 如何在超大分辨率的圖片中檢測目標
如何在超大分辨率的圖片中檢測目標
本文通過一篇YOLT的文章引出超大分辨率的圖片遇到目標檢測任務該如何處理?此類問題一般出現在遙感領域和醫療影像中居多,我們先來分析超大圖像的目標檢測存在哪些問題,然后學習一下YOLT是如何解決這些問題的,最后結合現有技術探討目前的可行性方案。
1
當超大分辨率圖像邂逅目標檢測任務
曾經有小伙伴問過我針對超大分辨率的圖像如何做目標檢測任務?
我們先思考一下超大分辨率數據在哪些場景中會出現,比如衛星地圖做建筑物、樓宇的檢測:
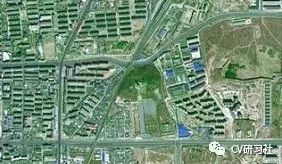
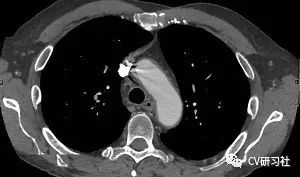
在醫療影像中做病灶體的檢測:
在無人機航拍圖中做船舶、車輛、房屋等檢測:

是否可以沿用通用框架做該類圖片的目標檢測呢?
輸入如此大分辨率的圖片到網絡中,最直接的問題就是機器的顯存爆掉,無法進行訓練任務。
如果你真的有一個非常牛逼的集群直接訓練大尺寸圖像,最后的預測結果恐怕也不盡如人意,原因出在大尺寸圖像中的目標往往只占5-10個像素點,檢測網絡一旦經過多次下采樣后,這些小目標的特征很難被提取到。
衛星地圖等數據非常稀有珍貴,不像無人駕駛的開源數據有幾十萬幾百萬張的量級,如何高效的利用高質量的訓練圖片也是關鍵所在。
所以直接硬上通用模型檢測出來的效果可能是這樣的,要么伴隨著圖片的resize,目標被縮放沒了;要么基于N×N網格的預測造成密集連續目標的漏檢:

此類任務的難點或者優化方向在哪里?
它的核心在于四個方向:
如何處理高分辨的輸入
如何提高密集小目標檢測
如何解決類別不平衡問題
如何利用少量的訓練數據
下面我們通過一篇名為You Only Look Twice的文章來分析上述幾個問題,名稱有點蹭熱度的嫌疑哦,不過誰讓YOLO系列那么火,大家都喜歡在它的框架上改改發文章呢!
2
You Only Look Twice
《Rapid Multi-Scale Object Detection In Satellite Imagery》這篇文章描述了大尺寸圖像目標檢測的常規方法,總的來說就是對超大分辨率的圖像進行滑窗裁剪成多個子圖,然后對每一個子圖進行目標檢測,最后將所有子圖的結果拼接后進行NMS過濾。
數據端
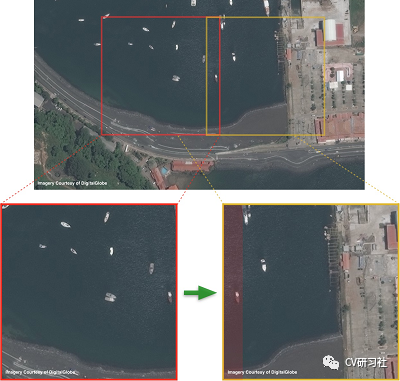
對超大分辨率圖片進行滑窗裁剪,如下圖所示,一個16000×16000像素的圖片,采用416×416像素的滑窗,最后生成約1500個子圖。

文章指出在滑窗裁剪的時候必須有15%的重疊區域,原因是如果一個目標剛好處于窗口邊緣被切分成2塊,本身目標所占像素就少又被截斷會造成更加難以檢測。但是重復部分會帶來同一個目標出現多個檢測框的問題,目前通過將所有子圖的檢測結果合并起來采用NMS處理進行過濾。
在衛星、遙感、航拍等圖片中,目標物體往往存在方向信息,如何提高目標檢測的旋轉不變性呢?在YOLT中通過數據增廣的方式旋轉圖片生成更多形狀的物體從而緩解問題。但是小編認為該方法治標不治本,輸出結果仍然是規則的矩形框,一旦遇到長條形物體,比如輪船。預測的矩形框會引入很多冗余區域。可以嘗試在損失函數中增加旋轉角進行學習。

