

在智能體的開發中,強化學習與大語言模型、視覺語言模型等基礎模型的進一步融合究竟能擦出怎樣的火花?谷歌 DeepMind 給了我們新的答案。
一直以來,DeepMind 引領了強化學習(RL)智能體的發展,從最早的 AlphaGo、AlphaZero 到后來的多模態、多任務、多具身 AI 智能體 Gato,智能體的訓練方法和能力都在不斷演進。
從中不難發現,隨著大模型越來越成為人工智能發展的主流趨勢,DeepMind 在智能體的開發中不斷嘗試將強化學習與自然語言處理、計算機視覺領域融合,努力實現不同模態任務的統一。Gato 很好地說明了這一點。
近日,谷歌 DeepMind 在一篇新論文《Towards A Unified Agent with Foundation Models》中,探討了利用基礎模型打造統一的智能體。

一作 Norman Di Palo 為帝國理工學院機器學習博士生,在谷歌 DeepMind 實習期間(任職研究科學家)參與完成本論文。
論文地址:https://arxiv.org/pdf/2307.09668.pdf
何謂基礎模型(Foundation Models)呢?我們知道,近年來,深度學習取得了一系列令人矚目的成果,尤其在 NLP 和 CV 領域實現突破。盡管模態不同,但具有共同的結構,即大型神經網絡,通常是 transformer,使用自監督學習方法在大規模網絡數據集上進行訓練。
雖然結構簡單,但基于它們開發出了極其有效的大語言模型(LLM),能夠處理和生成具有出色類人能力的文本。同時,ViT 能夠在無監督的情況下從圖像和視頻中提取有意義的表示,視覺語言模型(VLM)可以連接描述語言中視覺輸入或將語言描述轉換為視覺輸出的數據模態。
這些模型的規模和能力使社區創造出了「基礎模型」一詞,這些模型可以用作涵蓋各種輸入模態的下游任務的支柱。
