") 數(shù)據(jù)結(jié)構(gòu)的存儲(chǔ)方式及基本操作
數(shù)據(jù)結(jié)構(gòu)的存儲(chǔ)方式及基本操作
這是好久之前的一篇文章 [學(xué)習(xí)數(shù)據(jù)結(jié)構(gòu)的框架思維]的修訂版。之前那篇文章收到廣泛好評(píng),沒(méi)看過(guò)也沒(méi)關(guān)系,這篇文章會(huì)涵蓋之前的所有內(nèi)容,并且會(huì)舉很多代碼的實(shí)例,談?wù)勅绾问褂每蚣芩季S,并且給對(duì)于算法無(wú)從下手的朋友給一點(diǎn)具體可執(zhí)行的刷題建議。
首先,這里講的都是普通的數(shù)據(jù)結(jié)構(gòu)和算法,咱不是搞競(jìng)賽的,野路子出生,只解決常規(guī)的問(wèn)題,以面試為最終目標(biāo)。另外,以下是我個(gè)人的經(jīng)驗(yàn)的總結(jié),沒(méi)有哪本算法書會(huì)寫這些東西,所以請(qǐng)讀者試著理解我的角度,別糾結(jié)于細(xì)節(jié)問(wèn)題,因?yàn)檫@篇文章就是對(duì)數(shù)據(jù)結(jié)構(gòu)和算法建立一個(gè)框架性的認(rèn)識(shí)。
從整體到細(xì)節(jié),自頂向下,從抽象到具體的框架思維是通用的,不只是學(xué)習(xí)數(shù)據(jù)結(jié)構(gòu)和算法,學(xué)習(xí)其他任何知識(shí)都是高效的。
先說(shuō)數(shù)據(jù)結(jié)構(gòu),然后再說(shuō)算法。
一、數(shù)據(jù)結(jié)構(gòu)的存儲(chǔ)方式
數(shù)據(jù)結(jié)構(gòu)的存儲(chǔ)方式只有兩種: 數(shù)組(順序存儲(chǔ))和鏈表(鏈?zhǔn)酱鎯?chǔ)) 。
這句話怎么理解,不是還有散列表、棧、隊(duì)列、堆、樹、圖等等各種數(shù)據(jù)結(jié)構(gòu)嗎?
我們分析問(wèn)題,一定要有遞歸的思想,自頂向下,從抽象到具體。你上來(lái)就列出這么多,那些都屬于「上層建筑」,而數(shù)組和鏈表才是「結(jié)構(gòu)基礎(chǔ)」。因?yàn)槟切┒鄻踊臄?shù)據(jù)結(jié)構(gòu),究其源頭,都是在鏈表或者數(shù)組上的特殊操作,API 不同而已。
比如說(shuō) 「隊(duì)列 」 、 「棧」 這兩種數(shù)據(jù)結(jié)構(gòu)既可以使用鏈表也可以使用數(shù)組實(shí)現(xiàn)。用數(shù)組實(shí)現(xiàn),就要處理擴(kuò)容縮容的問(wèn)題;用鏈表實(shí)現(xiàn),沒(méi)有這個(gè)問(wèn)題,但需要更多的內(nèi)存空間存儲(chǔ)節(jié)點(diǎn)指針。
「圖」 的兩種表示方法,鄰接表就是鏈表,鄰接矩陣就是二維數(shù)組。鄰接矩陣判斷連通性迅速,并可以進(jìn)行矩陣運(yùn)算解決一些問(wèn)題,但是如果圖比較稀疏的話很耗費(fèi)空間。鄰接表比較節(jié)省空間,但是很多操作的效率上肯定比不過(guò)鄰接矩陣。
