 總結FasterTransformer Encoder優化技巧
總結FasterTransformer Encoder優化技巧
FasterTransformer BERT
FasterTransformer BERT 包含優化的 BERT 模型、高效的 FasterTransformer 和 INT8 量化推理。
模型結構
標準的 BERT 和 高效的 FasterTransformer
FasterTransformer 編碼器支持以下配置。
- Batch size (B1): 批量大小 <= 4096
- Sequence length (S): 序列長度 <= 4096。對于 INT8 模型,當 S > 384 時 S 需要是 32 的倍數。
- Size per head (N): 小于 128 的偶數。
- Head number (H): 在 FP32 下滿足 H * N <= 1024 或在 FP16 下滿足 H * N <= 2048 的任何數字。
- Data type: FP32, FP16, BF16, INT8 and FP8 (Experimental).
- 如果內存足夠,任意層數(N1)
在 FasterTransformer v1.0 中,我們提供了高度優化的 BERT 等效編碼器模型。接下來,基于Effective Transformer的思想,我們在 FasterTransformer v2.1 中通過去除無用的 padding 來進一步優化BERT推理,并提供 Effective FasterTransformer。在 FasterTransformer v3.0 中,我們提供了 INT8 量化推理以獲得更好的性能。
在 FasterTransformer v3.1 中,我們優化了 INT8 Kernel 以提高 INT8 推理的性能,并將 TensorRT 的多頭注意力插件集成到 FasterTransformer 中。在 FasterTransformer v4.0 中,我們添加了多頭注意力 Kernel 支持 V100 的 FP16 模式和 T4, A100 的 INT8 模式。下圖演示了除 INT8 外的這些優化的流程圖。在FasterTransformer v5.0中,我們重構了代碼,將 mask building 和 padding 移動到 Bert 的 forward 函數中,并在 Ampere GPU 上基于稀疏特性來加速GEMM。在 FasterTransformer v5.1 中,我們支持對 Bert FP16 進行進行多節點多 GPU 推理。
BERT 模型是 google 在2018年提出的。FasterTransformer 的encoder 相當于 BERT 模型,但是做了很多優化。圖 1 最左邊的流程顯示了 FasterTransformer 中的優化。經過優化后,FasterTransformer 僅使用 8 或 6 個 gemms(藍色塊)和 6 個自定義 CUDA kernel(綠色塊)來實現一個 transformer 塊。
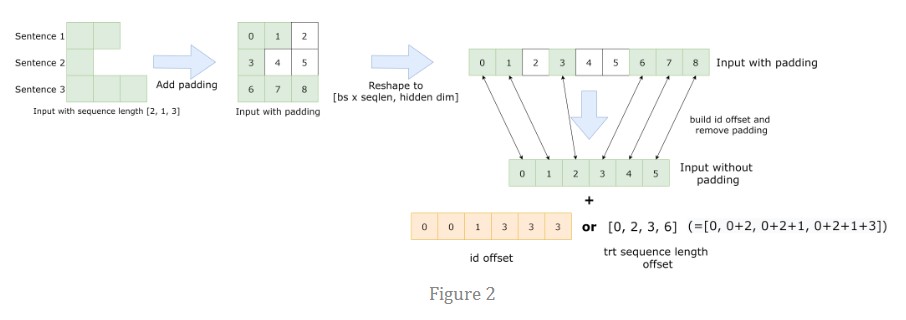
對于 Effective FasterTransformer,主要思想是去除句子的填充以防止計算無用的標記。當一個 Batch 的平均序列長度遠小于最大序列長度時,此方法可以節省大量時間。圖 2 顯示了我們使用的想法和偏移量(橙色)。要實現 Effective FasterTransformer,我們需要考慮兩個問題。首先,我們需要去除 BERT 之前的 padding,離開 BERT 之后重建 padding 以保持結果的形狀。這很簡單,帶來的開銷基本可以忽略。第二個問題是多頭注意力的計算。一個天真的解決方案是在多頭注意力之前重建填充并在多頭注意力之后移除填充,如圖 1 的第二個流程圖所示。因為我們可以將這些重建/移除融合到其他 kernel 中,額外的開銷也是可以忽略的。
為了進一步提高多頭注意力的性能,我們集成了 TensorRT 的多頭注意力,將整個注意力計算融合到一個 kernel 中。源代碼在這里。該 kernel 同時支持 Effective FasterTransformer 和標準 BERT 模型。圖 1 中的第三個和第四個流程圖顯示了工作流程。有了這樣的 kernel ,我們就不用擔心多頭注意力的填充問題了。這個 kernel 需要另一個偏移量,如圖 2 所示。

