") 論文插圖也能自動(dòng)生成了!用到了擴(kuò)散模型,還被ICLR 2023接收!
論文插圖也能自動(dòng)生成了!用到了擴(kuò)散模型,還被ICLR 2023接收!
如果論文中的圖表不用繪制,對(duì)于研究者來(lái)說(shuō)是不是一種便利呢?有人在這方面進(jìn)行了探索,利用文本描述生成論文圖表,結(jié)果還挺有模有樣的呢!
生成式 AI 已經(jīng)風(fēng)靡了人工智能社區(qū),無(wú)論是個(gè)人還是企業(yè),都開(kāi)始熱衷于創(chuàng)建相關(guān)的模態(tài)轉(zhuǎn)換應(yīng)用,比如文生圖、文生視頻、文生音樂(lè)等等。
最近呢,來(lái)自 ServiceNow Research、LIVIA 等科研機(jī)構(gòu)的幾位研究者嘗試基于文本描述生成論文中的圖表。為此,他們提出了一種 FigGen 的新方法,相關(guān)論文還被 ICLR 2023 收錄為了 Tiny Paper。

論文地址:https://arxiv.org/abs/2306.00800
也許有人會(huì)問(wèn)了,生成論文中的圖表有什么難的呢?這樣做對(duì)于科研又有哪些幫助呢?
科研圖表生成有助于以簡(jiǎn)潔易懂的方式傳播研究結(jié)果,而自動(dòng)生成圖表可以為研究者帶來(lái)很多優(yōu)勢(shì),比如節(jié)省時(shí)間和精力,不用花大力氣從頭開(kāi)始設(shè)計(jì)圖表。此外設(shè)計(jì)出具有視覺(jué)吸引力且易理解的圖表能使更多的人訪問(wèn)論文。
然而生成圖表也面臨一些挑戰(zhàn),它需要表示框、箭頭、文本等離散組件之間的復(fù)雜關(guān)系。與生成自然圖像不同,論文圖表中的概念可能有不同的表示形式,需要細(xì)粒度的理解,例如生成一個(gè)神經(jīng)網(wǎng)絡(luò)圖會(huì)涉及到高方差的不適定問(wèn)題。
