 微服務之間涉及到的數據依賴問題應該怎么處理呢?
微服務之間涉及到的數據依賴問題應該怎么處理呢?
曾經設計的一個供應鏈系統中,存在商品 、銷售訂單 、采購 這三個服務,它們的主數據的部分結構如下所示:
商品 :
| ID | 名稱 | 分類 | 型號 | 生產年份 | 編碼 |
|---|---|---|---|---|---|
訂單和子訂單 :
| 訂單ID | 下單時間 | 客戶 | 總金額 | 子訂單ID | 商品ID | 單價 | 數量 |
|---|---|---|---|---|---|---|---|
采購單和子訂單 :
| 采購單ID | 下單時間 | 供應商 | 總金額 | 采購子訂單ID | 商品ID | 單價 | 數量 |
|---|---|---|---|---|---|---|---|
在設計這個供應鏈系統時,我們需要滿足以下兩個需求:
根據商品的型號/分類/生成年份/編碼 等查找訂單;
根據商品的型號/分類/生成年份/編碼 等查找采購訂單。
初期我們的方案是這樣設計的:嚴格按照的微服務劃分原則將商品相關的職責存放在商品系統中。因此,在查詢訂單與采購單時,如果查詢字段包含商品字段,我們需要按照如下順序進行查詢:
先根據商品字段調用商品的服務,然后返回匹配的商品信息;
在訂單或采購單中,通過 IN 語句匹配商品 ID,再關聯查詢對應的單據。
為了方便理解這個過程,訂單查詢流程圖如下圖所示:

初期方案設計完后,很快我們就遇到了一系列問題:
隨著商品數量的增多,匹配的商品越來越多,于是訂單服務中包含 IN 語句的查詢效率越來越慢
商品作為一個核心服務,依賴它的服務越來越多,同時隨著商品數據量的增長,商品服務已不堪重負,響應速度也變慢,還存在請求超時 的情況
由于商品服務超時,相關服務處理請求經常失敗。
結果就是業務方每次查詢訂單或采購單時,只要帶上了商品這個關鍵字,查詢效率就會很慢而且老是失敗。于是,我們重新想了一個新方案——數據冗余 ,下面我們一起來看下。
1、數據冗余的方案
數據冗余說白了就是在訂單、采購單中保存一些商品字段 信息。
為了方便理解,我們借助上面實際業務場景具體說明下,看看兩者的區別。
商品 :
| ID | 名稱 | 分類ID | 型號 | 生產年份ID | 編碼 |
|---|---|---|---|---|---|
訂單和子訂單 :
| 訂單ID | 下單時間 | 客戶 | 總金額 | ||||
|---|---|---|---|---|---|---|---|
| 子訂單ID | 商品ID | 單價 | 數量 | 商品名稱 | 商品分類ID | 商品型號 | 生產批次ID |
采購單和子訂單 :
| 采購單ID | 下單時間 | 供應商 | 總金額 | ||||
|---|---|---|---|---|---|---|---|
| 采購子訂單ID | 商品ID | 單價 | 數量 | 商品名稱 | 商品分類ID | 商品型號 | 生產批次ID |
調整架構方案后,每次查詢時,我們就可以不再依賴商品服務了 。
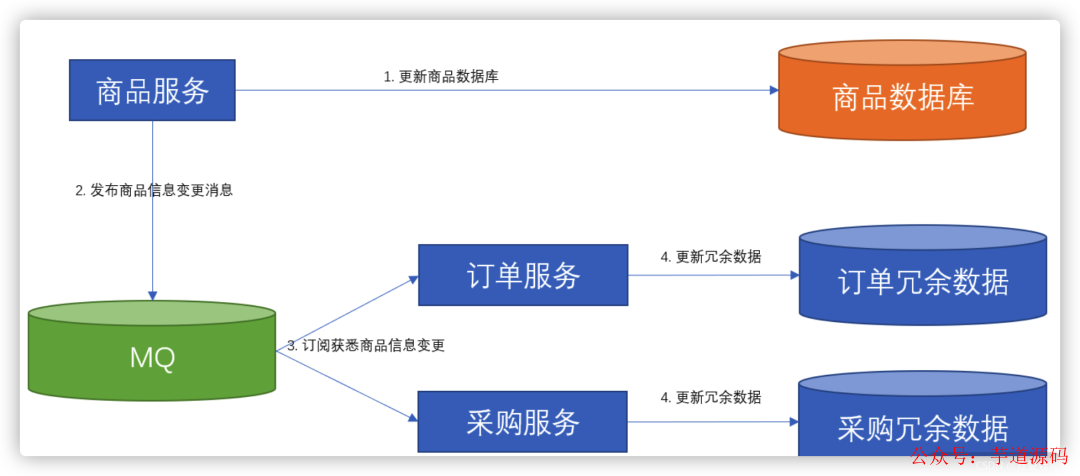
但是,如果商品進行了更新,我們如何同步冗余的數據呢?在此分享2種 解決辦法。
每次更新商品時,先調用訂單與采購服務,再更新商品的冗余數據。
每次更新商品時,先發布一條消息,訂單與采購服務各自訂閱這條消息后,再各自更新商品冗余數據。
那么這2種方案會出現哪些問題呢?