第一個偏移量 [0, 0, 1, 3, 3, 3]比較好理解,直接和[0, 1, 2, 3, 4, 5]迭代就可以得到原始的位置了。第二個偏移量是從0位置開始,記錄連續的原始token個數,比如我們將[0, 2, 3, 6]做差分,得到[2, 1, 3]也對應了原始的數據中每行做的padding的tokn數目。
此外,我們發現 padding 會影響某些任務的準確性,盡管它們應該是無用的。因此,我們建議刪除下游任務最終輸出中的填充。
編碼器的參數、輸入和輸出:
-
Constructor of BERT

-
Input of BERT

-
Output of BERT

上面聲明了 Bert 模型的輸入參數,以及輸入和輸出Tensor的shape。
此外,注意到 TensorRT 的多頭注意力Kernel雖然功能很強大但是也有一些限制。首先,這個kernel需要 Turing 或者更新架構的 GPU,并且每個頭的大小必須是64。當條件不滿足時,我們使用FasterTransformer的原始多頭注意力實現。其次,它需要一個額外的序列長度偏移量,如Figure2所示,更多的細節在這里 。當輸入有 padding 時,序列長度偏移的形狀為 。假設這里有3個序列,長度分別為 , , ,然后 padding 之后的序列長度為 。那么序列長度偏移時 。即,序列長度偏移記錄了每個句子的序列長度。當我們有 padding 時,我們將 padding 視為一些獨立的句子。
在 FasterTransformer v4.0 中,我們實現了兩條 INT8 推理的流水線,如圖 3 所示。對于 int8_mode == 1 (int8v1),我們不量化殘差連接,使用 int32 作為 int8 gemms 的輸出,并對權重采用逐通道的量化方式。對于 int8_mode == 2 (int8v2),我們量化殘差連接,使用 int8 作為 int8 gemms 的輸出,并對權重采用逐張量的量化。一般來說,int8_mode == 1 的精度更高,而 int8_mode == 2 的性能更好。

