 count()的原理
count()的原理
在我們平時查詢數據庫表記錄行數的時候,經常會使用到count()函數,比如使用count(*)、count(1)或者count(某個主鍵或索引列),今天我們來對比下這些用法中哪個性能最優秀!
創建短信表
比如說,你有一張短信表(sms) ,里面放了各種需要發送的短信信息。
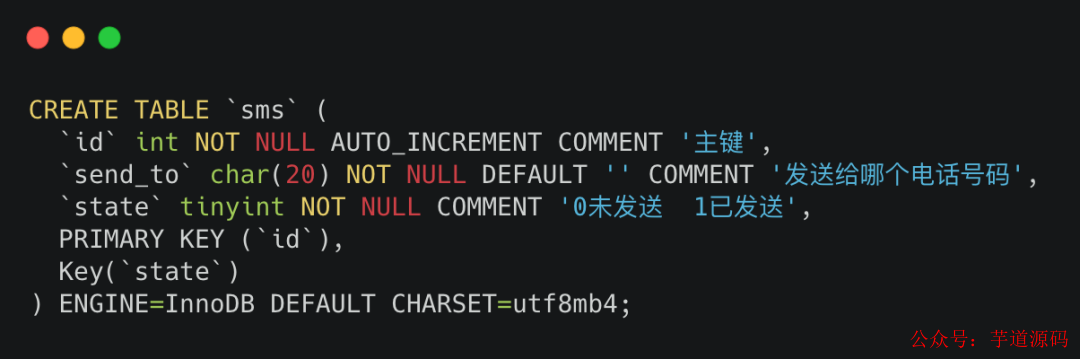 sms建表sql
sms建表sql sms表
sms表需要注意的是state字段,為0的時候說明這時候短信還未發送。
此時還會有一個異步線程 不斷的撈起未發送(state=0)** 的短信數據,執行發短信操作,發送成功之后state字段會被*置為1(已發送) 。也就是說未發送的數據會不斷變少* 。
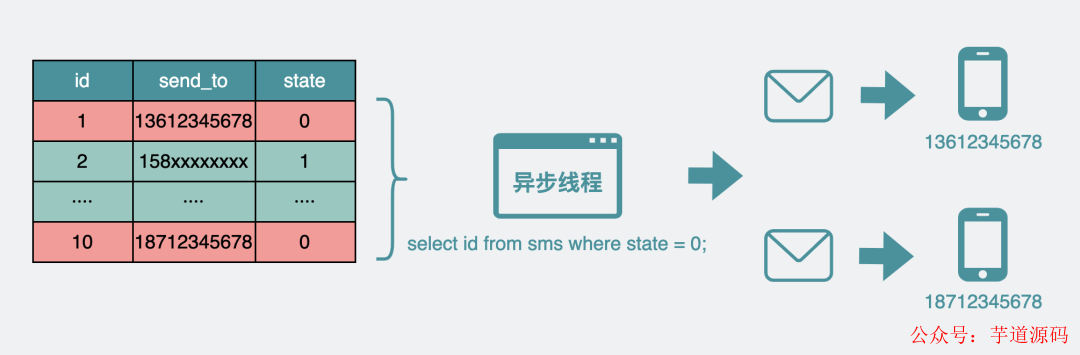 異步線程發送短信
異步線程發送短信假設由于某些原因,你現在需要做一些監控,比如監控的內容是,你的sms數據表里還有沒有state=0(未發送)的短信,方便判斷一下堆積的未發送短信大概在什么樣的一個量級。
為了獲取滿足某些條件的行數是多少 ,我們一般會使用count()方法 。
這時候為了獲取未發送的短信數據,我們很自然就想到了使用下面的sql語句進行查詢。
selectcount(*)fromsmswherestate=0;
然后再把獲得數據作為打點發給監控服務。
當數據表小的時候,這是沒問題的,但當數據量大的時候,比如未發送的短信到了百萬量級 的時候,你就會發現,上面的sql查詢時間會變得很長,最后timeout報錯,查不出結果了 。
為什么?
