 volatile的實現原理分析
volatile的實現原理分析
volatile的作用是什么?
volatile是一個輕量級的synchronized,一般作用于 變量 ,在多處理器開發的過程中保證了內存的可見性。相比于synchronized關鍵字,volatile關鍵字的執行成本更低,效率更高。
volatile的特性有哪些?
并發編程的三大特性為可見性、有序性和原子性。通常來講
volatile可以保證可見性和有序性。
- 可見性:
volatile可以保證不同線程對共享變量進行操作時的可見性。即當一個線程修改了共享變量時,另一個線程可以讀取到共享變量被修改后的值。 - 有序性:
volatile會通過禁止指令重排序進而保證有序性。 - 原子性:對于單個的
volatile修飾的變量的讀寫是可以保證原子性的,但對于i++這種復合操作并不能保證原子性。這句話的意思基本上就是說volatile不具備原子性了。
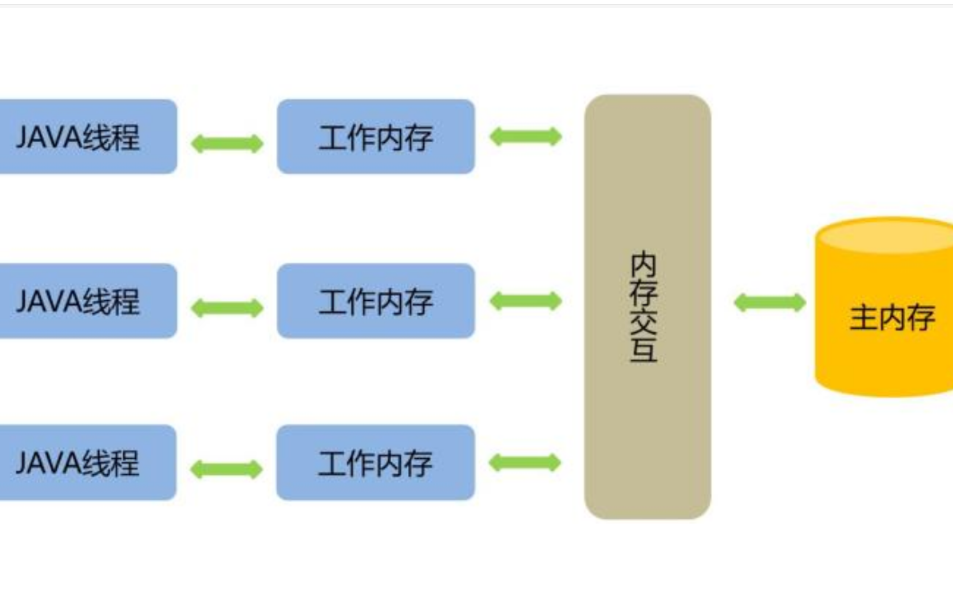
Java內存的可見性問題
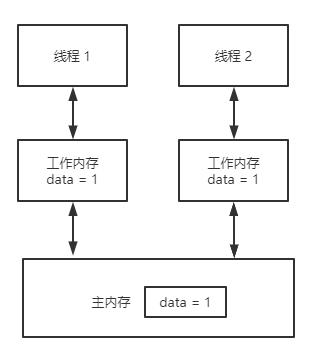
Java的內存模型如下圖所示。
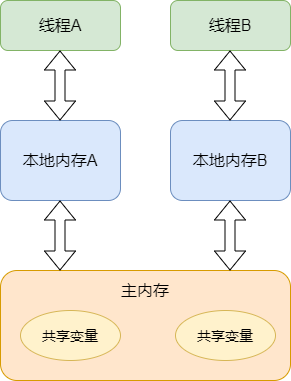
這里的本地內存并不是真實存在的,只是Java內存模型的一個抽象概念,它包含了控制器、運算器、緩存等。同時Java內存模型規定,線程對共享變量的操作必須在自己的本地內存中進行,不能直接在主內存中操作共享變量。這種內存模型會出現什么問題呢?,
- 線程A獲取到共享變量X的值,此時本地內存A中沒有X的值,所以加載主內存中的X值并緩存到本地內存A中,線程A修改X的值為1,并將X的值刷新到主內存中,這時主內存及本地內存A中的X的值都為1。
- 線程B需要獲取共享變量X的值,此時本地內存B中沒有X的值,加載主內存中的X值并緩存到本地內存B中,此時X的值為1。線程B修改X的值為2,并刷新到主內存中,此時主內存及本地內存B中的X值為2,本地內存A中的X值為1。
- 線程A再次獲取共享變量X的值,此時本地內存中存在X的值,所以直接從本地內存中A獲取到了X為1的值,但此時主內存中X的值為2,到此出現了所謂內存不可見的問題。
該問題Java內存模型是通過synchronized關鍵字和volatile關鍵字就可以解決。
為什么代碼會重排序?
