
信息抽取(IE)旨在從非結構化文本中抽取出結構化信息,該結果可以直接影響很多下游子任務,比如問答和知識圖譜構建。因此,探索ChatGPT的信息抽取能力在一定程度上能反映出ChatGPT生成回復時對任務指令理解的性能。

論文:Is Information Extraction Solved by ChatGPT? An Analysis of Performance, Evaluation Criteria, Robustness and Errors
地址:https://arxiv.org/pdf/2305.14450.pdf
代碼:https://github.com/RidongHan/Evaluation-of-ChatGPT-on-Information-Extraction
本文將從性能、評估標準、魯棒性和錯誤類型四個角度對ChatGPT在信息抽取任務上的能力進行評估。
實驗
實驗設置
任務和數據集
本文的實驗采用4類常見的信息抽取任務,包括命名實體識別(NER),關系抽取(RE),事件抽取(EE)和基于方面的情感分析(ABSA),它們一共包含14類子任務。
對于NER任務,采用的數據集包括CoNLL03、FewNERD、ACE04、ACE05-Ent和GENIA。
對于RE任務,采用的數據集包括CCoNLL04、NYT-multi、TACRED和SemEval 2010。
對于EE任務,采用的數據集包括CACE05-Evt、ACE05+、CASIE和Commodity News EE。
對于ABSA任務,采用的數據集包括D17、D19、D20a和D20b,均從SemEval Challenges獲取。
實驗結果
1、性能
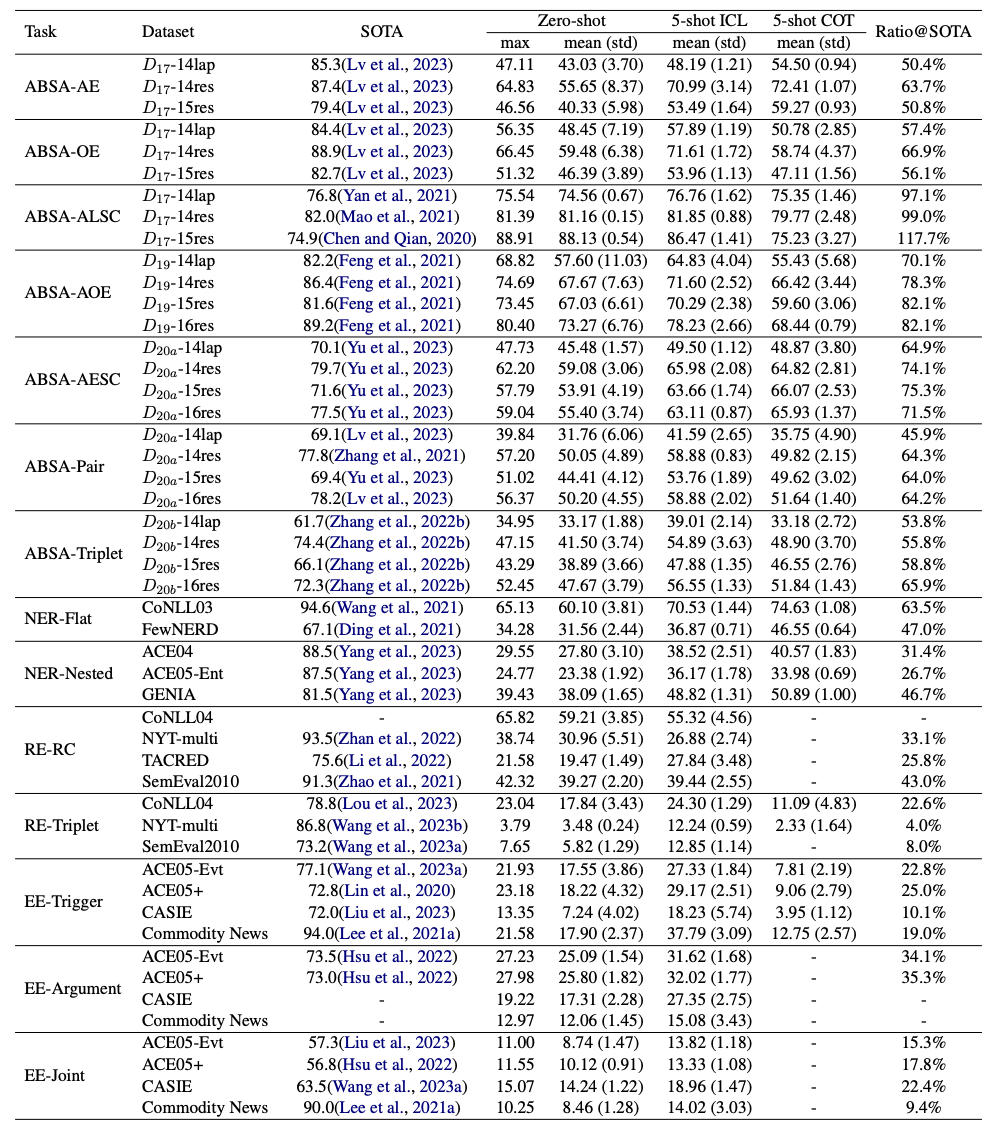
從上圖結果可以明顯看出:
(1)ChatGPT和SOTA方法之間存在顯著的性能差距;
(2)任務的難度越大,性能差距越大;
(3)任務場景越復雜,性能差距越大;
(4)在一些簡單的情況下,ChatGPT可以達到或超過SOTA方法的性能;
(5)使用few-shot ICL提示通常有顯著提升(約3.0~13.0的F1值),但仍明顯落后于SOTA結果;
(6)與few-shot ICL提示相比,few-shot COT提示的使用不能保證進一步的增益,有時它比few-shot ICR提示的性能更差。
2、對性能gap的思考
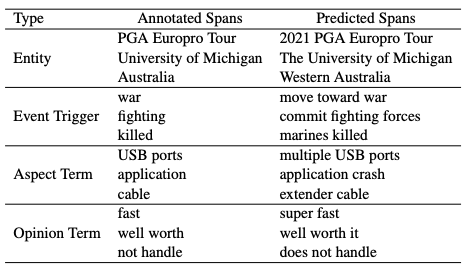
通過人工檢查ChatGPT的回復,發現ChatGPT傾向于識別比標注的跨度更長的sapn,以更接近人類的偏好。因此,之前的硬匹配(hard-matching)策略可能不適合如ChatGPT的LLM,所以本文提出了一種軟匹配(soft-matching)策略,算法流程如下。

