") 基于一種可擴展的解碼器范式
基于一種可擴展的解碼器范式
1. 論文信息
代碼:https://github.com/opendrivelab/thinktwice
2. 引言
端到端自動駕駛是一種基于傳感器觀測預(yù)測動作的方法。與傳統(tǒng)的模塊化自動駕駛框架不同,端到端方法展現(xiàn)出了巨大的潛力。在這種方法中,整個駕駛系統(tǒng)從感知到控制都是端到端學(xué)習(xí)的。系統(tǒng)的輸入是原始的傳感器數(shù)據(jù),輸出是車輛的控制信號。這種方法在閉環(huán)評估中表現(xiàn)出了令人矚目的性能。
隨著深度學(xué)習(xí)的進步,自動駕駛引起了學(xué)術(shù)界和工業(yè)界的關(guān)注。端到端自動駕駛旨在構(gòu)建一個完全可微分的學(xué)習(xí)系統(tǒng),能夠直接將原始傳感器輸入映射到控制信號或未來的軌跡。由于其高效性和避免累積誤差的能力,近年來取得了令人矚目的進展。現(xiàn)有的工作都采用編碼器-解碼器范式。編碼器模塊從原始傳感器數(shù)據(jù)(相機,LiDAR,雷達等)中提取信息并生成表示特征。將該特征作為輸入,解碼器直接預(yù)測路徑點或控制信號。在這種范式下,編碼器沒有訪問自我代理的預(yù)期行為,這使得從大量傳感器輸入的感知領(lǐng)域中找到安全關(guān)鍵區(qū)域并推斷未來情況的負擔(dān)落在解碼器身上。
為了解決這些問題,該研究提出了兩個原則來設(shè)計新模型:充分利用編碼器的能力,擴展解碼器的能力并進行密集監(jiān)督。為了實現(xiàn)這兩個原則,研究人員提出了級聯(lián)解碼器范式,以粗到細的方式預(yù)測自我車輛的未來動作。具體來說,他們首先采用類似于傳統(tǒng)方法的MLP來生成粗略的未來軌跡和動作。然后從編碼器中檢索預(yù)測未來位置周圍的特征,并將其進一步輸入到多個卷積層中以獲取與目標相關(guān)的場景特征。接下來,他們設(shè)計了一個預(yù)測模塊,以當前場景的特征和粗略動作為輸入,并生成未來場景表示特征。最后,他們預(yù)測粗略預(yù)測和地面真實軌跡之間的偏移量以進行細化。該過程可以級聯(lián)堆疊,以增加解碼器對條件未來的時空先驗知識的容量。該研究在CARLA自動駕駛基準測試中進行了實驗,并取得了最先進的性能。他們還進行了廣泛的消融研究,以證明所提出方法的有效性。總之,該研究有三個貢獻:首先,提出了一種可擴展的端到端自動駕駛解碼器范式,強調(diào)擴展解碼器容量在這一領(lǐng)域的重要性。其次,他們設(shè)計了一個解碼器模塊來查找安全關(guān)鍵區(qū)域,并預(yù)測在預(yù)測的動作/軌跡條件下的未來場景,為訓(xùn)練過程注入了時空先驗知識和密集監(jiān)督。最后,他們在兩個競爭基準測試中展示了最先進的性能,并進行了廣泛的消融研究,以驗證所提出的模塊的有效性。他們相信,在端到端自動駕駛中,解碼器(決策部分)與編碼器(感知部分)同等重要。他們希望他們的探索能夠激發(fā)社區(qū)在這一領(lǐng)域的進一步努力。
