") 百度智算峰會精彩回顧:應(yīng)用驅(qū)動的數(shù)據(jù)中心計算架構(gòu)演進
百度智算峰會精彩回顧:應(yīng)用驅(qū)動的數(shù)據(jù)中心計算架構(gòu)演進
在今日舉行的“2022 百度云智峰會·智算峰會”上,NVIDIA 解決方案工程中心高級技術(shù)經(jīng)理路川分享了以“應(yīng)用驅(qū)動的數(shù)據(jù)中心計算架構(gòu)演進”為題的演講,探討 GPU 數(shù)據(jù)中心的發(fā)展趨勢,以及介紹 NVIDIA 在構(gòu)建以 GPU 為基礎(chǔ)的數(shù)據(jù)中心架構(gòu)方面的實踐經(jīng)驗。以下為內(nèi)容概要。
應(yīng)用對算力需求的不斷增長
以 GPU 為核心的分布式計算系統(tǒng)已經(jīng)成為大模型應(yīng)用重要的一環(huán)
數(shù)據(jù)中心的發(fā)展是由應(yīng)用驅(qū)動的。隨著 AI 的興起、普及,AI 大模型訓練在各領(lǐng)域的逐步應(yīng)用,人們對數(shù)據(jù)中心的 GPU 算力、GPU 集群的需求在飛速增長。傳統(tǒng)的以 CPU 為基礎(chǔ)的數(shù)據(jù)中心架構(gòu),已很難滿足 AI 應(yīng)用的發(fā)展需求,NVIDIA 也一直在探索如何構(gòu)建一個高效的以 GPU 為基礎(chǔ)的數(shù)據(jù)中心架構(gòu)。
今天我將從三個方面跟大家一起探討這個話題:一,應(yīng)用驅(qū)動;二,NVIDIA 最新一代 GPU SuperPOD 的架構(gòu)設(shè)計;三,未來 GPU 數(shù)據(jù)中心、GPU 集群的發(fā)展趨勢 。
我們首先看下近幾年 AI 應(yīng)用的發(fā)展趨勢。總體上來講,應(yīng)用業(yè)務(wù)對計算的需求是不斷飛速增長。我們以目前最流行的三個業(yè)務(wù)方向為例說明。

第一個應(yīng)用場景,AI 應(yīng)用。我們可以從最左邊的圖表中可以看到,近 10 年 CV 和 NLP 模型的變化,這兩類業(yè)務(wù)場景是 AI 領(lǐng)域最流行、最成功,也是應(yīng)用范圍最為廣泛的場景。在圖表中我們可以看到,CV 從 2012 年的 AlexNet 到最新的 wav2vec,模型對計算的需求增長了 1,000 倍。
NLP 模型在引入 Transformer 結(jié)構(gòu)后,模型規(guī)模呈指數(shù)級增長,Transformer 已成為大模型、大算力的代名詞。目前 CV 類的應(yīng)用也逐步引入 Transformer 結(jié)構(gòu)來構(gòu)建相關(guān)的 AI 模型,不斷提升應(yīng)用性能。數(shù)據(jù)顯示在最近兩年內(nèi)關(guān)于 Transformer AI 模型的論文增長了 150 倍,而非 Transformer 結(jié)構(gòu)的 AI 模型相關(guān)論文增長了大概 8 倍。
我們可以看到人們越來越意識到大模型在 AI 領(lǐng)域的重要性,和對應(yīng)用帶來的收益。同時大模型也意味著算力的需求的增長,以及對數(shù)據(jù)中心計算集群需求的增長。
第二個應(yīng)用場景,數(shù)字孿生、虛擬人等模擬場景與 AI 的結(jié)合也是最近兩年的應(yīng)用熱點。人們通過數(shù)字孿生、虛擬人可以更好地對企業(yè)生產(chǎn)流程進行管控,線上虛擬交互有更好的體驗,這背后都需要要巨大的算力資源來滿足渲染、實時交互等功能。
第三個應(yīng)用場景,量子計算,也是最近幾年我們計算熱點的技術(shù)。量子計算是利用量子力學,可以比傳統(tǒng)的計算機更快地解決復雜的問題。量子計算機的發(fā)展還處在非常前期的階段,相關(guān)的量子算法的研究和應(yīng)用也需要大量的算力做模擬支撐。
前面我們提到了 AI 大模型的業(yè)務(wù)應(yīng)用,為什么要用到大模型,大模型可以給我們帶來什么樣的收益?
