") 深度學(xué)習(xí):神經(jīng)網(wǎng)絡(luò)算法的昨天、今天和明天
深度學(xué)習(xí):神經(jīng)網(wǎng)絡(luò)算法的昨天、今天和明天
2016年,圍棋人工智能軟件AlphaGo打敗了韓國圍棋名將李世石。2017年,新一代AlphaGo(AlphaGo Master)的戰(zhàn)斗力升級(jí),又打敗了世界排名第一的柯潔。這樣的人工智能(Artificial Intelligence)系統(tǒng),不再簡單地只靠儲(chǔ)存能力戰(zhàn)勝人類,而是已經(jīng)在一些具體的領(lǐng)域超越了人類的認(rèn)知,甚至像是擁有了“思考”的能力,更接近大眾對人工智能的想象。
人工智能似乎一直是一個(gè)遙遠(yuǎn)的科幻的概念,但事實(shí)上,當(dāng)今世界很多應(yīng)用已經(jīng)達(dá)到了“人工智能”的標(biāo)準(zhǔn)。除了前文提到的圍棋軟件,還有自動(dòng)駕駛系統(tǒng)、智能管家,甚至蘋果手機(jī)上的語音助手Siri都是一種人工智能。而這些應(yīng)用背后的核心算法就是深度學(xué)習(xí)(Deep Learning),也是機(jī)器學(xué)習(xí)(Machine Learning)領(lǐng)域最火熱的一個(gè)分支。和其他機(jī)器學(xué)習(xí)算法有很大不同,
深度學(xué)習(xí)依賴大量數(shù)據(jù)的迭代訓(xùn)練,進(jìn)而發(fā)現(xiàn)數(shù)據(jù)中內(nèi)在的特征(Feature),然后給出結(jié)果。這些特征中,有很多已經(jīng)超越了人為定義的特征的表達(dá)能力,因此得以讓深度學(xué)習(xí)在很多任務(wù)的表現(xiàn)上大大超越了其他機(jī)器學(xué)習(xí)算法,甚至超越了人類自己。
但是,深度學(xué)習(xí)還沒能全方面超越人類。相反,它的工作完全依賴于人類對算法的設(shè)計(jì)。深度學(xué)習(xí)從誕生到爆發(fā)用了大約五十年。從其發(fā)展歷程,我們可以窺見計(jì)算機(jī)科學(xué)家們的步步巧思,并從中探討其可能的發(fā)展方向。
一、什么是深度學(xué)習(xí)
深度學(xué)習(xí)就是人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Network)。神經(jīng)網(wǎng)絡(luò)算法得名于其對于動(dòng)物神經(jīng)元傳遞信息方式的模擬,而深度學(xué)習(xí)這一“俗稱”又來自于多層級(jí)聯(lián)的神經(jīng)元:眾多的層讓信息的傳遞實(shí)現(xiàn)了“深度”。
在動(dòng)物身上,神經(jīng)一端連接感受器,另一端連接大腦皮層,中間通過多層神經(jīng)元傳導(dǎo)信號(hào)。神經(jīng)元之間也不是一對一連接,而是有多種連接方式(如輻射式、聚合式等),從而形成了網(wǎng)絡(luò)結(jié)構(gòu)。這一豐富的結(jié)構(gòu)最終不僅實(shí)現(xiàn)了信息的提取,也使動(dòng)物大腦產(chǎn)生了相應(yīng)的認(rèn)知。動(dòng)物的學(xué)習(xí)過程則需要外界信息在大腦中的整合。外界信息進(jìn)入神經(jīng)系統(tǒng),進(jìn)而成為大腦皮層可以接收的信號(hào);信號(hào)與腦中的已有信息進(jìn)行比對,也就在腦中建立了完整的認(rèn)知。
類似地,通過計(jì)算機(jī)編程,計(jì)算機(jī)科學(xué)家讓一層包含參數(shù)(Parameter)和權(quán)重(Weight)的函數(shù)模擬神經(jīng)元內(nèi)部的操作,用非線性運(yùn)算的疊加模擬神經(jīng)元之間的連接,最終實(shí)現(xiàn)對信息的重新整合,進(jìn)而輸出分類或預(yù)測的結(jié)果。針對神經(jīng)網(wǎng)絡(luò)輸出結(jié)果與真實(shí)結(jié)果之間的差異,神經(jīng)網(wǎng)絡(luò)會(huì)通過梯度(Gradient)逐層調(diào)整相應(yīng)的權(quán)重以縮小差異,從而達(dá)到深度學(xué)習(xí)的目的。