3. 方法
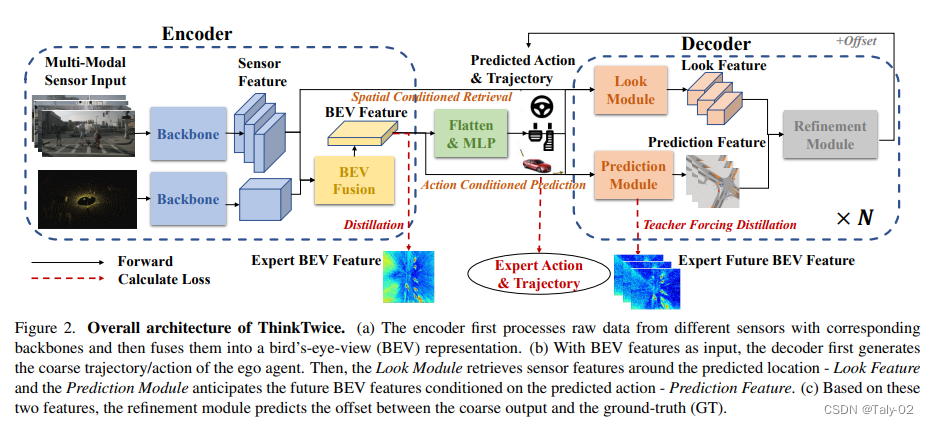
本文提出了一種可擴展的解碼器范式,稱為ThinkTwice,用于端到端自動駕駛。作者使用模仿學(xué)習(xí)框架收集駕駛?cè)罩荆@是一系列車輛狀態(tài)和傳感器數(shù)據(jù)。他們使用4個攝像頭(前置、左側(cè)、右側(cè)、后置)、一個激光雷達、IMU、GPS和車速表在城鎮(zhèn)01、城鎮(zhèn)03、城鎮(zhèn)04和城鎮(zhèn)06上以2 Hz的速度收集數(shù)據(jù)。他們總共收集了189K幀用于進行大部分實驗和消融研究。作者使用ResNet-18架構(gòu)提取圖像特征,使用PointNet++架構(gòu)提取LiDAR特征。然后,他們將圖像特征投影和對齊到BEV上的LiDAR特征。
3.1. BEV Encoder
本文考慮了在自動駕駛中常用的兩種傳感器:攝像頭和激光雷達。為了融合它們的信息,首先將原始傳感器數(shù)據(jù)分別轉(zhuǎn)換為俯視圖(BEV)特征,然后直接連接BEV特征,因為它們已經(jīng)在空間上對齊。對于來自多個視角的相機輸入 - RGB圖像,首先在每個圖像上使用圖像骨干網(wǎng)絡(luò)(例如ResNet)獲得其緊湊的特征圖。為了將2D圖像轉(zhuǎn)換為BEV空間,采用了LSS :首先預(yù)測每個像素的離散深度分布,并將每個像素沿著相機光線分散成離散點,在該點處的特征是其預(yù)測深度和相應(yīng)像素特征的乘積。對于BEV中的每個網(wǎng)格,通過截錐體池化從該網(wǎng)格內(nèi)的那些點聚合特征。通過這種方式,作者可以將任意數(shù)量的相機圖像聚合到一個C×BH×BW特征圖中,其中C是隱藏的維度,BH和BW是BEV網(wǎng)格的高度和寬度。此外,為了引入時間線索,作者通過將歷史圖像的先前BEV轉(zhuǎn)換為當前自我中心坐標系來聚合先前BEV。因此,先前和當前的特征圖被空間對齊,作者可以簡單地將它們連接起來得到最終的BEV特征。另外,作者發(fā)現(xiàn)
深度預(yù)測模塊的真實監(jiān)督對于圖像的分散非常重要,這與物體檢測領(lǐng)域的發(fā)現(xiàn)一致。
分散圖像特征時,有益于添加一個語義分割模塊并分散預(yù)測的語義分數(shù)。作者推測,它通過過濾掉不相關(guān)的紋理信息來增加了端到端模型的泛化能力。對于LiDAR輸入 - 點云,作者采用了流行的SECOND ,它在體素化的點云上應(yīng)用了稀疏的3D卷積,最終輸出也是一個C×BH×BW的BEV特征圖。
