") 基于OpenVINO? 2022.2與oneAPI構(gòu)建GPU視頻分析服務(wù)流水線 第二篇
基于OpenVINO? 2022.2與oneAPI構(gòu)建GPU視頻分析服務(wù)流水線 第二篇
作者:楊亦誠
前文回顧
基于OpenVINO 2022.2與oneAPI構(gòu)建GPU視頻分析服務(wù)流水線-第一篇
任務(wù)背景
在 Part 1 部分我們已經(jīng)討論了如何在英特爾 GPU 設(shè)備上利用 oneVPL 和 OpenVINO構(gòu)建一個簡單的視頻分析流水線服務(wù),但是在真實的工程環(huán)境中,為了能進一步“壓榨”邊緣設(shè)備有限硬件資源,降低項目成本,單臺 AI Box 往往需要接入不止一路的視頻分析任務(wù),并同時進行解碼與推理,這種情況如何優(yōu)化多任務(wù)進程下的 AI 分析性能也成為了另外一大挑戰(zhàn)。
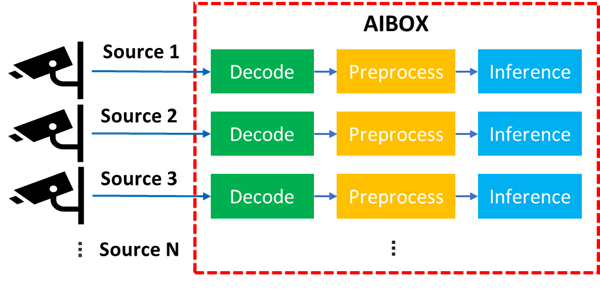
圖:AI Box 多通道處理示意圖
首先,我們來看一下多通道視頻分析任務(wù)的優(yōu)化方向,這里有兩個非常重要概念:延遲 or 吞吐量?
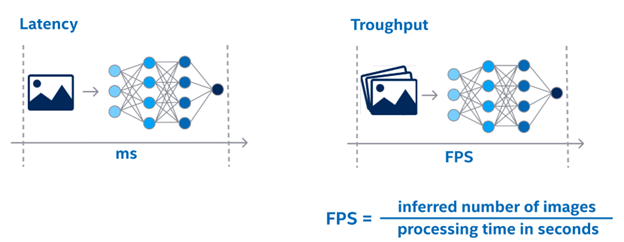
圖:延遲和吞吐量對比說明
·延遲(Lantency),是指在處理單幀任務(wù)時所消耗的總時間;
·吞吐量(Throughput),是指在單位時間內(nèi)所能處理的任務(wù)總量。
鑒于單通道視頻分析任務(wù)中,視頻源中的每一幀是以流水線這樣的形式(一個接一個one by one)被送入到視頻分析服務(wù)中,前后兩幀存在時間上的依賴關(guān)系,理論上我們在同一時刻內(nèi)只需要處理一幀畫面的推理任務(wù),因此這個時候我們更多是以延遲作為它的優(yōu)化方向。但在多通道情況下,通道之間的數(shù)據(jù)往往沒有相關(guān)性,我們需要在單位時間內(nèi)盡可能的去處理更多通道的數(shù)據(jù),在這種情況下,我們把吞吐量作為性能的主要優(yōu)化方向,而提升吞吐量最好的方法就是提升多任務(wù)的并行性,減少單一任務(wù)多線程間由于數(shù)據(jù)同步帶來的額外開銷。
OpenVINO 推理并行優(yōu)化方案
在談到 OpenVINO 的并行優(yōu)化方案的時候,這里有幾個關(guān)鍵的配置參數(shù)不得不提一下:
· Thread:硬件系統(tǒng)可分配的最小并行執(zhí)行單位,在 CPU 和 GPU 上,這個數(shù)字分別和 CPU 的核心數(shù)和 GPU 的 EU(Execution Unit)數(shù)相掛鉤。