二、深度學(xué)習(xí)的雛形
其實(shí),模擬動(dòng)物的神經(jīng)活動(dòng),并非深度學(xué)習(xí)的專利。早在1957年,F(xiàn)rank Rosenblatt就提出了感知機(jī)(Perceptron)的概念。這是一種只能分出兩類結(jié)果的單層神經(jīng)網(wǎng)絡(luò)。這種模型非常簡單,輸出結(jié)果與輸入信息之間幾乎就是一個(gè)“加權(quán)和”的關(guān)系。雖然權(quán)重會(huì)直接根據(jù)輸出結(jié)果與真實(shí)值之間的差異自動(dòng)調(diào)整,但是整個(gè)系統(tǒng)的學(xué)習(xí)能力有限,只能用于簡單的數(shù)據(jù)擬合。
幾乎與此同時(shí),神經(jīng)科學(xué)界出現(xiàn)了重大進(jìn)展。神經(jīng)科學(xué)家David Hubel和Torsten Wiesel對貓的視覺神經(jīng)系統(tǒng)的研究證實(shí),視覺特征在大腦皮層的反應(yīng)是通過不同的細(xì)胞達(dá)成的。其中,簡單細(xì)胞(Simple Cell)感知光照信息,復(fù)雜細(xì)胞(Complex Cell)感知運(yùn)動(dòng)信息。
受此啟發(fā),1980年,日本學(xué)者福島邦彥(Kunihiko Fukushima)提出了一個(gè)網(wǎng)絡(luò)模型“神經(jīng)認(rèn)知機(jī)(Neocognitron)”(圖1)用以識(shí)別手寫數(shù)字。這種網(wǎng)絡(luò)分成多層,每層由一種神經(jīng)元組成。在網(wǎng)絡(luò)內(nèi)部,兩種神經(jīng)元交替出現(xiàn),分別用以提取圖形信息和組合圖形信息。這兩種神經(jīng)元到后來演化成了重要的卷積層(Convolution Layer)和提取層(Pooling Layer)。但是這個(gè)網(wǎng)絡(luò)的神經(jīng)元都是由人工設(shè)計(jì)而成,其神經(jīng)元也不會(huì)根據(jù)結(jié)果進(jìn)行自動(dòng)調(diào)整,因此也就不具有學(xué)習(xí)能力,只能限制在識(shí)別少量簡單數(shù)字的初級(jí)階段。
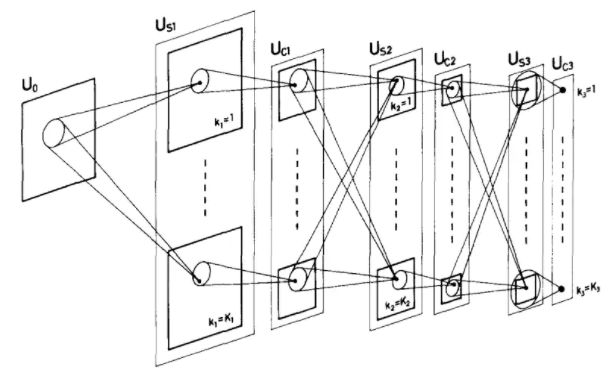
圖1:神經(jīng)認(rèn)知機(jī)Neocognitron的工作原理圖(摘自原文Fukushima, Kunihiko. "Neocognitron: A hierarchical neural network capable of visual pattern recognition."Neural networks1.2 (1988): 119-130)
當(dāng)學(xué)習(xí)能力無法被實(shí)現(xiàn)的時(shí)候,就需要更多的人工設(shè)計(jì)來替代網(wǎng)絡(luò)的自主學(xué)習(xí)。1982年,美國科學(xué)家John Hopfield發(fā)明了一種神經(jīng)網(wǎng)絡(luò),在其中加入了諸多限制,讓神經(jīng)網(wǎng)絡(luò)在變化中保持記憶以便學(xué)習(xí)。同年,芬蘭科學(xué)家Teuvo Kohonen在無監(jiān)督算法向量量化神經(jīng)網(wǎng)絡(luò)(Learning Vector Quantization Network)的基礎(chǔ)上提出了自組織映射(Self-Organizing Map),希望通過縮短輸入和輸出之間的歐氏距離,從繁雜的網(wǎng)絡(luò)中學(xué)習(xí)到正確的關(guān)系。