「散列表」 就是通過(guò)散列函數(shù)把鍵映射到一個(gè)大數(shù)組里。而且對(duì)于解決散列沖突的方法,拉鏈法需要鏈表特性,操作簡(jiǎn)單,但需要額外的空間存儲(chǔ)指針;線性探查法就需要數(shù)組特性,以便連續(xù)尋址,不需要指針的存儲(chǔ)空間,但操作稍微復(fù)雜些。
「樹」 ,用數(shù)組實(shí)現(xiàn)就是「堆」,因?yàn)椤付选故且粋€(gè)完全二叉樹,用數(shù)組存儲(chǔ)不需要節(jié)點(diǎn)指針,操作也比較簡(jiǎn)單;用鏈表實(shí)現(xiàn)就是很常見的那種「樹」,因?yàn)椴灰欢ㄊ峭耆鏄洌圆贿m合用數(shù)組存儲(chǔ)。為此,在這種鏈表「樹」結(jié)構(gòu)之上,又衍生出各種巧妙的設(shè)計(jì),比如二叉搜索樹、AVL 樹、紅黑樹、區(qū)間樹、B 樹等等,以應(yīng)對(duì)不同的問(wèn)題。
了解 Redis 數(shù)據(jù)庫(kù)的朋友可能也知道,Redis 提供列表、字符串、集合等等幾種常用數(shù)據(jù)結(jié)構(gòu),但是對(duì)于每種數(shù)據(jù)結(jié)構(gòu),底層的存儲(chǔ)方式都至少有兩種,以便于根據(jù)存儲(chǔ)數(shù)據(jù)的實(shí)際情況使用合適的存儲(chǔ)方式。
綜上,數(shù)據(jù)結(jié)構(gòu)種類很多,甚至你也可以發(fā)明自己的數(shù)據(jù)結(jié)構(gòu),但是底層存儲(chǔ)無(wú)非數(shù)組或者鏈表, 二者的優(yōu)缺點(diǎn)如下 :
數(shù)組由于是緊湊連續(xù)存儲(chǔ),可以隨機(jī)訪問(wèn),通過(guò)索引快速找到對(duì)應(yīng)元素,而且相對(duì)節(jié)約存儲(chǔ)空間。但正因?yàn)檫B續(xù)存儲(chǔ),內(nèi)存空間必須一次性分配夠,所以說(shuō)數(shù)組如果要擴(kuò)容,需要重新分配一塊更大的空間,再把數(shù)據(jù)全部復(fù)制過(guò)去,時(shí)間復(fù)雜度 O(N);而且你如果想在數(shù)組中間進(jìn)行插入和刪除,每次必須搬移后面的所有數(shù)據(jù)以保持連續(xù),時(shí)間復(fù)雜度 O(N)。
鏈表因?yàn)樵夭贿B續(xù),而是靠指針指向下一個(gè)元素的位置,所以不存在數(shù)組的擴(kuò)容問(wèn)題;如果知道某一元素的前驅(qū)和后驅(qū),操作指針即可刪除該元素或者插入新元素,時(shí)間復(fù)雜度 O(1)。但是正因?yàn)榇鎯?chǔ)空間不連續(xù),你無(wú)法根據(jù)一個(gè)索引算出對(duì)應(yīng)元素的地址,所以不能隨機(jī)訪問(wèn);而且由于每個(gè)元素必須存儲(chǔ)指向前后元素位置的指針,會(huì)消耗相對(duì)更多的儲(chǔ)存空間。
二、數(shù)據(jù)結(jié)構(gòu)的基本操作
對(duì)于任何數(shù)據(jù)結(jié)構(gòu),其基本操作無(wú)非遍歷 + 訪問(wèn),再具體一點(diǎn)就是:增刪查改。
數(shù)據(jù)結(jié)構(gòu)種類很多,但它們存在的目的都是在不同的應(yīng)用場(chǎng)景,盡可能高效地增刪查改 。話說(shuō)這不就是數(shù)據(jù)結(jié)構(gòu)的使命么?