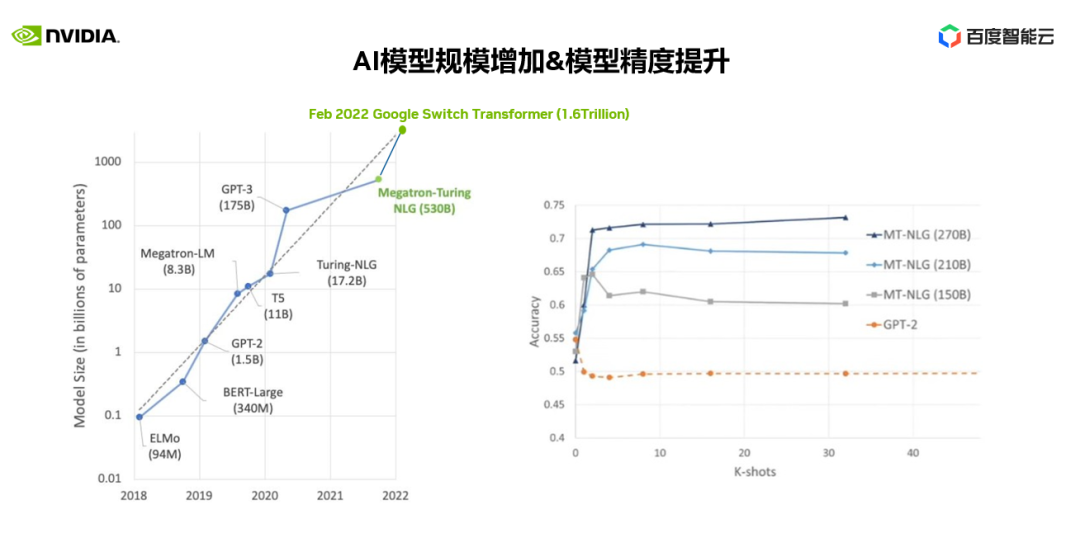
在右圖中我們可以看到 1.5B GPT-2 和 MT-NLG 在 150B-270B 不同參數(shù)規(guī)模下對應(yīng)用精度的影響。
我們可以清楚地看到大模型對應(yīng)用精度的效果,尤其是對復雜、泛化的業(yè)務(wù)場景的表現(xiàn)尤為突出。同時大模型在預測(inference)端正在快速發(fā)展,優(yōu)化特定場景、特定行業(yè)的性能,優(yōu)化預測端計算資源使用等,相信在不久的將來會有更多像 ChatGPT 一樣令人驚嘆的應(yīng)用在行業(yè)落地。這都將會推動大模型基礎(chǔ)研究,推動對訓練大模型所需算力的建設(shè)。一個以 GPU 為基礎(chǔ)的分布式計算系統(tǒng)也是大模型應(yīng)用所必須的。
AI 大模型訓練為什么要用到 GPU 集群,用到更大規(guī)模的 GPU?它能給我們的訓練帶來什么樣的收益?這邊我們用兩個實際的例子作為參考。
一個應(yīng)用是 BERT 340M 參數(shù)規(guī)模,使用 Selene A100 SuperPOD 集群,訓練完成則需要 0.2 分鐘,在使用 1/2 個集群規(guī)模,訓練完成需要 0.4 分鐘,使用 1/4 個集群規(guī)模下訓練完成則需要 0.7 分鐘。我們可以看到在小參數(shù)規(guī)模下,使用幾十臺 DGX A100 也可以快速完成整個訓練任務(wù),對于整個訓練的迭代影響并不大。
另一個是 Megatron 530B 參數(shù)規(guī)模的 NLP 大模型,訓練這個 530B 參數(shù)的大模型,使用整個 Selene SuperPOD 集群資源則需要 3.5 周、近一個月的時間才能完成,而使用 1/2、1/4 集群節(jié)點規(guī)模的情況下,則需要數(shù)月的訓練時間才能完成整個訓練,這對于大模型研發(fā)人員來說是不可接受的。另外研發(fā)人員的時間成本是非常寶貴的,研究到產(chǎn)品化的時間也是非常關(guān)鍵的,我們不可能把時間浪費在訓練等待上。
在管理層面,構(gòu)建一個 GPU 集群,通過集群的作業(yè)調(diào)度和管理系統(tǒng),可以優(yōu)化調(diào)度各種類型、各種需求的 GPU 任務(wù),使用集群的 GPU 資源,以最大化利用 GPU 集群。在 Facebook 的一篇論文中提到,通過作業(yè)調(diào)度管理系統(tǒng),F(xiàn)acebook AI 超級計算系統(tǒng)上每天可以承載 3.5 萬個獨立的訓練任務(wù)。
因此,GPU 規(guī)模和集群管理對于提升分布式任務(wù)的運行效率非常關(guān)鍵。
