 數據結構和算法學習筆記(1)
數據結構和算法學習筆記(1)
這是好久之前的一篇文章學習數據結構的框架思維的修訂版。之前那篇文章收到廣泛好評,沒看過也沒關系,這篇文章會涵蓋之前的所有內容,并且會舉很多代碼的實例,談談如何使用框架思維,并且給對于算法無從下手的朋友給一點具體可執行的刷題建議。
首先,這里講的都是普通的數據結構和算法,咱不是搞競賽的,野路子出生,只解決常規的問題,以面試為最終目標。另外,以下是我個人的經驗的總結,沒有哪本算法書會寫這些東西,所以請讀者試著理解我的角度,別糾結于細節問題,因為這篇文章就是對數據結構和算法建立一個框架性的認識。
從整體到細節,自頂向下,從抽象到具體的框架思維是通用的,不只是學習數據結構和算法,學習其他任何知識都是高效的。
先說數據結構,然后再說算法。
一、數據結構的存儲方式
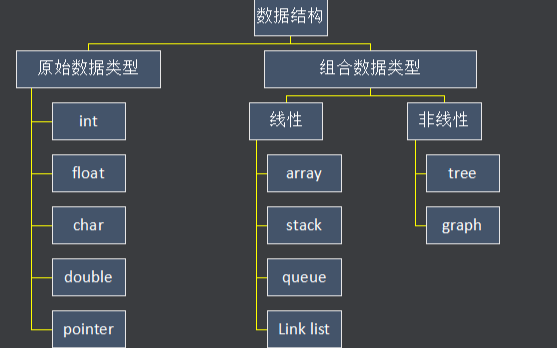
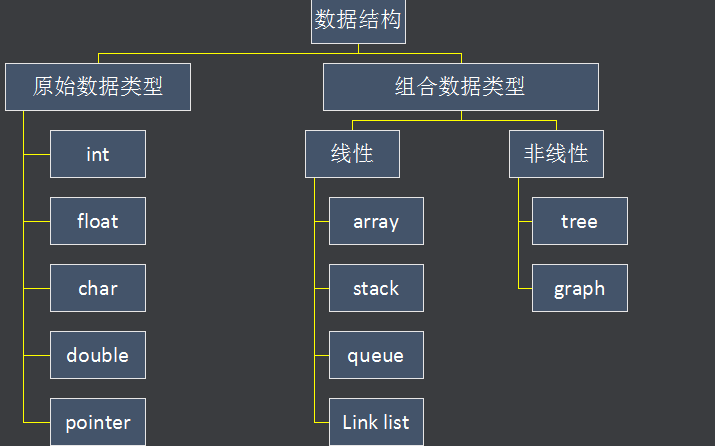
數據結構的存儲方式只有兩種: 數組(順序存儲)和鏈表(鏈式存儲) 。
這句話怎么理解,不是還有散列表、棧、隊列、堆、樹、圖等等各種數據結構嗎?
我們分析問題,一定要有遞歸的思想,自頂向下,從抽象到具體。你上來就列出這么多,那些都屬于「上層建筑」,而數組和鏈表才是「結構基礎」。因為那些多樣化的數據結構,究其源頭,都是在鏈表或者數組上的特殊操作,API 不同而已。
比如說 「隊列 」 、 「棧」 這兩種數據結構既可以使用鏈表也可以使用數組實現。用數組實現,就要處理擴容縮容的問題;用鏈表實現,沒有這個問題,但需要更多的內存空間存儲節點指針。
「圖」 的兩種表示方法,鄰接表就是鏈表,鄰接矩陣就是二維數組。鄰接矩陣判斷連通性迅速,并可以進行矩陣運算解決一些問題,但是如果圖比較稀疏的話很耗費空間。鄰接表比較節省空間,但是很多操作的效率上肯定比不過鄰接矩陣。
「散列表」 就是通過散列函數把鍵映射到一個大數組里。而且對于解決散列沖突的方法,拉鏈法需要鏈表特性,操作簡單,但需要額外的空間存儲指針;線性探查法就需要數組特性,以便連續尋址,不需要指針的存儲空間,但操作稍微復雜些。
「樹」 ,用數組實現就是「堆」,因為「堆」是一個完全二叉樹,用數組存儲不需要節點指針,操作也比較簡單;用鏈表實現就是很常見的那種「樹」,因為不一定是完全二叉樹,所以不適合用數組存儲。為此,在這種鏈表「樹」結構之上,又衍生出各種巧妙的設計,比如二叉搜索樹、AVL 樹、紅黑樹、區間樹、B 樹等等,以應對不同的問題。
了解 Redis 數據庫的朋友可能也知道,Redis 提供列表、字符串、集合等等幾種常用數據結構,但是對于每種數據結構,底層的存儲方式都至少有兩種,以便于根據存儲數據的實際情況使用合適的存儲方式。
綜上,數據結構種類很多,甚至你也可以發明自己的數據結構,但是底層存儲無非數組或者鏈表, 二者的優缺點如下 :
數組由于是緊湊連續存儲,可以隨機訪問,通過索引快速找到對應元素,而且相對節約存儲空間。但正因為連續存儲,內存空間必須一次性分配夠,所以說數組如果要擴容,需要重新分配一塊更大的空間,再把數據全部復制過去,時間復雜度 O(N);而且你如果想在數組中間進行插入和刪除,每次必須搬移后面的所有數據以保持連續,時間復雜度 O(N)。
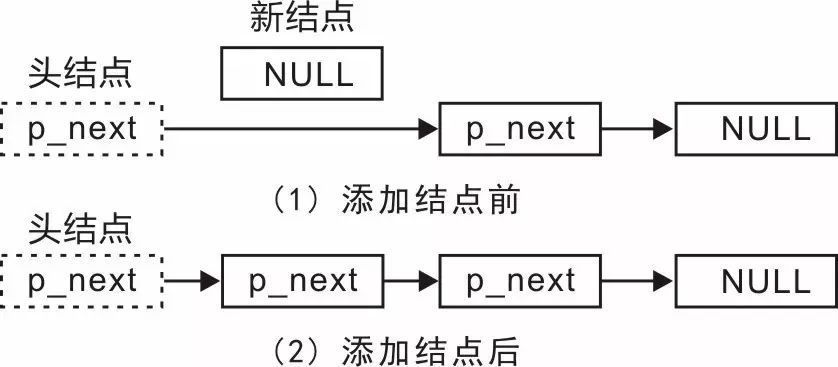
