") NVIDIA Triton 系列文章(9):為服務(wù)器添加模型
NVIDIA Triton 系列文章(9):為服務(wù)器添加模型
前面已經(jīng)用https://github.com/triton-inference-server/server/doc/examples 開(kāi)源倉(cāng)的范例資源,創(chuàng)建一個(gè)最基礎(chǔ)的模型倉(cāng)以便執(zhí)行一些基礎(chǔ)的用戶(hù)端范例,現(xiàn)在就要帶著讀者為模型倉(cāng)添加新的模型。
在“創(chuàng)建模型倉(cāng)”的文章里講解過(guò),Triton 模型倉(cāng)使用目錄結(jié)構(gòu)與相關(guān)文件來(lái)形成一個(gè)模型的基礎(chǔ)要素,如下所列:
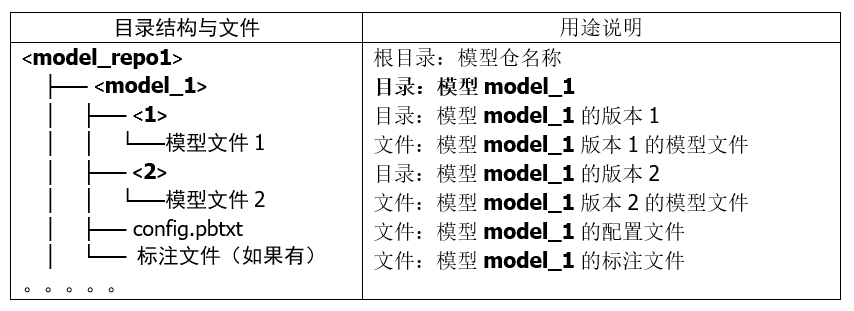
上面的目錄結(jié)構(gòu)與模型文件是最基本的材料,處理起來(lái)是很容易的,比較復(fù)雜的部分是配置文件 config.pbtxt 的內(nèi)容,里面提供 Triton 服務(wù)器用來(lái)管理模型執(zhí)行特性的各項(xiàng)參數(shù),這些設(shè)置的內(nèi)容主要分為靜態(tài)的基礎(chǔ)(minimal)設(shè)置項(xiàng)與動(dòng)態(tài)的優(yōu)化(optimization)設(shè)置兩大部分,本文內(nèi)容先針對(duì)基礎(chǔ)配置項(xiàng)的部分進(jìn)行說(shuō)明。
為了說(shuō)明這些配置內(nèi)容,這里先以范例模型倉(cāng)里的 inception_graphdef 模型的配置文件 config.pbtxt 為例,來(lái)配合以下的簡(jiǎn)單說(shuō)明,比較容易讓大家理解詳細(xì)的內(nèi)容:

每個(gè)配置文件里都至少包含以下5個(gè)部分:
1. 模型名稱(chēng):
這部分直接使用存放模型的文件夾名稱(chēng),因此可以省略,如果要指定的話就必須與文件夾名稱(chēng)一致。
2. 平臺(tái)/后端名稱(chēng)(Name, Platform and Backend):
這部分必須與模型訓(xùn)練時(shí)使用的框架與文件格式相匹配,以下是使用頻率較高的種類(lèi):
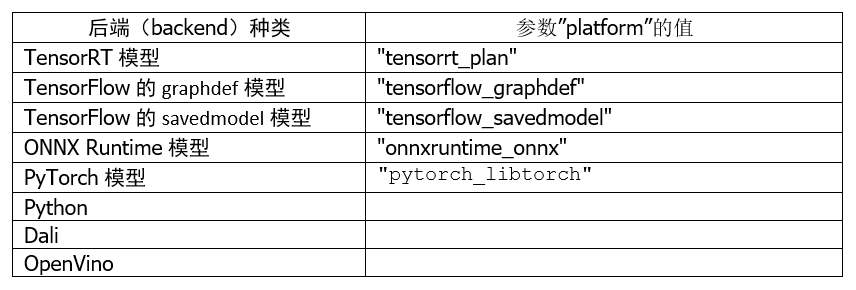
至于其他平臺(tái)/后端的對(duì)應(yīng)名稱(chēng),就需要根據(jù)實(shí)際的平臺(tái)與對(duì)應(yīng)名稱(chēng)進(jìn)行配置。
3. 模型執(zhí)行策略(Model Transaction Policy):
這個(gè)屬性只有一個(gè)“解耦(decoupled)與否”的選項(xiàng)。使用解耦意味著模型生成的響應(yīng)的數(shù)量可能與發(fā)出的請(qǐng)求的數(shù)量不同,并且響應(yīng)可能與請(qǐng)求的順序無(wú)關(guān)。
默認(rèn)值為 false,上面范例中并未列出這個(gè)參數(shù)的配置值,表示“不啟用解耦”功能,意味著該模型將為每個(gè)請(qǐng)求生成一個(gè)響應(yīng)。
如果需要啟用解耦功能,就在配置文件內(nèi)添加以下內(nèi)容:
model_transaction_policy {
decoupled: True
}
4. 最大批量值(Maximum Batch Size):
Triton 服務(wù)器支持多種調(diào)度和批處理算法,可以為每個(gè)模型獨(dú)立選擇。這個(gè)屬性表示執(zhí)行該推理模型計(jì)算時(shí)的最大批量規(guī)模,包括“無(wú)狀態(tài)(stateless)”或“有狀態(tài)(stateful)”等類(lèi)型的模型。
這個(gè)參數(shù)主要配合下面“輸入/輸出節(jié)點(diǎn)內(nèi)容”的張量尺度部分,例如本范例中輸入節(jié)點(diǎn)張量格式為“format: FORMAT_NHWC”,但是下面尺度“dims: [ 299, 299, 3 ]”的三個(gè)數(shù)值是對(duì)應(yīng)到“HWC(高/寬/通道)”,缺少“批量值(N)”的部分,這正是這個(gè)“最大批量值”為輸入節(jié)點(diǎn)與輸出節(jié)點(diǎn)所配置的數(shù)值,這樣 Triton 可以使用動(dòng)態(tài)批處理器或序列批處理器自動(dòng)對(duì)模型進(jìn)行批處理。
在這種情況下,max_batch_size 應(yīng)設(shè)置為大于或等于1的值,表示應(yīng)與該模型一起使用的最大批次大小;對(duì)于不支持批處理或不支持以上述特定方式進(jìn)行批處理的推理模型,則將 max_batch_size 設(shè)置為 0。
5. 輸入節(jié)點(diǎn)與輸出節(jié)點(diǎn)(Inputs and Outputs):
每個(gè)推理模型都有至少一個(gè)輸入節(jié)點(diǎn)與輸出節(jié)點(diǎn),這部分的內(nèi)容必須配合模型的內(nèi)容,不能自己隨便定義。
要添加新的推理模型時(shí),推薦使用 Netron 工具查看模型的網(wǎng)絡(luò)結(jié)構(gòu),只要在瀏覽器上輸入“netron.app”后打開(kāi)模型文件就可以。目前經(jīng)過(guò)測(cè)試,Netron.APP 工具能查看 ONNX、TensorFlow/graphdef、Pytorch 等模型文件的網(wǎng)絡(luò)結(jié)構(gòu),相當(dāng)方便。
下圖是 model_repository/inception_graphdef/1/model.graphdef 模型文件所能看到的輸入/輸出節(jié)點(diǎn)的內(nèi)容:
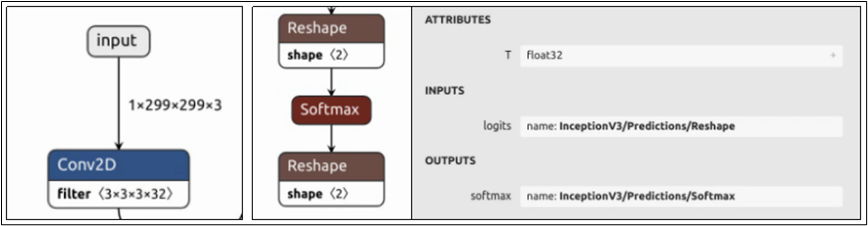
每個(gè)節(jié)點(diǎn)都包含“名稱(chēng)”、“數(shù)據(jù)類(lèi)型”與“尺度(shape)”三個(gè)部分,現(xiàn)在就進(jìn)一步說(shuō)明:
(1) 節(jié)點(diǎn)名稱(chēng)(name):
上圖最左邊的輸入節(jié)點(diǎn)在整個(gè)網(wǎng)絡(luò)結(jié)構(gòu)的最上方,名稱(chēng)為“input”;中間輸出節(jié)點(diǎn)在網(wǎng)絡(luò)結(jié)構(gòu)最下方,點(diǎn)選“softmax”節(jié)點(diǎn)會(huì)出現(xiàn)右邊灰色信息塊,顯示其完整名稱(chēng)為“InceptionV3/Predictions/Softmax”。現(xiàn)在對(duì)照模型的 config.pbtxt 里對(duì)應(yīng)內(nèi)容,是必須能匹配的,否則啟動(dòng) Triton 服務(wù)器時(shí)會(huì)出現(xiàn)錯(cuò)誤。
