 YOLOv8 來啦!一文帶你解讀 YOLO"內卷"期的模型選型以及在 NGC 飛槳容器中快速體驗!
YOLOv8 來啦!一文帶你解讀 YOLO"內卷"期的模型選型以及在 NGC 飛槳容器中快速體驗!
本次為大家帶來 YOLOv8、PP-YOLOE+等 YOLO 全系列體驗。歡迎廣大開發者使用 NVIDIA 與飛槳聯合深度適配的 NGC 飛槳容器,在 NVIDIA GPU 上體驗 PaddleDetection v2.5 的新特性。
PaddleDetection 快速體驗 YOLO 全系列模型
回顧整個虎年,堪稱 YOLO 內卷元年,各路 YOLO 系列神仙打架,各顯神通。一開始大部分用戶做項目做實驗還是使用的 YOLOv5,然后 YOLOv6、YOLOv7、PP-YOLOE+、DAMO-YOLO、RTMDet 就接踵而至,于是就在自己的數據集逐一嘗試,好不容易把這些下餃子式的 YOLO 模型訓練完測試完,忙完工作準備回家過年時,YOLOv8 又閃電發布,YOLOv6 又更新了 3.0 版本...用戶還得跟進繼續訓練測試,其實很多時候就是重復工作。此外換模型訓練調參也會引入更多的不確定性,而且往往業務數據集大則幾十萬張圖片,重訓成本很高,但訓完了新的精度不一定更高,速度指標在特定機器環境上也未必可觀,參數量、計算量的變化尤其在邊緣設備上也不能忽視。所以在這樣的內卷期,作為開發者我們應該怎么選擇一個適合自己的模型呢?

為了方便統一 YOLO 系列模型的開發測試基準,以及模型選型,百度飛槳推出了 PaddleYOLO 開源模型庫,支持 YOLO 系列模型一鍵快速切換,并提供對應 ONNX 模型文件,充分滿足各類部署需求。此外 YOLOv5、YOLOv6、YOLOv7 和 YOLOv8 在評估和部署過程中使用了不同的后處理配置,因而可能造成評估結果虛高,而這些模型在 PaddleYOLO 中實現了統一,保證實際部署效果和模型評估指標的一致性,并對這幾類模型的代碼進行了重構,統一了代碼風格,提高了代碼易讀性。下面的講解內容也將圍繞 PaddleYOLO 相關測試數據進行分析。
完整教程文檔及模型下載鏈接:
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.5/docs/feature_models/PaddleYOLO_MODEL.md
YOLO 系列多硬件部署示例下載鏈接:
https://github.com/PaddlePaddle/FastDeploy/blob/develop/examples/vision/detection/paddledetection
總體來說,選擇合適的模型,要明確自己項目的要求和標準,精度和速度一般是最重要的兩個指標,但還有模型參數量、FLOPs 計算量等也需要考慮。接下來就具體講一講這幾個關鍵點。
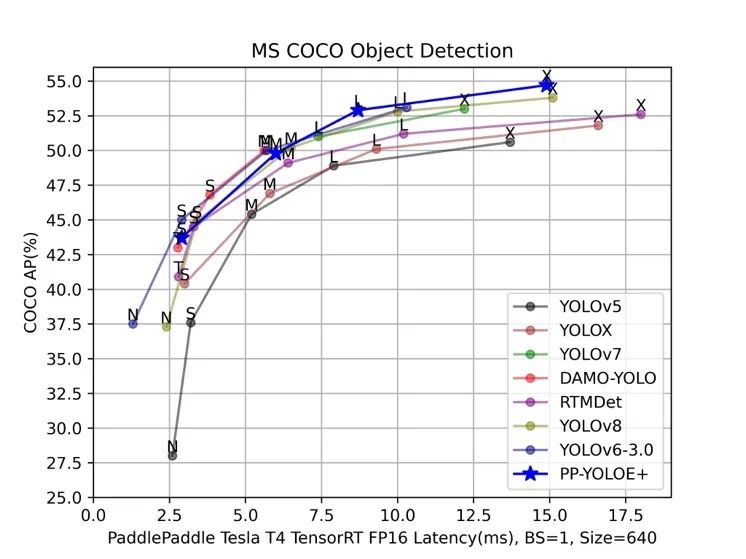
STEP1. 看精度
首先是精度,從上圖 YOLO 系列 Benchmark 圖可以看出,幾乎每個模型的目標都是希望自己的模型折線在坐標軸上是最高的,這也是各個模型的主要競爭點。各家都會訓練業界權威的 COCO 數據集去刷高精度,但是遷移到實際業務數據集上時,效果哪個高并不一定,各個模型的泛化能力并不和 COCO 數據集上的精度正相關。COCO 數據集精度差距在 1.0 以內的模型,其實業務數據集上差別不會很大,而且實際業務項目一般也不會只看 mAP 這一個指標,也可能需要關注 AP50、AP75、Recall 等指標。
要想在業務數據集達到較高精度,最重要是一點其實是加載一個較強的預訓練(pre-trained)權重。COCO 預訓練權重可以極快收斂,精度也會遠高于用 ImageNet 預訓練權重訓的。一個較強的預訓練在下游任務中的效果會優于絕大多數的調參和算法優化。在 2022 年 9 月份,飛槳官方將 PP-YOLOE 模型升級為 PP-YOLOE+,最重要的一點就是提供了 Objects365 大規模數據集的預訓練權重,Objects365 數據集含有的數據量可達百萬級,在大數據量下的訓練可以使模型獲得更強大的特征提取能力、更好的泛化能力,在下游任務上的訓練可以達到更好的效果。基于 Objects365 的 PP-YOLOE+預訓練模型,將學習率調整為原始的十分之一,在 COCO 數據集上訓練的 epoch 數從300減少到了只需 80,大大縮短了訓練時間的同時,獲得了精度上的顯著提升。實際業務場景中,在遇到比 COCO 更大規模數據集的情況下,傳統的基于 COCO 預訓練的模型就顯得杯水車薪了,無論訓練 200 epoch還是80 epoch,模型收斂都會非常慢,而使用 Objects365 預訓練模型可以在較少的訓練輪次 epoch 數如只 30 個 epoch,就實現快速收斂并且最終精度更高。
此外還有一些自監督或半監督策略可以繼續提升檢測精度,但是對于開發者來講,時間資源、硬件資源消耗極大,以及目前的開發體驗還不是很友好,需要持續優化。