因此,本文研究者在一個(gè)論文圖表對(duì)數(shù)據(jù)集上訓(xùn)練了一個(gè)生成式模型,捕獲圖表組件與論文中對(duì)應(yīng)文本之間的關(guān)系。這就需要處理不同長(zhǎng)度和高技術(shù)性文本描述、不同圖表樣式、圖像長(zhǎng)寬比以及文本渲染字體、大小和方向問(wèn)題。
在具體實(shí)現(xiàn)過(guò)程中,研究者受到了最近文本到圖像成果的啟發(fā),利用擴(kuò)散模型來(lái)生成圖表,提出了一種從文本描述生成科研圖表的潛在擴(kuò)散模型 ——FigGen。
這個(gè)擴(kuò)散模型有哪些獨(dú)到之處呢?我們接著往下看細(xì)節(jié)。
模型與方法
研究者從頭開(kāi)始訓(xùn)練了一個(gè)潛在擴(kuò)散模型。
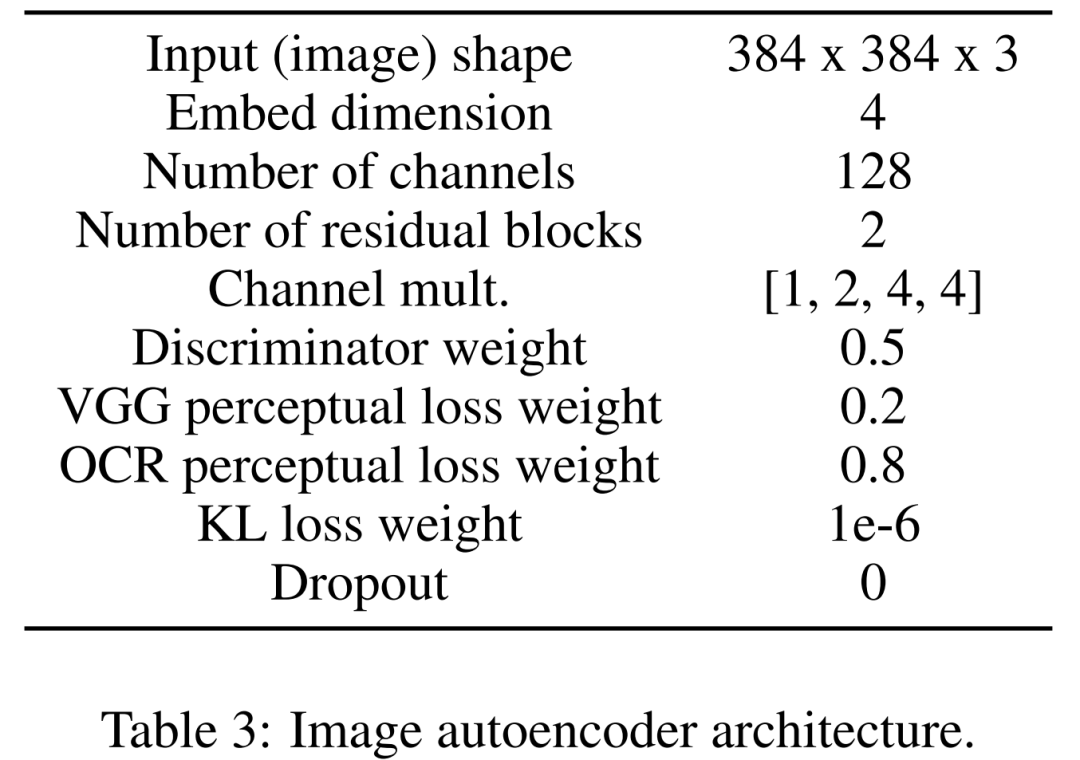
首先學(xué)習(xí)一個(gè)圖像自動(dòng)編碼器,用來(lái)將圖像映射為壓縮的潛在表示。圖像編碼器使用 KL 損失和 OCR 感知損失。調(diào)節(jié)所用的文本編碼器在該擴(kuò)散模型的訓(xùn)練中端到端進(jìn)行學(xué)習(xí)。下表 3 為圖像自動(dòng)編碼器架構(gòu)的詳細(xì)參數(shù)。
然后,該擴(kuò)散模型直接在潛在空間中進(jìn)行交互,執(zhí)行數(shù)據(jù)損壞的前向調(diào)度,同時(shí)學(xué)習(xí)利用時(shí)間和文本條件去噪 U-Net 來(lái)恢復(fù)該過(guò)程。
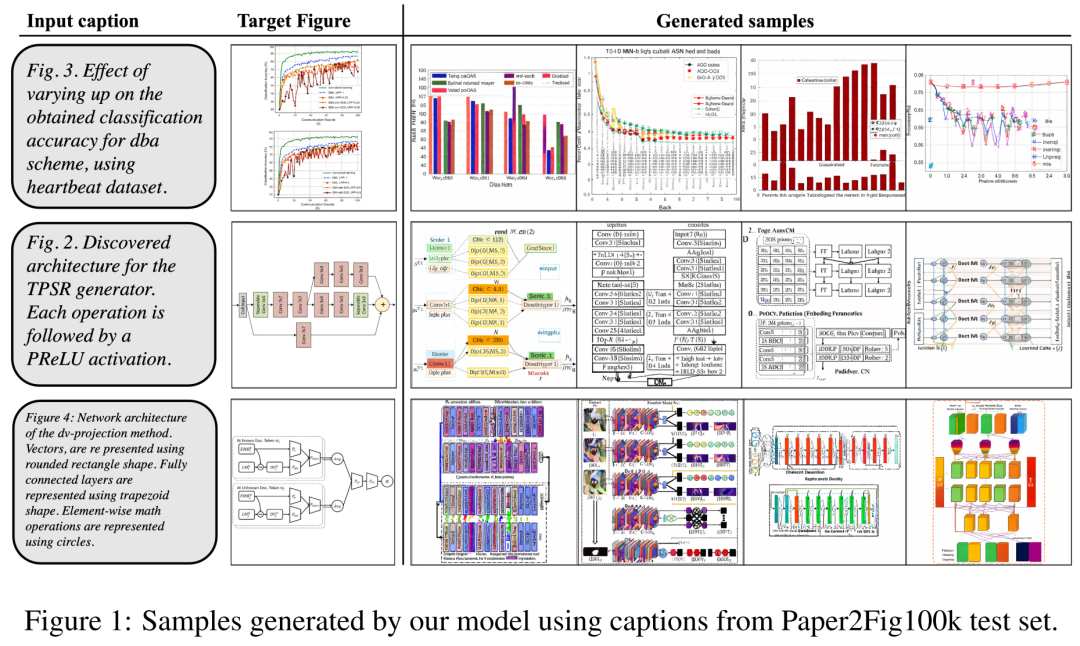
至于數(shù)據(jù)集,研究者使用了 Paper2Fig100k,它由論文中的圖表文本對(duì)組成,包含了 81,194 個(gè)訓(xùn)練樣本和 21,259 個(gè)驗(yàn)證樣本。下圖 1 為 Paper2Fig100k 測(cè)試集中使用文本描述生成的圖表示例。