為了利用時間信息,類似于物體檢測領(lǐng)域的現(xiàn)有作品,作者將來自多幀的對齊點云簡單地串聯(lián)起來,并添加一個通道來指示時間步長。在融合兩個BEV特征圖時,作者只是將它們簡單地串聯(lián)起來,并通過一系列2D卷積層進行處理。由于行動是端到端自動駕駛中唯一的直接監(jiān)督,對于高維多傳感器輸入來說太稀疏了,因此作者為BEV特征圖提供額外的特征級監(jiān)督。具體來說,作者使用Roach [87]中間的BEV特征圖作為目標,使用基于RL的帶特權(quán)輸入的教師網(wǎng)絡(luò),將柵格化的BEV周圍環(huán)境作為特權(quán)輸入,并通過幾個卷積層實現(xiàn)了不錯的性能。請注意,任何具有BEV特征表示的可學(xué)習(xí)專家模型都可以在此處采用,作者之所以采用Roach是由于其通過RL訓(xùn)練獲得的健壯性。通過讓學(xué)生網(wǎng)絡(luò)(即ThinkTwice的編碼器)的中間BEV特征圖與教師網(wǎng)絡(luò)的類似,每個BEV網(wǎng)格都獲得了關(guān)于決策相關(guān)信息的密集監(jiān)督。在實驗部分,作者經(jīng)驗證明,這種監(jiān)督是必要的,并且比先前SOTA作品中常用的BEV分割監(jiān)督信號更好。因此,本文提出的方法將BEV特征圖與額外的監(jiān)督結(jié)合起來,以獲得更好的性能。
3.2. Decoder
Decoder模塊包括三個子模塊:Look Module、Prediction Module和Refinement Module。其中,Look Module模塊用于將人類駕駛員的先驗知識(目標位置)注入到模型中,提高模型的泛化能力;Prediction Module模塊用于預(yù)測場景的未來發(fā)展,以及提供監(jiān)督信號;Refinement Module模塊用于通過對預(yù)測結(jié)果的微調(diào)來提高預(yù)測精度。這三個子模塊分別對應(yīng)于解碼器中的三個階段:粗略預(yù)測、注入先驗知識、微調(diào)預(yù)測結(jié)果。通過將這三個子模塊結(jié)合起來,能夠獲得更準確的自動駕駛預(yù)測結(jié)果。具體來說:
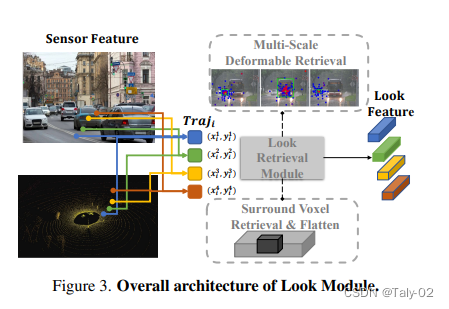
Look Module是解碼器中的第一個子模塊,其主要作用是將駕駛員的先驗知識注入到模型中。在實際駕駛中,駕駛員會查看目標位置,以確保沒有與其他車輛的碰撞和違反交通規(guī)則等風(fēng)險。為了實現(xiàn)這個目標,Look Module通過引入預(yù)測軌跡,將模型的關(guān)注點引導(dǎo)到了預(yù)測軌跡所在的區(qū)域。對于攝像頭數(shù)據(jù),Look Module使用多尺度變形注意力來聚合信息;對于激光雷達數(shù)據(jù),Look Module直接檢索目標軌跡周圍的點云,并通過MLP網(wǎng)絡(luò)來獲得特征表示。最后將兩者特征拼接起來,得到Look Feature,用于后續(xù)的預(yù)測過程。