STEP2. 看速度
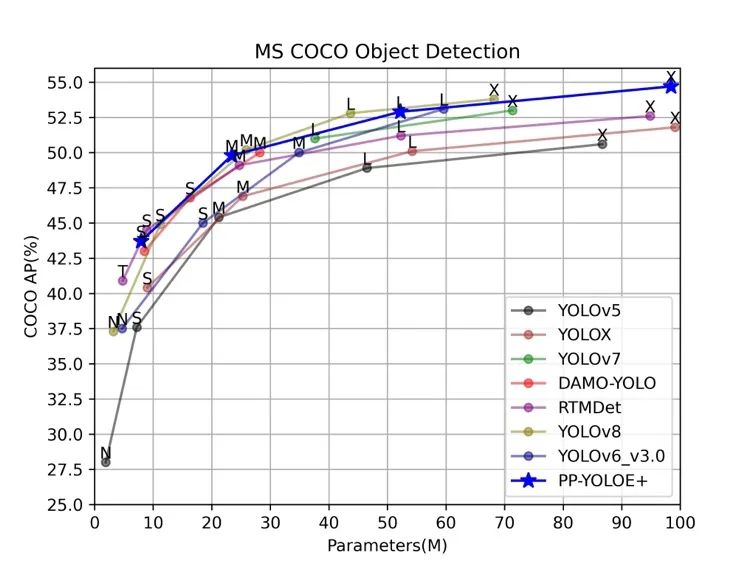
速度不像精度很快就能復現證明的,鑒于各大 YOLO 模型發布的測速環境也不同,還是得統一測試環境進行實測。上圖是飛槳團隊在飛槳框架對齊各大模型精度的基礎上,統一在 Tesla T4 上開啟 TensorRT 以 FP16 進行的測試。
另外需要注意的是,各大 YOLO 模型發布的速度只是純模型速度,是去除 NMS(非極大值抑制)的后處理和圖片前處理的,實際應用端到端的耗時還是要加上 NMS 后處理和圖片前處理的時間,以及將數據從 CPU 拷貝到 GPU/XPU 等加速卡上和將數據從加速卡拷貝到 CPU 的時間。通常 NMS 的參數對速度影響極大,尤其是 score threshold(置信度閾值) 、NMS 的 IoU 閾值、top-k 框數(參與 NMS 的最多框數)以及 max_dets(每張圖保留的最多框數) 等參數。
比如最常用的是調 score threshold,一般為了提高 Recall(召回率)都會設置成 0.001、0.01 之類的,但其實這種置信度范圍的低分框對實際應用來說意義不大;如果設置成 0.1、0.2 則會提前過濾掉眾多的低分框,這樣 NMS 速度和整個端到端部署的速度就會顯著上升,代價是掉一些 mAP,但對于結果可視化在視覺效果上其實影響很小。
STEP3. 看參數量、計算量
這方面在學術研究場景中一般不會著重考慮,但是在產業應用場景中就非常重要,需要注意設備的硬件限制。例如堆疊一些模塊結構來改造原模型,增加了 2~3 倍參數量提高了一點點 mAP,這是 AI 競賽常用的“套路”,精度雖然有少許提升,但速度變慢了很多,參數量和 FLOPs 也都變大了很多,對于產業應用來說意義不大,又如一些特殊模塊,例如 ConvNeXt,參數量極大但是 FLOPs 很小,雖然可以提升精度,但也會降低速度,參數量也可能受設備容量限制。
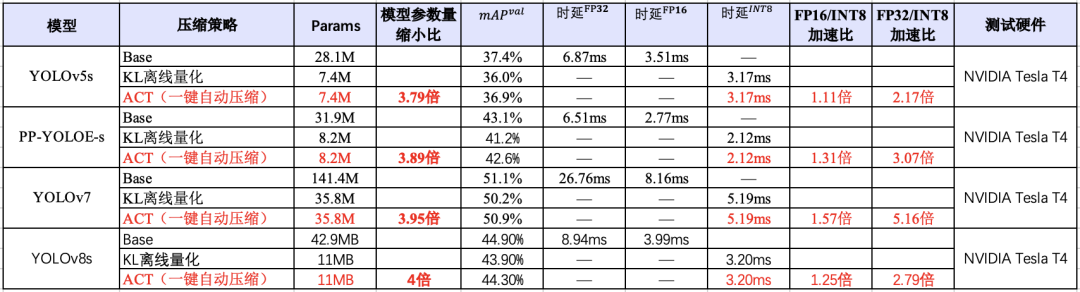
在對資源、顯存及其敏感的場景,除了選擇參數量較小的模型,也需要考慮和壓縮工具聯合使用。如下圖所示,在 YOLO 系列模型上,使用 PaddleSlim 自動壓縮工具(ACT)壓縮后,可以在盡量保證精度的同時,降低模型大小和顯存占用,并且該能力已經在飛槳全場景高性能 AI 部署工具 FastDeploy 中集成,實現一鍵壓縮。
