

轉自:中國指揮與控制學會(本文系《指揮與控制學報》刊文精選) 作者:林萌龍陳濤任棒棒張萌萌陳洪輝
摘要
為了應對在未來復雜的戰場環境下,由于通信受限等原因導致的集中式決策模式難以實施的情況,提出了一個基于多智能體深度強化學習方法的分布式作戰體系任務分配算法,該算法為各作戰單元均設計一個獨立的策略網絡,并采用集中式訓練、分布式執行的方法對智能體的策略網絡進行訓練,結果顯示,經過學習訓練后的各作戰單元具備一定的自主協同能力,即使在沒有中心指控節點協調的情況下,依然能夠獨立地實現作戰任務的高效分配。
馬賽克戰[1]、聯合全域指揮控制[2]等新型作戰概念所構想的未來作戰場景中,傳統的多任務平臺被分解為了眾多的小型作戰單元,這些小型作戰單元通常具備更高的靈活性,能夠根據戰場環境的變化快速對自身所承擔的任務進行調整,以實現更好的整體作戰效果。在未來的新型作戰場景中,傳統的集中式指揮控制模式存在著指揮鏈路過長、決策復雜度過高等問題,從而導致決策時效性和決策質量難以滿足要求[3]。近年來,邊緣指揮控制等新型指控模式應運而生,邊緣節點也即各作戰實體將具備一定程度的自主決策能力[4]。由于戰場環境的復雜多變特性,以及作戰實體的小型化、智能化發展趨勢,分布式決策的模式將在未來的戰場決策中發揮越來越重要的作用。
作戰體系是為了完成特定的作戰任務由一系列具備各項能力的作戰單元動態構建而成,在以往的集中式決策模式下,體系設計人員會根據作戰任務的能力需求以及作戰單元所具備的各項能力,以最大化作戰效能或最小化作戰單元的使用成本等為目標,來統一地對各作戰任務和作戰單元進行匹配。作戰體系的“作戰任務—作戰單元”匹配問題可以建模為一個優化問題,當問題規模較小時可以采用集中式決策的模式運用整數線性規劃等運籌學方法快速得到全局最優解[5],而當問題規模較大時可以采用遺傳算法等啟發式算法[6]或者強化學習算法[7]得到問題的近似最優解。采用集中式決策的一個重要前提條件是中心決策節點和作戰單元葉節點之間的通信暢通,因為葉節點需要將自身的狀態信息和觀測信息發送給中心決策節點,而中心節點需要將決策命令等發送給葉節點。然而在未來的作戰場景中,由于敵方的通信干擾等原因,中心節點和葉節點之間的通信鏈接很難保證連續暢通,同時頻繁的信息交互會造一定的通信負載和通信延遲,因此在未來很多的任務場景中需要作戰單元根據自身的狀態信息和觀測到的信息獨立地進行決策。
強化學習是一種利用智能體與環境的交互信息不斷地對智能體的決策策略進行改進的方法,隨著深度強化學習技術的快速發展,強化學習算法在無人機路徑規劃[8]、無線傳感器方案調度[9]等領域都取得了非常成功的應用,同時近年來多智能體強化學習算法在StarCraftⅡ[10]等環境中也取得了很好的效果。在作戰體系任務分配的場景中,可以將各作戰單元視為多個決策智能體,那么“作戰任務—作戰單元”的匹配任務就可以視為一個多智能體強化學習任務。而當前尚未有將多智能體強化學習方法應用到類似作戰體系的任務分配環境中的先例。本文的主要工作如下:
1) 建立一個通信受限情況下的作戰體系“作戰任務—作戰單元”匹配的任務場景。
2) 提出了一個基于多智能體強化學習技術的作戰體系任務分配算法。
3) 通過實驗驗證了采用上述算法訓練的各智能體可以在通信受限的場景下實現一定程度的自主協同,在沒有中心決策節點的情況下依然能夠實現作戰體系任務的有效分配。