如果商品服務每次更新商品都要調用訂單與采購服務,然后再更新冗余數據,則會出現以下兩種問題。
數據一致性問題 :如果訂單與采購的冗余數據更新失敗了,整個操作都需要回滾。這時商品服務的開發人員肯定不樂意,因為冗余數據不是商品服務的核心需求,不能因為邊緣流程阻斷了自身的核心流程。
依賴問題 :從職責來說,商品服務應該只關注商品本身,但是現在商品還需要調用訂單與采購服務。而且,依賴商品這個核心服務的服務實在是太多了,也就導致后續商品服務每次更新商品時,都需要調用更新訂單冗余數據、更新采購冗余數據、更新門店庫存冗余數據、更新運營冗余數據等一大堆服務。那么商品到底是下游服務還是上游服務?還能不能安心當底層核心服務?
因此,第一個解決辦法直接被我們否決了,即我們采取的第二個解決辦法——通過消息發布訂閱的方案 ,因為它存在如下 2 點 優勢:
商品無須調用其他服務,它只需要關注自身邏輯即可,頂多多生成一條消息送到 MQ 。
如果訂單、采購等服務的更新冗余數據失敗了,我們使用消息重試機制 就可以了,最終能保證數據的一致性。
此時,我們的架構方案如下圖所示:
這個方案看起來已經挺完美了,而且市面上基本也是這么做的,不過該方案存在如下幾個問題。
1、在這個方案中,僅僅保存冗余數據還遠遠不夠,我們還需要將商品分類與生產批號的清單進行關聯查詢。也就是說,每個服務不只是訂閱商品變更這一種消息,還需要訂閱商品分類、商品生產批號變更等消息。下面請注意查看訂單表結構的紅色加粗部分內容。
| 訂單ID | 下單時間 | 客戶 | 總金額 | ||||
|---|---|---|---|---|---|---|---|
| 子訂單ID | 商品ID | 單價 | 數量 | 商品名稱 | 商品分類ID | 商品型號 | 生產批次ID |
以上只是列舉了一部分的結構,事實上,商品表中還有很多字段存在冗余,比如保修類型、包換類型等。為了更新這些冗余數據,采購服務與訂單服務往往需要訂閱近十種消息,因此,我們基本上需要把商品的一小半邏輯復制過來。