Figure 3

對于 INT8 推理,需要量化模型。我們提供了 TensorFlow 量化工具和示例代碼,同時還提供了帶有 TensorRT 量化工具的 PyTorch 示例代碼。請先參考bert-quantization/bert-tf-quantization和examples/pytorch/bert/bert-quantization-sparsity中的README。
在 FasterTransformer v5.0 中,我們支持稀疏 gemm 以利用 Ampere GPU 的稀疏特性。我們還提供了一個關于 PyTorch 的示例。
在 FasterTransformer v5.1 中,我們支持 BERT 模型的多 GPU 多節點推理。
優化點解讀
優化主要是針對 Figure 1 也就是 BERT 的編碼器模塊的各個組件來講(我這里忽略了 Figure1 的和 padding 相關的組建的講解,感興趣的讀者可以自己看看 FasterTransformer)。
import torch.nn as nn
class Attention(nn.Module):
"""
Compute 'Scaled Dot Product Attention
"""
def forward(self, query, key, value, mask=None, dropout=None):
scores = torch.matmul(query, key.transpose(-2, -1)) \\
/ math.sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value),
class MultiHeadedAttention(nn.Module):
"""
Take in model size and number of heads.
"""
def __init__(self, h, d_model, dropout=0.1):
super().__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linear_layers = nn.ModuleList([nn.Linear(d_model, d_model) for _ in range(3)])
self.output_linear = nn.Linear(d_model, d_model)
self.attention = Attention()
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [l(x).view(batch_size, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linear_layers, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, attn = self.attention(query, key, value, mask=mask, dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
return self.output_linear(x)
Compute Q, K, V by three GEMMs or one Batch GEMM
add_QKV_bias 優化
這個是針對上面forward函數中 (1) 這部分存在的分別對 Q, K, V進行bias_add以及transpose的優化,將其融合成一個cuda kernel。
對于FP32,FasterTransformer是啟動 batch_size *seq_len *3 個 Block, 每個 Block 里面啟動 head_num *size_per_head 個線程只處理一個token(對應 head_num *size_per_head 次計算)的 bias_add 計算。我們注意到這里還將輸入的shape進行了改變,也就是將原始的[batch_size, seq_length, head_num * size_per_head] -> [batch_size, seq_length, head_num, size_per_head](對應 .view(batch_size, -1, self.h, self.d_k))->[batch_size, head_num, seq_length, size_per_head](對應.transpose(1, 2))。
而對于FP16模式,FasterTransformer是啟動 batch_size *seq_len 個 Block,,每個 Block 里面啟動 head_num *size_per_head 個線程同時處理QKV的同一個token(對應head_num * size_per_head次計算)并使用了half2相關的數學函數。這樣不僅僅可以達到2倍于half的訪存帶寬和計算吞吐,還可以極大地減少指令的發射數量。
高效的softmax kernel
這里我沒有怎么看,因為oneflow已經有一個比FasterTransformer更好的softmax kernel實現了。
transpose kernel
這個 kernel 是對應上面 BERT 的 Encoder 部分的:
x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.h * self.d_k)
這里的 x 的 shape 仍然和之前的 q 的 shape 一致, 為[batch_size, head_num, seq_length, size_per_head]。因為Attetion 層不會改變輸入的形狀,因為 Attention 的計算過程是:q *k 轉置(.transpose(2, 3)),除以 d_k **0.5,輸出維度是 [b, head_num , seq_length, seq_length] 即單詞和單詞直接的相似性 ,然后對最后一個維度進行 softmax 操作得到 [b, head_num, seq_length, seq_length] , 最后和 v(shape 也是 [batch_size, head_num, seq_length, size_per_head]) 做一個矩陣乘法,結果的 shape 和輸入的 shape 形狀都是:[batch_size, head_num, seq_length, size_per_head] 。因此這里的 x.transpose(1, 2) 就是把 shape 為 [batch_size, head_num, seq_length, size_per_head] 的 x 重新排列為 [batch_size, head_num, size_per_head, seq_length]。然后 x.contiguous().view(batch_size, -1, self.h *self.d_k) 進一步將 shape 重新排列為 [batch_size, seq_length, head_num * size_per_head] 。
對于 FP32 模式,啟動 batch_size *head_num *seq_length 個 Block , 然后每個 Block 啟動 size_per_head 個線程處理一個序列(一個序列對應 size_per_head 個元素)。如下:
const int seq_per_block = 1; grid.x = batch_size * head_num * seq_len / seq_per_block; block.x = seq_per_block * size_per_head; transpose
而 transpose 的kernel實現也比較簡單,根據blockIdx.x計算下batch_id和seq_id以及head_id(輸入 x 的 shape 為 [batch_size, head_num, seq_length, size_per_head]):
`template
global
void transpose(T* src, T* dst, const int batch_size, const int seq_len, const int head_num, const int size_per_head)
{
int batch_id = blockIdx.x / (head_num * seq_len);
int seq_id = blockIdx.x % seq_len;
int head_id = (blockIdx.x % (head_num * seq_len))/ seq_len;
dst[batch_id * (head_num * seq_len * size_per_head) + seq_id * head_num * size_per_head
head_id * size_per_head + threadIdx.x] = src[blockIdx.x * size_per_head + threadIdx.x];
}
`
對于 half 來說,采用和 add_QKV_bias 一樣的優化方式,每個 block 處理 4 個sequence。具體來說,就是現在啟動 batch_size *head_num *seq_len / 4 個 Block, 每個 Block 使用 2 *size_per_head 個線程處理 4 個序列。為什么 2 *size_per_head 個線程可以處理 4 個序列(一個序列對應 size_per_head 個元素),原因是因為使用了 half2 來做數據讀取。half 類型的 kernel 實現如下:
` inline device
int target_index(int id1, int id2, int id3, int id4, int dim_1, int dim_2, int dim_3, int dim_4)
{
return id1 * (dim_2 * dim_3 * dim_4) + id3 * (dim_2 * dim_4) + id2 * dim_4 + id4;
}
template<>
global
void transpose(__half* src, __half* dst,
const int batch_size, const int seq_len, const int head_num, const int size_per_head)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int batch_id = tid / (head_num * seq_len * size_per_head);
int head_id = (tid % (head_num * seq_len * size_per_head)) / (seq_len * size_per_head);
int seq_id = (tid % (seq_len * size_per_head)) / size_per_head;
int id = tid % size_per_head;
int target_id = target_index(batch_id, head_id, seq_id, id, batch_size, head_num, seq_len, size_per_head);
half2 * src_ptr = (half2* )src;
half2 * dst_ptr = (half2* )dst;
dst_ptr[target_id] = src_ptr[tid];
}
`
trt_add_QKV_bias 和 TensorRT fused multi-head attention kernel
實際上從 Figure1 也可以看出我們上面講到的 batch GEMM,softmax, GEMM,transpose 等操作都可以被合成一個超大的 cuda kernel,進一步進行優化,也就是這里的 TensorRT fused multi-head attention kernel。這個是將 TensorRT 的這個插件作為第三方倉庫引入到 FasterTransformer 進行加速的,具體的代碼我沒有研究過,這里就不展開了。
現在 MultiHeadAttention 部分涉及到的優化其實就講完了,我們接著看一下FasterTransformer 對 BERT Encoder 的其它部分的優化。我們這里貼一下 Transformer 的結構圖:

在 MultiHeadAttention 的后面接了一個 Add & Norm,這里的 Add 其實就是殘差,Norm 就是 LayerNorm。所以 Encoder 部分的兩個 Add & Norm 可以總結為:

add_bias_input_layernorm
對于 softmax 和 layernorm 我還沒看 FasterTransformer 的源碼,后續研究了之后再分享。
總的來說就是 add_bias_input_layernorm 這個優化把殘差連接和LayerNorm fuse到一起了,性能更好并且降低了kernel launch的開銷。
add_bias_act
在上圖的 Feed Forward 的實現中,還有一個 bias_add 和 gelu 激活函數挨著的 pattern ,所以 FasterTransformer 實現了這個 add_bias_act kernel 將兩個操作融合起來,常規操作。
-
編碼器
+關注
關注
45文章
3664瀏覽量
135051 -
gpu
+關注
關注
28文章
4768瀏覽量
129217 -
CUDA
+關注
關注
0文章
121瀏覽量
13656
發布評論請先 登錄
相關推薦
Faster Transformer v2.1版本源碼解讀
請問encoder的數據是記錄在PLC中還是記錄在encoder中?

DC-DC電源系統的優化設計總結

鼠標滾輪/編碼器檢測- wheel/encoder detect for mouse
NVIDIA FasterTransformer庫的概述及好處
Gowin MJPEG Encoder IP用戶指南
總結FasterTransformer Encoder(BERT)的cuda相關優化技巧
FasterTransformer GPT介紹
STM32 Encoder編碼器使用總結





 工商網監
工商網監
評論