不過(guò)這個(gè)環(huán)節(jié)里對(duì) PyTorch 模型需要特殊的處理,由于 TorchScript 模型文件中輸入/輸出的元數(shù)據(jù)不足,配置中輸入/輸出的“名稱(chēng)屬性”必須遵循以下特定的命名約定:
-
使用張量字典(Dictionary of Tensor):
-
映射到 forward() 函數(shù)的輸入值:
-
使用_格式:
-
如果所有輸入(或輸出)不遵循相同的命名約定,那么我們從模型配置中強(qiáng)制執(zhí)行嚴(yán)格排序,即我們假設(shè)配置中輸入(或輸出)的順序是這些輸入的真實(shí)順序。
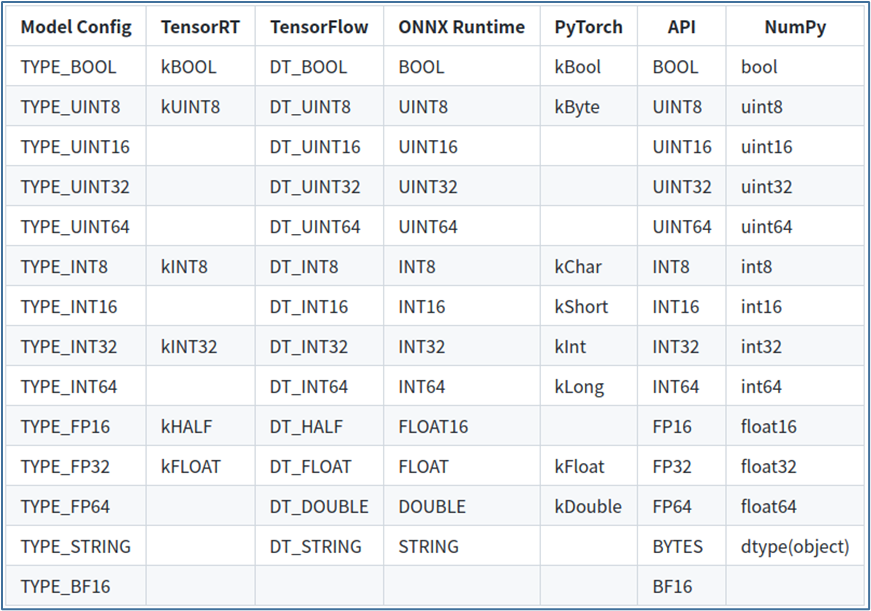
(2) 數(shù)據(jù)類(lèi)型(data_type):
輸入和輸出張量所允許的數(shù)據(jù)類(lèi)型因模型類(lèi)型而異,數(shù)據(jù)類(lèi)型部分描述了允許的數(shù)據(jù)類(lèi)型以及它們?nèi)绾斡成涞矫總€(gè)模型類(lèi)型的數(shù)據(jù)類(lèi)型。
下表顯示了 Triton 支持的張量數(shù)據(jù)類(lèi)型:
-
第 1 列顯示模型配置文件中顯示的數(shù)據(jù)類(lèi)型的名稱(chēng);
-
第 2~5 列顯示了支持的模型框架的相應(yīng)數(shù)據(jù)類(lèi)型,如果模型框架沒(méi)有給定數(shù)據(jù)類(lèi)型的條目,則 Triton 不支持該模型的數(shù)據(jù)類(lèi)型;
-
第 6 列為“API”,顯示 TRITONSERVER C API、TRITONBACKEND C API、HTTP/REST 協(xié)議和 GRPC 協(xié)議的對(duì)應(yīng)數(shù)據(jù)類(lèi)型;
-
第 7 列顯示 Python numpy 庫(kù)的對(duì)應(yīng)數(shù)據(jù)類(lèi)型。
以上是關(guān)于模型數(shù)據(jù)類(lèi)型的部分。
(3)張量尺度(dims):
這里提供的張量尺度內(nèi)容是去除第一個(gè) batch_size 的部分,因此需要與前面設(shè)定的 max_batch_size 組合形成完整的張量尺度。
輸入節(jié)點(diǎn)的張量尺度(如“dims: [ 299, 299, 3 ]”),表示模型和 Triton 在推理請(qǐng)求中預(yù)期的張量尺寸;輸出節(jié)點(diǎn)的張量尺度(如“dims: [ 1001 ]”),表示模型生成的輸出張量的形狀,并由 Triton 服務(wù)器響應(yīng)推斷請(qǐng)求返回。
輸入和輸出尺度內(nèi)的值都必須大于或等于 1,也就是不允許使用[]空尺度,節(jié)點(diǎn)的尺度由 max_batch_size 和輸入或輸出 dims 屬性指定的維度的組合指定。
-
max_batch_size > 0時(shí):整個(gè)尺度的形式為[-1, dims]。