2、每個依賴的服務需要重復實現冗余數據更新同步的邏輯。前面我們講了采購、訂單及其他服務都需要依賴商品數據,因此每個服務需要將冗余數據的訂閱、更新邏輯做一遍,最終重復的代碼就會很多。
3、MQ 消息類型太多了:聯調時最麻煩的是 MQ 之間的聯動,如果是接口聯調還好說,因為調用哪個服務器的接口相對可控而且比較好追溯;如果是消息聯調就比較麻煩,因為我們常常不知道某條消息被哪臺服務節點消費了,為了讓特定的服務器消費特定的消息,我們就需要臨時改動雙方的代碼。不過聯調完成后,我們經常忘了改回原代碼。
為此,我們不希望針對冗余數據這種非核心需求出現如此多的問題,最終決定使用一個特別的同步冗余數據方案,接下來我們進一步說明。
2、解耦業務邏輯的數據同步方案
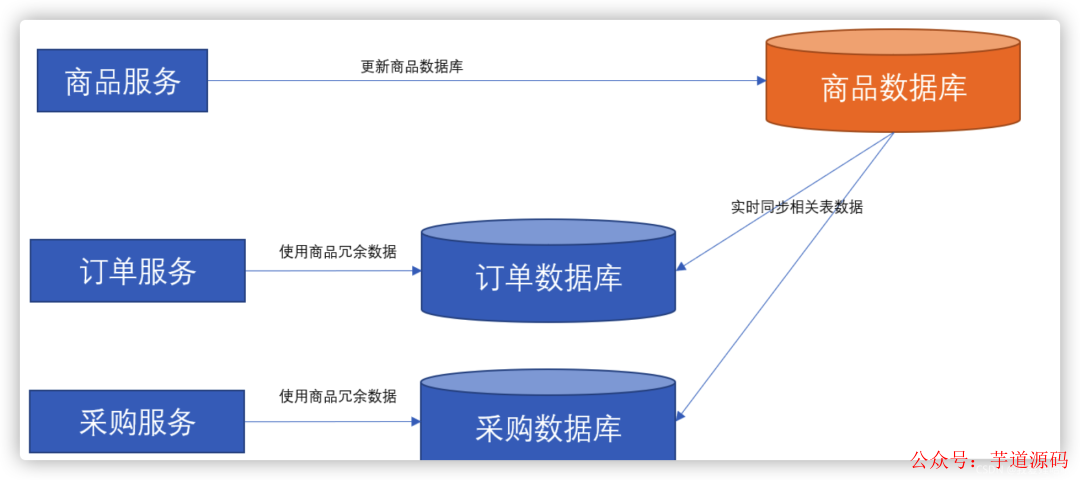
解耦業務邏輯的數據同步方案的設計思路是這樣的:
將商品及商品相關的一些表(比如分類表、生產批號表、保修類型、包換類型等)實時同步到需要依賴使用它們的服務的數據庫,并且保持表結構不變;
在查詢采購、訂單等服務時,直接關聯同步過來的商品相關表;
不允許采購、訂單等服務修改商品相關表。
此時,整個方案的架構如下圖所示:
以上方案就能輕松解決如下兩個問題:
商品無須依賴其他服務,如果其他服務的冗余數據同步失敗,它也不需要回滾自身的流程;
采購、訂單等服務無須關注冗余數據的同步。
不過,該方案的“缺點 ”是增加了訂單、采購等數據庫的存儲空間(因為增加了商品相關表)。
仔細計算后,我們發現之前數據冗余的方案中每個訂單都需要保存一份商品的冗余數據,假設訂單總數是 N,商品總數是 M,而 N 一般遠遠大于 M。因此,在之前數據冗余的方案中,N 條訂單就會產生 N 條商品的冗余數據。相比之下,解耦業務邏輯的數據同步方案更省空間,因為只增加了 M 條商品的數據。
此時問題又來了,如何實時同步相關表的數據呢?
