") 讓文獻檢索進入AI模式
讓文獻檢索進入AI模式
查閱文獻是進行科學(xué)研究的一項基本工作。據(jù)統(tǒng)計,科研人員查找消化科學(xué)技術(shù)資料的時間約占整個科研時間的51%。將文獻制作成一個知識庫或數(shù)據(jù)庫,使用人工智能方法,減輕科研人員查找和閱讀文獻的“負(fù)擔(dān)”嗎?5月30日,基于人工智能的科學(xué)研究論壇2023中關(guān)村論壇正式發(fā)布了基于猛犸語言模型+向量數(shù)據(jù)庫的——science navigator(文獻數(shù)據(jù)庫)。
這是通過對話提問的方式搜索、閱讀、分析、管理文獻的結(jié)果。這一成果由北京科學(xué)智能研究院、中國科學(xué)院計算機網(wǎng)絡(luò)信息中心、墨奇科技共同開發(fā)。
說:“在最初的“搜索式”利用“搜索式”搜索引擎和網(wǎng)絡(luò)搜索到,以及到目前人工智能技術(shù)的跨越式發(fā)展,我們大型語言理解和問答模式問題的能力在人類的智能水平接近的首次看見”。墨奇科技副總裁孟卓飛表示,文獻知識庫的發(fā)布恰逢搜索模式進入對話時代的發(fā)展趨勢。
文獻知識庫的性能優(yōu)勢可以用多、快、好、節(jié)約四個字來形容。孟卓飛介紹,“多”體現(xiàn)在“多模,多模,多數(shù)據(jù)”中。“快速”意味著“快速質(zhì)疑,快速引入,快速重復(fù)”。“好”體現(xiàn)為“更實時的數(shù)據(jù),更可靠的引用,更專業(yè)的理解”。“省”是顯著降低了極限系統(tǒng)優(yōu)化、自身向量算法和數(shù)據(jù)計算的成本。
文獻知識庫的發(fā)展方向是將更多的實驗數(shù)據(jù)包含在矢量數(shù)據(jù)庫中。這時,科學(xué)實驗的設(shè)計原理,實驗方式,實驗結(jié)論及結(jié)論后對應(yīng)的思考都可以作為質(zhì)疑對象。孟卓飛得益于大模型和矢量數(shù)據(jù)庫科研人員提出方向性問題拆卸機器的問題,將完成提出的設(shè)計模擬實驗等一系列程序,可以到內(nèi)容中得出的結(jié)果問題的反省和反復(fù)釋放科研人員時間精力在進一步解決關(guān)鍵問題和創(chuàng)新的想法。
-
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3845瀏覽量
64586 -
文獻檢索
+關(guān)注
關(guān)注
0文章
2瀏覽量
1400
發(fā)布評論請先 登錄
相關(guān)推薦
企業(yè)AI算力租賃模式的好處
APM32F10xx進入低功耗模式的問題分析

TLV320AIC3106如何在不進行音頻采集或播放時讓芯片進入低功耗模式?
解決睡眠模式進入系統(tǒng)在速度命令模式下的問題

軟件系統(tǒng)的數(shù)據(jù)檢索設(shè)計
ESP32有時可以進入省電模式,有時不可以進入省電模式,為什么?
TC397進入SCR模式的條件是什么?
stm8l與LIS3DH加速計通過I2C進行通信,是否可以讓STM8L152進入停機模式呢?

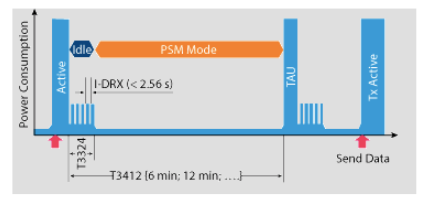
NB-IoT PSM模式的進入和退出分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論