1背景
1.1集中式決策VS分布式決策
集中式決策模式下存在一個中心決策節點來負責全局的任務決策,如圖1所示,各作戰單元通過通信鏈接將自身的狀態信息和觀測信息發送給中心決策節點,中心決策節點進行全局的決策后將決策命令發送給各作戰單元去執行。與集中式決策不同,分布式決策模式下將不存在一個中心決策節點來協調各實體間的行動,而是由各實體根據自身所擁有的信息,獨立地進行決策。采用分布式決策一般是為了應對兩種情形,一種是采用集中式決策需要考慮的要素過多,決策復雜度過大難以進行有效的決策,另一種是由于決策節點與葉節點之間的通信受限或通信成本過高難以進行有效的通信,導致各葉節點需要獨立地進行決策。
集中式決策具有分析簡單、可靠性高等優點,然而并不是所有的決策問題都適合采用集中式決策,例如在有些任務場景中不具備進行集中式決策的通信條件或者通信成本過高。在分布式系統中,如果不存在中心節點進行全局協調,那么該分布式系統就被稱為是自適應系統[11],自適應系統是各個子模塊根據有限的自身感知和一些預定的規則,獨立地進行思考、決策并采取相應的動作,共同完成分布式系統的任務。典型的狼群系統、蟻群系統都屬于自適應系統,傳統的自適應系統大多采用基于規則的方法進行研究,但是這些規則的制定往往需要領域專家進行深度參與,并且是一個不斷試錯的過程。
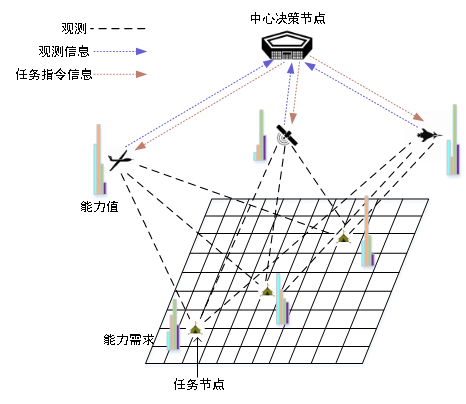
圖1集中式決策示意圖
Fig. 1 Centralized decision diagram
強化學習作為一種端到端(End-to-end)的學習訓練方法不需要領域專家的過多參與而是通過智能體與環境的動態交互來不斷改進自身的決策策略。采用強化學習方法來解決分布式決策問題已經在多個領域得到了成功應用,在定向傳感器最大目標覆蓋問題(Maximum Target Coverage)中,Jing Xu等將該問題抽象為一個兩層決策問題,其中上層決策為各傳感器分配檢測目標,下層決策為各傳感器調整角度,之后每層決策問題均使用單智能體強化學習算法來進行求解,實驗結果表明該方法能有效解決定向傳感器最大目標覆蓋問題[12];Sykora基于圖神經網絡和注意力機制提出了一個用來解決多車輛路徑規劃問題(Multi Vehicle Routing Problem, MVRP)的深度神經網絡模型,并采用強化學習方法對模型進行訓練,該模型包含一個價值迭代模塊和通信模塊,各車輛根據自身觀測信息和通信信息獨立進行決策,結果顯示該模型可以有效解決MVRP問題[13]。
1.2多智能體強化學習
強化學習技術已經在多個領域得到了成功應用,并取得了非常顯著的效果,包括Atari游戲[14]、圍棋[15]等,然而上述場景多針對的是單個智能體在靜態環境中的應用,而現實中的很多場景都是多個智能體在動態環境中的應用,涉及到智能體間的復雜交互。與單個智能體強化學習任務相比,多智能體強化學習任務需要同時對多個智能體的策略進行優化,優化難度顯著增強,總結來看,多智能體強化學習任務主要在以下幾個方面與單智能體強化學習任務存在顯著區別:
1)觀測范圍的變化。在單智能體強化學習所解決的馬爾可夫決策過程(Markov decision problem,MDP)中,通常假定的是環境是完全可觀測的,智能體直接從環境那里獲得全局的狀態信息;而多智能體強化學習任務通常被建模為部分可觀測馬爾可夫決策過程(partially observable Markov decision problem,POMDP),智能體不再擁有全局視野而是根據一個觀測函數從全局狀態中得到自身的觀測數據。部分可觀測的假定與現實世界中的場景更加契合,但同時也增加了模型訓練的難度。
2)環境的不穩定特性(Non-Stationarity)。多智能體強化學習的一個重要特點就是各智能體通常是同時進行學習的,導致每個智能體所面臨的環境是非靜止的,因此導致了環境的不穩定特性。具體地說就是一個智能體所采取的行動會影響其他智能體所能獲得的獎勵以及狀態的變化。因此,智能體在進行學習時需要考慮其他智能體的行為。環境的不穩定特性違背了單智能體強化學習算法中環境狀態的馬爾科夫特性,即個體的獎勵和當前狀態只取決于之前的狀態和所采取的行動,這也就使得在多智能體強化學習任務中使用傳統的單智能體強化學習算法可能會存在算法難以收斂等問題。
多智能體強化學習的相關研究已經成為了機器學習領域的一個研究熱點,其中,獨立Q學習算法(Independent Q-Learning, IQL)[16]是最早應用于多智能體強化學習任務的算法之一,IQL算法為每一個智能體都設置一個Q價值函數,并進行獨立的訓練,由于將其他的智能體視為環境中的一部分,而其他智能體又是在不斷學習進化的,導致了環境的不穩定性,因此當智能體的數量超過兩個時IQL算法的性能表現通常較差。
近來有很多研究采用集中式訓練和分散式執行的模式來解決多智能體強化學習任務,有很多研究采用Actor-Critic算法來訓練模型,其中Critic網絡在訓練階段可以利用全局的狀態信息來輔助Actor網絡的訓練,而在模型執行階段,智能體的Actor網絡再根據自身的觀測信息獨立地做出動作選擇。例如Lowe提出的多智能體深度深度確定性策略算法(multi-agent deep deterministic policy gradient, MADDPG)算法[17]為每一個智能體都提供一個集中式的Critic網絡,這個Critic網絡可以獲得所有智能體的狀態和動作信息,然后采用深度確定性策略算法(deep deterministic policy gradient, DDPG)訓練智能體的策略網絡。Foerster提出的基準多智能體算法(counterfactual multi-agent, COMA)[18]也采用一個集中式的Critic網絡,此外還設計了一個基準優勢函數(counterfactual advantage function)來評估各智能體對總體目標的貢獻程度,以此解決多智能體任務的信用分配(credit assignment)問題。Sunehag提出的價值分解網絡算法(value-decomposition networks, VDN)[19]將集中式的狀態-動作價值函數分解為各智能體的價值函數之和,然而該方法是假定多智能體系統的總體價值函數可以用各智能體的價值函數之和來進行表示,然而在大多數的任務場景中該約束條件并不能得到滿足,因此限制了該方法的適用范圍。針對VDN模型所存在的問題,Rashid提出的Q-Mix算法[20]在此基礎上進行了改進,去除了集中式critic網絡的價值函數相加性要求,而只是對各智能體的狀態-動作價值函數施加了單調性約束。