集群的最關(guān)鍵的地方就是通信,集群任務(wù)的調(diào)試優(yōu)化重點也是在使用各種并行方式優(yōu)化通信策略。在 GPU 集群中,通信主要分為兩個部分,一個是節(jié)點內(nèi)通信,一個是節(jié)點間通信。
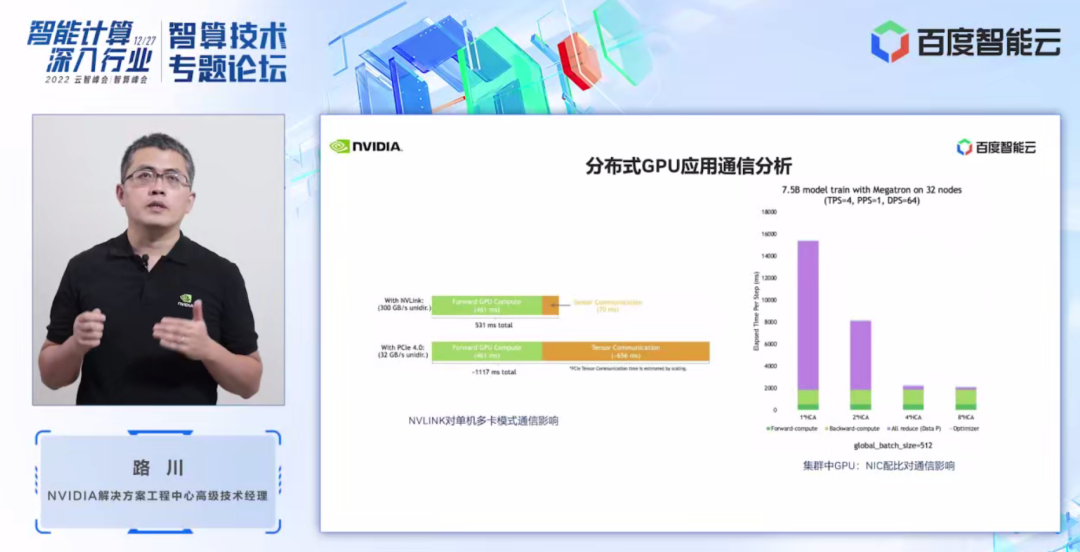
在左圖中我們可以看到節(jié)點間通信 NVLink 對于它的重要性。圖中示例使用 tensor 并行的方式,在節(jié)點間分別采用 NVLink 和采用 PCIe 4.0 進行通信的對比,我們可以看到,NVLink 環(huán)境下程序的通信時間僅需 70ms(毫秒),而 PCIe 環(huán)境下通信時間則需要 656ms,當用多個節(jié)點組成的集群環(huán)境下差距會更加明顯。
在右圖中,我們使用 7.5B 的 AI 模型,采用 TPS=4,PPS=1,數(shù)據(jù)并行 DPS=64 的情況下,在 32 個集群的節(jié)點規(guī)模下,不同網(wǎng)卡對分布式訓練任務(wù)的影響。紫色部分代表了通信占比,綠色代表計算時間占比。我們可以清晰地看到網(wǎng)卡數(shù)量、網(wǎng)絡(luò)帶寬對分布式應(yīng)用的性能的影響。
GPU 集群應(yīng)用于 AI 訓練也是最近幾年才逐步在客戶中開始應(yīng)用。在 AI 發(fā)展的早期,模型較小,大部分采單機多卡或是多機數(shù)據(jù)并行的方式進行訓練,所以對 GPU 集群的要求并不是很高。2018 年 11 月,NVIDIA 第一次推出基于 DGX-2 的 SuperPOD 架構(gòu),也是看到 AI 發(fā)展的趨勢,看到了 AI 應(yīng)用對 GPU 分布式集群在 AI 訓練中的需求。
SuperPOD 的架構(gòu)也在不斷地演進和優(yōu)化。通過 NVIDIA 實戰(zhàn)經(jīng)驗和性能優(yōu)化驗證,SuperPOD 可以幫助客戶迅速構(gòu)建起屬于自己的高性能 GPU 分布式集群。
NVIDIA 最新一代 Hopper GPU 架構(gòu)下 SuperPod 的集群拓撲
下面我來簡單介紹下,最新一代 Hopper GPU 架構(gòu)下 SuperPOD 的集群拓撲。
計算節(jié)點采用 Hopper 最新的 GPU,相比較與 Ampere GPU 性能提升 2~3 倍。計算性能的提升需要更強的網(wǎng)絡(luò)帶寬來支撐,所以外部的網(wǎng)絡(luò)也由原來的 200Gb 升級為 400Gb,400Gb 的網(wǎng)絡(luò)交換機可以最多支撐到 64 個 400Gb 網(wǎng)口,所以每個計算 POD 由原來的 20 個變?yōu)?32 個。更高的計算密度,在一個 POD 內(nèi) GPU 直接的通信效率要更高。
