") 如何用Python自動獲取排班人員
如何用Python自動獲取排班人員
總體思路是對比班次的開始時間和結(jié)束時間,
計算出當前的班次,
再根據(jù)班次得出當前的值班人員,
最后用while循環(huán),實時刷新當前的值班人員,
當然也可以去個重,如果這個周期和上個周期的值班人員一樣,不顯示,如果不一樣再顯示出來也可以,更具有實用性
import time
from datetime import datetime
# 值班時間表,時間用字符串表示,看起來清晰一些
# 中班分層兩個key,是為了下面對比時間方便
schedule_dict = {
'早班': ['8:30', '16:30'],
'中班-昨天': ["16:30", "00:00"],
'中班-今天': ["00:00", "00:30"],
'晚班': ["00:30", "8:30"]
}
# 值班人員表
attendants_dict = {
'早班': '張三',
'中班-昨天': '李四',
'中班-今天': '李四',
'晚班': '王五'
}
# 自動計算好當前時間的年、月、日
now_year = datetime.now().year
now_month = datetime.now().month
now_day = datetime.now().day
# 從 schedule_dict 中的字符串提取出數(shù)字的小時、分鐘
def get_hour_minute(hour_minute_string):
hour = int(str(hour_minute_string).split(':')[0])
minute = int(str(hour_minute_string).split(':')[1])
return hour, minute
def run():
# 值班人員列表初始化
on_call_list = []
# 遍歷值班時間的表
for k, v in schedule_dict.items():
# 把 schedule_dict中的字符串弄成數(shù)字的小時、分鐘
time_begin_str, time_end_str = v
hour_begin, minute_begin = get_hour_minute(time_begin_str)
hour_end, minute_end = get_hour_minute(time_end_str)
# 值班開始的時間
time_begin = datetime(year=now_year, month=now_month, day=now_day,
hour=hour_begin, minute=minute_begin)
# 值班結(jié)束的時間
time_end = datetime(year=now_year, month=now_month, day=now_day,
hour=hour_end, minute=minute_end)
# 現(xiàn)在的時間
time_now = datetime.now()
# 三個班次,會循環(huán)3次,對比現(xiàn)在的時間在哪個班次
if time_begin <= time_now <= time_end:
print('現(xiàn)在班次是:', k)
on_call_person = attendants_dict.get(k)
print('值班人員是:', on_call_person)
on_call_list.append(on_call_person)
no_on_call_list = list(set(attendants_dict.values()) - set(on_call_list))
print('休息的人分別是:', '、'.join(no_on_call_list))
print('-------------------------------------------------------------------')
def main():
while 1:
run()
# 這里可以30分鐘刷一次,改成1800就行,
# 這樣就能實時獲取當前值班的人,休息的人
time.sleep(10)
if __name__ == '__main__':
main()
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
計算
+關注
關注
2文章
451瀏覽量
38848 -
循環(huán)
+關注
關注
0文章
92瀏覽量
16019
發(fā)布評論請先 登錄
相關推薦
為何運維人員要學Python?
,當你做出一套運維自動化系統(tǒng)的時候,你的價值將得到顯現(xiàn),那么運維人員如何學好Python呢?今天只談學習方法,不談知識。1、學習編程不止是學習語法,需要學習算法(計算思維、解決問題的方法、編程思路
發(fā)表于 02-02 18:55
什么是磁力鏈接?如何用Python獲取磁力種子?
通過磁力就可以獲取種子文件從而進行下載,這跟直接使用種子下載時一個道理的,只是少了從磁力到種子文件的一個過程而已。
如何用python爬取抖音app數(shù)據(jù)
記錄一下如何用python爬取app數(shù)據(jù),本文以爬取抖音視頻app為例。
如何用Python計算提高機器學習算法和結(jié)果
本文將簡要介紹常用的距離度量方法、它們的工作原理、如何用Python計算它們以及何時使用它們。這樣可以加深知識和理解,提高機器學習算法和結(jié)果。
發(fā)表于 10-31 10:58
?639次閱讀