計算機在執行程序的過程中,編譯器和處理器通常會對指令進行重排序,這樣做的目的是為了提高性能。具體可以看下面這個例子。
int a = 1;
int b = 2;
int a1 = a;
int b1 = b;
int a2 = a + a;
int b2 = b + b;
......
像這段代碼,不斷地交替讀取a和b,會導致寄存器頻繁交替存儲a和b,使得代碼性能下降,可對其進入如下重排序。
int a = 1;
int b = 2;
int a1 = a;
int a2 = a + a;
int b1 = b;
int b2 = b + b;
......
按照這樣的順序執行代碼便可以避免交替讀取a和b,這就是重排序的意義。
指令重排序一般分為編譯器優化重排、指令并行重排和內存系統重排三種。
- 編譯器優化重排:編譯器在不改變單線程程序語義的情況下,可以對語句的執行順序進行重新排序。
- 指令并行重排:現代處理器多采用指令級并行技術來將多條指令重疊執行。對于不存在數據依賴的程序,處理器可以對機器指令的執行順序進行重新排列。
- 內存系統重排:因為處理器使用緩存和讀/寫緩沖區,使得加載(load)和存儲(store)看上去像是在亂序執行。
注:簡單解釋下數據依賴性:如果兩個操作訪問了同一個變量,并且這兩個操作有一個是寫操作,這兩個操作之間就會存在數據依賴性,例如:
a = 1;
b = a;
如果對這兩個操作的執行順序進行重排序的話,那么結果就會出現問題。
其實,這三種指令重排說明了一個問題,就是指令重排在單線程下可以提高代碼的性能,但在多線程下可以會出現一些問題。
重排序會引發什么問題?
前面已經說過了,在單線程程序中,重排序并不會影響程序的運行結果,而在多線程場景下就不一定了。可以看下面這個經典的例子,該示例出自《Java并發編程的藝術》。
class ReorderExample{
int a = 0;
boolean flag = false;
public void writer(){
a = 1; // 操作1
flag = true; // 操作2
}
public void reader(){
if(flag){ // 操作3
int i = a + a; // 操作4
}
}
}
假設線程1先執行writer()方法,隨后線程2執行reader()方法,最后程序一定會得到正確的結果嗎?
答案是不一定的,如果代碼按照下圖的執行順序執行代碼則會出現問題。
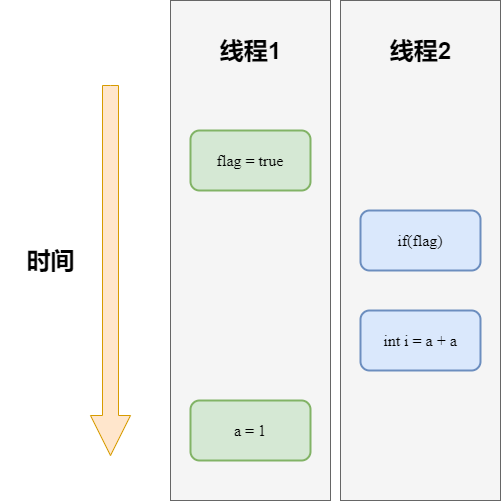
操作1和操作2進行了重排序,線程1先執行flag=true,然后線程2執行操作3和操作4,線程2執行操作4時不能正確讀取到a的值,導致最終程序運行結果出問題。這也說明了在多線程代碼中,重排序會破壞多線程程序的語義。
as-if-serial規則和happens-before規則的區別?
區別:
- as-if-serial定義:無論編譯器和處理器如何進行重排序,單線程程序的執行結果不會改變。
- happens-before定義:一個操作happens-before另一個操作,表示第一個的操作結果對第二個操作可見,并且第一個操作的執行順序也在第二個操作之前。但這并不意味著Java虛擬機必須按照這個順序來執行程序。如果重排序的后的執行結果與按happens-before關系執行的結果一致,Java虛擬機也會允許重排序的發生。
- happens-before關系保證了同步的多線程程序的執行結果不被改變,as-if-serial保證了單線程內程序的執行結果不被改變。
相同點:happens-before和as-if-serial的作用都是在不改變程序執行結果的前提下,提高程序執行的并行度。
voliatile的實現原理?