2問題描述
作戰體系是為了完成特定的使命任務而動態建立的。通常,作戰體系的使命任務可以分解為一系列的子任務,而每項子任務的實現又都需要一系列能力的支持,同時不同類型的任務對能力的需求也不同,例如對敵方目標的打擊任務所需要的火力打擊能力的支持較多,而對敵方目標的偵察任務所需要的偵察能力支持較多。在通常情況下,體系設計人員會根據己方的任務能力需求,以及自身所擁有的作戰單元所能提供的能力值來為各作戰任務分配合適的作戰資源,這是一種集中式的決策方法。集中式決策的方法的優點是可以獲取全局信息,能根據已有的信息對整體做出合理的決策,集中式決策的方法通常能得出全局最優解。然而隨著馬賽克戰等新型作戰概念的應用,未來的戰場環境下,由于敵方的通信干擾等因素,以及決策時效性的要求等原因,傳統的集中式決策的方式可能難以實現,因此需要根據各作戰單元根據戰場環境和自身狀態信息獨立地進行決策。由集中式決策向分布式決策方式的轉變也更加符合邊緣作戰等新型作戰場景的構想,邊緣節點將具備更高的自主決策權,可以更加獨立地根據戰場環境的狀態調整自身的動作。
2.1場景描述
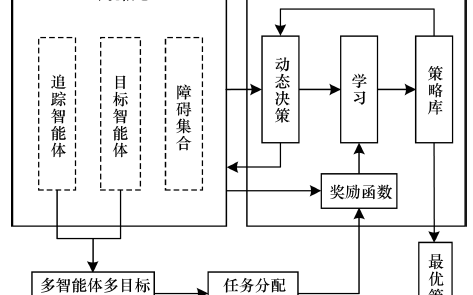
在一個通信受限的聯合作戰場景中,如圖2所示,幾個作戰單元分別位于戰場空間中的不同位置,每個作戰單元都具備一定的能力,由于通信受限,作戰單元不能與中心決策節點進行有效通信,而各實體間只能進行有限的通信或者不能通信,因此在進行決策時每個作戰單元都只能根據自身所能獲取到的信息獨立地進行決策。這種分布式的決策方式可能會帶來一系列的問題,例如由于沒有中心決策節點來協調任務分配,各實體在進行獨立決策時可能會出現多個作戰單元都選擇去完成同一個任務,從而造成某些任務沒有作戰單元來完成的現象。因此我們希望能夠利用多智能體強化學習技術,來為每一個作戰單元都訓練出來一個能夠進行獨立的分布式決策的策略網絡,并且根據這些策略網絡得到的智能體策略能夠實現一定程度上的自協同。
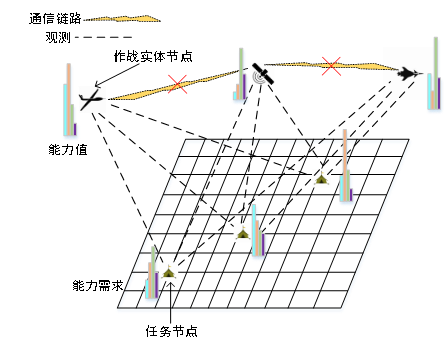
圖2分布式決策場景下的體系任務分配
Fig. 2 SoS task assignment in decentralized decision
2.2 狀態空間、動作空間與獎勵函數設計
上述場景中的作戰單元的決策過程可以被建模為一個部分可觀測的馬爾可夫決策過程。場景中的每一個作戰單元都可以被視為一個決策智能體,智能體的狀態空間也即觀測空間包含自身的位置信息和能力值信息、其他智能體的位置信息,以及任務節點的位置信息和能力需求信息。智能體的動作是選擇哪一個任務節點作為自己的目標節點,因此智能體的動作空間是離散的。
在利用強化學習解決此類優化問題時,優化目標函數的取值通常就可以作為強化學習中智能體的獎勵值,因此確定優化問題目標函數的過程也就是確定強化學習獎勵函數的過程。在上述作戰體系的任務分配場景中,體系任務分配的目標是體系中所有的任務節點都被分配了合適的作戰單元來完成,因此該場景是一個合作型的多智能體強化學習任務,各智能體共享一個相同的獎勵值,相關獎勵函數的設計可以根據任務節點的覆蓋程度以及任務的完成效果來進行設計:
1)如果有任意一個任務節點沒有被分配作戰單元來完成,那么獎勵值-5,任務節點的覆蓋程度越低,則智能體所獲得的獎勵值越低。