我們先從count()方法的原理 聊起。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
count()的原理
count()方法的目的是計算當前sql語句查詢得到的非NULL的行數 。
我們知道mysql是分為server層和存儲引擎層的 。
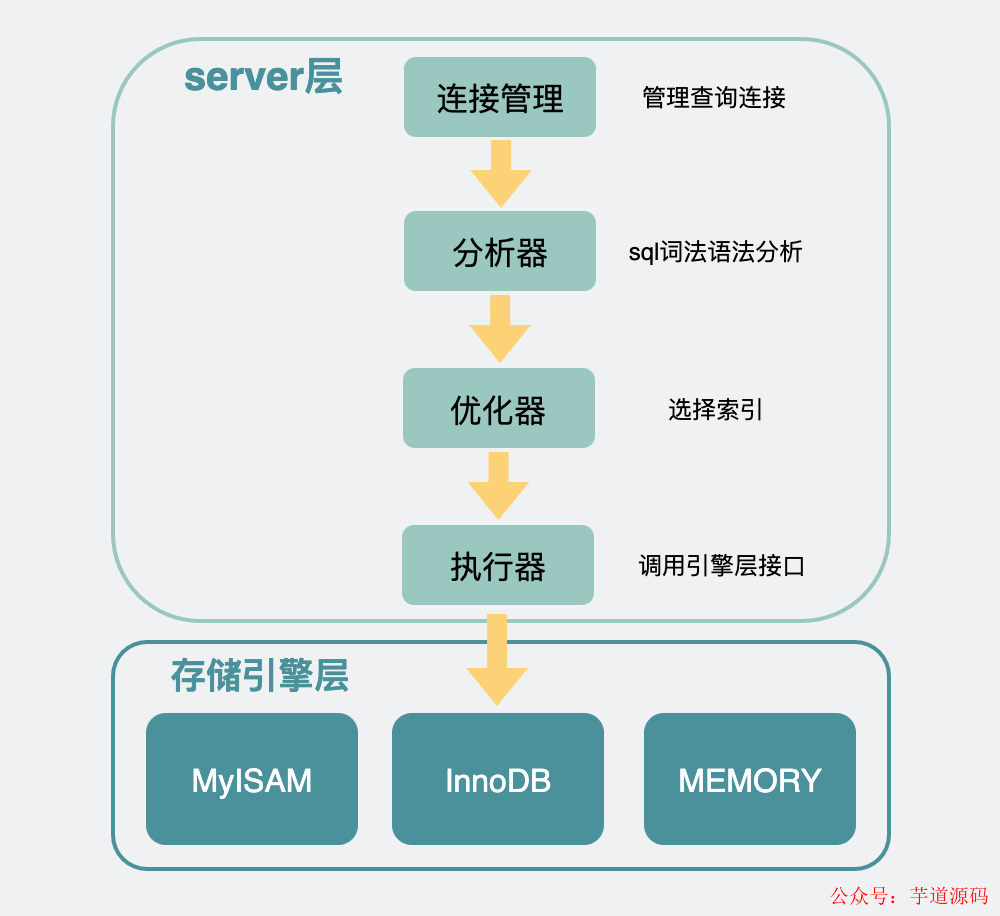 Mysql架構
Mysql架構
存儲引擎層里可以選擇各種引擎進行存儲,最常見的是innodb、myisam。具體使用哪個存儲引擎,可以通過建表sql里的ENGINE字段進行指定。比如這篇文章開頭的建表sql里用了ENGINE=InnoDB,那這張表用的就是innodb引擎。
雖然在server層都叫count()方法,但在不同的存儲引擎下,它們的實現方式是有區別的。
比如同樣是讀全表數據 select count(*) from sms;語句。
使用 myisam引擎 的數據表里有個記錄當前表里有幾行數據的字段,直接讀這個字段返回就好了,因此速度快得飛起。
而使用innodb引擎 的數據表,則會選擇體積最小的索引樹 ,然后通過遍歷葉子節點的個數挨個加起來,這樣也能得到全表數據。
因此回到文章開頭的問題里,當數據表行數變大后,單次count就需要掃描大量的數據 ,因此很可能就會出現超時報錯。
那么問題就來了。
為什么innodb不能像myisam那樣實現count()方法
myisam和innodb這兩個引擎,有幾個比較明顯的區別,這個是八股文常考了。
其中最大的區別在于myisam不支持事務,而innodb支持事務。
而事務,有四層隔離級別,其中默認隔離級別就是可重復讀隔離級別(RR) 。
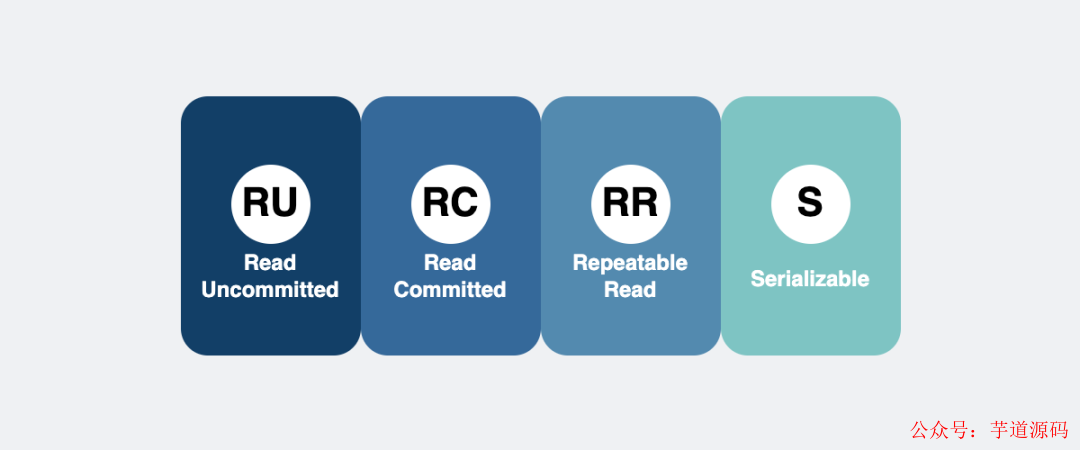 四層隔離級別