如何遍歷 + 訪問(wèn)?我們?nèi)匀粡淖罡邔觼?lái)看,各種數(shù)據(jù)結(jié)構(gòu)的遍歷 + 訪問(wèn)無(wú)非兩種形式:線性的和非線性的。
線性就是 for/while 迭代為代表,非線性就是遞歸為代表。再具體一步,無(wú)非以下幾種框架:
數(shù)組遍歷框架,典型的線性迭代結(jié)構(gòu):
void traverse(int[] arr) {
for (int i = 0; i < arr.length; i++) {
// 迭代訪問(wèn) arr[i]
}
}
鏈表遍歷框架,兼具迭代和遞歸結(jié)構(gòu):
/* 基本的單鏈表節(jié)點(diǎn) */
class ListNode {
int val;
ListNode next;
}
void traverse(ListNode head) {
for (ListNode p = head; p != null; p = p.next) {
// 迭代訪問(wèn) p.val
}
}
void traverse(ListNode head) {
// 遞歸訪問(wèn) head.val
traverse(head.next)
}
二叉樹遍歷框架,典型的非線性遞歸遍歷結(jié)構(gòu):
/* 基本的二叉樹節(jié)點(diǎn) */
class TreeNode {
int val;
TreeNode left, right;
}
void traverse(TreeNode root) {
traverse(root.left)
traverse(root.right)
}
你看二叉樹的遞歸遍歷方式和鏈表的遞歸遍歷方式,相似不?再看看二叉樹結(jié)構(gòu)和單鏈表結(jié)構(gòu),相似不?如果再多幾條叉,N 叉樹你會(huì)不會(huì)遍歷?
二叉樹框架可以擴(kuò)展為 N 叉樹的遍歷框架:
/* 基本的 N 叉樹節(jié)點(diǎn) */
class TreeNode {
int val;
TreeNode[] children;
}
void traverse(TreeNode root) {
for (TreeNode child : root.children)
traverse(child)
}
N 叉樹的遍歷又可以擴(kuò)展為圖的遍歷,因?yàn)閳D就是好幾 N 叉棵樹的結(jié)合體。你說(shuō)圖是可能出現(xiàn)環(huán)的?這個(gè)很好辦,用個(gè)布爾數(shù)組 visited 做標(biāo)記就行了,這里就不寫代碼了。
所謂框架,就是套路。不管增刪查改,這些代碼都是永遠(yuǎn)無(wú)法脫離的結(jié)構(gòu),你可以把這個(gè)結(jié)構(gòu)作為大綱,根據(jù)具體問(wèn)題在框架上添加代碼就行了,下面會(huì)具體舉例 。
三、算法刷題指南
首先要明確的是, 數(shù)據(jù)結(jié)構(gòu)是工具,算法是通過(guò)合適的工具解決特定問(wèn)題的方法 。也就是說(shuō),學(xué)習(xí)算法之前,最起碼得了解那些常用的數(shù)據(jù)結(jié)構(gòu),了解它們的特性和缺陷。
那么該如何在 LeetCode 刷題呢?之前的文章 [算法學(xué)習(xí)之路]寫過(guò)一些,什么按標(biāo)簽刷,堅(jiān)持下去云云。現(xiàn)在距那篇文章已經(jīng)過(guò)去將近一年了,我不想說(shuō)那些不痛不癢的話了,直接說(shuō)具體的建議:
先刷二叉樹,先刷二叉樹,先刷二叉樹 !