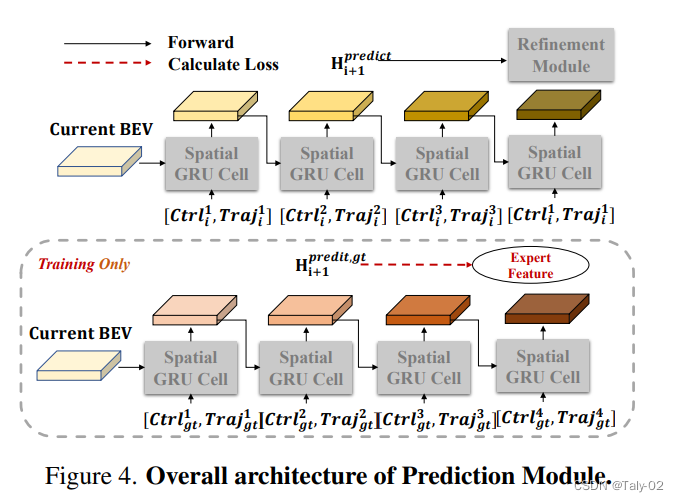
Prediction Module是解碼器中的第二個子模塊,其主要作用是預(yù)測場景的未來發(fā)展,并提供監(jiān)督信號。在實際駕駛中,駕駛員會預(yù)測周圍車輛和行人的行為,以及他們對自己的駕駛決策作出的響應(yīng)。為了實現(xiàn)這個目標,Prediction Module使用空間GRU(Spatial-GRU)對當前的BEV特征進行建模,以及獲得當前時刻的預(yù)測動作和軌跡。同時,Prediction Module通過引入Ground-Truth數(shù)據(jù),將監(jiān)督信號注入到模型中。具體而言,Prediction Module使用“Teacher Forcing”技術(shù),將Ground-Truth的動作和軌跡作為額外的輸入提供給模型,以便在訓(xùn)練過程中獲得準確的監(jiān)督信號。
Refinement Module是解碼器中的第三個子模塊,其主要作用是通過微調(diào)預(yù)測結(jié)果來提高預(yù)測精度。在實際駕駛中,駕駛員會根據(jù)周圍的車輛和行人的行為作出相應(yīng)的駕駛決策,并在行駛過程中不斷微調(diào)自己的決策,以適應(yīng)復(fù)雜的交通環(huán)境。為了實現(xiàn)這個目標,Refinement Module引入了Look Feature和Prediction Feature,以及當前時刻的預(yù)測動作和軌跡,通過MLP網(wǎng)絡(luò)對預(yù)測結(jié)果進行微調(diào),得到更加精確的預(yù)測結(jié)果。同時,Refinement Module使用Ground-Truth數(shù)據(jù)對預(yù)測結(jié)果進行監(jiān)督,以便在訓(xùn)練過程中獲得準確的監(jiān)督信號。最終,通過不斷的微調(diào),預(yù)測結(jié)果的準確度得到了提高。
因此,這三個子模塊共同構(gòu)成了解碼器模塊,通過引入駕駛員的先驗知識、預(yù)測場景的未來發(fā)展,并通過微調(diào)預(yù)測結(jié)果來提高預(yù)測精度,實現(xiàn)了更加準確的自動駕駛預(yù)測。
4. 實驗
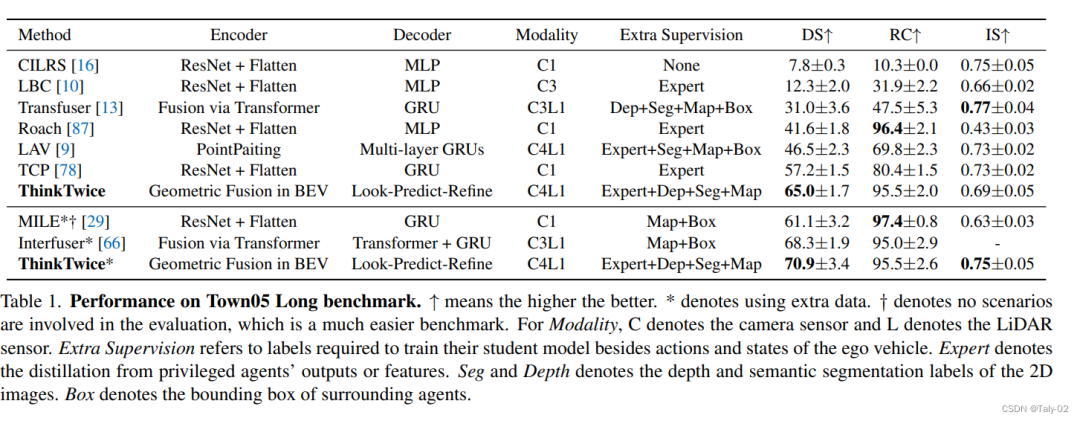
該論文的作者使用了一個名為ThinkTwice的模仿學(xué)習(xí)框架來收集駕駛記錄,這是車輛狀態(tài)和傳感器數(shù)據(jù)的序列。他們使用了4個相機(前、左、右、后)、一個激光雷達、IMU、GPS和速度計,在town01、town03、town04和town06上以2 Hz的速度收集數(shù)據(jù)。他們總共收集了189K幀以進行大多數(shù)實驗和消融研究。如表格所示,不同模型在Town05 Long基準測試中的表現(xiàn)。