2)任務完成的效果可以根據作戰單元與任務節點的距離以及作戰單元的能力取值與任務實體的能力需求的匹配程度來確定。作戰單元與任務節點的距離越小,任務完成的時效性越高,智能體獲得的獎勵值相應也越高,同時任務節點的能力需求與作戰單元所能提供的能力值匹配度越高,則任務完成的效果越好,相應地智能體所能獲得的獎勵值越多。
智能體所包含的信息可以用一個元組進行表示其中表示智能體當前所處的位置坐標,則表示智能體在能力上的取值,n為能力類型的數量。同時任務節點包含的信息也可以用一個元組來表示,表示任務節點的位置坐標,表示任務節點對能力1的需求。那么智能體i與任務節點j之間的距離可以根據兩者的坐標計算得到,如式所示,智能體與任務節點j的能力匹配值也可以根據式計算得到,其中表示能力匹配系數。對于任意一項能力來說,智能體i所能提供的能力值與任務節點j的能力需求值之間的比值越大說明采用智能體來完成任務在該項能力上取得的效果越好,將各項能力的效果進行累加,可以得到完成該任務的整體效果評估結果,累加得到的取值越大,則該項任務的整體完成效果越好;同時我們考慮如果智能體所提供的所有能力值都大于該任務節點的需求值那么表示該任務節點的所有需求都得到了較好的滿足,則我們將上述累加得到的匹配值乘以一個系數,而如果有一項智能體所提供的能力值小于任務節點的需求值,則認為任務節點的需求沒有得到很好的滿足,因此我們將上述累加得到的匹配值乘以一個系數,如式3所示。

在上述作戰體系任務分配場景中,所有的智能體共享同一個獎勵值,各智能體的決策目標就是使得該獎勵值最大化。
3基于MADDPG算法的作戰體系任務分配模型
依據生成數據的策略和進行評估的策略是否相同,強化學習算法可以分為在線(on-policy)算法和離線(off-policy)算法,on-policy算法例如優勢動作評論算法(Advantage Actor Critic, A2C)、置信域策略優化算法(Trust Region Policy Optimization, TRPO)中用于生成數據的策略和進行評估的策略是相同的,每個批次用于評估的數據都是由當前最新的策略網絡新生成的并且數據用完就丟棄,而off-policy算法例如DDPG算法、軟演員-評論家算法(Soft Actor-Critic, SAC)算法則是將智能體每次與環境的交互數據存放在一個名為經驗回放池(replay buffer)的結構中,模型每次進行訓練時就從數據經驗回放池中取出一定數量的訓練樣本進行參數更新。由于采用經驗回放機制在每次訓練時是隨機抽取不同訓練周期的數據,因此可以消除樣本之間關聯性的影響,同時在強化學習任務中,訓練交互數據通常是比較寶貴的,如果每條數據只能被利用一次則是對訓練數據的嚴重浪費,采用經驗回放機制還能夠提高樣本的利用效率,加快模型的訓練速度,尤其是在多智能體的強化學習訓練任務中,各智能體與環境的交互數據更顯寶貴,因此在多智能體強化學習中多采用off-policy算法進行模型訓練,例如著名的MADDPG算法及其諸多變種都屬于多智能體領域的off-policy強化學習算法。