模型細(xì)節(jié)
首先是圖像編碼器。第一階段,圖像自動(dòng)編碼器學(xué)習(xí)一個(gè)從像素空間到壓縮潛在表示的映射,使擴(kuò)散模型訓(xùn)練更快。圖像編碼器還需要學(xué)習(xí)將潛在圖像映射回像素空間,同時(shí)不丟失圖表重要細(xì)節(jié)(如文本渲染質(zhì)量)。
為此,研究者定義了一個(gè)具有瓶頸的卷積編解碼器,在因子 f=8 時(shí)對(duì)圖像進(jìn)行下采樣。編碼器經(jīng)過(guò)訓(xùn)練可以最小化具有高斯分布的 KL 損失、VGG 感知損失和 OCR 感知損失。
其次是文本編碼器。研究者發(fā)現(xiàn)通用文本編碼器不太適合生成圖表任務(wù)。因此他們定義了一個(gè)在擴(kuò)散過(guò)程中從頭開(kāi)始訓(xùn)練的 Bert transformer,其中使用大小為 512 的嵌入通道,這也是調(diào)節(jié) U-Net 的跨注意力層的嵌入大小。研究者還探索了不同設(shè)置下(8、32 和 128)的 transformer 層數(shù)量的變化。
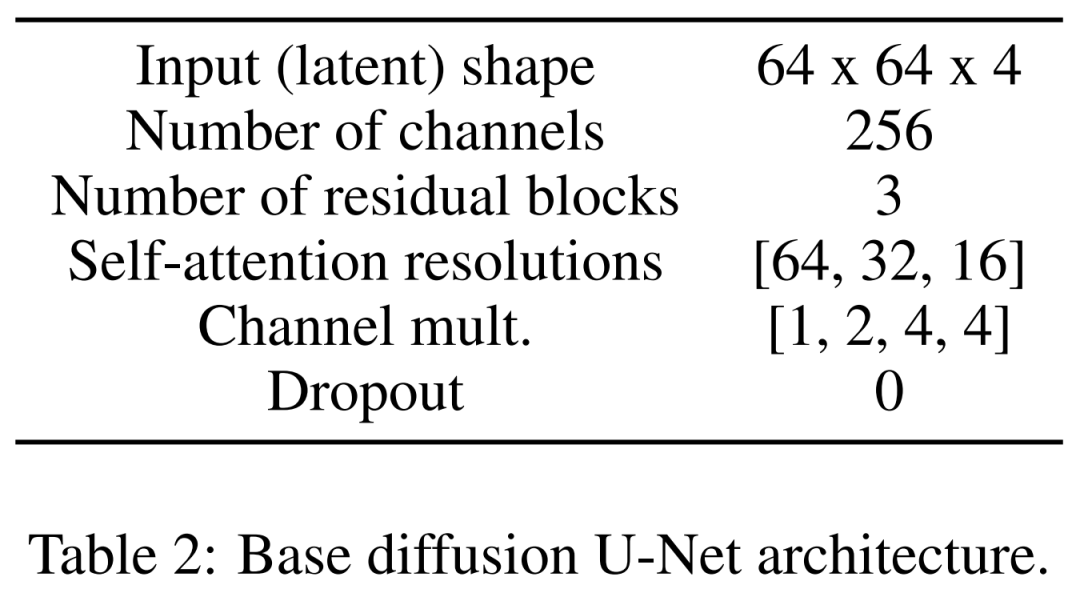
最后是潛在擴(kuò)散模型。下表 2 展示了 U-Net 的網(wǎng)絡(luò)架構(gòu)。研究者在感知上等效的圖像潛在表示中執(zhí)行擴(kuò)散過(guò)程,其中該圖像的輸入大小被壓縮到了 64x64x4,使擴(kuò)散模型更快。他們定義了 1,000 個(gè)擴(kuò)散步驟和線性噪聲調(diào)度。
訓(xùn)練細(xì)節(jié)
為了訓(xùn)練圖像自動(dòng)編碼器,研究者使用了一個(gè) Adam 優(yōu)化器,它的有效批大小為 4 個(gè)樣本、學(xué)習(xí)率為 4.5e?6,期間使用了 4 個(gè) 12GB 的英偉達(dá) V100 顯卡。為了實(shí)現(xiàn)訓(xùn)練穩(wěn)定性,他們?cè)?50k 次迭代中 warmup 模型,而不使用判別器。