該表格包括各種列,如Modality、Extra Supervision、Expert、Seg and Depth和Box。Modality列表示使用的傳感器類型,其中C表示相機傳感器,L表示激光雷達傳感器。Extra Supervision列指訓(xùn)練學(xué)生模型所需的額外標簽,除了自我車輛的行動和狀態(tài)。Expert列表示來自特權(quán)代理輸出或特征的蒸餾。Seg和Depth列表示2D圖像的深度和語義分割標簽。Box列表示周圍代理的邊界框。結(jié)果表明,顯式使用深度和分割預(yù)測來自圖像特征到BEV特征的投影過程(Model3)和使用兩幀作為輸入而不是一幀(Model4)的模型表現(xiàn)出了比其他模型更好的性能。然而,盡管引入了運動線索,Model4的改進只是微小的。總的來說,該表格提供了不同模型在Town05 Long基準測試中的表現(xiàn)比較,各個列指示了使用的傳感器類型、訓(xùn)練所需的額外標簽以及其他影響模型表現(xiàn)的因素。
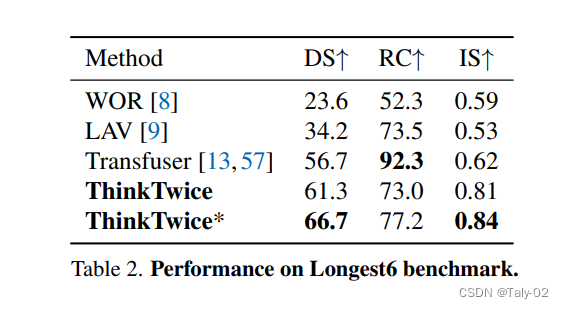
本文在兩個閉環(huán)評估基準測試中與現(xiàn)有的最先進方法進行了比較。在Town5Long基準測試中,ThinkTwice在兩個協(xié)議下均取得了最佳的DS得分,而Roach和MILE可以運行較長時間(最高RC),但發(fā)生的碰撞或違反交通規(guī)則更多。另一方面,Transfuser的運行最安全(最高IS),但過于謹慎而無法完成路線。至于Longest6基準測試,Transfuser可以獲得非常高的路線完成得分,但我們的方法獲得了最佳的DS和IS得分,這表明我們的方法駕駛過程更加安全。
在編碼器方面,作者通過實驗發(fā)現(xiàn),單純采用幾何融合技術(shù)而沒有相關(guān)監(jiān)督會導(dǎo)致性能下降;加入深度和語義分割任務(wù)的模型略有提升,這可能是這兩個輔助任務(wù)對圖像特征的正則化效果;顯式地在投影過程中使用深度和分割預(yù)測可以顯著提高性能,這表明監(jiān)督幾何投影的重要性;使用兩幀作為輸入而不是一幀的模型性能提升不大,這可能與慣性/模仿問題相關(guān);在解碼器方面,作者通過組件分析發(fā)現(xiàn),加入一個額外的解碼器層可以提高性能,而使用5個提出的解碼器層可以顯著提高性能,并證明了提出的解碼器范式的有效性和其強大的可擴展性。最終,作者采用Model6作為ThinkTwice的最終模型,并通過消融實驗驗證了其解碼器設(shè)計的有效性,特別是通過密集監(jiān)督的堆疊解碼器層可以得到SOTA的性能。總的來說,本文的實驗結(jié)果證實了作者提出的思路和方法,在編碼器和解碼器中注入先驗知識是非常重要的。
5. 討論
image-20230527130912709
