 java虛擬機與計算機內存是如何協同工作的
java虛擬機與計算機內存是如何協同工作的
介紹
為了屏蔽各種硬件和操作系統的內存訪問差異,以實現讓java程序在各種平臺下都能達到一致的并發效果,java虛擬機規范中定義了java內存模型,簡稱JMM。java內存模型規范了java虛擬機與計算機內存是如何協同工作的,它規定了一個線程如何和何時可以看到其他線程修改過的共享變量的值,以及在必須時如何同步地訪問共享變量。
一、jvm內存分配結構
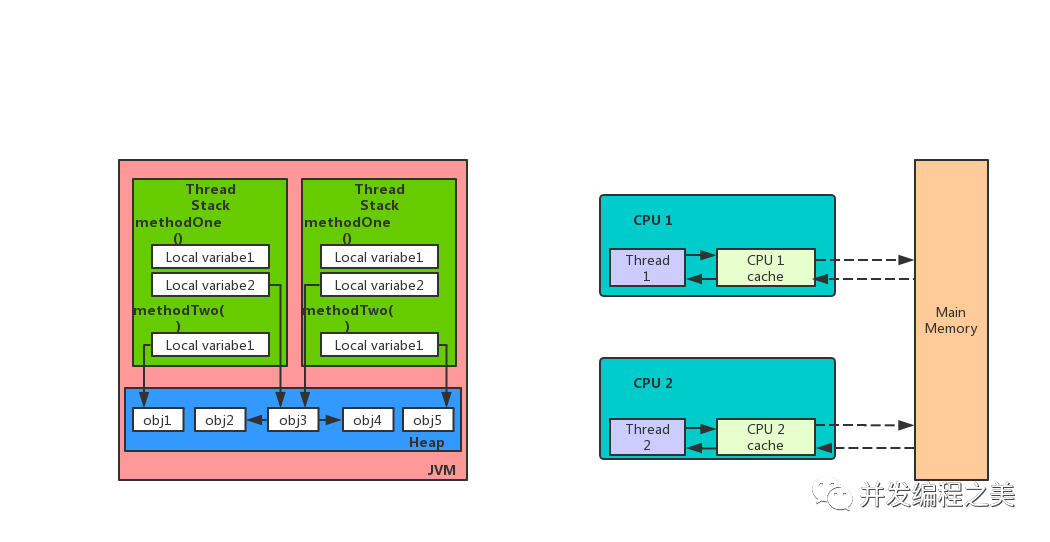
- java中的堆是運行時的數據區域,堆的優勢是可以動態的分配內存大小,生存期也不必事先告訴編譯器,垃圾回收機制負責回收不再使用的數據,缺點是由于運行時動態分配內存,因此存取速度相對慢一些。
- 棧的優勢是存取數據比堆要快一些,僅次于計算中的寄存器,棧的數據是可以共享的。缺點是存在棧中的數據的生存期以及大小必須是確定的,缺乏一些靈活性。棧中主要存放一些基本類型的變量。
- java內存模型要求調用棧和本地變量存放在線程棧上,對象存放在堆上。具體說下,一個本地變量,也有可能指向一個對象的引用,這種情況下,引用這個本地變量是存放在線程棧上,但是對象本身是存放在堆上的。一個對象包含方法,方法中的本地變量是存放在線程棧上的,即使這些方法所屬的對象存放在堆上。一個對象的成員變量可能隨著對象自身存放在堆上,不管這個成員變量是原始類型還是引用類型。靜態成員變量跟隨著類的定義一起存放在堆上,存在堆上的對象可以被所持有這個對象引用的線程訪問。
- 當一個線程可以訪問這個對象的時候,它也可以訪問這個對象的成員變量。如果兩個線程同時調用同一個對象上的同一個方法,他們就會都訪問這個對象的成員變量,但是每一個線程都擁有了這個成員變量的私有拷貝