四層隔離級別innodb引擎通過MVCC實現了可重復隔離級別 ,事務開啟后,多次執行同樣的select快照讀 ,要能讀到同樣的數據。
于是我們看個例子。
 為什么innodb不單獨記錄表行數
為什么innodb不單獨記錄表行數對于兩個事務A和B,一開始sms表假設就2條 數據,那事務A一開始確實是讀到2條數據。事務B在這期間插入了1條數據,按道理數據庫其實有3條數據了,但由于可重復讀的隔離級別,事務A依然還是只能讀到2條數據。
因此由于事務隔離級別的存在,不同的事務在同一時間下,看到的表內數據行數是不一致的 ,因此innodb,沒辦法,也沒必要像myisam那樣單純的加個count字段信息在數據表上。
那如果不可避免要使用count(),有沒有辦法讓它快一點?
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
各種count()方法的原理
count()的括號里,可以放各種奇奇怪怪的東西,想必大家應該看過,比如放個星號*,放個1,放個索引列啥的。
我們來分析下他們的執行流程。
count方法的大原則是server層會從innodb存儲引擎里讀來一行行數據,并且只累計非null的值 。但這個過程,根據count()方法括號內的傳參,有略有不同。
count(*)
server層拿到innodb返回的行數據,不對里面的行數據做任何解析和判斷 ,默認取出的值肯定都不是null,直接行數+1。
count(1)
server層拿到innodb返回的行數據,每行放個1進去,默認不可能為null,直接行數+1.
count(某個列字段)
由于指明了要count某個字段,innodb在取數據的時候,會把這個字段解析出來 返回給server層,所以會比count(1)和count(*)多了個解析字段出來的流程。
- 如果這個列字段是主鍵id ,主鍵是不可能為null的,所以server層也不用判斷是否為null,innodb每返回一行,行數結果就+1.