前面已經講述
volatile具備可見性和有序性兩大特性,所以volatile的實現原理也是圍繞如何實現可見性和有序性展開的。
volatile實現內存可見性原理
導致內存不可見的主要原因就是Java內存模型中的本地內存和主內存之間的值不一致所導致,例如上面所說線程A訪問自己本地內存A的X值時,但此時主內存的X值已經被線程B所修改,所以線程A所訪問到的值是一個臟數據。那如何解決這種問題呢?
volatile可以保證內存可見性的關鍵是volatile的讀/寫實現了緩存一致性,緩存一致性的主要內容為:
- 每個處理器會通過嗅探總線上的數據來查看自己的數據是否過期,一旦處理器發現自己緩存對應的內存地址被修改,就會將當前處理器的緩存設為無效狀態。此時,如果處理器需要獲取這個數據需重新從主內存將其讀取到本地內存。
- 當處理器寫數據時,如果發現操作的是共享變量,會通知其他處理器將該變量的緩存設為無效狀態。
那緩存一致性是如何實現的呢?可以發現通過volatile修飾的變量,生成匯編指令時會比普通的變量多出一個Lock指令,這個Lock指令就是volatile關鍵字可以保證內存可見性的關鍵,它主要有兩個作用:
- 將當前處理器緩存的數據刷新到主內存。
- 刷新到主內存時會使得其他處理器緩存的該內存地址的數據無效。
volatile實現有序性原理
前面提到重排序可以提高代碼的執行效率,但在多線程程序中可以導致程序的運行結果不正確,那
volatile是如何解決這一問題的呢?
為了實現volatile的內存語義,編譯器在生成字節碼時會通過插入內存屏障來禁止指令重排序。
內存屏障:內存屏障是一種CPU指令,它的作用是對該指令前和指令后的一些操作產生一定的約束,保證一些操作按順序執行。
Java虛擬機插入內存屏障的策略
Java內存模型把內存屏障分為4類,如下表所示:
| 屏障類型 | 指令示例 | 說明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 保證Load1數據的讀取先于Load2及后續所有讀取指令的執行 |
| StoreStore Barriers | Store1;StoreStore;Store2 | 保證Store1數據刷新到主內存先于Store2及后續所有存儲指令 |
| LoadStore Barriers | Load1;LoadStore;Store2 | 保證Load1數據的讀取先于Store2及后續的所有存儲指令刷新到主內存 |
| StoreLoad Barriers | Store1;StoreLoad;Load2 | 保證Store1數據刷新到主內存先于Load2及后續所有讀取指令的執行 |
注:StoreLoad Barriers同時具備其他三個屏障的作用,它會使得該屏障之前的所有內存訪問指令完成之后,才會執行該屏障之后的內存訪問命令。
Java內存模型對編譯器指定的volatile重排序規則為:
- 當第一個操作是
volatile讀時,無論第二個操作是什么都不能進行重排序。 - 當第二個操作是
volatile寫時,無論第一個操作是什么都不能進行重排序。 - 當第一個操作是
volatile寫,第二個操作為volatile讀時,不能進行重排序。
根據volatile重排序規則,Java內存模型采取的是保守的屏障插入策略,volatile寫是在前面和后面分別插入內存屏障,volatile讀是在后面插入兩個內存屏障,具體如下:
volatile讀:在每個volatile讀后面分別插入LoadLoad屏障及LoadStore屏障(根據volatile重排序規則第一條),如下圖所示
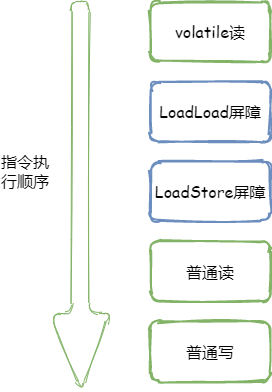
