 10張圖帶你輕松理解關系型數據庫系統的工作原理
10張圖帶你輕松理解關系型數據庫系統的工作原理
什么是索引
索引是一種幫助減少數據查詢時間的數據結構。索引在實現這一目標時,需要付出存儲、內存和保持更新(較慢的寫入速度)的額外成本,這使得我們可以跳過檢查每一行表的繁瑣任務。
就像書后面的索引頁一樣,它可以幫助你找到正確的一頁。
為什么需要索引
小量的數據是易于管理的(比如一個小班級的出勤表), 但是, 當數據規模變得更大時(比如一個大城市的出生登記), 事情就不那么容易了。之前能夠很快執行的操作都開始變得緩慢。
想象一下,如果你需要在一頁 A4 紙的名單上上找到某個信息,與需要在上千頁的名單中找到它,你的查詢策略會有何變化。
無論你想到的查詢策略是什么,幾乎總會有某個數據庫在某個特定的時間點用到了和你相似的策略,因為隨著它們的發展,他們需要收集和存儲的數據會逐漸變得龐大,最終必將遇到上述的問題。
因此,我們需要索引來幫助我們盡可能快地獲得我們需要的相關數據。
索引是如何工作的?
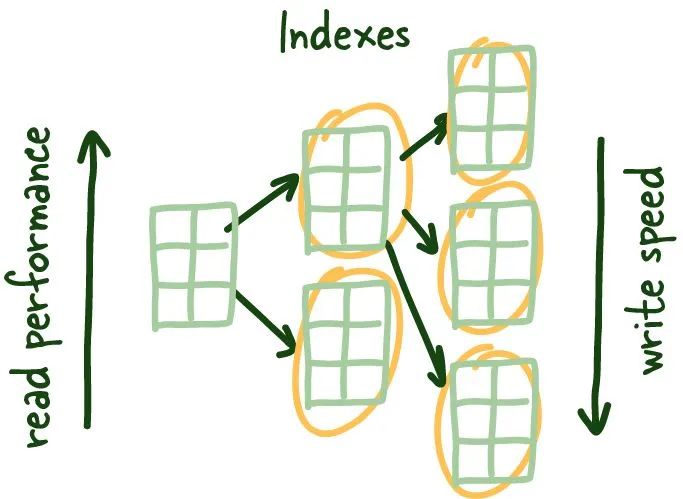
一般而言,索引越多讀取性能越好,但這是以寫性能的降低為代價的,因為你需要保持對索引的更新
其中一個方案是根據查詢方式來維護數據存儲邏輯。比如你需要通過姓名來查詢某個名單,那就將名單按照姓名進行排序。但這個策略有許多問題需要考慮:
- 如果我有多種查詢方式呢? 比如,既有用姓名查詢也有用身份證查詢。
- 如果有新數據的寫入, 寫入速度會受到多大的影響?
- 如何處理數據的更新呢?
- 所有的數據操作的復雜度是什么樣的呢?
無論你的原始策略是什么,肯定都需要一種維護數據順序的方式以便獲取相關的無序數據。
如下表中的例子,幾乎不需要什么時間,我們就可以通過掃描整個表將查詢到我們想要的數據。
+─────+─────────+──────────────+
| id | name | city |
+─────+─────────+──────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
+─────+─────────+──────────────+
加入存儲的數據規模無法全部存放到內存,或者需要很長的時間才能將數據從磁盤加載到內存呢?如下表中,數據分散在磁盤中,無法完全加載到內存。
+──────────+─────────+───────────────────+
| id | name | city |
+──────────+─────────+───────────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
| ... | ... | ... |
| 1000000 | Steph | San Francisco |
| 1001000 | Linus | Portland |
+───────+─────────+──────────────────────+
大部分 R&D 立刻想到了,我們需要字典(hash表)以及一種可以不需要掃描磁盤直接定位到正在查詢的指定行的手段。
索引葉子節點提供指定列到索引的映射,它能夠存儲符合條件的行所在的位置。

RowIDs indexes mapping to table data
這些索引葉子節點是索引列和相應行在磁盤上的位置之間的映射。它提供了一種通過索引列來快速獲取指定行的方法。掃描索引的速度會更快,因為它是你要搜索的列的緊湊表示(更少的字節)。它為你節省了讀取一堆塊來尋找所需數據的時間,而且更便于緩存,進一步加快了整個過程的速度。
這些索引的葉子節點是統一大小的,我們在每個塊中盡可能多地存儲這些葉子節點。由于這種結構需要對數據進行排序(邏輯上,而不是磁盤上的物理排序),我們需要解決必須快速添加和刪除數據的問題。通常我們用一個雙向鏈表來解決這個問題。
這里的好處有兩個:它允許我們向前和向后讀取索引葉子節點,并在我們刪除或添加新行時快速重建索引結構,因為我們只是在修改指針。
由于這些葉子節點在磁盤上并不是按順序排列的,我們需要一種方法來獲得正確的索引葉子節點。
平衡樹(B-Tree)