1987年,美國科學(xué)家Stephen Grossberg和Gail Carpenter依據(jù)自己早先的理論提出了自適應(yīng)共振理論網(wǎng)絡(luò) (Adaptive resonance theory),也就是讓某個(gè)已知信息和未知信息發(fā)生“共振”,從而從已知信息推測未知的信息實(shí)現(xiàn)“類比學(xué)習(xí)”。雖然這些網(wǎng)絡(luò)都加上了“自組織”、“自適應(yīng)”、“記憶”等關(guān)鍵詞,但其學(xué)習(xí)方式效率不高,而且需要根據(jù)應(yīng)用本身不斷地優(yōu)化設(shè)計(jì),再加上網(wǎng)絡(luò)的記憶容量很小,很難在實(shí)際中應(yīng)用。
1986年,計(jì)算機(jī)科學(xué)家David Rumelhart、Geoffrey Hinton和Ronald Williams發(fā)表了反向傳播算法(Backpropagation),才算階段性地解決了神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)的難題。通過梯度的鏈?zhǔn)椒▌t,神經(jīng)網(wǎng)絡(luò)的輸出結(jié)果和真實(shí)值之間的差異可以通過梯度反饋到每一層的權(quán)重中,也就讓每一層函數(shù)都類似感知機(jī)那樣得到了訓(xùn)練。這是Geoffrey Hinton第一個(gè)里程碑式的工作。如今的他是Google的工程研究員,曾獲得計(jì)算機(jī)領(lǐng)域最高榮譽(yù)的圖靈(Turing)獎(jiǎng)。他曾在采訪中說: “我們并不想構(gòu)建一個(gè)模型來模擬大腦的運(yùn)行方式。我們會(huì)觀察大腦,同時(shí)會(huì)想,既然大腦的工作模式可行,那么如果我們想創(chuàng)造一些其他可行的模型,就應(yīng)該從大腦中尋找靈感。反向傳播算法模擬的正是大腦的反饋機(jī)制。
之后的1994年,計(jì)算機(jī)科學(xué)家Yann LeCun在Geoffrey Hinton組內(nèi)做博士后期間,結(jié)合神經(jīng)認(rèn)知機(jī)和反向傳播算法,提出了用于識(shí)別手寫郵政編碼的卷積神經(jīng)網(wǎng)絡(luò)LeNet,獲得了99%的自動(dòng)識(shí)別率,并且可以處理幾乎任意的手寫形式。這一算法在當(dāng)時(shí)取得了巨大的成功,并被應(yīng)用于美國郵政系統(tǒng)中。
三、深度學(xué)習(xí)的爆發(fā)
盡管如此,深度學(xué)習(xí)并沒有因此而熱門。原因之一,就是神經(jīng)網(wǎng)絡(luò)需要更新大量參數(shù)(僅2012年提出的AlexNet就需要65萬個(gè)神經(jīng)元和6000萬個(gè)參數(shù)),需要強(qiáng)大的數(shù)據(jù)和算力的支持 (圖2)。而如果想通過降低網(wǎng)絡(luò)的層數(shù)來降低數(shù)據(jù)量和訓(xùn)練時(shí)間,其效果也不如其他的機(jī)器學(xué)習(xí)方法(比如2000年前后大行其道的支持向量機(jī),Support Vector Machine)。2006年Geoffrey Hinton的另一篇論文首度使用了“深度網(wǎng)絡(luò)”的名稱(Deep Belief Nets),為整個(gè)神經(jīng)網(wǎng)絡(luò)的優(yōu)化提供了途徑。雖然為后面深度學(xué)習(xí)的炙手可熱奠定了基礎(chǔ),但是之所以用“深度網(wǎng)絡(luò)”而避開之前“神經(jīng)網(wǎng)絡(luò)”的名字,就是因?yàn)橹髁餮芯恳呀?jīng)不認(rèn)可“神經(jīng)網(wǎng)絡(luò)”,甚至到了看見相關(guān)標(biāo)題就拒收論文的程度。