這是我這刷題的親身體會(huì),下圖是我從 2018/10 到 2019/10 這一年的心路歷程:
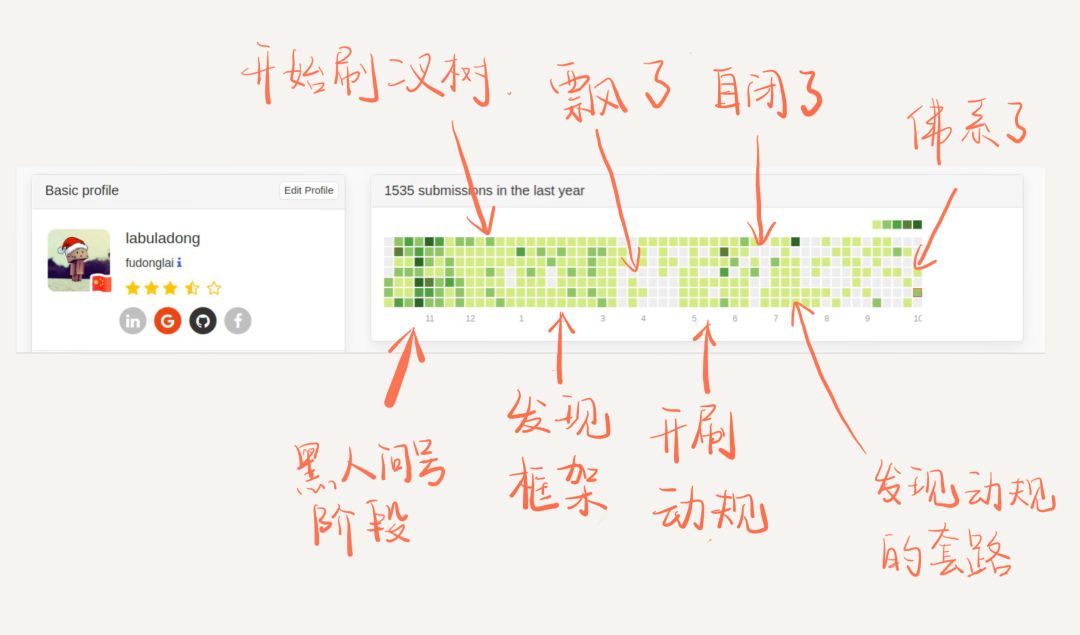
公眾號(hào)文章的閱讀數(shù)據(jù)顯示,大部分人對(duì)數(shù)據(jù)結(jié)構(gòu)相關(guān)的算法文章不感興趣,而是更關(guān)心動(dòng)規(guī)回溯分治等等技巧。為什么要先刷二叉樹呢, 因?yàn)槎鏄涫亲钊菀着囵B(yǎng)框架思維的,而且大部分算法技巧,本質(zhì)上都是樹的遍歷問(wèn)題 。
刷二叉樹看到題目沒(méi)思路?根據(jù)很多讀者的問(wèn)題,其實(shí)大家不是沒(méi)思路,只是沒(méi)有理解我們說(shuō)的「框架」是什么。 不要小看這幾行破代碼,幾乎所有二叉樹的題目都是一套這個(gè)框架就出來(lái)了 。
void traverse(TreeNode root) {
// 前序遍歷
traverse(root.left)
// 中序遍歷
traverse(root.right)
// 后序遍歷
}
比如說(shuō)我隨便拿幾道題的解法出來(lái),不用管具體的代碼邏輯,只要看看框架在其中是如何發(fā)揮作用的就行。
LeetCode 124 題,難度 Hard,讓你求二叉樹中最大路徑和,主要代碼如下:
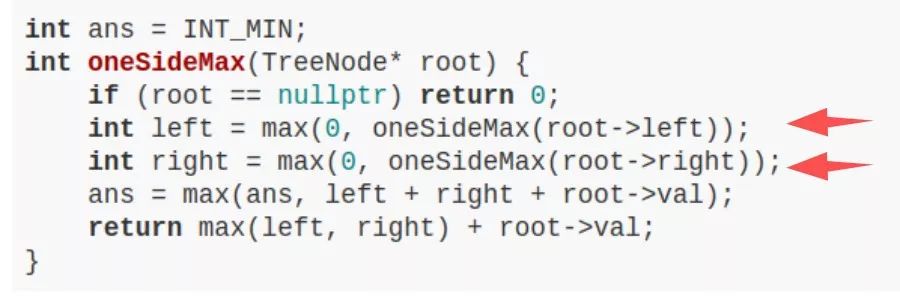
看出來(lái)了嗎,這就是個(gè)后序遍歷嘛。
LeetCode 105 題,難度 Medium,讓你根據(jù)前序遍歷和中序遍歷的結(jié)果還原一棵二叉樹,很經(jīng)典的問(wèn)題吧,主要代碼如下:
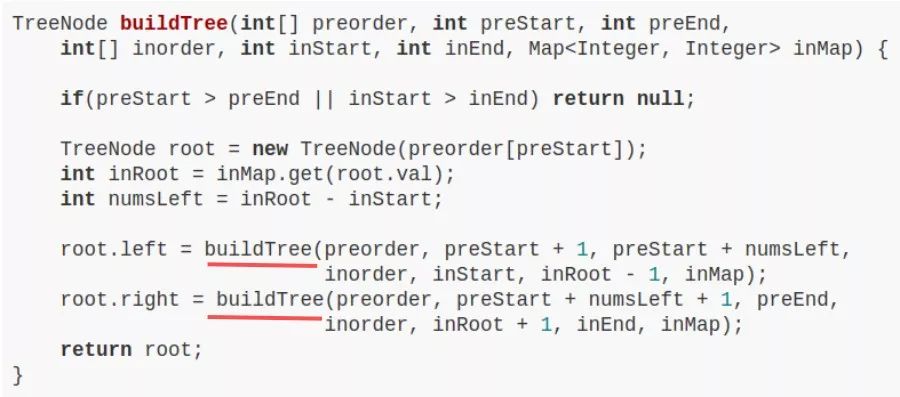
不要看這個(gè)函數(shù)的參數(shù)很多,只是為了控制數(shù)組索引而已,本質(zhì)上該算法也就是一個(gè)前序遍歷。
LeetCode 99 題,難度 Hard,恢復(fù)一棵 BST,主要代碼如下:

這不就是個(gè)中序遍歷嘛,對(duì)于一棵 BST 中序遍歷意味著什么,應(yīng)該不需要解釋了吧。
你看,Hard 難度的題目不過(guò)如此,而且還這么有規(guī)律可循,只要把框架寫出來(lái),然后往相應(yīng)的位置加?xùn)|西就行了,這不就是思路嗎。
剛開始刷二叉樹的題目,前 10 道也許有點(diǎn)難受;結(jié)合框架再做 20 道,也許你就有點(diǎn)自己的理解了;刷完整個(gè)專題,再去做什么回溯動(dòng)規(guī)分治專題,你就會(huì)發(fā)現(xiàn)只要涉及遞 歸的問(wèn)題,都是樹的問(wèn)題 。