· Stream:OpenVINO對于多 Thread 的管理單元,OpenVINO可以將一個或多個 Thread 封裝為一個 Stream,多個 Stream 中的推理任務(wù)可以并行執(zhí)行,且平均分配 Thread 總數(shù)。
· Infer Request:推理任務(wù)的承載實例,每個 Infer Request 在執(zhí)行過程中會被單獨分配到一個 stream 中。
· Batch size:將 Batch size 個輸入數(shù)據(jù)打包成在一起,送入 infer request 中進行推理,下圖展示的是 Batch size 為一的情況(每個 infer request 中只有一個 input image )。
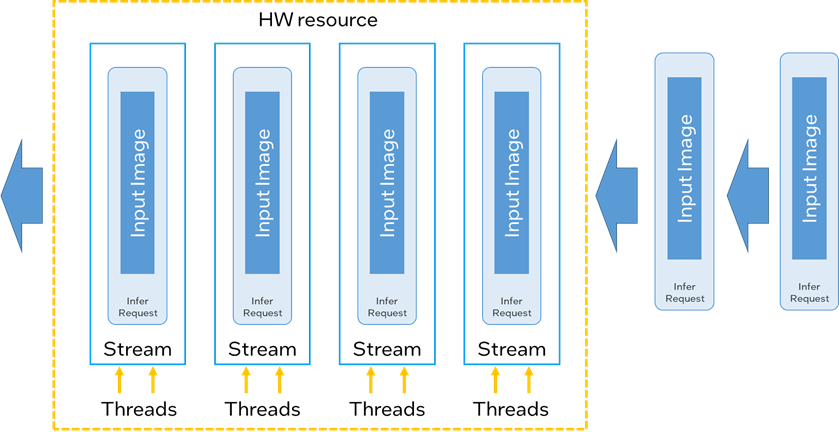
圖:Thread, Stream, Infer request 關(guān)系說明
可以看到OpenVINO中的 Stream 更像是一個并行執(zhí)行的推理任務(wù)隊列,當其中的一個 infer request 完成推理后,這個閑置出的 stream 才能去加載下一個 infer request 推理任務(wù)。因此在實際開發(fā)過程中,我們需設(shè)置 infer request 的數(shù)量大于 stream 數(shù)量,確保在空閑 infer reques 在完成數(shù)據(jù)載入后,會被不間斷地被送入空閑的 stream 中。
這里做個不一定恰當?shù)谋扔鳎瑂tream 好比是工位,infer request 好比是工人,工人只有坐在工位上才能工作,沒有工位的工人只能等到前面的工人完成作業(yè)后,才能坐進工位進行工作。但與此同時我們要確保那些沒有工位的工人在等待的過程中要做好充足的準備,比如準備好工具(加載輸入數(shù)),這樣一旦坐進工位后,就立馬可以開動干活。
大家可以通過OpenVINO自帶的 benmark_app 性能基準工具對這三個參數(shù)進行配置,分別測試在不同配置情況下,對于實際性能的影響。
benchmark_app -m MODEL_DIR -nstreams NUMBER_STREAMS -nthreads NUMBER_THREADS -nireq NUMBER_INFER_REQUESTS --b BATCH_SIZE
向右滑動查看完整代碼
為實現(xiàn) Infer request 并行化的目標,OpenVINO中特別提供了一組異步推理接口。在使用異步接口進行推理時。推理線程采用非阻塞模式,這也意味這個你可以同時開啟多個推理請求并行執(zhí)行,或是在處理單個推理任務(wù)的過程中,之前其他前后處理任務(wù)。相較同步 API,異步 API 可以盡可能的提升設(shè)備資源的利用率。