問題來了:我們能否利用(視覺)語言模型的性能和能力來設計更高效和通用的強化學習智能體呢?
在接受網絡規模的文本和視覺數據訓練后,這些模型的常識推理、提出和排序子目標、視覺理解和其他屬性也出現了。這些都是需要與環境交互并從環境中學習的智能體的基本特征,但可能需要花費大量的時間才能從反復試錯中顯現出來。而利用存儲在基礎模型中的知識,我們能夠極大地引導這一過程。
受到這一思路的啟發,谷歌 DeepMind 的研究者設計了一個全新的框架,該框架將語言置于強化學習機器人智能體的核心,尤其是在從頭開始學習的環境中。
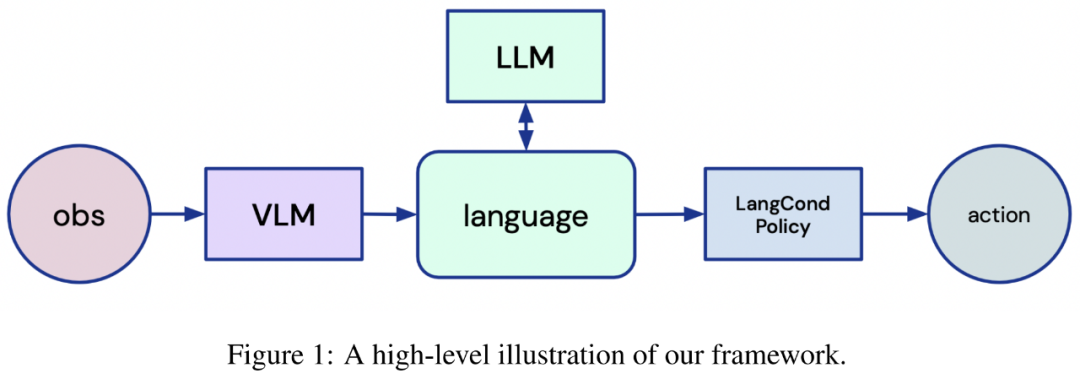
圖 1:框架示意圖。
他們表示,這個利用了 LLM 和 VLM 的框架可以解決強化學習設置中的一系列基礎問題,具體如下:
1)高效探索稀疏獎勵環境
2)重新使用收集的數據來有序引導新任務的學習
3)調度學得的技巧來解決新任務
4)從專家智能體的觀察中學習
在最近的工作中,這些任務需要不同的、專門設計的算法來單獨處理,而本文證明了利用基礎模型開發更統一方法的可能性。
此外,谷歌 DeepMind 將在 ICLR 2023 的 Reincarnating Reinforcement Learning Workshop 中展示該研究。
以語言為中心的智能體框架
該研究旨在通過分析基礎模型的使用,設計出更通用的 RL 機器人智能體,其中基礎模型在大量圖像和文本數據集上進行預訓練。該研究為 RL 智能體提出了一個新框架,利用 LLM 和 VLM 的出色能力使智能體能夠推理環境、任務,并完全根據語言采取行動。
為此,智能體首先需要將視覺輸入映射到文本描述;然后該研究要用文本描述和任務描述 prompt LLM,以向智能體提供語言指令。最后,智能體需要將 LLM 的輸出轉化為行動。
使用 VLM 連接視覺和語言
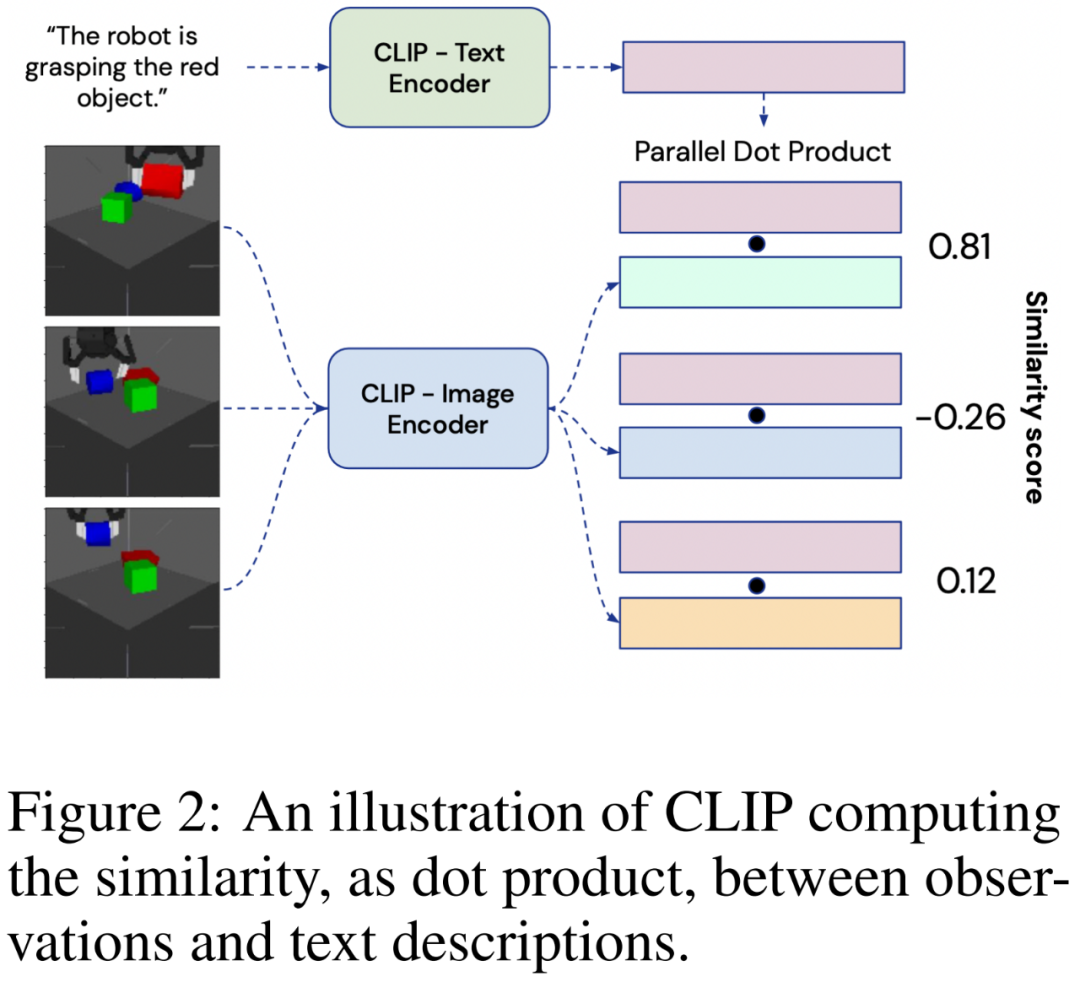
