 地平線旭日X3派試用體驗 | 運行輕量級人臉檢測模型
地平線旭日X3派試用體驗 | 運行輕量級人臉檢測模型
一、下載代碼
Linzaer的代碼倉中,提供了PyTorch和ONNX格式的預訓練模型,同時還提供了常用框架的Python和C++推理代碼實現,以及測試圖片、腳本和說明文檔,直接使用即可:
# 當然,首先需要聯網 # 如果沒有git先安裝一下: # sudo apt install git # 下載大佬的代碼倉: git clone https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB.git
下載完成后,可以通過 ls -al 命令查頂層看有哪些文件和目錄(當然,GitHub網頁上也能看):
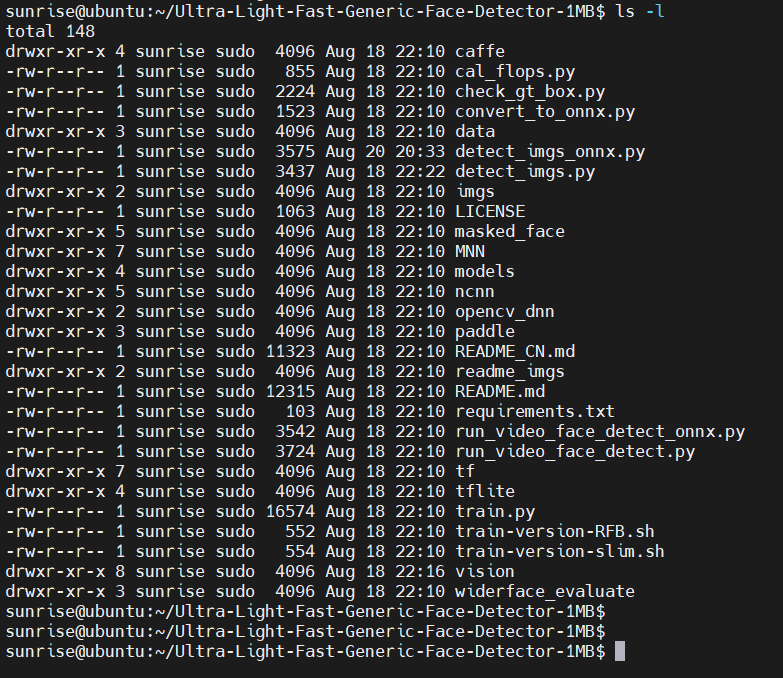
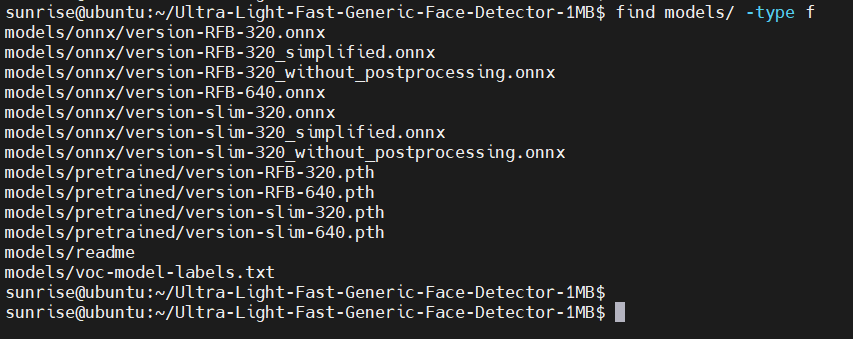
預訓練的模型位于 models 子目錄,使用 find models/ -type f 命令,可以查看有哪些文件:
二、安裝依賴
地平線發布的旭日X3派系統鏡像已經自帶了python3和pip3命令,不用再安裝了。樹莓派上,如果沒有python3和pip3命令,需要先安裝:
sudo apt install python3 python3-pip
2.1 更新pip源
由于pip install 默認會從pypi.org(國外主機)下載軟件包,國內網絡環境一般下載速度較慢。因此,建議修改pip源配置:
pip3 config set global.index-url http://mirrors.aliyun.com/pypi/simple/ pip3 config set global.trusted-host mirrors.aliyun.com pip3 config set global.timeout 120
2.2 按裝pip包
大佬的代碼倉中提供了requirements.txt,里面記錄執行倉中python代碼所需的Python軟件包。使用pip命令安裝即可:
pip3 install -r requirements.txt
稍等一段時間,下載完成,如下圖:
可以看到下載鏈接已經變成 aliyun 的了。
三、運行模型
代碼倉頂層的 detect_imgs.py 和 detect_imgs_onnx.py 兩個腳本文件,可以直接使用 models 下的預訓練模型進行推理。
其中,detect_imgs.py 腳本的內容如下:
""" This code is used to batch detect images in a folder. """ import argparse import os import sys import cv2 from vision.ssd.config.fd_config import define_img_size parser = argparse.ArgumentParser( description='detect_imgs') parser.add_argument('--net_type', default="RFB", type=str, help='The network architecture ,optional: RFB (higher precision) or slim (faster)') parser.add_argument('--input_size', default=640, type=int, help='define network input size,default optional value 128/160/320/480/640/1280') parser.add_argument('--threshold', default=0.6, type=float, help='score threshold') parser.add_argument('--candidate_size', default=1500, type=int, help='nms candidate size') parser.add_argument('--path', default="imgs", type=str, help='imgs dir') parser.add_argument('--test_device', default="cuda:0", type=str, help='cuda:0 or cpu') args = parser.parse_args() define_img_size(args.input_size) # must put define_img_size() before 'import create_mb_tiny_fd, create_mb_tiny_fd_predictor' from vision.ssd.mb_tiny_fd import create_mb_tiny_fd, create_mb_tiny_fd_predictor from vision.ssd.mb_tiny_RFB_fd import create_Mb_Tiny_RFB_fd, create_Mb_Tiny_RFB_fd_predictor result_path = "./detect_imgs_results" label_path = "./models/voc-model-labels.txt" test_device = args.test_device class_names = [name.strip() for name in open(label_path).readlines()] if args.net_type == 'slim': model_path = "models/pretrained/version-slim-320.pth" # model_path = "models/pretrained/version-slim-640.pth" net = create_mb_tiny_fd(len(class_names), is_test=True, device=test_device) predictor = create_mb_tiny_fd_predictor(net, candidate_size=args.candidate_size, device=test_device) elif args.net_type == 'RFB': model_path = "models/pretrained/version-RFB-320.pth" # model_path = "models/pretrained/version-RFB-640.pth" net = create_Mb_Tiny_RFB_fd(len(class_names), is_test=True, device=test_device) predictor = create_Mb_Tiny_RFB_fd_predictor(net, candidate_size=args.candidate_size, device=test_device) else: print("The net type is wrong!") sys.exit(1) net.load(model_path) if not os.path.exists(result_path): os.makedirs(result_path) listdir = os.listdir(args.path) sum = 0 for file_path in listdir: img_path = os.path.join(args.path, file_path) orig_image = cv2.imread(img_path) image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB) boxes, labels, probs = predictor.predict(image, args.candidate_size / 2, args.threshold) sum += boxes.size(0) for i in range(boxes.size(0)): box = boxes[i, :] cv2.rectangle(orig_image, (box[0], box[1]), (box[2], box[3]), (0, 0, 255), 2) # label = f"""{voc_dataset.class_names[labels[i]]}: {probs[i]:.2f}""" label = f"{probs[i]:.2f}" # cv2.putText(orig_image, label, (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) cv2.putText(orig_image, str(boxes.size(0)), (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) cv2.imwrite(os.path.join(result_path, file_path), orig_image) print(f"Found {len(probs)} faces. The output image is {result_path}") print(sum)
可以看到,該腳本中:
- 使用 --path 選項執行輸入圖片所在目錄,默認為 imgs;
- 將后處理后的輸出圖片保存到detect_imgs_results目錄;
- 默認使用models/pretrained/version-RFB-320.pth 模型。
3.1 跑torch模型
好了,準備直接跑 detect_imgs.py :
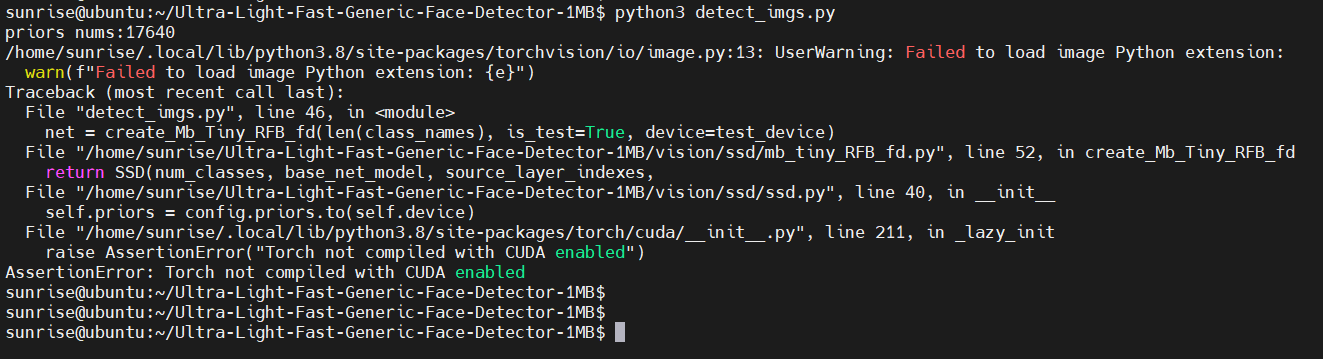
失敗了,說PyTorch不是使能CUDA編譯的。
從代碼中,我們看到可以通過 test_device 選項指定設備,默認是 cuda:0 。
我們手動指定 test_device 為 CPU,繼續嘗試運行:
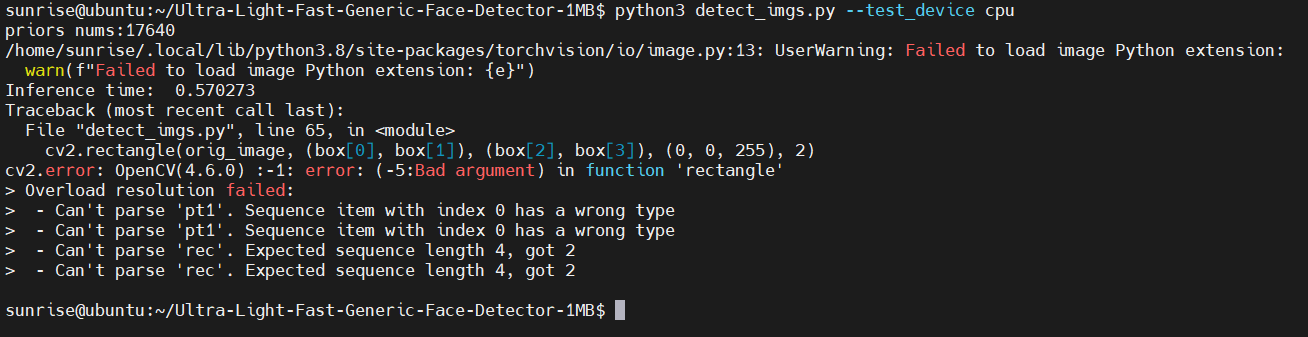
又失敗了,這次是OpenCV報錯,說是 cv2.rectangle 的參數類型不對。
將box坐標轉為int,具體修改:
diff --git a/detect_imgs.py b/detect_imgs.py index 570f6a4..73b7d38 100644 --- a/detect_imgs.py +++ b/detect_imgs.py @@ -62,7 +62,9 @@ for file_path in listdir: sum += boxes.size(0) for i in range(boxes.size(0)): box = boxes[i, :] - cv2.rectangle(orig_image, (box[0], box[1]), (box[2], box[3]), (0, 0, 255), 2) + x1, y1 = int(box[0]), int(box[1]) + x2, y2 = int(box[2]), int(box[3]) + cv2.rectangle(orig_image, (x1, y1), (x2, y2), (0, 0, 255), 2) # label = f"""{voc_dataset.class_names[labels[i]]}: {probs[i]:.2f}""" label = f"{probs[i]:.2f}" # cv2.putText(orig_image, label, (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
再次執行:
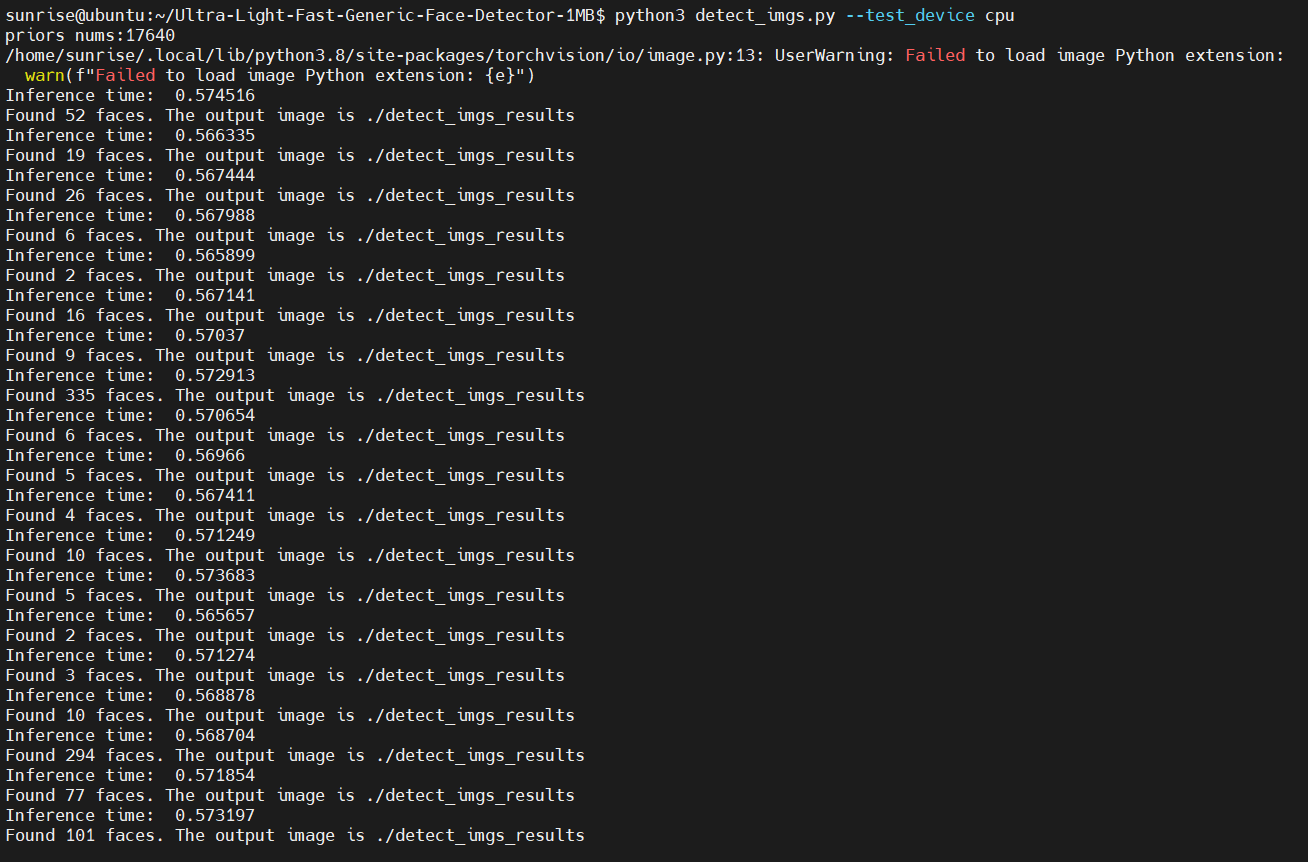
已經可以正常識別到人臉了。
3.2 跑onnx模型
類似的,嘗試運行 detect_imgs_onnx.py 腳本,使用onnx模型進行推理:
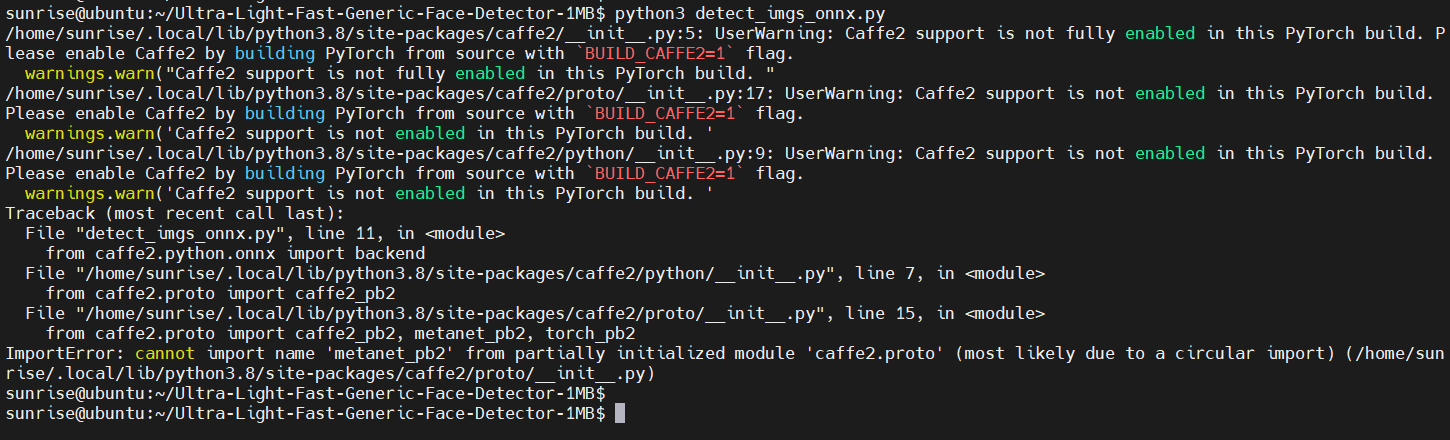
這里也報錯了。
這個報錯,我們不需要去解決它,只需要將腳本中多余的代碼刪除即可,修改內容為:
diff --git a/detect_imgs_onnx.py b/detect_imgs_onnx.py index 2594085..9644449 100644 --- a/detect_imgs_onnx.py +++ b/detect_imgs_onnx.py @@ -8,7 +8,6 @@ import cv2 import numpy as np import onnx import vision.utils.box_utils_numpy as box_utils -from caffe2.python.onnx import backend # onnx runtime import onnxruntime as ort @@ -48,11 +47,6 @@ label_path = "models/voc-model-labels.txt" onnx_path = "models/onnx/version-RFB-320.onnx" class_names = [name.strip() for name in open(label_path).readlines()] -predictor = onnx.load(onnx_path) -onnx.checker.check_model(predictor) -onnx.helper.printable_graph(predictor.graph) -predictor = backend.prepare(predictor, device="CPU") # default CPU - ort_session = ort.InferenceSession(onnx_path) input_name = ort_session.get_inputs()[0].name result_path = "./detect_imgs_results_onnx"
四、查看結果
由于WiFi天線的問題,連接ssh,速度反應很慢,scp拷貝文件也非常慢,一度卡住。
所以這里使用nginx Web服務器,通過HTTP協議和PC的瀏覽器查看推理輸出的結果圖片。首先安裝 nginx ,使用如下命令:
sudo apt install nginx
安裝成功后,可以通過ps命令查看nginx進程是否正常啟動:

可以看到 nginx 進程正常啟動了。
查看IP地址:
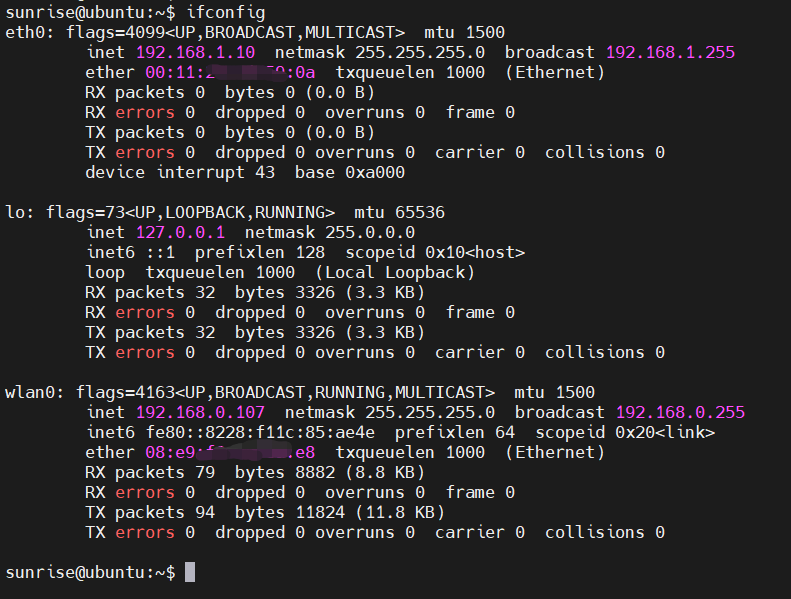
將推理輸出的結果圖片拷貝到/var/www/html目錄:

我的PC此時和開發板連在同一個熱點上,因此,可以通過瀏覽器輸入http://192.168.0.107/9.jpg
onnx模型推理的輸出結果圖片,也可以通過同樣方法查看。
五、結果對比
本節對旭日X3派和樹莓派3B+上運行“輕量級人臉檢測模型”的結果進行對比。
為了方便對比,上述兩個腳本需要重新修改,最終修改為:
diff --git a/detect_imgs.py b/detect_imgs.py index 570f6a4..0886677 100644 --- a/detect_imgs.py +++ b/detect_imgs.py @@ -54,7 +54,7 @@ if not os.path.exists(result_path): os.makedirs(result_path) listdir = os.listdir(args.path) sum = 0 -for file_path in listdir: +for file_path in sorted(listdir): img_path = os.path.join(args.path, file_path) orig_image = cv2.imread(img_path) image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB) @@ -62,11 +62,13 @@ for file_path in listdir: sum += boxes.size(0) for i in range(boxes.size(0)): box = boxes[i, :] - cv2.rectangle(orig_image, (box[0], box[1]), (box[2], box[3]), (0, 0, 255), 2) + x1, y1 = int(box[0]), int(box[1]) + x2, y2 = int(box[2]), int(box[3]) + cv2.rectangle(orig_image, (x1, y1), (x2, y2), (0, 