我們直接找一個現成的開源中間件就可以了,不過它需要滿足支持實時同步、支持增量同步、不用寫業務邏輯、支持 MySQL 之間同步、活躍度高這五點要求。
根據這五點要求,我們在市面上找了一圈,發現了 Canal 、Debezium 、DataX 、Databus 、Flinkx 、Bifrost 這幾款開源中間件,它們之間的區別如下表所示:
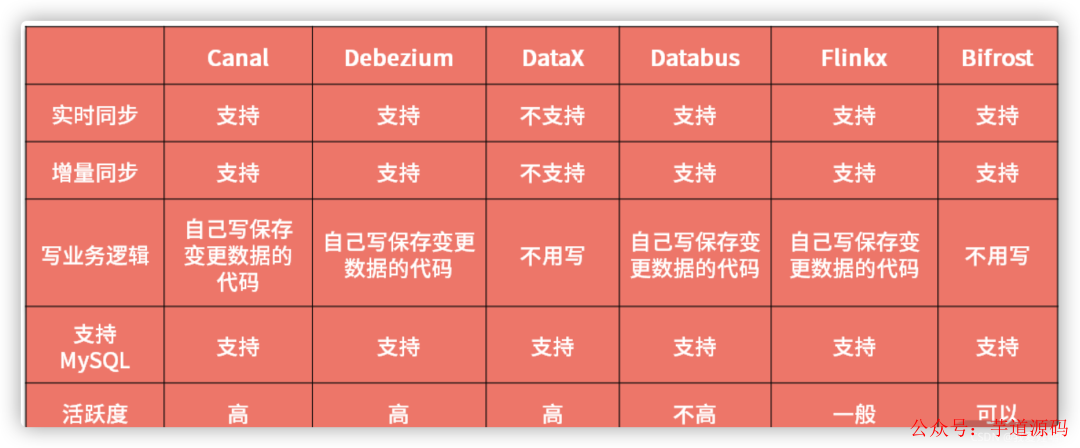
從對比表中來看,比較貼近我們需求的開源中間件是 Bifrost ,原因如下:
它的界面管理不錯;
它的架構比較簡單,出現問題后,我們可以自行調查,之后就算作者不維護了也可以自我維護,相對比較可控。
作者更新活躍;
自帶監控報警功能。
因此,最終我們使用了 Bifrost 開源中間件,此時整個方案的架構如下圖所示:
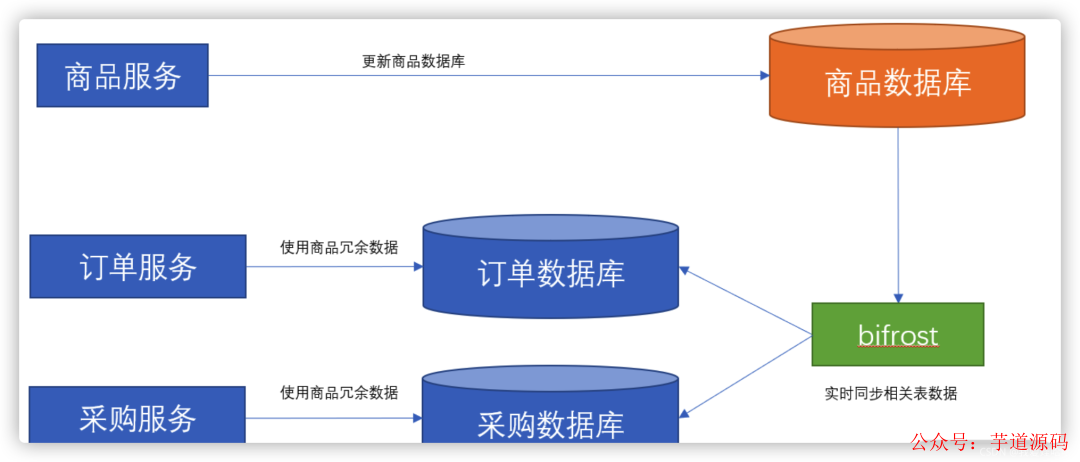
3、最終效果
整個架構方案上線后,商品數據的同步還算比較穩定,此時商品服務的開發人員只需要關注自身邏輯,無須再關注使用數據的人。如果需要關聯使用商品數據的訂單,采購服務的開發人員也無須關注商品數據的同步問題,只需要在查詢時加上關聯語句即可,實現了雙贏。
然而,唯一讓我們擔心的是 Bifrost 不支持集群,沒法保障高可用性。不過,到目前為止,它還沒有出現宕機的情況,反而是那些部署多臺節點負載均衡的后臺服務常常會出現宕機。
最終,我們總算解決了服務之間數據依賴的問題。
審核編輯:劉清
-
解耦控制
+關注
關注
0文章
29瀏覽量
10226 -
MYSQL數據庫
+關注
關注
0文章
96瀏覽量
9412 -
Bifrost架構
+關注
關注
0文章
2瀏覽量
3294
原文標題:微服務之間的數據依賴問題,該如何解決?
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何用ACM簡化你的Spring Cloud微服務環境配置管理
使用阿里云ACM簡化你的Spring Cloud微服務環境配置管理
中斷系統涉及到哪些問題
運維是如何看待微服務和容器的

自動駕駛技術涉及到的AI科技

微服務和容器之間的有何關系?
微服務循環依賴調用引發的血案
從分層架構到微服務架構介紹(五)





 工商網監
工商網監
評論