深度學(xué)習(xí)的轉(zhuǎn)折發(fā)生在2012年。在計(jì)算機(jī)視覺領(lǐng)域,科學(xué)家也逐漸注意到了數(shù)據(jù)規(guī)模的重要性。2010年,斯坦福大學(xué)的計(jì)算機(jī)系副教授李飛飛(Li Fei-Fei)發(fā)布了圖像數(shù)據(jù)庫ImageNet,共包含上千萬張經(jīng)過人工標(biāo)記過的圖片,分屬于1000個(gè)類別,涵蓋動(dòng)物、植物、生活等方方面面。2010—2017年,計(jì)算機(jī)視覺領(lǐng)域每年都會(huì)舉行基于這些圖片的分類競賽,ImageNet也因此成為全世界視覺領(lǐng)域機(jī)器學(xué)習(xí)和深度學(xué)習(xí)算法的試金石。2012年,Geoffrey Hinton在多倫多大學(xué)的學(xué)生,Alex Krizhevsky,在ImageNet的分類競賽中,通過在兩塊NVIDIA顯卡(GPU)上編寫神經(jīng)網(wǎng)絡(luò)算法而獲得了冠軍,而且其算法的識(shí)別率大幅超過第二名。這個(gè)網(wǎng)絡(luò)隨后被命名為AlexNet。這是深度學(xué)習(xí)騰飛的開始。
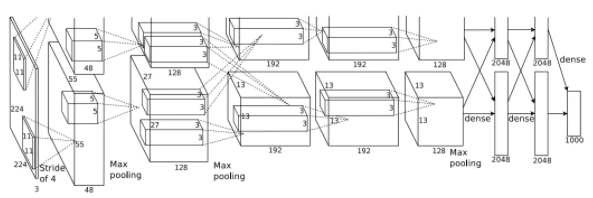
圖2:AlexNet的網(wǎng)絡(luò)結(jié)構(gòu)(摘自原文Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton."Imagenet classification with deep convolutional neural networks."Advances in neural information processing systems. 2012.)
從AlexNet開始,由ImageNet提供數(shù)據(jù)支持,由顯卡提供算力支持,大量關(guān)于神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的研究逐漸鋪開。首先,由于大量軟件包的發(fā)布(如Caffe,TensorFlow,Torch等),實(shí)現(xiàn)深度學(xué)習(xí)變得越來越容易。其次,在研究領(lǐng)域,從ImageNet分類競賽和任務(wù)為更加復(fù)雜的圖像分割和描述的COCO競賽中,又產(chǎn)生了VGGNet、GoogLeNet、ResNet和DenseNet。這些神經(jīng)網(wǎng)絡(luò)的層數(shù)逐漸增加,從AlexNet的11層到VGGNet的19層,而到ResNet和DenseNet時(shí),深度已經(jīng)達(dá)到了150層乃至200層,達(dá)成了名副其實(shí)的“深度”學(xué)習(xí)。這些深度神經(jīng)網(wǎng)絡(luò)在一些數(shù)據(jù)集上關(guān)于分類問題的測試,甚至已經(jīng)超過了人類的識(shí)別準(zhǔn)確率(在ImageNet上人類的錯(cuò)誤率大約為5%,而SENet的錯(cuò)誤率可以達(dá)到2.25%)。如表1所示:
| 年份 | 2012 | 2013 | 2014 | 2014 | 2015 | 2016 | 2017 |
| 網(wǎng)絡(luò) | AlexNet | ZFNet | VGGNet | GoogLeNet | ResNet | ResNeXt | SENet |
| Top5錯(cuò)誤率 | 15.32% | 13.51% | 7.32% | 6.67% | 3.57% | 3.03% | 2.25% |
| 層數(shù) | 8 | 8 | 16 | 22 | 152 | 152 | 154 |