直接舉例吧,說(shuō)幾道我們之前文章寫過(guò)的問(wèn)題。
[動(dòng)態(tài)規(guī)劃詳解]說(shuō)過(guò)湊零錢問(wèn)題,暴力解法就是遍歷一棵 N 叉樹:
def coinChange(coins: List[int], amount: int):
def dp(n):
if n == 0: return 0
if n < 0: return -1
res = float('INF')
for coin in coins:
subproblem = dp(n - coin)
# 子問(wèn)題無(wú)解,跳過(guò)
if subproblem == -1: continue
res = min(res, 1 + subproblem)
return res if res != float('INF') else -1
return dp(amount)
這么多代碼看不懂咋辦?直接提取出框架,就能看出核心思路了:
# 不過(guò)是一個(gè) N 叉樹的遍歷問(wèn)題而已
def dp(n):
for coin in coins:
dp(n - coin)

其實(shí)很多動(dòng)態(tài)規(guī)劃問(wèn)題就是在遍歷一棵樹,你如果對(duì)樹的遍歷操作爛熟于心,起碼知道怎么把思路轉(zhuǎn)化成代碼,也知道如何提取別人解法的核心思路。
再看看回溯算法,前文 [回溯算法詳解]干脆直接說(shuō)了,回溯算法就是個(gè) N 叉樹的前后序遍歷問(wèn)題,沒(méi)有例外。
比如 N 皇后問(wèn)題吧,主要代碼如下:
void backtrack(int[] nums, LinkedList) {
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
if (track.contains(nums[i]))
continue;
track.add(nums[i]);
// 進(jìn)入下一層決策樹
backtrack(nums, track);
track.removeLast();
}
/* 提取出 N 叉樹遍歷框架 */
void backtrack(int[] nums, LinkedList) {
for (int i = 0; i < nums.length; i++) {
backtrack(nums, track);
}
N 叉樹的遍歷框架,找出來(lái)了吧。你說(shuō),樹這種結(jié)構(gòu)重不重要?