網絡端
基于YOLOv2的結構做了一些改進,在YOLO系列或者很多檢測網絡都進行了32倍的下采樣,但是在遙感地圖等超大分辨率圖片中,目標物體所占像素本身就很少,經過32倍下采樣后,基本無法有效檢測。所以YOLT減少了下采樣的比例收縮到16倍并增加網絡的層數提供特征提取能力。
文章借助YOLOv2中的PassThrough層,融合深淺特征圖的特征目的是提升對小目標的檢測效果。當然這一操作完全可以考慮由PAN替代,在FPN上采樣融合的特征金字塔之后,又增加了一個下采樣融合的特征金字塔。
本文并沒有提到類別不平衡問題,但是任何目標檢測任務其實都存在前后背景的不平衡,一般會從三種方法進行考慮,其一是做數據的上采樣和下采樣來平衡不同類別之間的數據量;其二是采用某些數據增廣的手段來增多前景目標在一張圖像中的占比;其三是通過設計損失函數通過權重控制不同類別的優化力度。
3
如何處理高分辨的輸入圖像?
較常見的方式就是像上述文章提到的對一張超大分辨率的圖片切割成多個子圖,但是在這一過程中存在幾個問題,比如:
目標位于切割邊緣怎么辦?
切割的圖片大小如何設置?
目標切割的問題在上面已經提過,可以用重疊切割的方法解決目標被截斷的問題。
假設數據集的圖片尺寸不同的前提下,我們可以從結果端反向思考切割尺寸的問題,一般會設置一個固定的子圖尺寸比如416×416,但是原圖可能無法剛好切割成整數個子圖,所以對最邊緣的子圖可以采用letterbox的方式縮放到416的尺寸,相比直接resize能夠保留物體特征。
4
如何提高密集小目標檢測?
在目標檢測領域中,小目標檢測一直都是其中一個難點。針對該問題,近些年也提出了不少優化的方式:
圖像金字塔進行多尺度訓練。將原始圖像生成多個不同分辨率的圖像金字塔,再對每層金字塔用固定輸入分辨率的分類器在該層滑動來檢測目標。不過此方法需要對圖像做多次的特征提取,速度太慢。該方法也有改進版本,如SNIP網絡只訓練合適尺寸的目標,當真值的尺寸和Anchor接近時才訓練檢測器,過大過小的均丟棄。
特征金字塔融合淺層和深層信息,如FPN和PAN等。通過各層融合的方式從淺層網絡中學習更多的細節特征,從深層網絡中學習更多的語義特征。
設計與小目標尺寸匹配的Anchor。不同任務的檢測目標尺寸均有差異,可以根據先驗知識,采用手工或者聚類的方式離線得到一定個數的Anchor。
采用空洞卷積減少下采樣次數,其目的是考慮下采樣會丟失圖片的部分信息,而空洞卷積能夠在不增加參數量的同時具有更大的感受野,提供降低采樣次數的一種思路。
-
圖像
+關注
關注
2文章
1085瀏覽量
40477 -
分辨率
+關注
關注
2文章
1065瀏覽量
41946
原文標題:如何在超大分辨率的圖片中檢測目標?
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何提高透鏡成像的分辨率
HDMI接口支持哪些視頻分辨率

Moritex 5X 高分辨率遠心鏡頭 助力晶圓檢測

VR顯示器分辨率的選擇
伺服編碼器分辨率是什么意思
基于CNN的圖像超分辨率示例
電流探頭的分辨率和靈敏度有關系嗎?

psoc的規格再驅動lcd屏的時候,是否可以驅動RGB/RGB666的屏?支持的最大分辨率是多少?
編碼器分辨率是什么意思 編碼器分辨率和脈沖數的關系

電容觸摸屏的分辨率怎么調
什么是DSR(動態超級分辨率)?DSR是做什么的?如何開啟DSR技術?
淺談相機的圖像分辨率





 工商網監
工商網監
評論