但是經典的MADDPG算法并不能直接應用到體系的“作戰任務—作戰單元”匹配任務中來,主要是兩個原因,一個是MADDPG算法是專門為連續動作空間任務所設計的,而體系的任務分配場景中各智能體都是離散型的動作空間,因此需要對算法進行一定的修改使得修改后的算法可以應用于離散型動作空間的問題;另一個原因是當前MADDPG算法所解決的問題都是多步決策問題,也即每個智能體最后輸出的是一個動作序列,這樣在進行網絡參數訓練時智能體就可以利用數據組進行梯度計算,而我們的體系“作戰任務—作戰單元”匹配任務是屬于單步決策問題每個智能體最終輸出的動作只有一個而非一個序列,智能體所生成的訓練數據組為缺少了智能體的下一步狀態,因此需要對智能體的策略網絡和價值網絡的損失函數計算方法進行一定的修改,使得該方法可以應用到單步決策問題中來。
MADDPG算法是用來解決連續動作空間的強化學習任務的,當智能體的動作空間是離散時,通常采用的是利用argmax函數來將值最大的節點作為具體的策略節點輸出,但是由于argmax函數不滿足多元函數連續且具有偏導數的條件,因此argmax函數是不可導的,這樣神經網絡就無法計算梯度并采用反向傳播的機制進行參數學習,此外argmax函數的輸出不具備隨機性,函數的輸出每次都是將最大值的節點輸出,忽略了該數據作為概率的屬性。采用Gumbel-softmax方法可以根據輸入向量生成一組離散的概率分布向量[21],以此來解決上述問題。
采用Gumbel-softmax方法生成離散的概率分布向量的算法流程如下所示。

3.1基于MADDPG任務分配算法框架

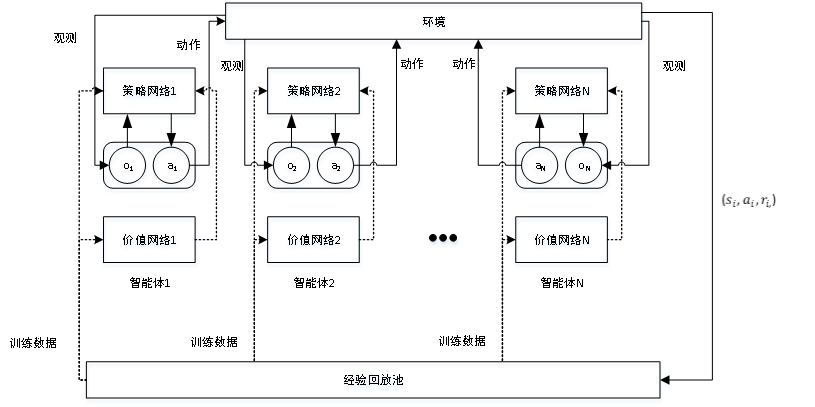
圖3基于MADDPG的體系任務分配算法框架
Fig. 3 SoS task assignment algorithm based on MADDP
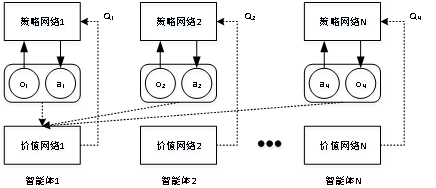
圖4集中式訓練的模型框架
Fig. 4 Centralized training model framework
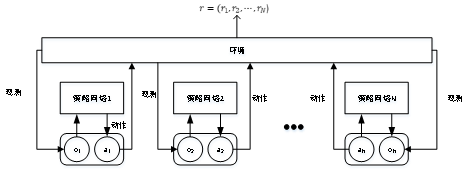
圖5分布式執行的模型框架
Fig. 5 Decentralized execution model framework
3.2 Actor網絡結構
智能體的策略網絡結構如圖6所示,智能體的策略網絡的輸入是該智能體的觀測信息,包含智能體自身的位置信息、狀態信息、其他智能體相對于智能體的位置距離以及任務節點的位置信息和能力需求信息,輸入信息經過多層神經網絡處理后輸出一個維度為任務節點個數的向量,之后經過Gumbel-softmax方法處理后得到各任務節點的選擇概率,最后選擇概率最大的節點作為智能體在觀測信息為時的動作選擇結果。

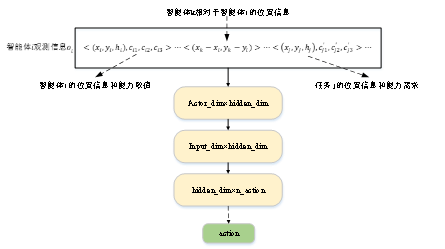
圖6Actor網絡結構
Fig. 6 Actor network structure
3.3Critic網絡結構
智能體的價值網絡結構如圖7所示,智能體的價值網絡的輸入包含所有智能體的觀測信息o=(o1,o2,...on)和動作選擇信息a=(a1,a2,....an),同樣的,策略網絡的輸入信息經過多層神經網絡處理后輸出一個維度為1的向量,該向量的取值就是個各智能體在觀測信息為o且動作選擇結果為a時的獎勵估計值。
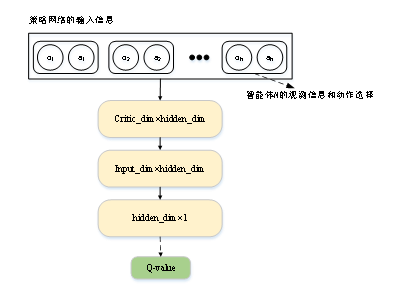
圖7Critic網絡結構
Fig. 7 Critic network structure