FastDeploy 快速部署
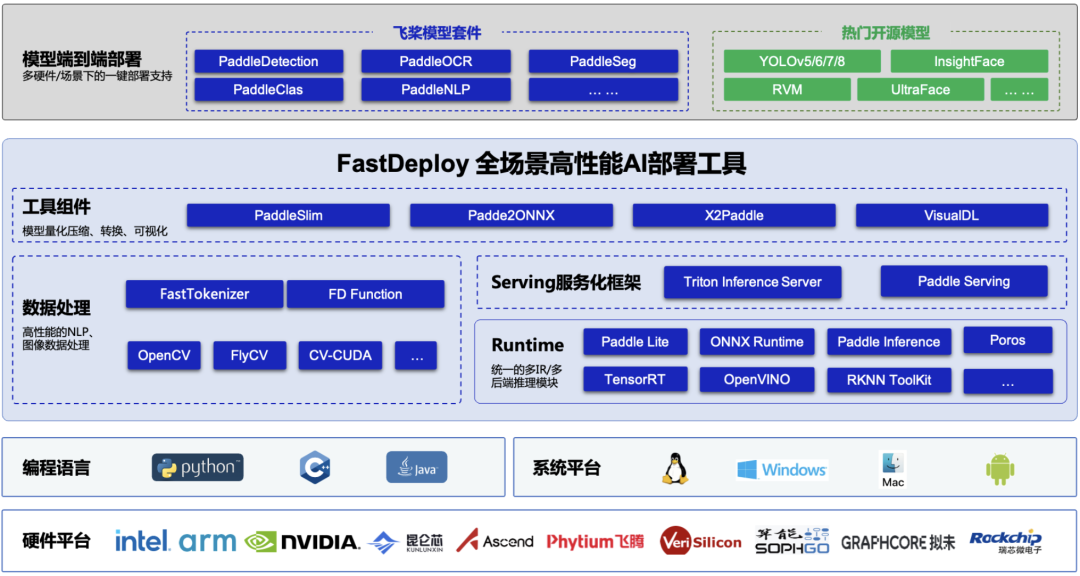
基于產業落地部署需求,全場景高性能 AI 部署工具 FastDeploy 統一了飛槳的推理引擎和生態推理引擎(包括 Paddle Inference、Paddle Lite、TensorRT、Poros 等多推理后端),并融合高性能 NLP 加速庫 FastTokenizer、CV 高新能加速庫 CV-CUDA,實現了 AI 模型端到端的推理性能優化,支持 YOLOv5、YOLOv8、PP-YOLOE+等在內的 160 多個產業級特色模型。支持 NVIDIA Jetson、NVIDIA GPU 等全系列硬件,同時支持高性能服務化部署,助力企業用戶快速完成 AI 模型部署。
加入 PaddleDetection 技術交流群,體驗 NVIDIA NGC + PaddleDetection
入群方式:微信掃描下方二維碼,關注公眾號,填寫問卷后進入微信群隨時進行技術交流,獲取 PaddleDetection 學習大禮包

NGC 飛槳容器介紹
如果您希望體驗 PaddleDetection v2.5 的新特性,歡迎使用 NGC 飛槳容器。NVIDIA 與百度飛槳聯合開發了 NGC 飛槳容器,將最新版本的飛槳與最新的 NVIDIA 的軟件棧(如 CUDA)進行了無縫的集成與性能優化,最大程度的釋放飛槳框架在 NVIDIA 最新硬件上的計算能力。這樣,用戶不僅可以快速開啟 AI 應用,專注于創新和應用本身,還能夠在 AI 訓練和推理任務上獲得飛槳+NVIDIA 帶來的飛速體驗。
最佳的開發環境搭建工具 - 容器技術
-
容器其實是一個開箱即用的服務器。極大降低了深度學習開發環境的搭建難度。例如你的開發環境中包含其他依賴進程(redis,MySQL,Ngnix,selenium-hub 等等),或者你需要進行跨操作系統級別的遷移
-
容器鏡像方便了開發者的版本化管理
-
容器鏡像是一種易于復現的開發環境載體
-
容器技術支持多容器同時運行
最好的 PaddlePaddle 容器
NGC 飛槳容器針對 NVIDIA GPU 加速進行了優化,并包含一組經過驗證的庫,可啟用和優化 NVIDIA GPU 性能。此容器還可能包含對 PaddlePaddle 源代碼的修改,以最大限度地提高性能和兼容性。此容器還包含用于加速 ETL (DALI, RAPIDS),、訓練(cuDNN, NCCL)和推理(TensorRT)工作負載的軟件。
