 Docker入門指南之Docker使用場景介紹
Docker入門指南之Docker使用場景介紹
一、為什么使用Docker
隨著大數據平臺型產品方向的深入應用實踐和Docker開源社區的逐漸成熟,業界有不少的大數據研發團隊開始使用Docker。
簡單來說,Docker會讓大數據平臺部署更加簡單快捷、讓研發和測試團隊集成交付更加敏捷高效、讓產線環境的運維更加有質量保障。
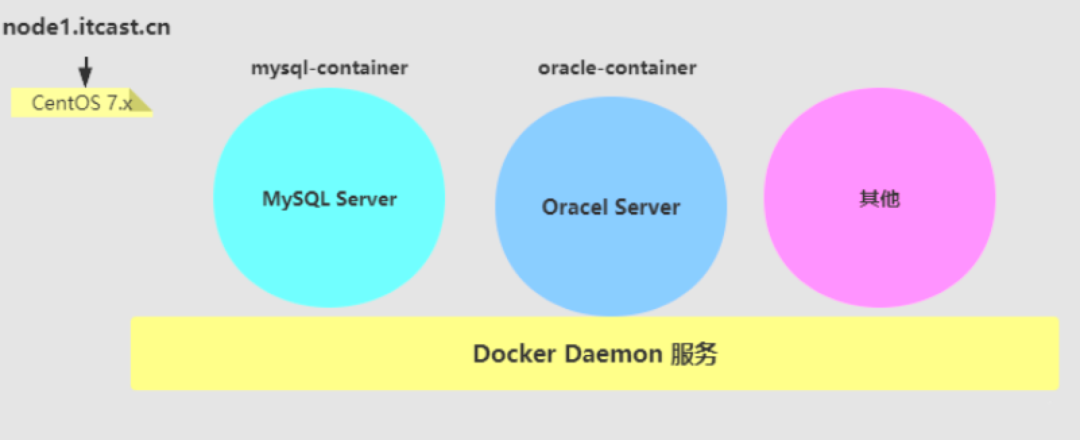
1.1 Docker的使用場景一
在大數據平臺型產品的開發過程中,經常要跟許多模塊打交道,包括Hadoop、Hive、Spark、Zookeeper……等多達幾十個開源組件,為了不影響團隊成員間的工作任務協同,開發人員其實非常需要自己有一套獨立的集群環境,以便反復測試自己負責的模塊。
可真實的企業開發環境往往只有一兩個大的虛擬集群,這可怎么辦?難道要給每個開發人員都配幾臺獨立的物理機器?
1.2 Docker的使用場景二
針對每一次新版本的發布,產品測試組都需要反復的重裝整個平臺以便發現問題,而正如本文前面所闡述的那樣,大數據平臺所依賴的組件繁多,不同組件模塊依賴的底層庫也不盡相同。
經常會出現各種依賴沖突問題,而一旦安裝完成,就很難再讓Linux系統恢復到一個非常干凈的狀態。
通過Remove、UnInstall、rpm -e等手動方式卸載,往往需要花費很長的時間,那如何才能快速地恢復大數據平臺集群的系統環境?
1.3 Docker的使用場景三
當測試人員在測試大數據平臺過程中發現了一個BUG,需要保存現場,這里面包括相關的大數據組件配置、進程狀態、運行日志、還有一些中間數據。
可是,平臺集群服務器節點數量很多,針對每個進程的配置目錄和日志文件,都相對較獨立。
一般都需要專業的開發工程師或者運維工程師進入相關服務器節點,按照不同組件的個性化配置信息,手工方式收集所需的各個條目信息,然后打包匯集到日志中心服務器進行統一分析。
而目前業界并沒有一款能夠自動分布式收集故障相關的日志系統,但測試工作還要繼續,怎么辦?
傳統解決方案的缺陷
想要解決這些問題,第一個想到的方案當然是用虛擬機,但這種方式并不能完美的解決以上問
題,比如:
-
雖然虛擬機也可以完成系統環境的遷移,但這并不是它所擅長的,不夠靈活,很笨重。
-
虛擬機的快照可以保存當前的狀態,但要恢復回去,就得把當前正在運行的虛擬機關閉,所以
并不適合頻繁保存當前狀態的業務場景。
-
雖然可以給每個人都分配幾個虛擬機用,但它是一個完整的系統,本身需要較多的資源,底層
物理機的資源很快就被用完了,所以我們需要尋找其它方式來彌補這些不足
**
-
大數據
+關注
關注
64文章
8908瀏覽量
137692 -
SPARK
+關注
關注
1文章
105瀏覽量
19952 -
Docker
+關注
關注
0文章
492瀏覽量
11925 -
hive
+關注
關注
0文章
12瀏覽量
3856
發布評論請先 登錄
相關推薦
Docker是什么?
Docker入門指南
docker基礎知識和使用bmnnsdk時的docker常用命令
學習 Docker 容器的 8 個命令分享






 工商網監
工商網監
評論