0, 255), 2) # label = f"""{voc_dataset.class_names[labels[i]]}: {probs[i]:.2f}""" label = f"{probs[i]:.2f}" # cv2.putText(orig_image, label, (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) cv2.putText(orig_image, str(boxes.size(0)), (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) cv2.imwrite(os.path.join(result_path, file_path), orig_image) - print(f"Found {len(probs)} faces. The output image is {result_path}") + print(f"Found {len(probs)} faces. The output image is {result_path}/{file_path}") print(sum) diff --git a/detect_imgs_onnx.py b/detect_imgs_onnx.py index 2594085..19ae9fb 100644 --- a/detect_imgs_onnx.py +++ b/detect_imgs_onnx.py @@ -8,7 +8,6 @@ import cv2 import numpy as np import onnx import vision.utils.box_utils_numpy as box_utils -from caffe2.python.onnx import backend # onnx runtime import onnxruntime as ort @@ -48,11 +47,6 @@ label_path = "models/voc-model-labels.txt" onnx_path = "models/onnx/version-RFB-320.onnx" class_names = [name.strip() for name in open(label_path).readlines()] -predictor = onnx.load(onnx_path) -onnx.checker.check_model(predictor) -onnx.helper.printable_graph(predictor.graph) -predictor = backend.prepare(predictor, device="CPU") # default CPU - ort_session = ort.InferenceSession(onnx_path) input_name = ort_session.get_inputs()[0].name result_path = "./detect_imgs_results_onnx" @@ -64,7 +58,7 @@ if not os.path.exists(result_path): os.makedirs(result_path) listdir = os.listdir(path) sum = 0 -for file_path in listdir: +for file_path in sorted(listdir): img_path = os.path.join(path, file_path) orig_image = cv2.imread(img_path) image = cv2.cvtColor(orig_image, cv2.COLOR_BGR2RGB) @@ -76,10 +70,11 @@ for file_path in listdir: image = np.expand_dims(image, axis=0) image = image.astype(np.float32) # confidences, boxes = predictor.run(image) - time_time = time.time() + start_time = time.time() confidences, boxes = ort_session.run(None, {input_name: image}) - print("cost time:{}".format(time.time() - time_time)) + stop_time = time.time() boxes, labels, probs = predict(orig_image.shape[1], orig_image.shape[0], confidences, boxes, threshold) + print(f"{file_path}, faces: {boxes.shape[0]}, time: {stop_time - start_time:.9f}") for i in range(boxes.shape[0]): box = boxes[i, :] label = f"{class_names[labels[i]]}: {probs[i]:.2f}"
添加了文件名排序、文件名輸出、推理時間輸出,方便在兩個平臺上運行是進行對比。
使用如下命令,進行 torch模型數據統計:
# 記錄運行輸出 python3 detect_imgs.py --test_device cpu | tee torch.txt # 提取人臉數 grep faces torch.txt | cut -d' ' -f2 # 提取消耗時間 grep time: torch.txt | awk '{print $3}'
經上述命令統計,torch模型在旭日X3派和樹莓派3B+的運行結果如下:

可以看到,旭日X3派上torch模型平均耗時要比樹莓派短58%,而這僅僅只是CPU計算性能差異。
類似的,兩個開發板運行onnx模型的結果如下:
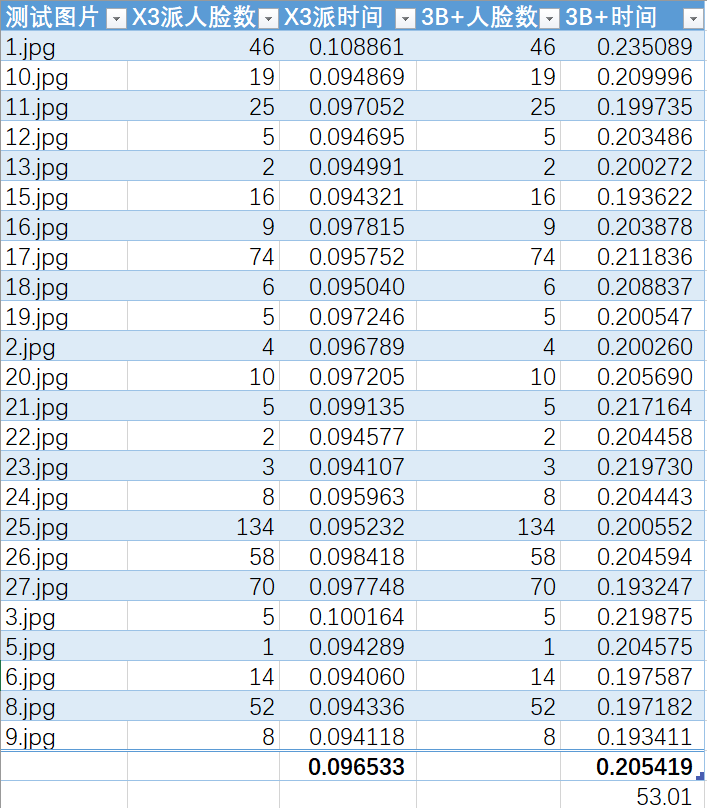
可以看到,旭日X3派上onnx模型平均耗時要比樹莓派短53%,而這僅僅只是CPU計算性能差異。
原作者:xusiwei1236
原鏈接:詳見地平線開發者社區
-
嵌入式
+關注
關注
5092文章
19176瀏覽量
307570 -
人工智能
+關注
關注
1796文章
47643瀏覽量
240204
發布評論請先 登錄
相關推薦
知行科技與地平線達成戰略合作
地平線SuperDrive相關問答
地平線SuperDrive首發三大黑科技,決勝智能化競爭下半場







 工商網監
工商網監
評論