- 如果這個列是普通索引字段 ,innodb一般會走普通索引 ,每返回一行數據,server層就會判斷這個字段是否為null,不是null的情況下+1。當然如果建表sql里字段定義為not null的話,那就不用做這一步判斷直接+1。
- 如果這個列沒有加過索引 ,那innodb可能會全表掃描,返回的每一行數據,server層都會判斷這個字段是否為null,不是null的情況下+1。同上面的情況一樣,字段加了not null也就省下這一步判斷了。
理解了原理后我們大概可以知道他們的性能排序是
count(*)≈count(1)>count(主鍵id)>count(普通索引列)>count(未加索引列)
所以說count(*),已經是最快的了。
知道真相的我眼淚掉下來。
那有沒有其他更好的辦法?
允許粗略估計行數的場景
我們回過頭來細品下文章開頭的需求,我們只是希望知道數據庫里還有多少短信是堆積在那沒發的,具體是1k還是2k其實都是差不多量級,等到了百萬以上,具體數值已經不重要了,我們知道它現在堆積得很離譜,就夠了。因此這個場景,其實是允許使用比較粗略 的估計的。
那怎么樣才能獲得粗略的數值呢?
還記得我們平時為了查看sql執行計劃用的explain命令 不。
其中有個rows ,會用來估計 接下來執行這條sql需要掃描和檢查多少行。它是通過采樣的方式計算出來的,雖然會有一定的偏差,但它能反映一定的數量級。
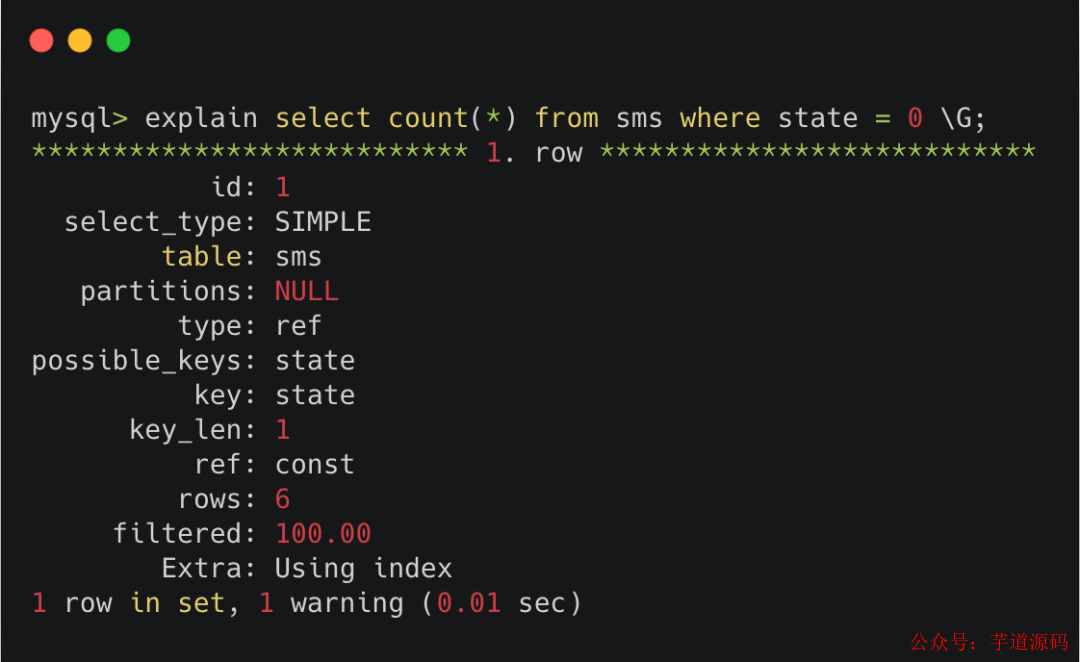 explain里的rows
explain里的rows有些語言的orm里可能沒有專門的explain語法,但是肯定有執行raw sql的功能,你可以把explain語句當做raw sql傳入,從返回的結果里將rows那一列讀出來使用。
一般情況下,explain的sql如果能走索引,那會比不走索引的情況更準 。單個字段的索引會比多個字段組成的復合索引要準。索引區分度越高,rows的值也會越準。
這種情況幾乎滿足大部分的監控場景。但總有一些場景,它要求必須得到精確的行數,這種情況該怎么辦呢?