對(duì)于訓(xùn)練潛在擴(kuò)散模型,研究者也使用 Adam 優(yōu)化器,它的有效批大小為 32,學(xué)習(xí)率為 1e?4。在 Paper2Fig100k 數(shù)據(jù)集上訓(xùn)練該模型時(shí),他們用到了 8 塊 80GB 的英偉達(dá) A100 顯卡。
實(shí)驗(yàn)結(jié)果
在生成過(guò)程中,研究者采用了具有 200 步的 DDIM 采樣器,并且為每個(gè)模型生成了 12,000 個(gè)樣本來(lái)計(jì)算 FID, IS, KID 以及 OCR-SIM1。穩(wěn)重使用無(wú)分類(lèi)器指導(dǎo)(CFG)來(lái)測(cè)試超調(diào)節(jié)。
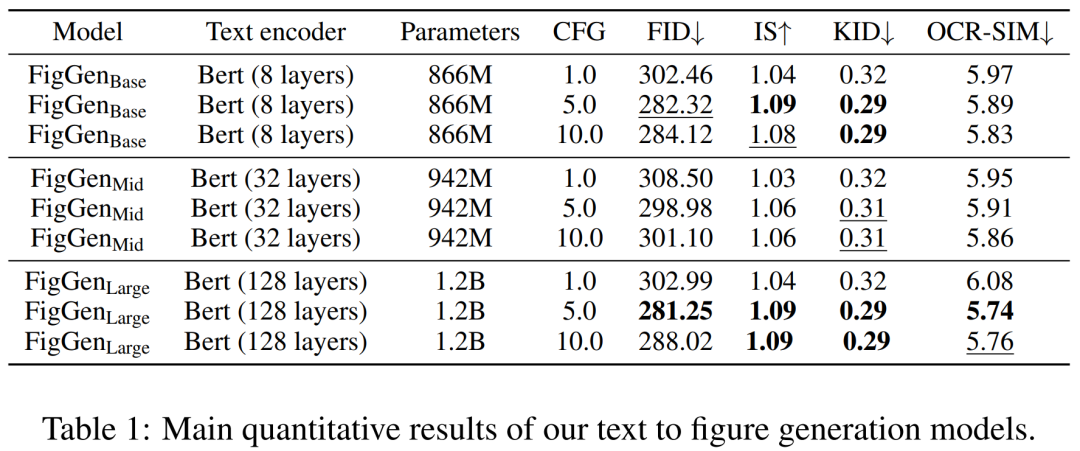
下表 1 展示了不同文本編碼器的結(jié)果。可見(jiàn),大型文本編碼器產(chǎn)生了最好的定性結(jié)果,并且可以通過(guò)增加 CFG 的規(guī)模來(lái)改進(jìn)條件生成。雖然定性樣本沒(méi)有足夠的質(zhì)量來(lái)解決問(wèn)題,但 FigGen 已經(jīng)掌握了文本和圖像之間的關(guān)系。
下圖 2 展示了調(diào)整無(wú)分類(lèi)器指導(dǎo)(CFG)參數(shù)時(shí)生成的額外 FigGen 樣本。研究者觀察到增加 CFG 的規(guī)模(這在定量上也得到了體現(xiàn))可以帶來(lái)圖像質(zhì)量的改善。
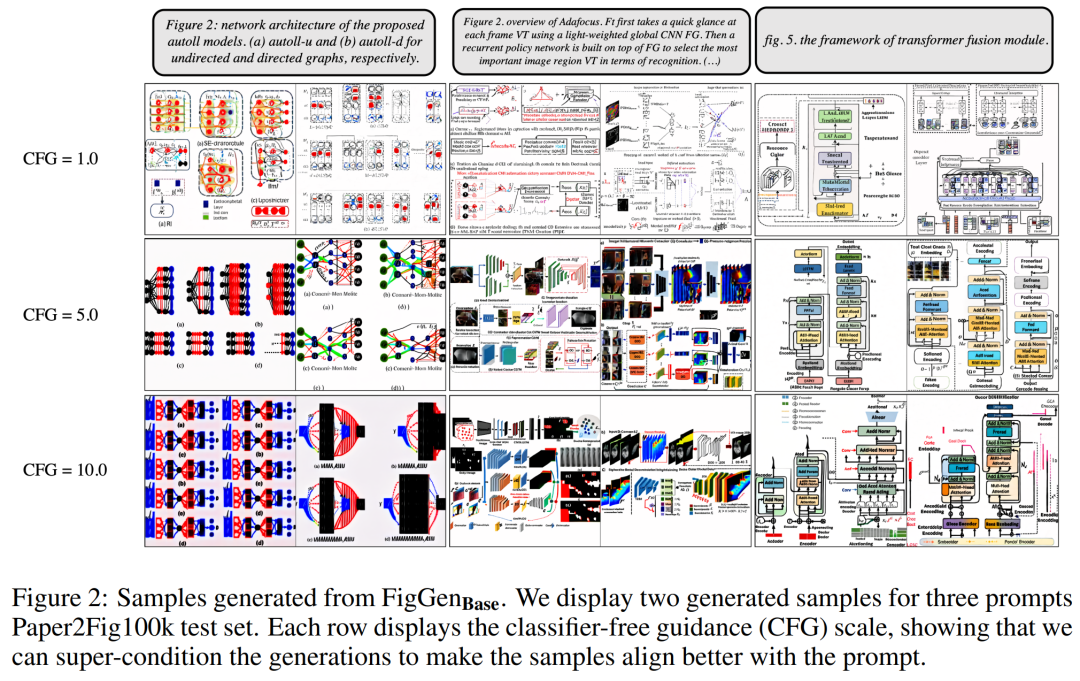
下圖 3 展示了 FigGen 的更多生成示例。要注意樣本之間長(zhǎng)度的變化,以及文本描述的技術(shù)水平,這會(huì)密切影響到模型正確生成可理解圖像的難度。