為了以語言形式描述從 RGB 相機獲取的視覺輸入,該研究使用了大型對比視覺語言模型 CLIP。
CLIP 由圖像編碼器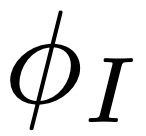 和文本編碼器
和文本編碼器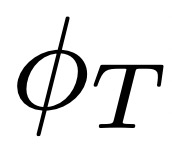 組成,在含有噪聲的大型圖像 - 文本描述對數據集上進行訓練。每個編碼器輸出一個 128 維的嵌入向量:圖像嵌入和匹配的文本描述會經過優化以具有較大的余弦相似度。為了從環境中生成圖像的語言描述,智能體會將觀察Ot提供給,并將可能的文本描述 ln提供給,如下圖 2 所示:
組成,在含有噪聲的大型圖像 - 文本描述對數據集上進行訓練。每個編碼器輸出一個 128 維的嵌入向量:圖像嵌入和匹配的文本描述會經過優化以具有較大的余弦相似度。為了從環境中生成圖像的語言描述,智能體會將觀察Ot提供給,并將可能的文本描述 ln提供給,如下圖 2 所示:
用 LLM 進行推理
語言模型將語言形式的 prompt 作為輸入,并通過自回歸計算下一個 token 的概率分布并從此分布中采樣來生成語言形式的輸出。該研究旨在讓 LLM 獲取表征任務的文本指令,并生成一組供機器人解決的子目標。在模型方面,該研究使用 FLAN-T5,定性分析表明,FLAN-T5 的表現略好于未根據指令進行微調的 LLM。
LLM 的 in-context 學習能力使該研究能夠直接使用它們,無需進行域內微調,并僅需要提供兩個任務指令和所需的語言輸出樣本來指導 LLM 的行為。
將指令轉化為行動
然后,使用語言條件策略網絡將 LLM 提供的語言目標轉化為行動。該參數化為 Transformer 的網絡將語言子目標的嵌入和時間步 t 時的 MDP 狀態(包括物體和機器人終端執行器的位置)作為輸入,每個輸入都用不同的向量表征,然后輸出機器人在時間步 t + 1 時要執行的動作。如下所述,該網絡是在 RL 循環中從頭開始訓練的。