必須精確估計行數的場景
這種場景就比較頭疼了,但也不是不能做。
我們可以單獨拉一張新的數據庫表,只為保存各種場景下的count。
CREATETABLE`count_table`(
`id`intNOTNULLAUTO_INCREMENTCOMMENT'主鍵',
`cnt_what`char(20)NOTNULLDEFAULT''COMMENT'各種需要計算的指標',
`cnt`tinyintNOTNULLCOMMENT'cnt指標值',
PRIMARYKEY(`id`),
KEY`idx_cnt_what`(`cnt_what`)
)ENGINE=InnoDBDEFAULTCHARSET=utf8mb4;
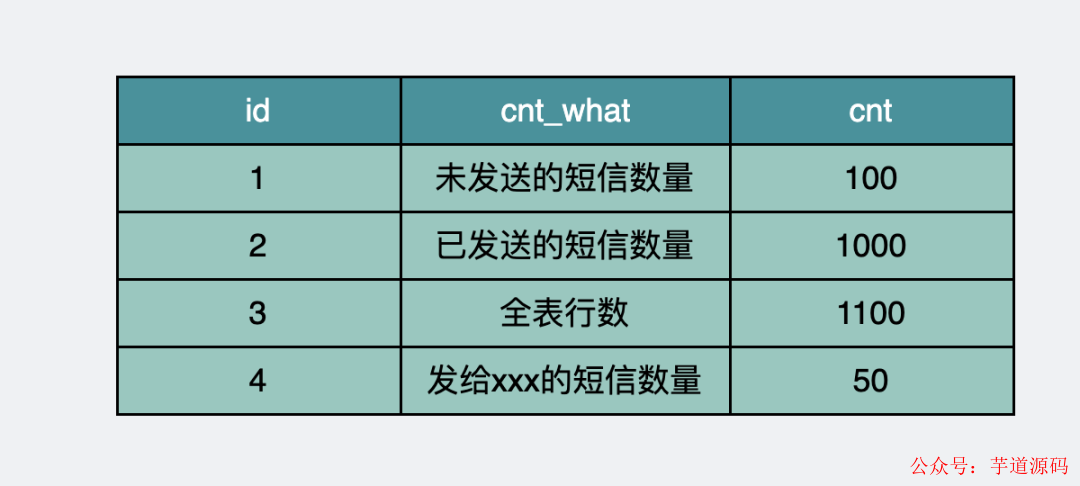 count_table表保存各種場景下的count
count_table表保存各種場景下的count當需要獲取某個場景下的cout值時,可以使用下面的sql進行直接讀取,快得飛起 。
selectcntfromcount_tablewherecnt_what="未發送的短信數量";
那這些count的結果值從哪來呢?