| 參數(shù)量 | 60M | 60M | 138M | 7M | 60M | 44M | 67M |
表1:歷年ImageNet圖片分類比賽優(yōu)秀網(wǎng)絡(luò)匯總(由原始論文計(jì)算,并參考https://github.com/sovrasov/flops-counter.pytorch)
自此,計(jì)算機(jī)科學(xué)家們越來越多地利用神經(jīng)網(wǎng)絡(luò)算法來解決問題。除了上述在二維圖像上的分類、分割、檢測等方面的應(yīng)用,神經(jīng)網(wǎng)絡(luò)還被用在時(shí)序信號(hào)甚至是無監(jiān)督的機(jī)器學(xué)習(xí)中。循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network)可以按照時(shí)間順序接受信號(hào)的輸入。一方面,它的每層神經(jīng)元可以壓縮并儲(chǔ)存記憶;另一方面,它可以從記憶中提取有效的維度進(jìn)行語音識(shí)別和文字理解。而把神經(jīng)網(wǎng)絡(luò)用在無監(jiān)督學(xué)習(xí)上,就跳出了“提取主成分”或者“提取特征值”的窠臼,簡單地用一個(gè)包含了多層網(wǎng)絡(luò)的自編碼器(Autoencoder),就可以把原始信息自動(dòng)地實(shí)現(xiàn)降維和提取。再結(jié)合向量量化網(wǎng)絡(luò),可以實(shí)現(xiàn)對特征的聚類,進(jìn)而在沒有太多標(biāo)記數(shù)據(jù)的情況下得到分類結(jié)果。可以說,神經(jīng)網(wǎng)絡(luò)無論是效果還是應(yīng)用范圍上,都成為了無可爭議的王者。
四、深度學(xué)習(xí)的發(fā)展現(xiàn)狀和趨勢
2017年,ImageNet圖像分類競賽宣布完成了最后一屆。但這并不意味著深度學(xué)習(xí)偃旗息鼓,恰恰相反,深度學(xué)習(xí)的研究和應(yīng)用脫離了之前以“分類問題”為研究主題的階段,進(jìn)入了廣泛發(fā)展的階段。同時(shí),與深度學(xué)習(xí)相關(guān)的國際會(huì)議投稿量逐年呈指數(shù)式地增加,也說明有越來越多的研究者和工程師投身于深度學(xué)習(xí)算法的研發(fā)和應(yīng)用。筆者認(rèn)為,深度學(xué)習(xí)近年來的發(fā)展呈現(xiàn)出以下幾個(gè)趨勢。
第一,從結(jié)構(gòu)上看,神經(jīng)網(wǎng)絡(luò)的類型會(huì)變得更加多樣。其中,可以執(zhí)行卷積神經(jīng)網(wǎng)絡(luò)逆向過程的生成對抗網(wǎng)絡(luò)(Generative Adversarial Network)從2016年被提出以來發(fā)展迅速,成為了深度學(xué)習(xí)一個(gè)重要的“增長點(diǎn)”。由于深度學(xué)習(xí)算法可以從原始信息(如圖像)中提取特征,那么其逆過程邏輯上也是可行的,即利用一些雜亂的信號(hào)通過特定神經(jīng)網(wǎng)絡(luò)來生成相應(yīng)的圖像。于是,計(jì)算機(jī)科學(xué)家Ian Good fellow提出了生成對抗網(wǎng)絡(luò)。這個(gè)網(wǎng)絡(luò)除了能生成圖像的生成器(Generator)之外,還提供了一個(gè)判別器(Discriminator)。在訓(xùn)練過程中,生成器趨于學(xué)習(xí)出一個(gè)讓計(jì)算機(jī)難以分辨的、極度逼近真實(shí)的生成圖片,判別器趨于學(xué)習(xí)出強(qiáng)大的判定真實(shí)圖片和生成圖片的能力。二者對抗學(xué)習(xí),生成圖片做得越真實(shí),判別器就會(huì)越難分辨;判別器能力越強(qiáng),也就促使生成器生成新的、更加真實(shí)的圖片。生成對抗網(wǎng)絡(luò)在人臉生成和識(shí)別、圖像分辨率提升、視頻幀率提升、圖像風(fēng)格遷移等領(lǐng)域中都有著廣泛的應(yīng)用。