收集與推斷的學習范式
智能體從與環境的交互中學習,其方法受到收集與推理范式的啟發。
在「收集」階段,智能體與環境互動,以狀態、觀察結果、行動和當前目標(s_t, o_t, a_t, g_i)的形式收集數據,并通過其策略網絡 f_θ(s_t, g_i) → a_t 預測行動。每一集結束后,智能體都會使用 VLM 來推斷收集到的數據中是否出現了任何子目標,從而獲得額外獎勵,將在后面詳細說明。
在「推斷」階段,研究者會在每個智能體完成一集后,即每完成 N 集后,通過行為克隆對經驗緩沖區中的策略進行訓練,從而在成功的情節上實現一種自我模仿。然后,更新后的策略權重將與所有分布式智能體共享,整個過程重復進行。
應用與成果
將語言作為智能體的核心,這為解決 RL 中的一系列基本挑戰提供了一個統一的框架。在這部分內容中,研究者討論了這些貢獻:探索、重用過去的經驗數據、調度和重用技能以及從觀察中學習。算法 1 描述了整體框架:

探索:通過語言生成課程
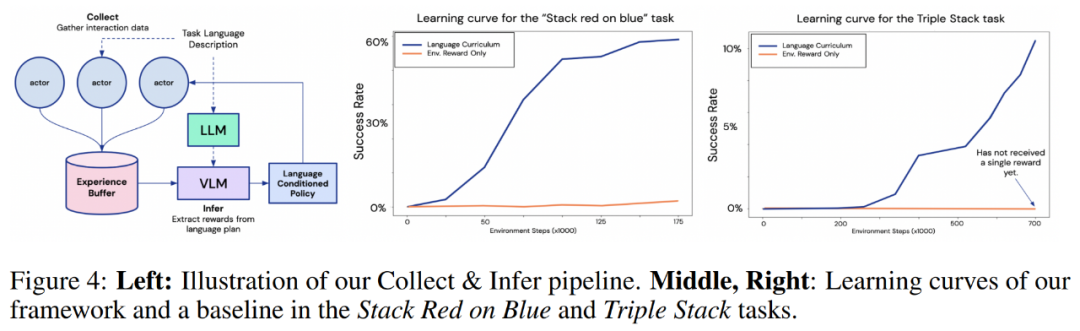
Stack X on Y 和 Triple Stack 的結果。在下圖 4 中,研究者所提出框架與僅通過環境獎勵進行學習的基線智能體進行了比較。從學習曲線可以清楚地看到,在所有任務中,本文的方法都比基線方法高效得多。
值得注意的是,在 Triple Stack 任務中,本文智能體的學習曲線迅速增長,而基線智能體仍然只能獲得一個獎勵,這是因為任務的稀疏度為 10^6 。
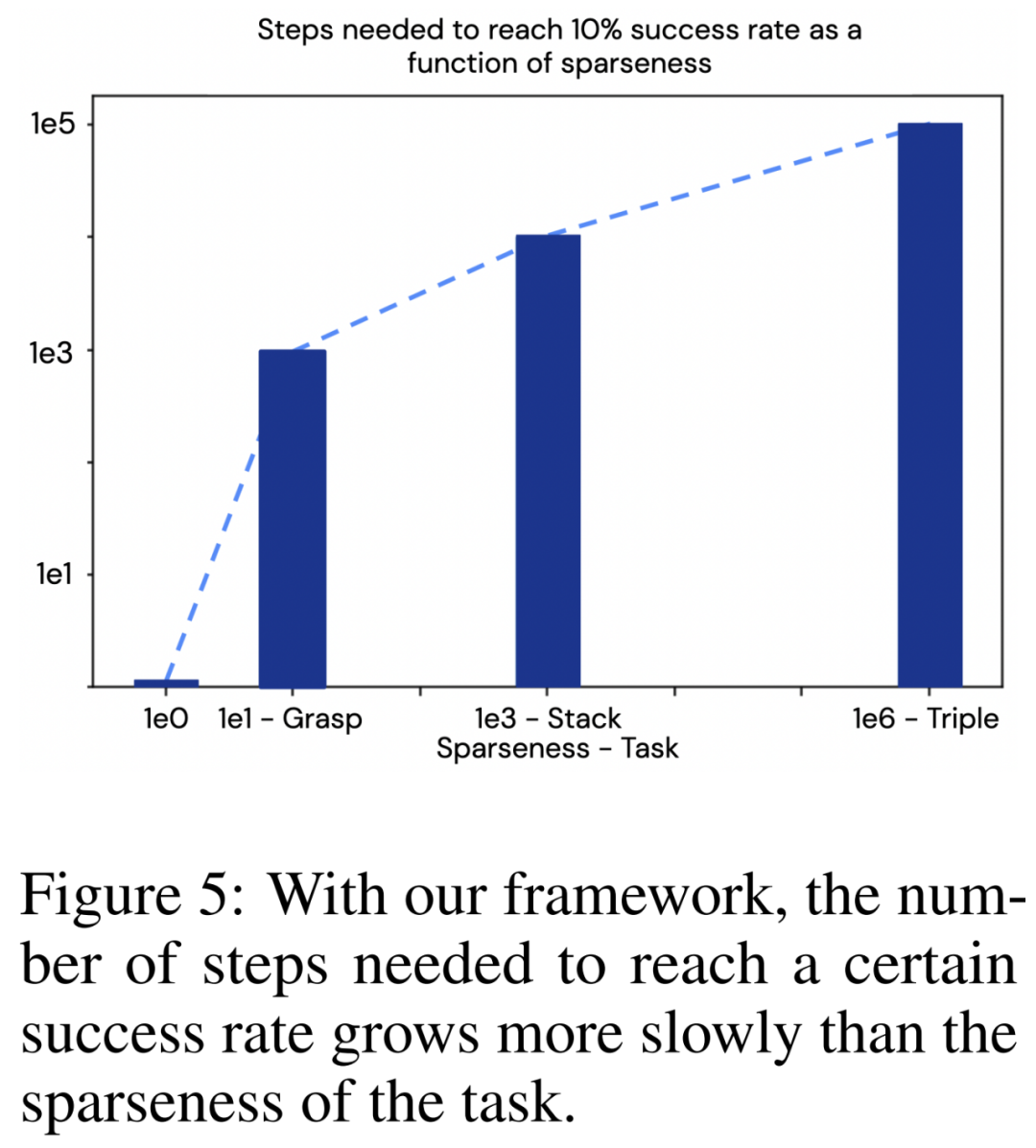
這些結果說明了一些值得注意的問題:可以將任務的稀疏程度與達到一定成功率所需的步驟數進行比較,如下圖 5 所示。研究者還在 「抓取紅色物體」任務上訓練了該方法,這是三個任務中最簡單的一個,其稀疏程度約為 10^1。可以看到,在本文的框架下,所需步驟數的增長速度比任務的稀疏程度更慢。這是一個特別重要的結果,因為通常在強化學習中,情況是正好相反的。