PaddlePaddle 容器具有以下優點:
-
適配最新版本的 NVIDIA 軟件棧(例如最新版本 CUDA),更多功能,更高性能
-
更新的 Ubuntu 操作系統,更好的軟件兼容性
-
按月更新
-
滿足 NVIDIA NGC 開發及驗證規范,質量管理
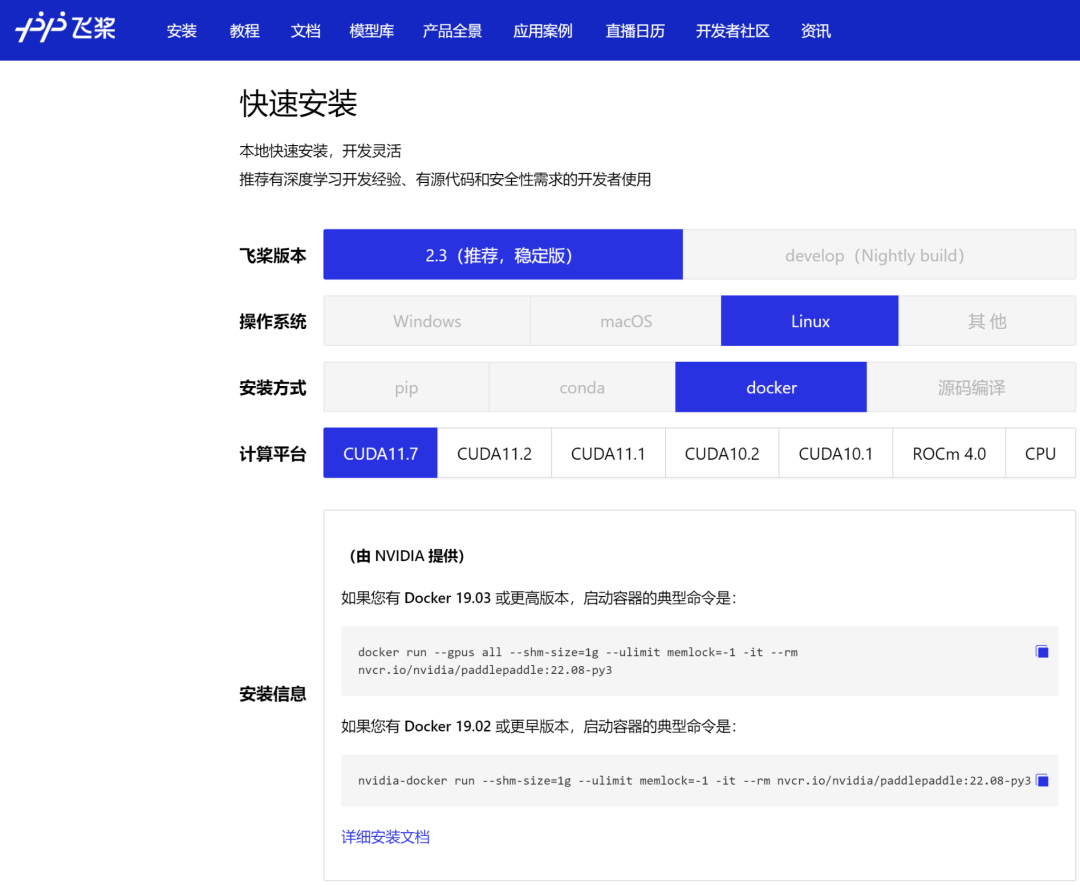
通過飛槳官網快速獲取
環境準備
使用 NGC 飛槳容器需要主機系統(Linux)安裝以下內容:
-
Docker 引擎
-
NVIDIA GPU 驅動程序
-
NVIDIA 容器工具包
有關支持的版本,請參閱 NVIDIA 框架容器支持矩陣 和 NVIDIA 容器工具包文檔。
不需要其他安裝、編譯或依賴管理。無需安裝 NVIDIA CUDA Toolkit。
NGC 飛槳容器正式安裝:
要運行容器,請按照 NVIDIA Containers For Deep Learning Frameworks User’s Guide 中 Running A Container 一章中的說明發出適當的命令,并指定注冊表、存儲庫和標簽。有關使用 NGC 的更多信息,請參閱 NGC 容器用戶指南。如果您有 Docker 19.03 或更高版本,啟動容器的典型命令是:
dockerrun--gpusall--shm-size=1g--ulimitmemlock=-1-it--rm
nvcr.io/nvidia/paddlepaddle:22.08-py3
*詳細安裝介紹 《NGC 飛槳容器安裝指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
【飛槳開發者說|NGC飛槳容器全新上線 NVIDIA產品專家全面解讀】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
飛槳與 NVIDIA NGC 合作介紹
NVIDIA 非常重視中國市場,特別關注中國的生態伙伴,而當前飛槳擁有超過 470 萬的開發者。在過去五年里我們緊密合作,深度融合,做了大量適配工作,如下圖所示。

今年,我們將飛槳列為 NVIDIA 全球前三的深度學習框架合作伙伴。我們在中國已經設立了專門的工程團隊支持,賦能飛槳生態。
為了讓更多的開發者能用上基于 NVIDIA 最新的高性能硬件和軟件棧。當前,我們正在進行全新一代NVIDIA GPU H100的適配工作,以及提高飛槳對 CUDA Operation API 的使用率,讓飛槳的開發者擁有優秀的用戶體驗及極致性能。