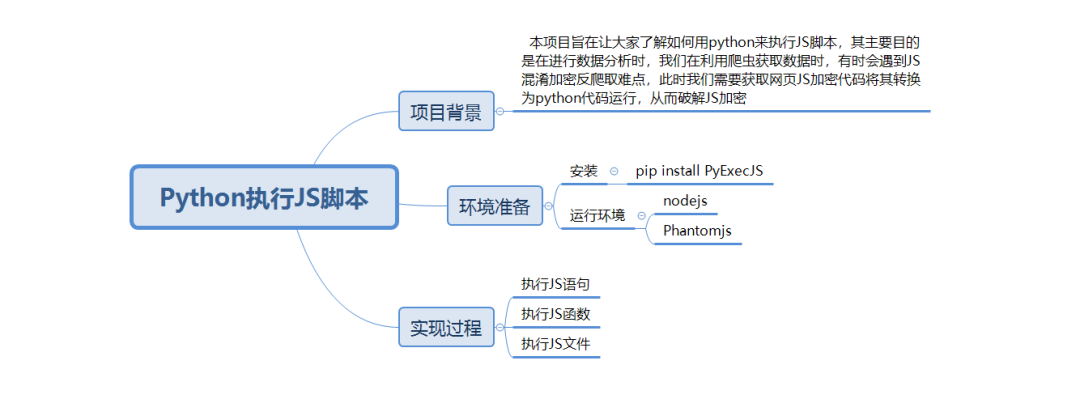
Python怎么玩轉(zhuǎn)JS腳本
本項目旨在讓大家了解如何用Python來執(zhí)行JS腳本,其主要目的是在進行數(shù)據(jù)
分析時,需要利用爬蟲獲取數(shù)據(jù),有時會遇到JS混淆加密反爬取難點,此時我們需
要獲取網(wǎng)頁JS加密代碼將其
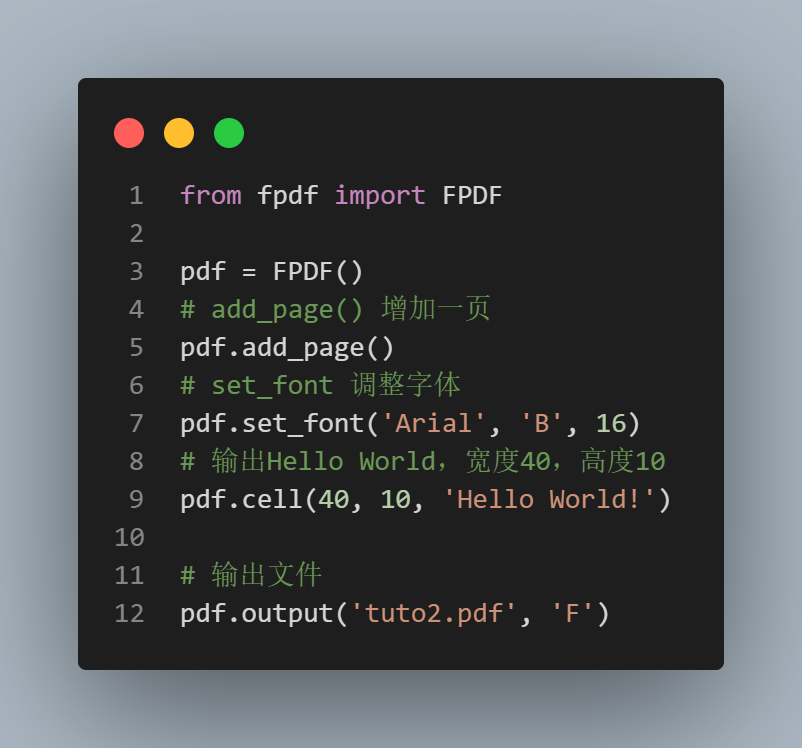
Python怎么批量生成PDF文檔
這種模板套用的場景下,使用Python進行自動化就尤為方便,用最短的時間辦最高效的事。
今天就給大家講講如何用Python自動套用模板

python有什么用 如何用python創(chuàng)建數(shù)據(jù)庫
python有什么用 如何用python創(chuàng)建數(shù)據(jù)庫 Python是一種高級編程語言,可以用于開發(fā)各種類型的應用程序和工具。它的廣泛應用使它在編程領域中極為受歡迎。
如何用Python自動套用模板批量生成PDF文檔
今天就給大家講講如何用Python自動套用模板批量生成的PDF文檔。 1.準備 開始之前,你要確保Python和pip已經(jīng)成功安裝在電腦上噢,如果沒有,請訪問這篇文章: 超詳細
yfinance:獲取數(shù)據(jù)的Python第三方模塊
yfinance 是一個使用 Yahoo! 獲取數(shù)據(jù)的 Python 第三方模塊。它支持獲取最細到1分鐘級的歷史數(shù)據(jù)及股票基本面數(shù)據(jù),是免費獲得美股分鐘級及以上粒度數(shù)據(jù)的不二之選。 1.準備 開始
如何用Python來實現(xiàn)文件系統(tǒng)的操作功能
就來介紹一下如何用 Python 來實現(xiàn)這些功能 輸出當前的路徑 我們可以通過 Python 當中的 OS 庫來獲取當前文件所在的位置 import os os .getcwd() 路

如何用Python自動套用模板批量生成PDF文檔
辦最高效的事。 今天就給大家講講如何用Python自動套用模板批量生成下方這樣的PDF文檔。 1.準備 開始之前,你要確保Python和pip已經(jīng)成功安裝在電腦上噢,如果沒有,請訪問這





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論