第二,研究的問題趨于多樣。一方面,一些在機(jī)器學(xué)習(xí)其他分支中的概念,如強(qiáng)化學(xué)習(xí)(Reinforcement Learning)、遷移學(xué)習(xí)(Transfer Learning),在深度學(xué)習(xí)中找到了新的位置。另一方面,深度學(xué)習(xí)本身的研究也從“工程試錯(cuò)”向“理論推導(dǎo)”發(fā)展。深度學(xué)習(xí)一直因其缺少理論基礎(chǔ)而飽受詬病,在訓(xùn)練過程中幾乎完全依賴數(shù)據(jù)科學(xué)家的經(jīng)驗(yàn)。為了減少經(jīng)驗(yàn)對結(jié)果的影響,以及減少選擇超參數(shù)的時(shí)間,除了對最初經(jīng)典網(wǎng)絡(luò)結(jié)構(gòu)的修改,研究者們也在從根本上修正深度學(xué)習(xí)的效率。一些研究者在試圖聯(lián)系其他機(jī)器學(xué)習(xí)的方法(比如壓縮感知、貝葉斯理論等),用以使深度學(xué)習(xí)從工程的試錯(cuò)變?yōu)橛欣碚撝笇?dǎo)下的實(shí)踐。還有一些研究在試圖解釋深度學(xué)習(xí)算法的有效性,而不只是把整個(gè)網(wǎng)絡(luò)當(dāng)做一個(gè)黑盒子。與此同時(shí),研究者也在針對超參數(shù)建立另一個(gè)機(jī)器學(xué)習(xí)的問題,即元學(xué)習(xí)(Meta Learning),以降低選擇超參數(shù)過程的難度和隨機(jī)性。
第三,隨著大量研究成果的新鮮出爐,更多的算法也被應(yīng)用于產(chǎn)品中。除了一些小規(guī)模的公司陸續(xù)開發(fā)了圖像生成小程序,大公司們也在競相搶占深度學(xué)習(xí)這一高地。互聯(lián)網(wǎng)巨頭Google、Facebook和Microsoft都先后成立了深度學(xué)習(xí)的發(fā)展中心,中國的互聯(lián)網(wǎng)公司百度、阿里巴巴、騰訊、京東以及字節(jié)跳動(dòng)等也都各自成立了自己的深度學(xué)習(xí)研究中心。一些基于深度學(xué)習(xí)技術(shù)的獨(dú)角獸公司,如DeepMind、商湯、曠視等,也從大量競爭者中脫穎而出。2019年以來,產(chǎn)業(yè)界的深度學(xué)習(xí)研究也漸漸地從關(guān)注論文發(fā)表轉(zhuǎn)變到了落地的項(xiàng)目。比如騰訊AI Lab對視頻播放進(jìn)行優(yōu)化,比如依圖制作的肺結(jié)節(jié)篩查已經(jīng)在國內(nèi)的一些醫(yī)院試點(diǎn)。
第四,隨著5G技術(shù)的逐漸普及,深度學(xué)習(xí)會(huì)跟云計(jì)算一起嵌入日常生活。深度學(xué)習(xí)這項(xiàng)技術(shù)一直難以落地的原因是計(jì)算資源的匱乏。一臺(tái)配備顯卡的超級(jí)計(jì)算機(jī)的成本可以達(dá)到50萬人民幣,而并不是所有公司都有充足的資金和能夠充分使用這些設(shè)備的人才。而隨著5G技術(shù)的普及,以及云技術(shù)的加持,公司可以通過租用的方式,低成本地從云中直接獲得計(jì)算資源。公司可以將數(shù)據(jù)上傳到云端,并且?guī)缀鯇?shí)時(shí)地收到云端傳回的計(jì)算結(jié)果。一大批新興的創(chuàng)業(yè)公司正在想辦法利用這些基礎(chǔ)設(shè)施:他們召集了一批計(jì)算機(jī)科學(xué)家和數(shù)據(jù)科學(xué)家,為其他公司提供深度學(xué)習(xí)算法支持和硬件支持。這使得一些之前跟計(jì)算機(jī)技術(shù)關(guān)系不大的行業(yè)(比如制造業(yè)、服務(wù)業(yè)、娛樂業(yè),甚至法律行業(yè)),不再需要自己定義問題、研發(fā)方案,而是通過與算法公司合作便利地享受到計(jì)算機(jī)技術(shù)行業(yè)的專業(yè)支持,也因此更容易獲得深度學(xué)習(xí)的賦能。