該算法表明,只要生成和span和標記的span存在包含關系且達到相似度的閾值,則認為結果正確。通過軟匹配策略,對重新評估ChatGPT的IE性能,得到的結果如下。
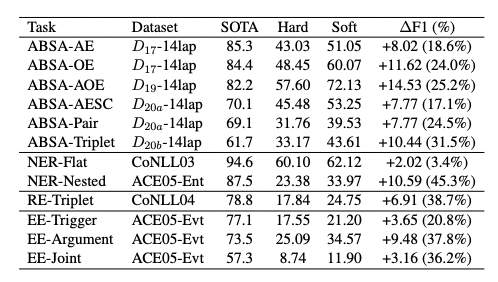
從上圖可以看出,軟匹配策略帶來一致且顯著的性能增益(F1值高達14.53),簡單子任務的提升更明顯。同時,雖然軟匹配策略帶來性能提升,但仍然沒有達到SOTA水平。
3、魯棒性分析
(1)無效輸出
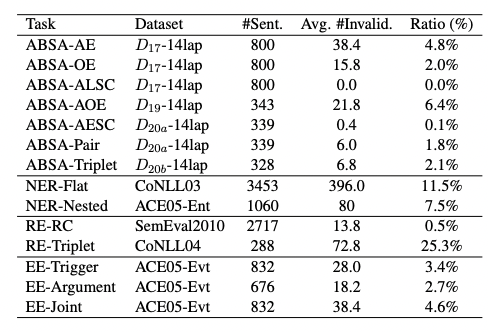
在大多數情況下,ChatGPT很少輸出無效回復。然而在RE-Triplet子任務中,無效回復占比高達25.3%。一個原因可能這個子任務更加與眾不同。
(2)無關上下文
由于ChatGPT對不同的提示非常敏感,本文研究了無關上下文對ChatGPT在所有IE子任務上性能的影響。主要通過在輸入文本前后隨機插入一段無關文本來修改zero-shot提示的“輸入文本”部分,無關文本不包含要提取的目標信息span,結果如圖所示。
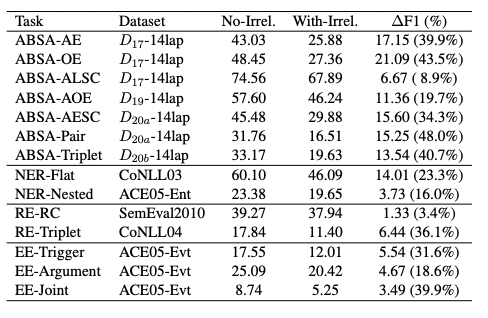
可以看出,當隨機添加無關上下文時,大多數子任務的性能都會顯著下降(最高可達48.0%)。ABSA-ALSC和RE-RC子任務的性能下降較小,這是因為它們基于給定的方面項或實體對進行分類,受到無關上下文的影響較小。因此,ChatGPT對無關上下文非常敏感,這會顯著降低IE任務的性能。
(3)目標類型的頻率
真實世界的數據通常為長尾分布,導致模型在尾部類型上的表現比在頭部類型上差得多。本文研究了“目標類型的頻率”對ChatGPT在所有IE子任務中的性能的影響,結果如圖所示。
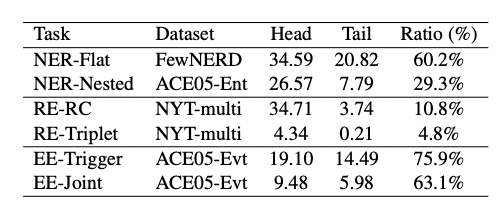
可以看出,尾部類型的性能明顯不如頭部類型,僅高達頭部類型的75.9%。在一些子任務上,比如RE-RC和RE-Triplet,尾部類型的性能甚至低于頭部類型性能的15%,所以ChatGPT也面臨長尾問題的困擾。
(4)其他
本文探討了ChatGPT是否可以區分RE-RC子任務中兩個實體的主客觀順序。由于大多數關系類型都是非對稱的,因此兩個實體的順序非常關鍵。對于非對稱關系類型的每個實例,交換實體的順序并檢測預測結果的變化,結果如圖所示。
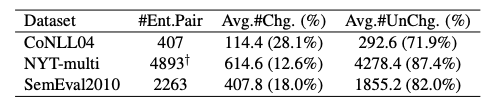
可以看到,交換順序后大多數預測結果(超過70%)與交換前保持不變。因此對于RE-RC子任務,ChatGPT對實體的順序不敏感,而且無法準確理解實體的主客體關系。
4、錯誤類型分析
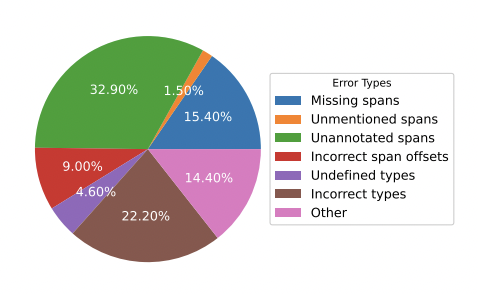