?
不過(guò)研究者也承認(rèn),盡管現(xiàn)在這些生成的圖表不能為論文作者提供實(shí)際幫助,但仍不失為一個(gè)有前景的探索方向。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4774瀏覽量
100896 -
人工智能
+關(guān)注
關(guān)注
1792文章
47425瀏覽量
238957 -
模型
+關(guān)注
關(guān)注
1文章
3267瀏覽量
48923
原文標(biāo)題:論文插圖也能自動(dòng)生成了!用到了擴(kuò)散模型,還被ICLR 2023接收!
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于擴(kuò)散模型的圖像生成過(guò)程

如何在PyTorch中使用擴(kuò)散模型生成圖像

AD8275 spice模型“AD8275.cir”自動(dòng)生成了一個(gè)LTspice模型用來(lái)仿真,仿真時(shí)彈出圖片所示窗口如何處理?
基于模型設(shè)計(jì)的HDL代碼自動(dòng)生成技術(shù)綜述
ICLR 2019在官網(wǎng)公布了最佳論文獎(jiǎng)!

近期必讀的6篇ICLR 2021相關(guān)論文
ICLR 2021杰出論文獎(jiǎng)出爐 讓我們看看前八位優(yōu)秀論文有哪些
擴(kuò)散模型在視頻領(lǐng)域表現(xiàn)如何?
蒸餾無(wú)分類(lèi)器指導(dǎo)擴(kuò)散模型的方法
頂刊TPAMI 2023!生成式AI與圖像合成綜述發(fā)布!

ICCV 2023 | 重塑人體動(dòng)作生成,融合擴(kuò)散模型與檢索策略的新范式ReMoDiffuse來(lái)了

谷歌新作UFOGen:通過(guò)擴(kuò)散GAN實(shí)現(xiàn)大規(guī)模文本到圖像生成

ICLR 2024高分投稿:用于一般時(shí)間序列分析的現(xiàn)代純卷積結(jié)構(gòu)

基于DiAD擴(kuò)散模型的多類(lèi)異常檢測(cè)工作






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論