這里分成兩種情況。
實時性要求較高的場景
如果你對這個cnt計算結果的實時性要求很高,那你需要將更新cnt的sql加入到對應變更行數的事務中 。
比如我們有兩個事務A和B,分別是增加未發送短信和減少未發送短信。
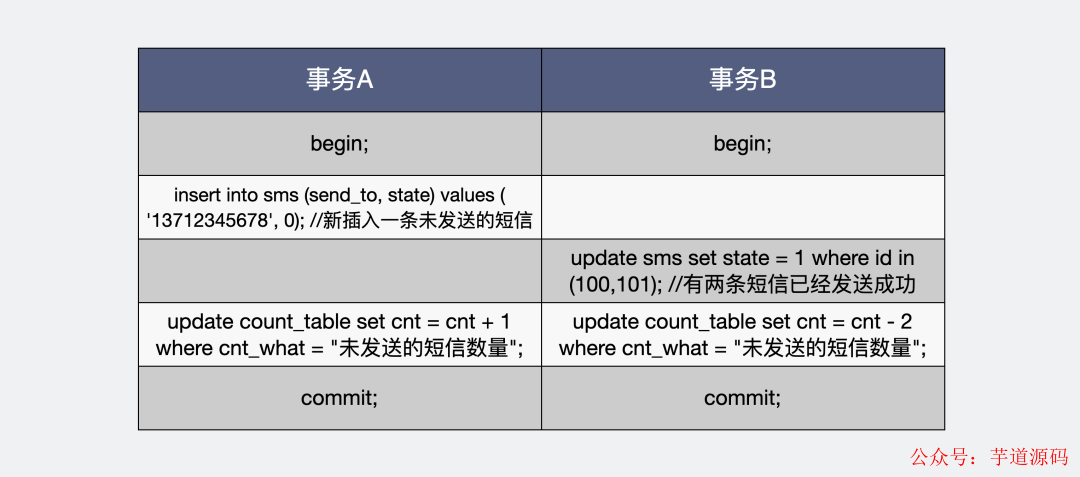 將更改表行數的操作放入到事務里
將更改表行數的操作放入到事務里這樣做的好處 是事務內的cnt行數依然符合隔離級別,事務回滾的時候,cnt的值也會跟著回滾。
壞處 也比較明顯,多個線程對同一個cnt進行寫操作,會觸發悲觀鎖,多個線程之間需要互相等待。對于高頻寫的場景 ,性能會有折損。
實時性沒那么高的場景
如果實時性要求不高的話,比如可以一天一次,那你可以通過全表掃描后做計算。
舉個例子,比如上面的短信表,可以按id排序 ,每次取出1w條數據,記下這一批里最大的id,然后下次從最大id開始再拿1w條數據出來,不斷循環。
對于未發送的短信,就只需要在撈出的那1w條數據里,篩選出state=0的條數。
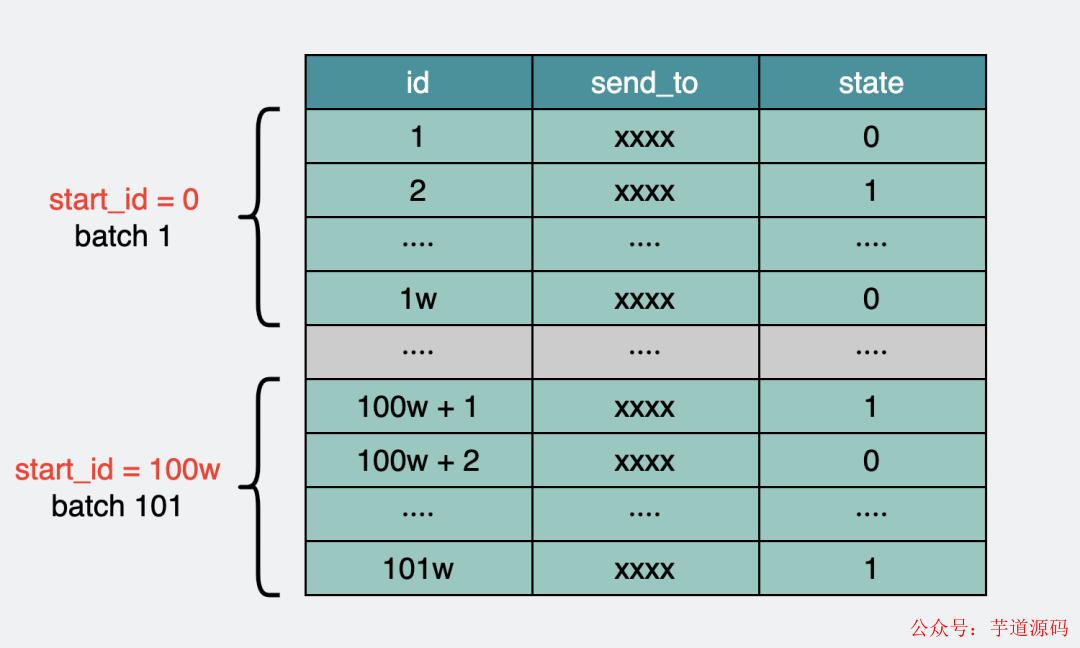 batch分批獲取短信表
batch分批獲取短信表當然如果有條件,這種場景最好的方式還是消費binlog將數據導入到hive里 ,然后在hive里做查詢,不少公司也已經有現成的組件可以做這種事情,不用自己寫腳本,豈不美哉。
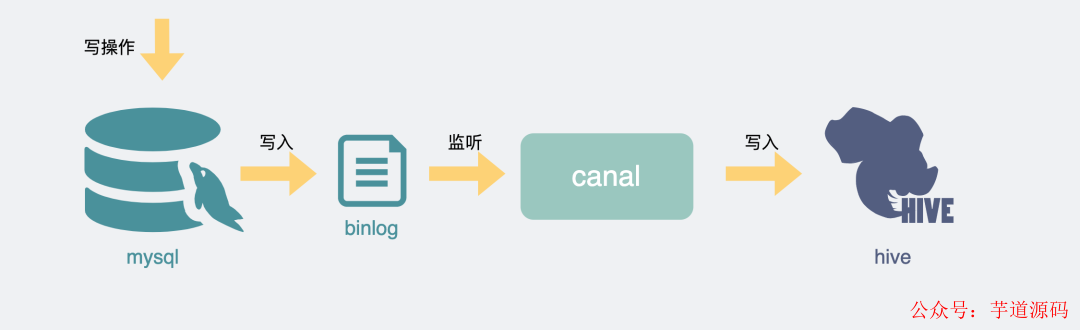 mysql同步hive
mysql同步hive總結