基于MADDPG的體系任務分配算法如算法1所示。當模型訓練完成后,各智能體就可以獨立地根據自身的觀測信息對體系任務進行高效的分配。
4實驗
4.1對比算法設置
為了驗證集中式訓練模式下的多智能體強化學習算法在分布式決策環境下,面對體系“作戰任務—作戰單元”匹配任務時的有效性,我們選擇分布式訓練的多智能體強化學習算法作為對比算法。集中式訓練的多智能體強化學習算法與分布式訓練的智能體強化學習算法最大的不同就是,集中式訓練的多智能體強化學習算法是采用集中式訓練分布式執行的模式,智能體的價值網絡在訓練階段可以獲取全局狀態信息來輔助智能體策略網絡的訓練;而分布式訓練的多智能體強化學習算法則是采用分布式訓練分布式執行的模式,各智能體都將其他智能體視為環境的一部分,無論是在模型訓練階段還是模型執行階段都是獨立的根據自身的觀測信息進行獨立決策。
4.2實驗環境
本文設計了一個通信受限條件下的體系“任務—作戰單元”匹配的任務場景,在該任務場景中,我們設計體系中擁有相同數量的作戰單元節點和作戰任務節點,各作戰單元和作戰任務節點分別位于場景中一個隨機生成的位置上,該位置的坐標在范圍內隨機生成,此外每個作戰單元都擁有三種類型能力,各能力的取值采用均勻分布的形式在一定的數據范圍內隨機生成,同樣的每個任務目標也有一定的能力需求對應于作戰單元所能提供的三種能力,任務目標的能力需求也采用均勻分布的形式在一定的數據范圍內隨機生成。由于敵方通信干擾等因素的影響,各作戰單元間不能進行通信,同時場景中也不存在一個中心決策節點來協調各作戰單元的決策,因此各作戰單元需要根據自身的狀態信息和觀測信息獨立地進行決策,決策內容是選擇哪一個任務目標作為自己的目標節點。由于我們所設計的體系任務分配場景屬于是合作型的任務,各作戰單元希望通過合作達到體系總體決策效果最優,因此我們將各作戰單元的任務分配整體效果作為各智能體的獎勵值。
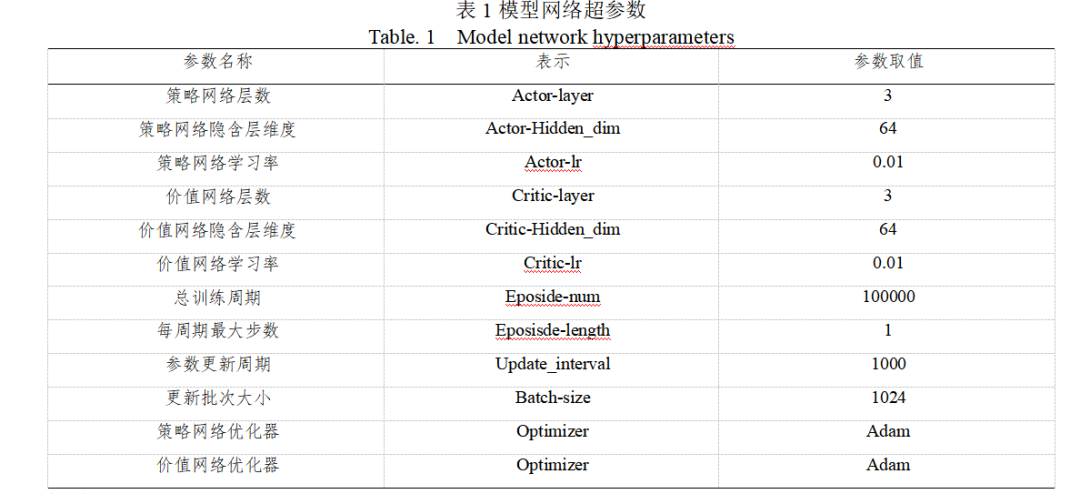
所有算法都采用Python進行實現,并在同一臺配置了Geforce RTX3090顯卡、Intel 16-Core i9-11900K CPU的計算機上運行。基于集中式訓練模式下的多智能體強化學習算法的體系任務分配模型網絡主要超參數如表1所示,為了保證一致,對比算法采用相同的網絡參數。
4.3 實驗結果分析
集中式訓練的多智能體強化學習算法和分布式訓練的多智能體強化學習算法在解決體系的“任務—作戰單元”匹配任務時的模型訓練曲線如圖8和圖9所示,橫坐標表示訓練的回合數,縱坐標表示智能體得到的平均獎勵值。可以看到,隨著訓練進程的推進,采用集中式訓練的多智能體強化學習算法進行訓練的智能體所得到的獎勵值不斷增大,最終穩定在0.6左右的水平,曲線收斂。在模型訓練剛開始的時候,智能體所得到的獎勵值是小于0的,也就是智能體還沒有學會與其他智能體進行任務協同分配,導致體系的任務分配出現有的任務被多個智能體選擇而有的任務沒有被選擇的現象,而隨著訓練進程的推進,由于環境反饋作用的影響,智能體逐漸學會了與其他智能體進行任務協同分配,即使在沒有中心決策節點進行協調的情況下,各智能體依然能夠根據自身的狀態信息和觀測到的信息采用分布式決策的方式獨立地做出使得體系的效能最大的任務分配方案。