鏈表因為元素不連續,而是靠指針指向下一個元素的位置,所以不存在數組的擴容問題;如果知道某一元素的前驅和后驅,操作指針即可刪除該元素或者插入新元素,時間復雜度 O(1)。但是正因為存儲空間不連續,你無法根據一個索引算出對應元素的地址,所以不能隨機訪問;而且由于每個元素必須存儲指向前后元素位置的指針,會消耗相對更多的儲存空間。
二、數據結構的基本操作
對于任何數據結構,其基本操作無非遍歷 + 訪問,再具體一點就是:增刪查改。
數據結構種類很多,但它們存在的目的都是在不同的應用場景,盡可能高效地增刪查改 。話說這不就是數據結構的使命么?
如何遍歷 + 訪問?我們仍然從最高層來看,各種數據結構的遍歷 + 訪問無非兩種形式:線性的和非線性的。
線性就是 for/while 迭代為代表,非線性就是遞歸為代表。再具體一步,無非以下幾種框架:
數組遍歷框架,典型的線性迭代結構:
void traverse(int[] arr) {
for (int i = 0; i < arr.length; i++) {
// 迭代訪問 arr[i]
}
}
鏈表遍歷框架,兼具迭代和遞歸結構:
/* 基本的單鏈表節點 */
class ListNode {
int val;
ListNode next;
}
void traverse(ListNode head) {
for (ListNode p = head; p != null; p = p.next) {
// 迭代訪問 p.val
}
}
void traverse(ListNode head) {
// 遞歸訪問 head.val
traverse(head.next)
}
二叉樹遍歷框架,典型的非線性遞歸遍歷結構:
/* 基本的二叉樹節點 */
class TreeNode {
int val;
TreeNode left, right;
}
void traverse(TreeNode root) {
traverse(root.left)
traverse(root.right)
}
你看二叉樹的遞歸遍歷方式和鏈表的遞歸遍歷方式,相似不?再看看二叉樹結構和單鏈表結構,相似不?如果再多幾條叉,N 叉樹你會不會遍歷?
二叉樹框架可以擴展為 N 叉樹的遍歷框架:
/* 基本的 N 叉樹節點 */
class TreeNode {
int val;
TreeNode[] children;
}
void traverse(TreeNode root) {
for (TreeNode child : root.children)
traverse(child)
}
N 叉樹的遍歷又可以擴展為圖的遍歷,因為圖就是好幾 N 叉棵樹的結合體。你說圖是可能出現環的?這個很好辦,用個布爾數組 visited 做標記就行了,這里就不寫代碼了。
所謂框架,就是套路。不管增刪查改,這些代碼都是永遠無法脫離的結構,你可以把這個結構作為大綱,根據具體問題在框架上添加代碼就行了,下面會具體舉例 。
-
算法
+關注
關注
23文章
4629瀏覽量
93188 -
數據結構
+關注
關注
3文章
573瀏覽量
40190 -
數組
+關注
關注
1文章
417瀏覽量
26001
發布評論請先 登錄
相關推薦
數據結構與算法分析(Java版)(pdf)

為什么要學習數據結構?數據結構的應用詳細資料概述免費下載
什么是數據結構?為什么要學習數據結構?數據結構的應用實例分析
數據結構和算法學習筆記(2)





 工商網監
工商網監
評論