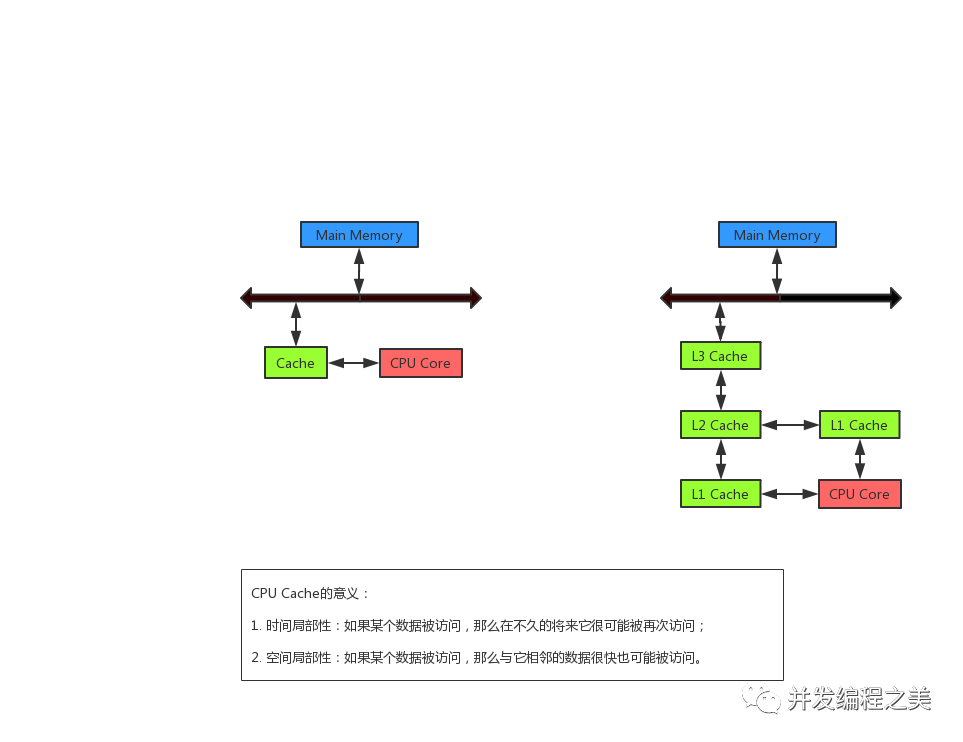
二、多核并發緩存架構
-
計算機在寄存器上執行的速度是遠大于在主內存上執行的速度;
-
由于計算機的存儲設備與處理器的運算速度之間存在幾個數量級的差距,所以新的計算機系統都不得不加入一層讀寫速度都盡可能接近處理器運算速度的高級緩存來作為內存與處理器之間的緩沖,將運算使用到的數據復制到緩存中,讓運算快速執行,當運算結束后,再將數據從緩存同步到內存中,這樣處理器就無需等待緩慢的內存讀寫了。
-
一個計算機還包含一個主存,所有的cpu都可以訪問這個主存,主存通常比CPU中的緩存大得多。
-
多核cpu運作原理:
通常情況下,當一個CPU需要讀取主存的時候,它會將主存的數據讀取到CPU緩存中,甚至會將緩存中的部分內容讀到它內部的寄存器里面,然后在寄存器中執行操作;當CPU需要將結果回寫到主存的時候,它會將內部寄存器的值刷新到緩存中,然后在某個時間點將值刷新回主存。
jvm內存分配結構與cpu多核并發緩存架構直接的關聯
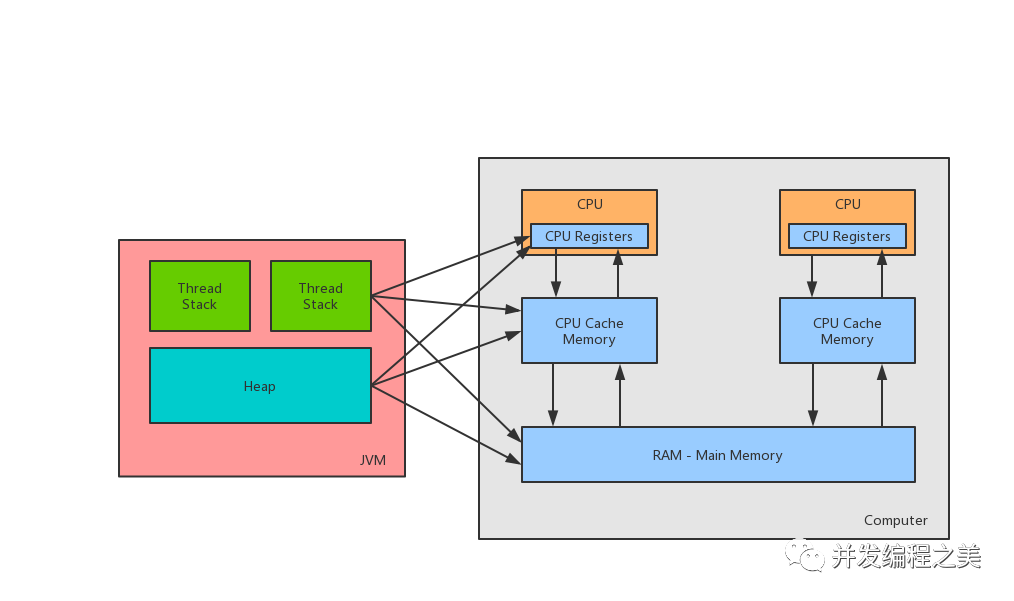
- 硬件架構沒有區分線程棧和堆,對于硬件架構來說所有的線程棧和堆都分布在主內存中,部分的線程棧和堆可能有時候會出現在CPU緩存中,和CPU內部的寄存器里面
三、java內存模型

- 線程之間共享變量存儲在主內存中,每一個線程都有一個私有的本地內存(工作內存),本地內存是java內存模型的一個抽象的概念,不是真實存在的,它涵蓋了緩存,寫緩沖區,寄存器,以及其他的硬件和編譯器的優化。本地內存中它存儲了該線程以讀或寫共享變量的拷貝的一個副本。
- 從更低的角度說,主內存就是硬件的內存,是為了獲取更好的運行速度,虛擬機以及硬件系統可能會讓工作內存優先存儲于寄存器和高速緩存中。