相對應地,采用分布式訓練的多智能體強化學習算法得到的獎勵值始終為負數,表示智能體沒有學會上述任務協同分配策略,隨著訓練進程的推進,各智能體沒有學會如何與其他智能體合作任務分配,主要原因是分布式訓練模式下的多智能體強化學習算法中智能體是將其他智能體視為環境的一部分,由于智能體的決策策略是在不斷改進變化的從而導致了環境的不穩定性,而采用集中式訓練分布式執行模式的多智能體強化學習算法在一定程度上緩解了環境不穩定性所帶來的影響。從上述實驗結果來看,采用集中式訓練分布式執行模式的多智能體強化學習算法來訓練智能體在通信受限的場景下進行分布式決策是有效的。
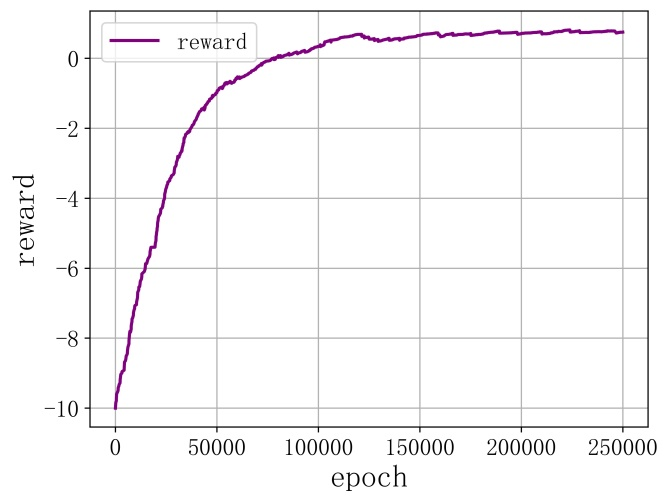
圖8集中式訓練的多智能體強化學習算法訓練的智能體平均獎勵曲線
Fig. 8 Meanreward curve of agent trained by centralized training multi-agent reinforcement learning algorithm
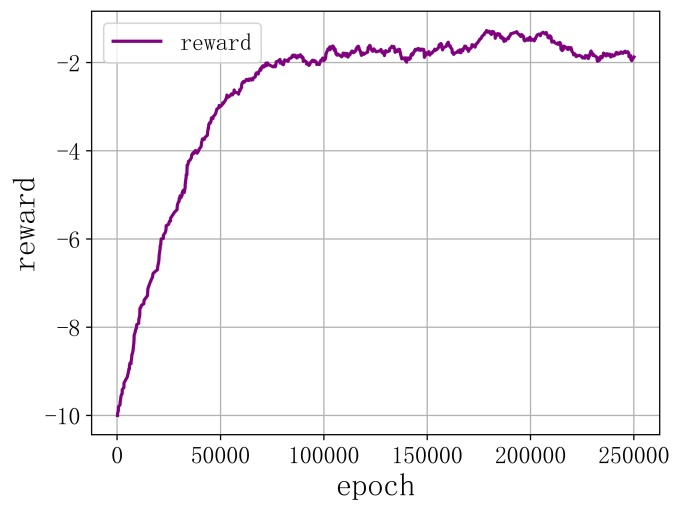
圖9分布式訓練的多智能體強化學習算法訓練的智能體平均獎勵曲線
Fig. 9 Meanreward curve of agent trained by decentralized training multi-agent reinforcement learning algorithm
5結論
隨著軍事裝備的快速發展,以及戰場環境的復雜多變,傳統的集中式決策模式越來越難以適應未來戰爭的需求,邊緣作戰單元根據自身的狀態信息和觀測信息獨立地進行決策將更加常見。
本文設計了一個在通信受限的場景下,作戰體系的“任務—作戰單元”匹配地體系設計任務,并基于多智能體強化學習技術,提出了一個基于MADDPG算法的體系任務分配模型,該模型針對體系設計場景中的離散動作空間以及單步決策等問題進行了相應改進,并采用集中式訓練和分布式執行的模式,在模型訓練階段各智能體的價值網絡將能夠獲取全局狀態信息來輔助策略網絡的訓練,而在模型運行階段各智能體只需要根據自身的觀測信息就能快速獨立地進行決策。實驗結果顯示,與分布式訓練的多智能體強化學習算法相比,采用集中式訓練的多智能體強化學習算法訓練出來的各智能體在進行分布式決策時具備更高的協同能力,所做出的體系任務分配方案效率更高。
審核編輯:湯梓紅
-
通信
+關注
關注
18文章
6140瀏覽量
137126 -
函數
+關注
關注
3文章
4363瀏覽量
63775 -
強化學習
+關注
關注
4文章
269瀏覽量
11466 -
任務分配
+關注
關注
0文章
10瀏覽量
2172 -
深度強化學習
+關注
關注
0文章
14瀏覽量
2370
原文標題:基于多智能體深度強化學習的體系任務分配方法
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是深度強化學習?深度強化學習算法應用分析

有人機/無人機的任務分配方法設計研究
將深度學習和強化學習相結合的深度強化學習DRL
多智體深度強化學習研究中首次將概率遞歸推理引入AI的學習過程
基于混沌量子粒子群緊急任務分配方法

語言模型做先驗,統一強化學習智能體,DeepMind選擇走這條通用AI之路






 工商網監
工商網監

評論