提取和轉移:通過重用離線數據進行高效的連續任務學習
研究者利用基于語言的框架來展示基于智能體過去經驗的引導。他們依次訓練了三個任務:將紅色物體堆疊在藍色物體上、將藍色物體堆疊在綠色物體上、將綠色物體堆疊在紅色物體上,將其稱之為 [T_R,B、T_B,G、T_G,R]。
順序任務學習的經驗重用結果。智能體應用這種方法連續學習了 [T_R,B、T_B,G、T_G,R]。在每個新任務開始時,研究者都會重新初始化策略權重,目標是探索本文框架提取和重用數據的能力,因此要隔離并消除可能由網絡泛化造成的影響。
下圖 7 中繪制了智能體需要在環境中采取多少交互步驟才能在每個新任務中達到 50% 的成功率。實驗清楚地說明了本文使用技術在重復利用以前任務收集的數據方面的有效性,從而提高了新任務的學習效率。
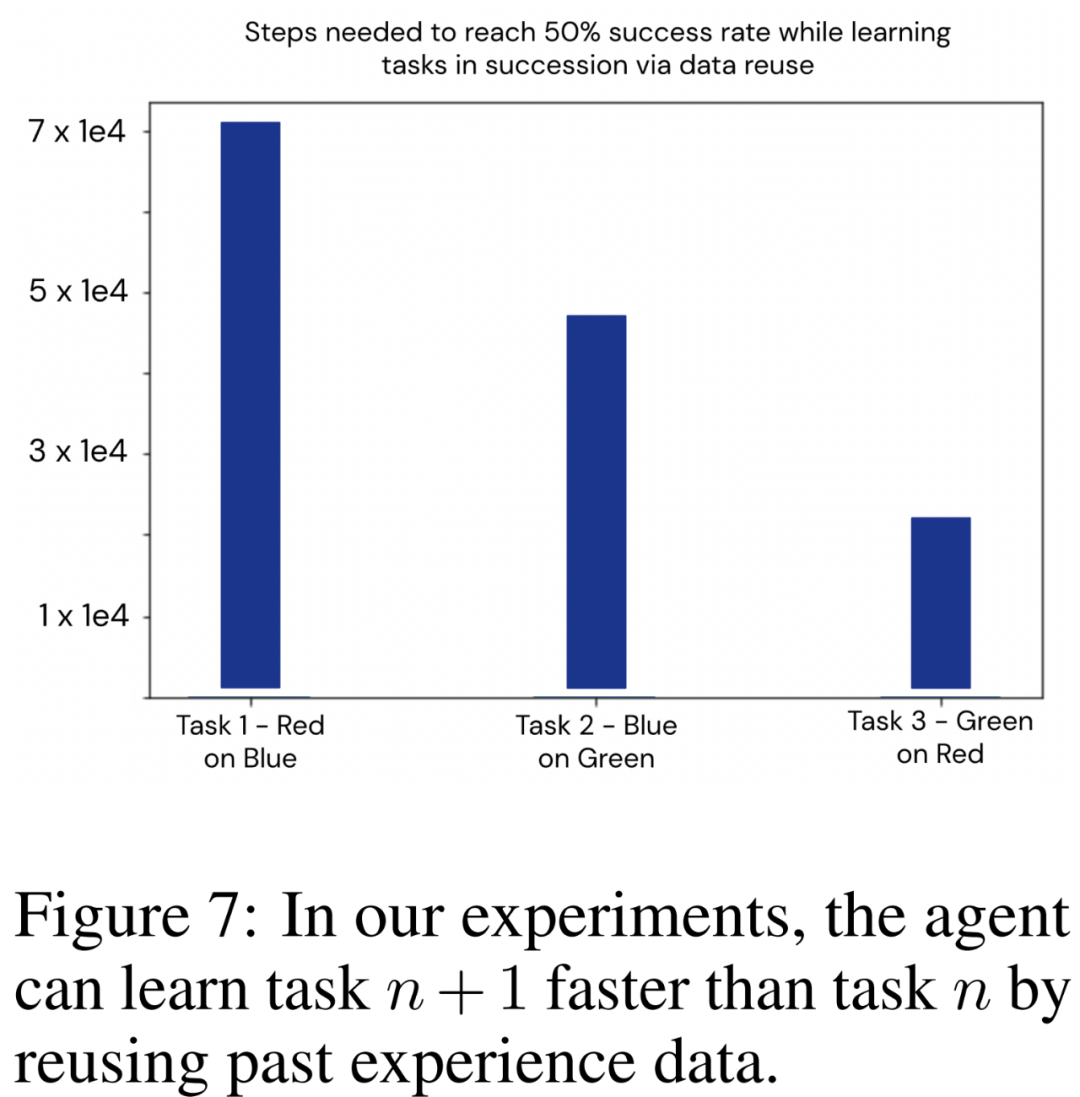
這些結果表明,本文提出的框架可用于釋放機器人智能體的終身學習能力:連續學習的任務越多,學習下一個任務的速度就越快。
調度和重復使用所學技能
至此,我們已經了解到框架如何使智能體能夠高效地探索和學習,以解決回報稀少的任務,并為終身學習重復使用和傳輸數據。此外,框架還能讓智能體調度和重復使用所學到的 M 技能來解決新任務,而不局限于智能體在訓練過程中遇到的任務。
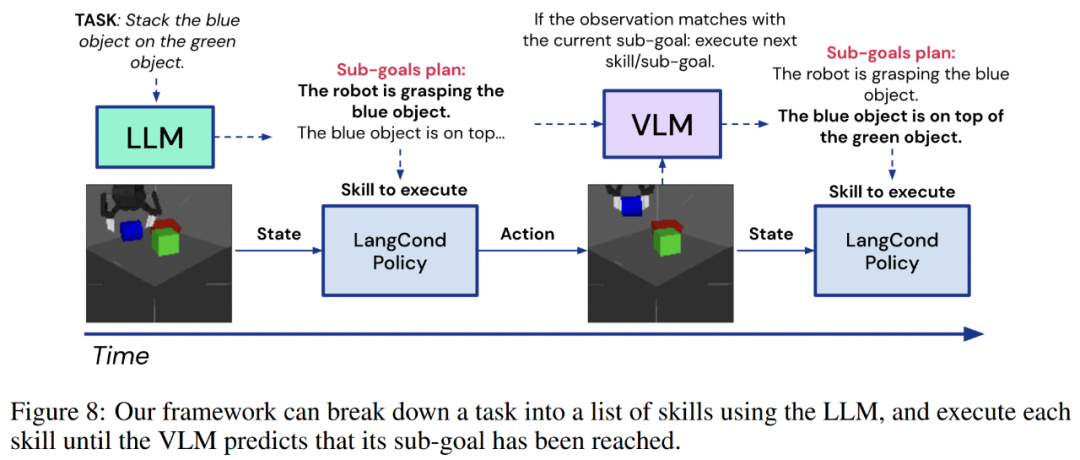
這種模式與前幾節中遇到的步驟相同:一條指令會被輸入到 LLM,如將綠色物體疊放在紅色物體上,或將紅色疊放在藍色物體上,再將綠色疊放在紅色物體上,然后 LLM 會將其分解為一系列更短視距的目標,即 g_0:N。然后,智能體可以利用策略網絡將這些目標轉化為行動,即 f_θ(s_t, g_n) → a_t。