- java內存模型中線程的工作內存是CPU的寄存器和高速緩存的一個抽象的描述,而JVM的靜態內存存儲模型(jvm內存模型),它只是一種對內存的物理化分而已,它只局限在JVM的內存。
- 線程A和線程B通信必須要經過下面兩個步驟:
- 線程A需要將本地內存A中更新過的共享變量刷新到主內存里面;
- 線程B去主內存中讀取線程A之前更新過的共享變量
- Java的多線程之間是通過共享內存進行通信的,而由于采用共享內存進行通信,在通信過程中會存在一系列如可見性、原子性、順序性等問題,而JMM就是圍繞著多線程通信以及與其相關的一系列特性而建立的模型。JMM定義了一些語法集,這些語法集映射到Java語言中就是volatile、synchronized等關鍵字。
四、java內存模型同步的八種指令操作
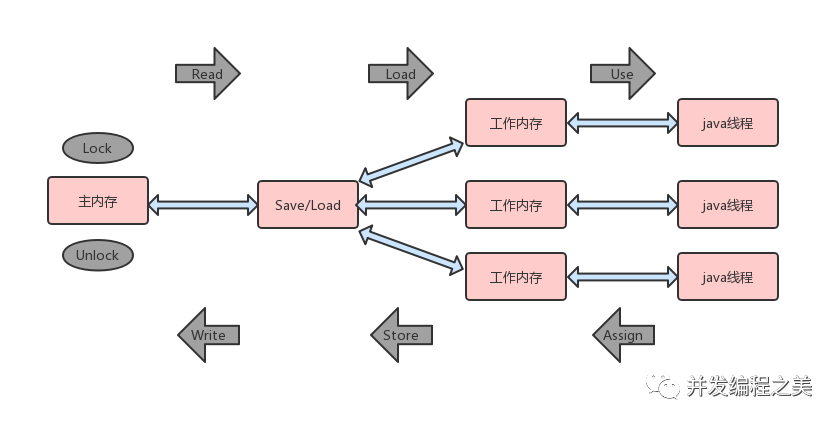
- lock(鎖定):作用于主內存的變量,把一個變量標識為一條線程獨占狀態。
- unlock(解鎖):作用于主內存的變量,把一個處于鎖定狀態的變量釋放出來,釋放后的變量才可以被其他線程鎖定。
- read(讀取):作用于主內存的變量,把一個變量值從主內存傳輸到線程的工作內存中,以便隨后的load動作使用。
- load(載入):作用于工作內存的變量,它把read操作從主內存中得到的變量值放入工作內存的變量副本中。
- use(使用):作用于工作內存的變量,把工作內存中的一個變量傳遞給執行引擎。每當虛擬機遇到一個需要使用到的變量的值得字節碼指令時,就會執行這個操作。
- assign(賦值):作用于工作內存的變量,它把一個從執行引擎接收到的值賦值給工作內存的變量。每當虛擬機遇到一個給變量賦值的字節碼指令時會執行這個操作。
- store(存儲):作用于工作內存的變量,把工作內存中的一個變量值傳送的主內存中,以便隨后的write的操作