NDR Infiniband 網(wǎng)絡(luò)、AR、SHARP、SHIELD 等新的特性,在路由交換效率、聚合通信加速、網(wǎng)絡(luò)穩(wěn)定性等方面有了進一步的提升,可以更好的支持分布式大規(guī)模 GPU 集群計算性能和穩(wěn)定性。在存儲和管理網(wǎng)絡(luò)方面,增加了智能網(wǎng)卡的支持,可以提供更多的管理功能,適應(yīng)不同客戶的需求。
未來數(shù)據(jù)中心 GPU 集群架構(gòu)的發(fā)展趨勢:
計算、互聯(lián)、軟件
下面,站在 NVIDIA 的角度,我們再來探討一下,未來數(shù)據(jù)中心 GPU 集群的架構(gòu)發(fā)展趨勢。整個 GPU 的集群主要有三個關(guān)鍵因素,分別是:計算、互聯(lián)和軟件。

一,計算。集群的架構(gòu)設(shè)計中,單節(jié)點計算性能越高,越有優(yōu)勢,所以在 GPU 選擇上我們會采用最新的 GPU 架構(gòu),這樣會帶來更強的 GPU 算力。
在未來兩年,Hopper 將成為 GPU 分布式計算集群的主力 GPU。Hopper GPU 我相信大家已經(jīng)很了解,相關(guān)特性我在這就不在贅述。我只強調(diào)一個功能,Transformer 引擎。
在上文應(yīng)用的發(fā)展趨勢里,我們也提到了以 Transformer 為基礎(chǔ)的 AI 大模型的研究。Transformer 也是大模型分布式計算的代名詞,在 Hopper 架構(gòu)里新增加了 Transformer 引擎,就是專門為 Transformer 結(jié)構(gòu)而設(shè)計的 GPU 加速單元,這會極大地加速基于 Transformer 結(jié)構(gòu)的大模型訓練效率。
二,互聯(lián)。GPU 是 CPU 的加速器,集群計算的另外一個重要組成部分是 CPU。NVIDIA 會在 2023 年發(fā)布基于 Arm 72 核、專為高性能設(shè)計的 Grace CPU,配置 500GB/s LPDDR5X 內(nèi)存,900GB/s NVLink, 可以跟 GPU 更好地配合,輸出強大的計算性能。
基于 Grace CPU,會有兩種形態(tài)的超級芯片,一是 Grace+Hopper,二是 Grace+Grace。
Grace+Hopper,我們知道 GPU 作為 CPU 加速器,并不是所有應(yīng)用任務(wù)都適用于 GPU 來加速,其中很關(guān)鍵的一個點就是 GPU 和 CPU 之間的存儲帶寬的瓶頸,Grace+Hopper 超級芯片就是解決此類問題。