-
max_batch_size = 0時(shí):整個(gè)形狀形成為[ dims]。
例如本文范例中輸入節(jié)點(diǎn)的尺度為“dims: [ 299, 299, 3 ]”、max_batch_size=128,則張量尺度的完整表達(dá)為“[ -1, 299, 299, 3]”;如果 max_batch_size=0 時(shí),則張量尺度的完整表達(dá)為“[ 299, 299, 3]”。
6. 版本策略(version_policy):
每個(gè)模型可以有一個(gè)或多個(gè)版本,模型配置的 ModelVersionPolicy 屬性用于設(shè)置以下策略之一。
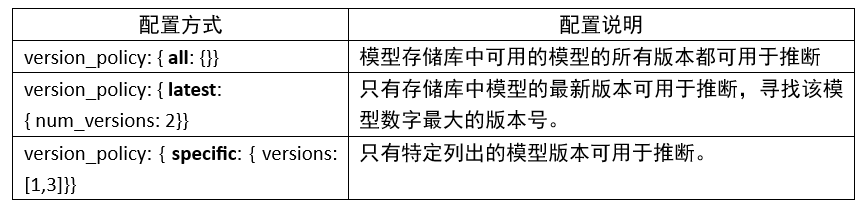
如果未指定版本策略,則使用最新版本(n=1)作為默認(rèn)值,表示 Triton 僅提供最新版本的模型。在所有情況下,從模型存儲(chǔ)庫(kù)中添加或刪除版本子目錄都可以更改后續(xù)推理請(qǐng)求中使用的模型版本。
以上是完成一個(gè) config.pbtxt 模型配置文件的最基礎(chǔ)內(nèi)容,大部分內(nèi)容都比較直觀,除了最后面的張量尺度會(huì)有比較多的變化之外,不過(guò)只要逐漸熟悉推理運(yùn)作的過(guò)程之后,就能更進(jìn)一步掌握與 batch_size 相關(guān)的應(yīng)用與調(diào)試方式。
原文標(biāo)題:NVIDIA Triton 系列文章(9):為服務(wù)器添加模型
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3842瀏覽量
91696
原文標(biāo)題:NVIDIA Triton 系列文章(9):為服務(wù)器添加模型
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NVIDIA推出開(kāi)放式Llama Nemotron系列模型
Triton編譯器的優(yōu)化技巧
Triton編譯器的優(yōu)勢(shì)與劣勢(shì)分析
Triton編譯器在機(jī)器學(xué)習(xí)中的應(yīng)用
Triton編譯器功能介紹 Triton編譯器使用教程
NVIDIA AI服務(wù)器領(lǐng)域重大革新:預(yù)計(jì)明年首推插槽式設(shè)計(jì)
NVIDIA助力提供多樣、靈活的模型選擇
NVIDIA攜手Meta推出AI服務(wù),為企業(yè)提供生成式AI服務(wù)
英偉達(dá)推出全新NVIDIA AI Foundry服務(wù)和NVIDIA NIM推理微服務(wù)
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型

英偉達(dá)推出AI模型推理服務(wù)NVIDIA NIM
使用NVIDIA Triton推理服務(wù)器來(lái)加速AI預(yù)測(cè)
服務(wù)器遠(yuǎn)程不上服務(wù)器怎么辦?服務(wù)器無(wú)法遠(yuǎn)程的原因是什么?
linux服務(wù)器和windows服務(wù)器
服務(wù)器連接應(yīng)用解決方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論