- write(寫入):作用于主內存的變量,它把store操作從工作內存中一個變量的值傳送到主內存的變量中。
對應的java內存模型的同步規則:
- 如果要把一個變量從主內存中復制到工作內存,就需要按順序地執行read和load操作,如果把變量從工作內存中同步回主內存中,就要順序地執行store和write操作。但java內存模型只要求上述操作必須順序執行,而沒有保證必須是連續執行。
- 不允許read和load、store和write操作之一單獨出現。
- 不允許一個線程丟棄它的最近assign的操作,即變量在工作內存中改變了之后必須同步到主內存中。
- 不允許一個線程無原因地(沒有發生過任何assign操作)把數據從工作內存同步回主內存中。
- 一個新的變量只能在主內存中誕生,不允許在工作內存中直接使用一個未被初始化(load或assign)的變量。即就是對一個變量實施use和store操作之前,必須先執行過了assign和load操作。
- 一個變量在同一時刻只允許一條線程對其進行lock操作,但lock操作可以被同一條線程重復執行多次,多次執行lock后,只有執行相同次數的unlock操作,變量才會被解鎖。lock和unlock必須成對出現。
- 如果對一個變量執行lock操作,將會清空工作內存中次變量的值,在執行引擎使用這個變量前需要重新執行load或assign操作初始化變量的值。
- 如果一個變量事先沒有被lock操作鎖定,則不允許對他執行unlock操作;也不允許去unlock一個被其他線程鎖定的變量。
- 對一個變量執行unlock操作之前,必須先把此變量同步到主內存中(執行store和write操作)。
五、案列分析
下面我們結合java內存模型分析下共享變量執行i++的操作流程:
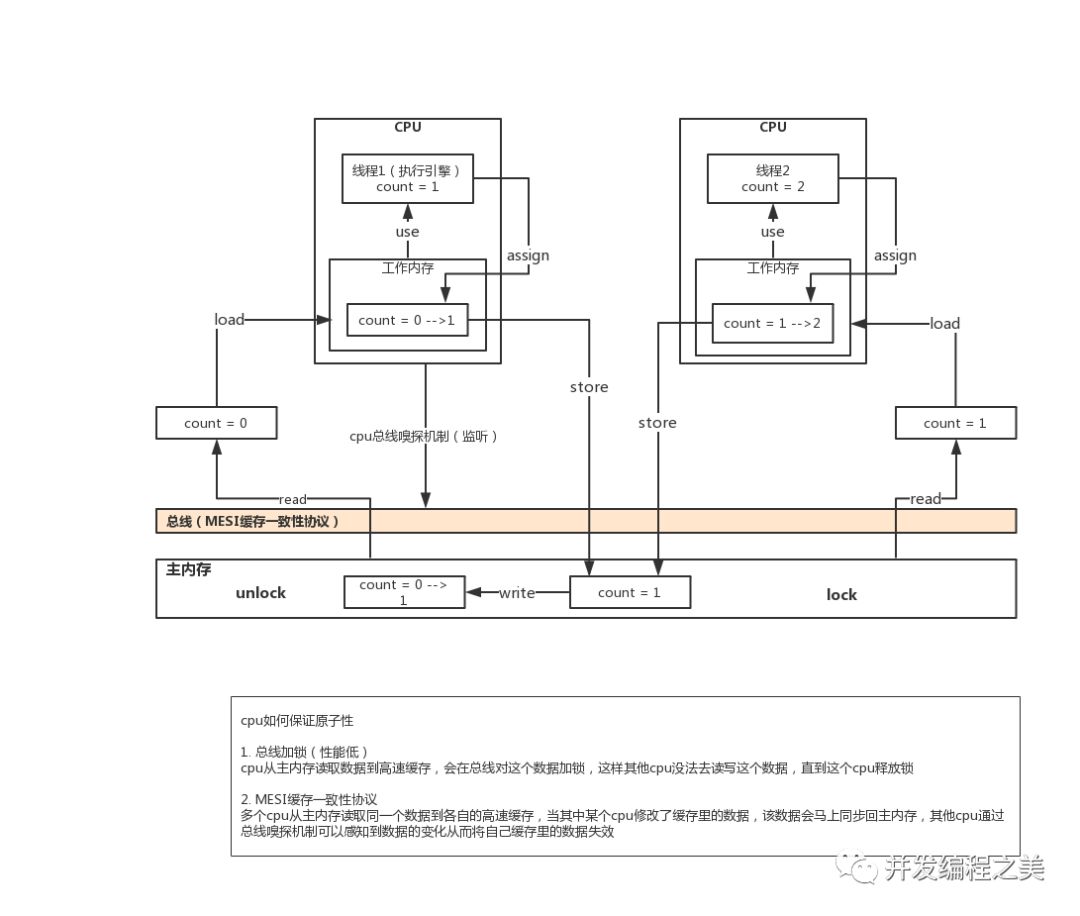