從圖中可以看出,“Unannotated spans”、“Incorrect types”和“Missing spans”是三種主要的錯誤類型,占70%以上。特別是,幾乎三分之一的錯誤是“Unannotated spans”的錯誤,這也引發了對標注數據質量的擔憂。
總結
本文從性能、評估標準、魯棒性和錯誤類型四個角度評估了ChatGPT的信息抽取能力,結論如下:
性能 本文評估了ChatGPT在zero-shot、few-shot和chain-of-thought場景下的17個數據集和14個IE子任務上的性能,發現ChatGPT和SOTA結果之間存在巨大的性能差距。
評估標準 本文重新審視了性能差距,發現硬匹配策略不適合評估ChatGPT,因為ChatGPT會產生human-like的回復,并提出軟匹配策略,以更準確地評估ChatGPT的性能。
魯棒性 本文從四個角度分析了ChatGPT對14個子任務的魯棒性,包括無效輸出、無關上下文、目標類型的頻率和錯誤類型并得出以下結論:1)ChatGPT很少輸出無效響應;2)無關上下文和長尾目標類型極大地影響了ChatGPT的性能;3)ChatGPT不能很好地理解RE任務中的主客體關系。
錯誤類型 通過人工檢查,本文分析了ChatGPT的錯誤,總結出7種類型,包括Missing spans、Unmentioned spans、Unannotated spans、Incorrect span offsets、Undefined types、Incorrect types和other。發現“Unannotated spans”是最主要的錯誤類型。這引發了大家對之前標注數據質量的擔心,同時也表明利用ChatGPT標記數據的可能性。
審核編輯 :李倩
-
AI
+關注
關注
87文章
33017瀏覽量
272766 -
數據集
+關注
關注
4文章
1217瀏覽量
25091 -
深度學習
+關注
關注
73文章
5531瀏覽量
122076 -
OpenAI
+關注
關注
9文章
1190瀏覽量
7078 -
ChatGPT
+關注
關注
29文章
1580瀏覽量
8422
原文標題:ChatGPT能解決信息抽取嗎?一份關于性能、評估標準、魯棒性和錯誤的分析
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
科技大廠競逐AIGC,中國的ChatGPT在哪?
基于子樹廣度的Web信息抽取
基于重復模式的自動Web信息抽取
基于XML的WEB信息抽取模型設計
基于WebHarvest的健康領域Web信息抽取方法
節點屬性的海量Web信息抽取方法
抽取式摘要方法中如何合理設置抽取單元?
了解信息抽取必須要知道關系抽取

基于篇章信息和Bi-GRU的事件抽取綜述
面向知識圖譜的信息抽取

10分鐘教你如何ChatGPT最詳細注冊教程
微信接入ChatGPT 利用ChatGPT的對話能力

ChatGPT Plus怎么支付 開通ChatGPT plus有什么功能?





 工商網監
工商網監

評論