在 Grace Hopper 超級芯片架構(gòu)下,GPU 可以通過高速的 NVLink 直接訪問到 CPU 顯存。對于大模型計算,更多應(yīng)用遷移到GPU上加速都有極大的幫助。
Grace+Grace ,是在一個模組上可以提供高達 144 CPU 核,1 TB/s LPDDR5X 的高速存儲,給集群節(jié)點提供了強勁的單節(jié)點的 CPU 計算性能,從而提升整個集群效率。
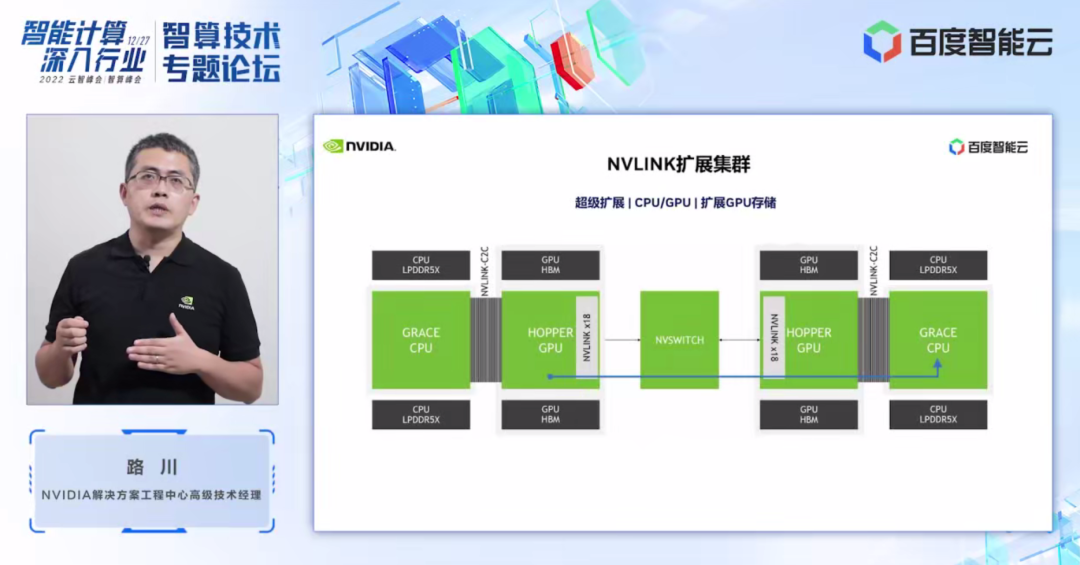
之前我們所熟知的 NVLink,都是應(yīng)用在節(jié)點內(nèi) GPU 和 GPU 之間的互聯(lián)。在 Grace Hopper 集群下,NVLink 可以做到節(jié)點之間互聯(lián),這樣節(jié)點之間 GPU-GPU,或 GPU-CPU,或 CPU-CPU 之間,都可以通過高速的 NVLink 進行互聯(lián),可以更高效地完成大模型的分布式計算。
在未來也許我們可以看到更多業(yè)務(wù)應(yīng)用遷移到 Grace+Hopper 架構(gòu)下,節(jié)點之間的 NVLlink 高速互聯(lián)也許會成為一個趨勢,更好地支持 GPU 分布式計算。
智能網(wǎng)卡在集群中的應(yīng)用,首先智能網(wǎng)卡技術(shù)并不是一個新的技術(shù),各家也有各家的方案,傳統(tǒng)上我們可以利用智能網(wǎng)卡把云業(yè)務(wù)場景下的 Hypervisor 管理、網(wǎng)絡(luò)功能、存儲功能等卸載到智能網(wǎng)卡上進行處理,這樣可以給云客戶提供一個云生的計算資源環(huán)境。NVIDIA 智能網(wǎng)卡跟百度也有很深的合作,包括 GPU 集群裸金屬方案也都配置了 NVIDIA 智能網(wǎng)卡進行管理。
在非 GPU 的業(yè)務(wù)場景下,我們看到智能網(wǎng)卡對 HPC 應(yīng)用業(yè)務(wù)的加速,主要是在分子動力學,氣象和信號處理應(yīng)用上,通過對集群中聚合通信的卸載,我們可以看到應(yīng)用可以獲得 20% 以上的收益。智能網(wǎng)卡技術(shù)也在不斷更新、升級,業(yè)務(wù)場景也在不斷探索。相信在未來的 GPU 集群上會有更多的業(yè)務(wù)或優(yōu)化加速可以使用到智能網(wǎng)卡技術(shù)。
三,軟件。數(shù)據(jù)中心基礎(chǔ)設(shè)施是基礎(chǔ)底座,如何能夠更高效、快速、方便地應(yīng)用到基礎(chǔ)架構(gòu)變革所帶來的優(yōu)勢,軟件生態(tài)的不斷完善和優(yōu)化是關(guān)鍵。