- 初始化共享變量i=0。
- 線程1通過read指令從主內存中讀取出共享變量i=0,通過load指令加載到線程1的工作內存中。
- 在線程1的工作內存中,通過use指令將共享變量i=0加載到cpu執行引擎進行+1計算,計算后共享變量i=1。
- 在線程1的工作內存中,通過assign指令將cpu執行引擎計算后的共享變量i=1賦值到線程1的工作內存中。
- 線程1通過store指令將線程1中工作內存的共享變量同步到主內存中。
- 在線程1的主內存中,通過write指令將共享變量i=1的值賦值給主內存的該共享變量,從而完成一次i++操作。
- 那么當線程1還未將共享變量的值同步賦值回寫到主內存時,線程2開始進行了i++操作,線程2通過read指令讀取到的共享變量i的值此時還是0,那么線程2又在0的基礎進行了i++操作。所以當很多線程并發執行i++操作時,結果是與我們預期不符的。
- 以上結合java內存模型分析了我們共享變量的一個執行流程。解釋了i++操作是一個線程不安全的。
結語
上一篇我們分析了java并發包中cas的原理,這篇總結下cas涉及到的java內存模型的原理,cas還涉及到的cpu緩存一致性協議,我們后面繼續分析。
-
處理器
+關注
關注
68文章
19400瀏覽量
230745 -
寄存器
+關注
關注
31文章
5363瀏覽量
120928 -
JAVA
+關注
關注
19文章
2973瀏覽量
104962 -
虛擬機
+關注
關注
1文章
926瀏覽量
28356
發布評論請先 登錄
相關推薦
Java虛擬機介紹
計算機內部總線,計算機內部總線是什么意思
分析java虛擬機內存要如何分配
Java內存區域分配、Java虛擬機棧、對象的訪問方式和GC
虛擬機內省與內存安全監測
私有云平臺的虛擬機內存調度策略





 工商網監
工商網監
評論