從觀察中學習:將視頻映射到技能
通過觀察外部智能體學習是一般智能體的理想能力,但這往往需要專門設計的算法和模型。而本文智能體可以以專家執行任務的視頻為條件,實現 one-shot 觀察學習。
在測試中,智能體拍攝了一段人類用手堆疊物體的視頻。視頻被分為 F 個幀,即 v_0:F。然后,智能體使用 VLM,再配上以子目標 g_0:M 表示的關于所學技能的 M 文本描述來檢測專家軌跡遇到了哪些子目標,具體如下圖 8:
更多技術細節和實驗結果請查閱原論文。
原文標題:語言模型做先驗,統一強化學習智能體,DeepMind選擇走這條通用AI之路
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
-
物聯網
+關注
關注
2921文章
45661瀏覽量
384878
原文標題:語言模型做先驗,統一強化學習智能體,DeepMind選擇走這條通用AI之路
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「零基礎開發AI Agent」閱讀體驗】+初品Agent
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
請求贈閱《零基礎開發AI Agent——手把手教你用扣子做智能體》
《AI Agent 應用與項目實戰》----- 學習如何開發視頻應用
詳解RAD端到端強化學習后訓練范式

了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
如何使用 PyTorch 進行強化學習
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
通過強化學習策略進行特征選擇







 工商網監
工商網監

評論