綜上,對(duì)于算法無(wú)從下手的朋友來(lái)說(shuō),可以先刷樹的相關(guān)題目,試著從框架上看問(wèn)題,而不要糾結(jié)于細(xì)節(jié)問(wèn)題 。
糾結(jié)細(xì)節(jié)問(wèn)題,就比如糾結(jié) i 到底應(yīng)該加到 n 還是加到 n - 1,這個(gè)數(shù)組的大小到底應(yīng)該開 n 還是 n + 1 ?
從框架上看問(wèn)題,就是像我們這樣基于框架進(jìn)行抽取和擴(kuò)展,既可以在看別人解法時(shí)快速理解核心邏輯,也有助于找到我們自己寫解法時(shí)的思路方向。
當(dāng)然,如果細(xì)節(jié)出錯(cuò),你得不到正確的答案,但是只要有框架,你再錯(cuò)也錯(cuò)不到哪去,因?yàn)槟愕姆较蚴菍?duì)的。
但是,你要是心中沒(méi)有框架,那么你根本無(wú)法解題,給了你答案,你也不會(huì)發(fā)現(xiàn)這就是個(gè)樹的遍歷問(wèn)題。
這種思維是很重要的,[動(dòng)態(tài)規(guī)劃詳解] 中總結(jié)的找狀態(tài)轉(zhuǎn)移方程的幾步流程,有時(shí)候按照流程寫出解法,說(shuō)實(shí)話我自己都不知道為啥是對(duì)的,反正它就是對(duì)了。。。
這就是框架的力量,能夠保證你在快睡著的時(shí)候,依然能寫出正確的程序; 就算你啥都不會(huì),都能比別人高一個(gè)級(jí)別。
四、最后總結(jié)
數(shù)據(jù)結(jié)構(gòu)的基本存儲(chǔ)方式就是鏈?zhǔn)胶晚樞騼煞N,基本操作就是增刪查改,遍歷方式無(wú)非迭代和遞歸。
刷算法題建議從「樹」分類開始刷,結(jié)合框架思維,把這幾十道題刷完,對(duì)于樹結(jié)構(gòu)的理解應(yīng)該就到位了。這時(shí)候去看回溯、動(dòng)規(guī)、分治等算法專題,對(duì)思路的理解可能會(huì)更加深刻一些。
-
算法
+關(guān)注
關(guān)注
23文章
4629瀏覽量
93193 -
數(shù)據(jù)結(jié)構(gòu)
+關(guān)注
關(guān)注
3文章
573瀏覽量
40195 -
數(shù)組
+關(guān)注
關(guān)注
1文章
417瀏覽量
26003
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
快速介紹8種常用數(shù)據(jù)結(jié)構(gòu)
數(shù)據(jù)結(jié)構(gòu)
常見的數(shù)據(jù)結(jié)構(gòu)
數(shù)據(jù)結(jié)構(gòu)鏈表的基本操作
FlashDB如何解決存儲(chǔ)數(shù)據(jù)后擴(kuò)展數(shù)據(jù)結(jié)構(gòu)的問(wèn)題
GPIB命令的數(shù)據(jù)結(jié)構(gòu)
GPIB命令的數(shù)據(jù)結(jié)構(gòu)
數(shù)據(jù)結(jié)構(gòu)_嚴(yán)蔚敏

數(shù)據(jù)結(jié)構(gòu)是什么_數(shù)據(jù)結(jié)構(gòu)有什么用
什么是數(shù)據(jù)結(jié)構(gòu)?為什么要學(xué)習(xí)數(shù)據(jù)結(jié)構(gòu)?數(shù)據(jù)結(jié)構(gòu)的應(yīng)用實(shí)例分析
這些程序員必須知道的數(shù)據(jù)結(jié)構(gòu)你知道多少
常見的數(shù)據(jù)結(jié)構(gòu)有哪些
嵌入式軟件常見的8種數(shù)據(jù)結(jié)構(gòu)

epoll的基礎(chǔ)數(shù)據(jù)結(jié)構(gòu)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論