B樹 VS B+樹
?「B樹 VS B+樹」
B+樹主要區別是,不在中間節點存儲任何數據。所有的數據引用都鏈接到葉子節點上,這樣可以更好地緩存樹狀結構(中間節點數據規模小更便于緩存索引信息)。
其次,B+樹葉子節點是鏈接的,所以如果你需要做索引掃描,你可以簡單的線性遍歷,而不是向上和向下遍歷整個樹,從磁盤上加載更多的索引數據。
?
在關系型數據庫中,B+樹的結構如下圖:

數據庫中的B+樹
什么是事務
事務是數據庫操作的基本單位,它要么完全成功要么完全失敗,不可能存在部分成功部分失敗的情況。
數據不一致
在不同數據隔離級別中可能會出現一些數據不一致現象,了解這些現象對于調試你的系統以及了解你的系統能夠容忍什么樣的不一致是至關重要的。
不可重復讀(Non-repeatable reads)

不可重復讀
如上圖所示,如果你在事務中的兩次后續讀取之間不能獲得一致的數據視圖,就會發生不可重復的讀取。在特定的模式下,數據庫的并發操作可能會出現你剛讀的值被修改,導致不可重復的讀取。
臟讀(Dirty reads)

臟讀
類似地,當你執行了一次讀取,另一個事務更新了同一行,但沒有提交工作,你執行了另一次讀取,你可以訪問未提交的(臟)值(這不是一個持久的狀態變化,與數據庫的狀態不一致), 就會發生臟讀取。
幻讀(Phantom reads)

幻讀
幻象讀取是另一種已提交的數據不一致現象,他常發生在處理數據統計的場景。例如,你在一個特定的事務中兩次計算客戶的總數。在兩次連續的讀取之間,另一個客戶注冊或刪除了他們的賬戶(已提交),如果你的數據庫不支持這些事務的范圍鎖,這將導致你得到兩個不同的值。
隔離級別

SQL標準的四種隔離級別
SQL標準定義了4個標準隔離級別,這些級別可以而且應該被全局配置(如果我們不能可靠地知道隔離級別,就會發生一些奇怪的問題)。
可重復讀(REPEATABLE READ)
在這個隔離級別下,確保在一個事務中多次讀取同一數據時,得到的結果是一致的。
這意味著事務在開始時會創建一個一致的快照,然后在事務結束之前,其他事務對數據的修改不會影響該事務的讀取結果。
在可重復讀級別下,解決了不可重復讀的問題,但可能出現幻讀問題。
串行化(SERIALIZABLE)
這是最高的隔離級別,它確保事務之間的并發執行就像是順序執行一樣。
在這個級別下,事務串行執行,避免了臟讀、不可重復讀和幻讀的問題。
雖然序列化提供了最高的數據一致性,但也犧牲了并發性能,因為事務必須依次執行,不能并行處理。
讀提交(READ COMMITTED)
在這個隔離級別下,一個事務只能讀取到已經提交的數據。這意味著臟讀的問題被解決了,因為事務只能看到其他事務已經提交的數據。
然而,在這個級別下,可能會出現不可重復讀問題。
讀未提交
在這個隔離級別下,一個事務可以讀取到另一個事務尚未提交的數據。這意味著一個事務可能會讀取到臟數據(未經提交的數據),即臟讀。
這個級別提供了最低的隔離性,允許并發事務之間產生相互干擾。
-
SQL
+關注
關注
1文章
773瀏覽量
44221 -
數據庫
+關注
關注
7文章
3845瀏覽量
64603 -
Hash算法
+關注
關注
0文章
43瀏覽量
7408
發布評論請先 登錄
相關推薦
MobiLink關系數據庫同步系統是什么?
DCS組態軟件實時數據庫系統的設計
數據庫系統輔助測試工具
數據庫系統概論之如何進行關系查詢處理和查詢優化
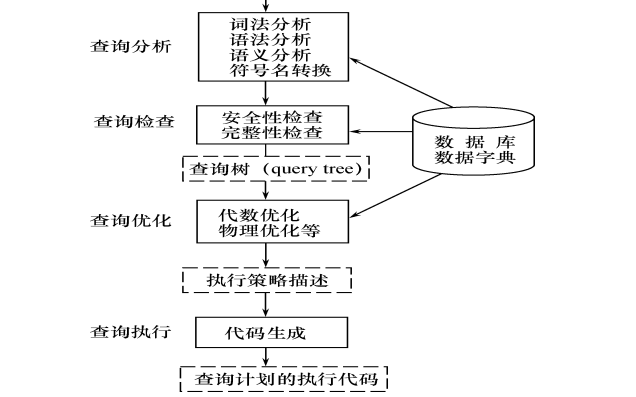
數據庫系統原理與應用教程之關系數據庫的詳細資料說明





 工商網監
工商網監
評論