘗試,就會搶到先機。
芯片巨頭NVIDIA在這方面做出了很好的榜樣。
當數據中心浪潮還未鋪天蓋地襲來、人工智能訓練還是小眾領域之時,英偉達已經投入重金,研發通用計算GPU和統一編程軟件CUDA,為英偉達謀一個好差事——計算平臺。
而在當時,讓GPU可編程,是“無用且虧本”的:不知道其性能是否能夠翻倍,但產品研發會翻倍。為此,沒有客戶愿意為此買單。但預判到單一功能圖形處理器不是長遠之計的英偉達毅然決定,在所有產品線上都應用CUDA。
在芯東西與英偉達中國區工程和解決方案高級總監賴俊杰博士的采訪中,賴俊杰表示:“為了計算平臺這一愿景,早期黃仁勛快速調動了英偉達上上下下非常多的資源。”
遠見+重金投入,在2012年,英偉達拿到了創新者的獎勵:2012年,深度學習算法的計算表現轟動學術圈,作為高算力且更為通用、易用的生產力工具,GPU+CUDA迅速風靡計算機科學界,成為人工智能開發的“標配”。
現如今,存算一體已顯現出強大的性能,在人工智能神經網絡、多模態的人工智能計算、類腦計算等大算力場景,有著卓越的表現。
國內廠商也在2019年前后紛紛布局存算一體,同時選擇3D封裝、chiplet等新興技術,RRAM、SRAM等新興存儲器,突破算力天花板。
AI大算力芯片的戰爭,創新者為先。
05.結語
ChatGPT火爆來襲,引發AI產業巨浪,國產AI芯片正迎來3.0時代;在3.0時代,更適配大模型的芯片架構——存算一體將嶄露頭角,同時系統級創新將成為未來的發展趨勢,搶先下注的廠商將先吃到ChatGPT帶來的紅利。
—END—
-
人工智能
+關注
關注
1794文章
47622瀏覽量
239591 -
深度學習
+關注
關注
73文章
5512瀏覽量
121405 -
AI芯片
+關注
關注
17文章
1903瀏覽量
35157
原文標題:大模型背景下,AI芯片廠商面臨怎樣的機遇與挑戰?
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AMD MI300X AI芯片面臨挑戰
Cadence如何應對AI芯片設計挑戰
產業"內卷化"下磁性元件面臨的機遇與挑戰








 工商網監
工商網監
評論