五、總結(jié)與討論
在五十多年的歷程中,深度學(xué)習(xí)經(jīng)過了從雛形到成熟、從簡單到復(fù)雜的發(fā)展,在學(xué)術(shù)界和業(yè)界積累了大量理論和技術(shù)。現(xiàn)在的發(fā)展方向趨向于多元化。這一方面是因?yàn)榇罅慨a(chǎn)品正處于研發(fā)階段,另一方面計(jì)算機(jī)科學(xué)家也在做一些關(guān)于深度學(xué)習(xí)的更加細(xì)致的研究。
當(dāng)然,作為一個(gè)綜合性的學(xué)科,除了以圖像識(shí)別為核心的發(fā)展歷程,深度學(xué)習(xí)在語音分析和自然語言處理上也有其各自的發(fā)展過程。同時(shí),多種神經(jīng)網(wǎng)絡(luò)、多媒體形態(tài)的結(jié)合,正在成為研究的熱點(diǎn)。比如結(jié)合圖像和語言處理的自動(dòng)給圖片配字幕(Image Captioning)就是一個(gè)具有挑戰(zhàn)的課題。
需要指出的是,神經(jīng)網(wǎng)絡(luò)的實(shí)現(xiàn)并非只有上述這一種方法,一些現(xiàn)階段沒有得到廣泛使用的網(wǎng)絡(luò)結(jié)構(gòu),比如如自適應(yīng)共振理論網(wǎng)絡(luò)、Hopfield網(wǎng)絡(luò)以及受限玻爾茲曼機(jī)(Restricted Boltzmann Machine)也可能在未來提供整個(gè)行業(yè)的前行動(dòng)力。可以肯定,雖然現(xiàn)在深度學(xué)習(xí)還是一個(gè)似乎縈繞著高級(jí)和神秘光環(huán)的存在,但在不久的將來,這件超級(jí)武器將會(huì)成為大小公司的基本技術(shù)。
審核編輯:郭婷
-
人工智能
+關(guān)注
關(guān)注
1791文章
47314瀏覽量
238617 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8420瀏覽量
132680 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5503瀏覽量
121192
發(fā)布評(píng)論請先 登錄
相關(guān)推薦
詳解深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)與卷積神經(jīng)網(wǎng)絡(luò)的應(yīng)用

【案例分享】基于BP算法的前饋神經(jīng)網(wǎng)絡(luò)
卷積神經(jīng)網(wǎng)絡(luò)—深度卷積網(wǎng)絡(luò):實(shí)例探究及學(xué)習(xí)總結(jié)
解析深度學(xué)習(xí):卷積神經(jīng)網(wǎng)絡(luò)原理與視覺實(shí)踐
使用keras搭建神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)基于深度學(xué)習(xí)算法的股票價(jià)格預(yù)測
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》講義
BP神經(jīng)網(wǎng)絡(luò)模型與學(xué)習(xí)算法
基于遞歸神經(jīng)網(wǎng)絡(luò)和前饋神經(jīng)網(wǎng)絡(luò)的深度學(xué)習(xí)預(yù)測算法
3小時(shí)學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)課件下載





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論