- mysql用count方法查全表數據 ,在不同的存儲引擎里實現不同,myisam有專門字段記錄全表的行數,直接讀這個字段就好了。而innodb則需要一行行去算。
-
性能方面
count(*) ≈ count(1) > count(主鍵id) > count(普通索引列) > count(未加索引列),但哪怕是性能最好的count(*),由于實現上就需要一行行去算,所以數據量大的時候就是不給力。 - 如果確實需要獲取行數,且可以接受不那么精確的行數(只需要判斷大概的量級) 的話,那可以用explain里的rows,這可以滿足大部分的監控場景,實現簡單。
- 如果要求行數準確 ,可以建個新表,里面專門放表行數的信息。
- 如果對實時性要求比較高 的話,可以將更新行數的sql放入到對應事務里,這樣既能滿足事務隔離性,還能快速讀取到行數信息。
- 如果對實時性要求不高 ,接受一小時或者一天的更新頻率,那既可以自己寫腳本遍歷全表后更新行數信息。也可以將通過監聽binlog將數據導入hive,需要數據時直接通過hive計算得出。
審核編輯 :李倩
-
數據
+關注
關注
8文章
7134瀏覽量
89410 -
SQL
+關注
關注
1文章
773瀏覽量
44219 -
程序員
+關注
關注
4文章
953瀏覽量
29833
原文標題:程序員新人頻繁使用count(*),被組長批評后怒懟:性能并不拉垮!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論