在這篇論文中,作者提出了幾項未來的工作,包括研究所提出的方法在其他自動駕駛?cè)蝿?wù)中的有效性,探索使用無監(jiān)督或半監(jiān)督學(xué)習(xí)減少所需訓(xùn)練數(shù)據(jù)量的可能性,并分析所提出方法的計算復(fù)雜度。他們還建議研究將其他傳感器模式(如雷達和音頻傳感器)納入到所提出方法中,以提高其性能的可能性。
本文旨在探討增加端到端自動駕駛模型容量的不同方法,并在公平的環(huán)境中進行比較。作者嘗試了多種方法,包括增加編碼器的大小以及MLP/GRU解碼器的寬度和深度等。結(jié)果顯示,簡單地增加編碼器或解碼器的深度/寬度不會帶來性能提升。相反,ThinkTwice以密集的監(jiān)督和時空知識以粗到細的方式增加解碼器的容量,注入了強大的先驗知識,并因此帶來了更好的性能。
本文也討論了在部署自動駕駛模型時需要考慮計算需求和內(nèi)存占用的重要性,因為這些模型通常在計算能力和內(nèi)存有限的邊緣設(shè)備上運行。作者運行了一些現(xiàn)有模型的官方代碼來估計它們的計算需求和內(nèi)存占用,并列出了結(jié)果。其中,ThinkTwice模型由于采用了BEV中的幾何融合技術(shù),需要大量的MAC和GPU內(nèi)存,但也因此在聯(lián)合感知規(guī)劃和傳感器融合方面具有優(yōu)勢。作者指出,學(xué)習(xí)BEV表示是當前工業(yè)和學(xué)術(shù)界的熱點問題,為了降低BEV模型的計算負擔(dān),一些更高效的實現(xiàn)方法已經(jīng)被提出。同時,工業(yè)界也在積極探索專門設(shè)計的邊緣設(shè)備和芯片。
6. 結(jié)論
本文提出了一種可擴展的解碼器范式,稱為ThinkTwice,用于端到端自動駕駛。該范式強調(diào)通過提出具有密集監(jiān)督和空間-時間先驗的可擴展解碼器層來擴大解碼器的容量。作者在兩個競爭性的閉環(huán)自動駕駛基準測試上實現(xiàn)了最先進的性能。本研究為社區(qū)中的這一研究領(lǐng)域提供了有用的信息。
責(zé)任編輯:彭菁
-
傳感器
+關(guān)注
關(guān)注
2552文章
51382瀏覽量
755776 -
解碼器
+關(guān)注
關(guān)注
9文章
1147瀏覽量
40870 -
自動駕駛
+關(guān)注
關(guān)注
784文章
13923瀏覽量
166818
原文標題:thinktwice:用于端到端自動駕駛的可擴展解碼器(已開源)
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
怎樣去設(shè)計一種基于VS1053B-L解碼器的MP3播放器
一種基于分組的低功耗變長解碼器的設(shè)計
有效的golomb解碼器設(shè)計

一種基于WM8741的音頻解碼器研究與設(shè)計
二進制解碼器到底是什么

光柵解碼器損壞的表現(xiàn)有哪些
全景聲解碼器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論