以上的各種適配,僅僅是讓飛槳的開發者擁有高性能的推理訓練成為可能。但是,這些離行業開發者還很遠,門檻還很高,難度還很大。
為此,我們將剛剛這些集成和優化工作,整合到三大產品線中。其中 NGC 飛槳容器最為閃亮。
NVIDIA NGC Container – 最佳的飛槳開發環境,集成最新的 NVIDIA 工具包(例如 CUDA)
 ?
?
?
?
?
?
?
?點擊“閱讀原文”或掃描下方海報二維碼,即可免費注冊 GTC 23,切莫錯過這場 AI 和元宇宙時代的技術大會!
原文標題:YOLOv8 來啦!一文帶你解讀 YOLO"內卷"期的模型選型以及在 NGC 飛槳容器中快速體驗!
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3840瀏覽量
91677
原文標題:YOLOv8 來啦!一文帶你解讀 YOLO"內卷"期的模型選型以及在 NGC 飛槳容器中快速體驗!
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在RK3568教學實驗箱上實現基于YOLOV5的算法物體識別案例詳解
YOLOv10自定義目標檢測之理論+實踐
在Ubuntu 24.04 LTS上安裝飛槳PaddleX
YOLOv6在LabVIEW中的推理部署(含源碼)

YOLOv8中的損失函數解析

【飛凌嵌入式OK3576-C開發板體驗】RKNN神經網絡-YOLO目標檢測
使用NVIDIA JetPack 6.0和YOLOv8構建智能交通應用
NVIDIA與百度飛槳攜手革新汽車風阻預測:DNNFluid-Car模型的崛起
百度發布文心大模型4.0 Turbo與飛槳框架3.0,引領AI技術新篇章
用OpenVINO C# API在intel平臺部署YOLOv10目標檢測模型

使用sophon-demo_v0.1.8_dbb4632_20231116下面的YOLOv8中的yolov8_bmcv歷程出現段錯誤的原因?
OpenVINO? C# API部署YOLOv9目標檢測和實例分割模型
基于OpenCV DNN實現YOLOv8的模型部署與推理演示
在Windows上使用OpenVINO? C# API部署Yolov8-obb實現任意方向的目標檢測

OpenCV4.8 C++實現YOLOv8 OBB旋轉對象檢測





 工商網監
工商網監
評論