LoadLoad屏障的作用:禁止上面的所有普通讀操作和上面的volatile讀操作進行重排序。
LoadStore屏障的作用:禁止下面的普通寫和上面的volatile讀進行重排序。
volatile寫:在每個volatile寫前面插入一個StoreStore屏障(為滿足volatile重排序規則第二條),在每個volatile寫后面插入一個StoreLoad屏障(為滿足voaltile重排序規則第三條),如下圖所示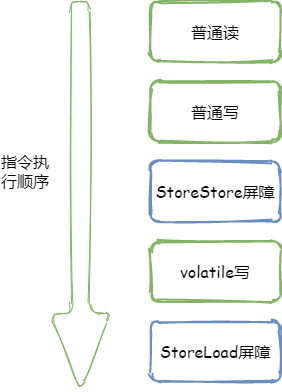
StoreStore屏障的作用:禁止上面的普通寫和下面的volatile寫重排序
StoreLoad屏障的作用:防止上面的volatile寫與下面可能出現的volatile讀/寫重排序。
編譯器對內存屏障插入策略的優化
因為Java內存模型所采用的屏障插入策略比較保守,所以在實際的執行過程中,只要不改變
volatile讀/寫的內存語義,編譯器通常會省略一些不必要的內存屏障。
代碼如下:
public class VolatileBarrierDemo{
int a;
volatile int b = 1;
volatile int c = 2;
public void test(){
int i = b; //volatile讀
int j = c; //volatile讀
a = i + j; //普通寫
}
}
指令序列示意圖如下:
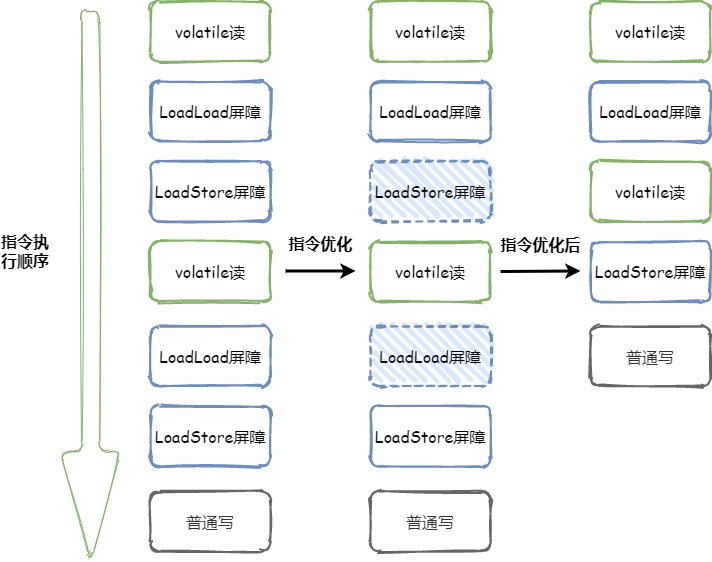
從上圖可以看出,通過指令優化一共省略了兩個內存屏障(虛線表示),省略第一個內存屏障LoadStore的原因是最后的普通寫不可能越過第二個volatile讀,省略第二個內存屏障LoadLoad的原因是下面沒有涉及到普通讀的操作。
volatile能使一個非原子操作變成一個原子操作嗎?
volatile只能保證可見性和有序性,但可以保證64位的long型和double型變量的原子性。
對于32位的虛擬機來說,每次原子讀寫都是32位的,會將long和double型變量拆分成兩個32位的操作來執行,這樣long和double型變量的讀寫就不能保證原子性了,而通過volatile修飾的long和double型變量則可以保證其原子性。
volatile、synchronized的區別?
volatile主要是保證內存的可見性,即變量在寄存器中的內存是不確定的,需要從主存中讀取。synchronized主要是解決多個線程訪問資源的同步性。volatile作用于變量,synchronized作用于代碼塊或者方法。volatile僅可以保證數據的可見性,不能保證數據的原子性。synchronized可以保證數據的可見性和原子性。volatile不會造成線程的阻塞,synchronized會造成線程的阻塞。
-
處理器
+關注
關注
68文章
19404瀏覽量
230807 -
開發
+關注
關注
0文章
370瀏覽量
40888 -
volatile
+關注
關注
0文章
45瀏覽量
13048
發布評論請先 登錄
相關推薦
Volatile變量的使用
什么是volatile
c語言volatile的作用
Volatile與多線程的認識與理解
volatile修飾的變量的認識和理解

Java中volatile的作用以及用法
volatile變量定義的意義和該用在哪里

C語言類型修飾符Volatile的使用說明
如何使用C++語法中的volatile
C++基礎語法之volatile、assert()和sizeof()
【嵌入式】C語言中volatile關鍵字

Volatile關鍵字在嵌入式開發中的應用
volatile的原理





 工商網監
工商網監
評論