針對不同的業(yè)務(wù)場景,NVIDIA 提供了 SuperPOD、OVX 等數(shù)據(jù)中心基礎(chǔ)設(shè)施的參考架構(gòu),可以幫助用戶構(gòu)建最優(yōu)的數(shù)據(jù)中心基礎(chǔ)設(shè)施架構(gòu)。
上層提供了各種軟件加速庫,如 cuQuantum 可以幫助客戶直接在 GPU 集群上模擬量子算法計算,Magnum IO 用來加速數(shù)據(jù)中心 GPU 集群和存儲系統(tǒng)的訪存 IO 效率,提升整個集群計算效率。
在未來會有更多的軟件工具、行業(yè) SDK,來支撐數(shù)據(jù)中心架構(gòu)的使用,讓各領(lǐng)域的研發(fā)人員不需要了解底層細節(jié),更加方便、快速地使用到數(shù)據(jù)中心 GPU 集群的的最優(yōu)性能。
原文標題:百度智算峰會精彩回顧:應(yīng)用驅(qū)動的數(shù)據(jù)中心計算架構(gòu)演進
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
英偉達
+關(guān)注
關(guān)注
22文章
3842瀏覽量
91688
原文標題:百度智算峰會精彩回顧:應(yīng)用驅(qū)動的數(shù)據(jù)中心計算架構(gòu)演進
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
智算中心會取代通用算力中心嗎?

回顧寧暢2024年度精彩瞬間
百度文心大模型日均調(diào)用量超15億
云計算與數(shù)據(jù)中心的關(guān)系
簡述數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)的演變
英特爾至強6能效核處理器助力數(shù)據(jù)中心變革
數(shù)據(jù)中心產(chǎn)品通常包括哪些

英特爾與百度共同為AI時代打造高性能基礎(chǔ)設(shè)施

百度百舸AI計算平臺4.0震撼發(fā)布
Molex連接器助力構(gòu)建未來數(shù)據(jù)中心 充分發(fā)揮人工智能AI的力量

云數(shù)據(jù)中心、智算中心、超算中心,有何區(qū)別?
2024百度移動生態(tài)萬象大會:百度新搜索11%內(nèi)容已AI生成
百度沈抖沈抖正式發(fā)布新一代智能計算操作系統(tǒng)—萬源
百度沈抖:傳統(tǒng)云計算不再是主角,智能計算呼喚新一代“操作系統(tǒng)”






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論