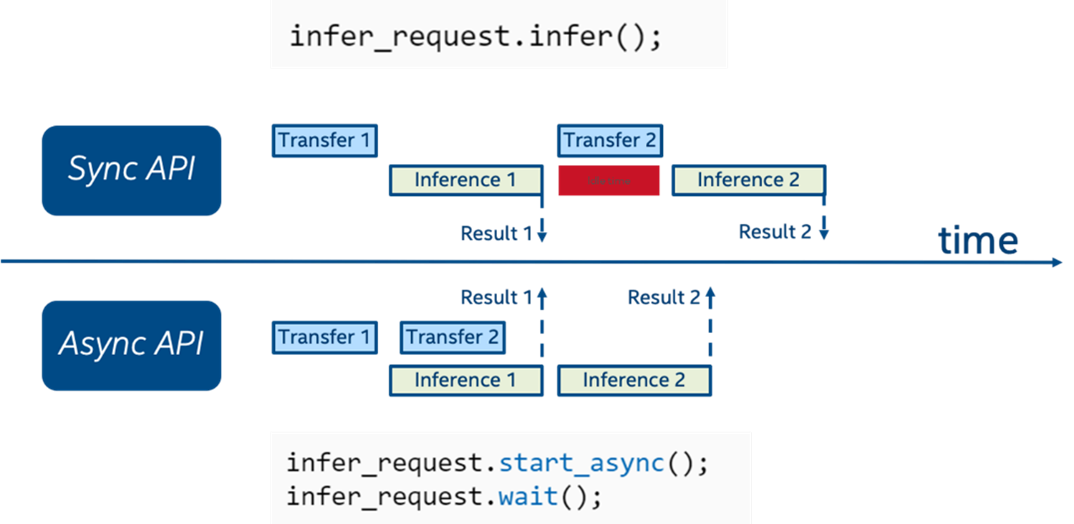
圖:同步與異步 API 比較
回到多通道視頻流分析優(yōu)化這個主題上,為了提升多任務(wù)的并行化率,我們目前主要有以下兩種優(yōu)化策略,這里的 batching 是指我們提前將多個輸入數(shù)據(jù)按次序疊加在一起,同時送進 infer request 中進行推理,并在獲取結(jié)果后對他們進行拆分,同樣可以達到數(shù)據(jù)并行的目的:
· 小 Batch size 配大 Stream number
· 大 Batch size 配小 Stream number
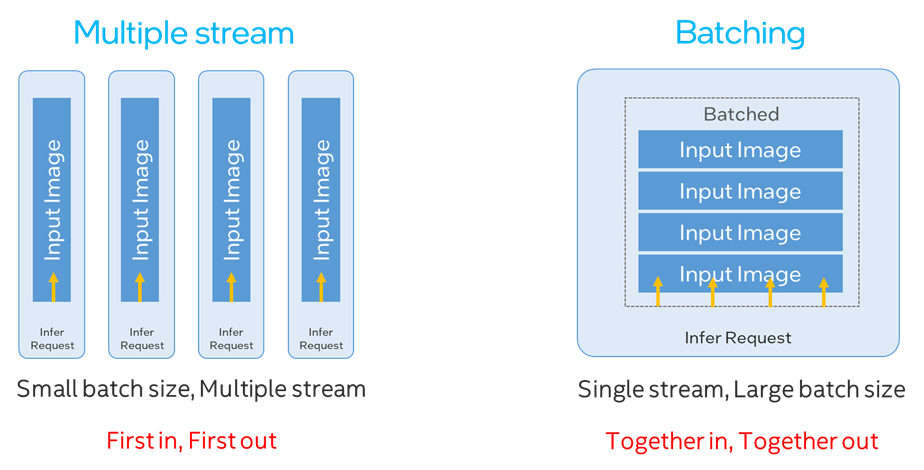
圖:Multiple stream和Batching方案比較
這兩種方案在 GPU 上各有不同的優(yōu)缺點。首先就小 Batch size 配大 stream number 來說,由于不同的 stream 之間沒有依賴性,所以先開始推理的 infer request 就可以先獲得結(jié)果數(shù)據(jù),適合對單幀數(shù)據(jù)推理延時比較敏感的場景,但同樣問題也顯而易見,由于每個 stream 的 OpenCL 隊列是需要通過單獨 CPU 線程來維護,并通過輪詢機制來獲取結(jié)果數(shù)據(jù),因此這也造成了對 CPU 額外的資源開銷,GPU stream 數(shù)越高,CPU 資源占用也越大。
而大 Batch size 配小 stream number 則沒有這樣的煩惱,可以最大化減少 CPU 上的開銷。但因為我們需要將多個 input 打包,所以先完成解碼的數(shù)據(jù)會和后完成解碼的數(shù)據(jù)一起送入 infer request 中進行推理,并同時返回結(jié)果,所以對時延敏感的任務(wù)并不友好。
針對 GPU 吞吐量這一優(yōu)化目標而言,利用 benchmark_app 實測發(fā)現(xiàn),在 stream 數(shù)量達到一個瓶頸后,則對對吞吐量提升沒有任何幫助,而通過增加 batch size 方式對于吞吐量性能的提升更為顯著,因此在該方案中,我們將采用大 batch 配小 stream 的方式來優(yōu)化性能。
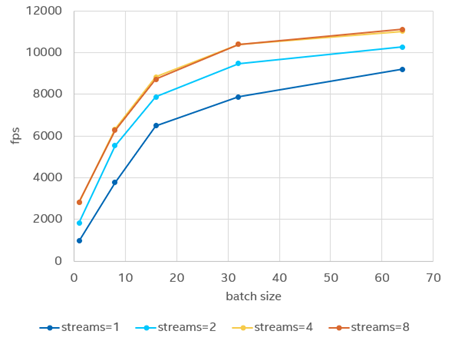
圖:比較不同stream和batch size配置下對于GPU性能的影響
(非官方數(shù)據(jù),僅供趨勢參考)
方案設(shè)計
這里我們用來做演示的多通道視頻分析服務(wù)主要會分為兩個部分,分別對應(yīng)了 oneVPL 和OpenVINO這兩個工具組件。
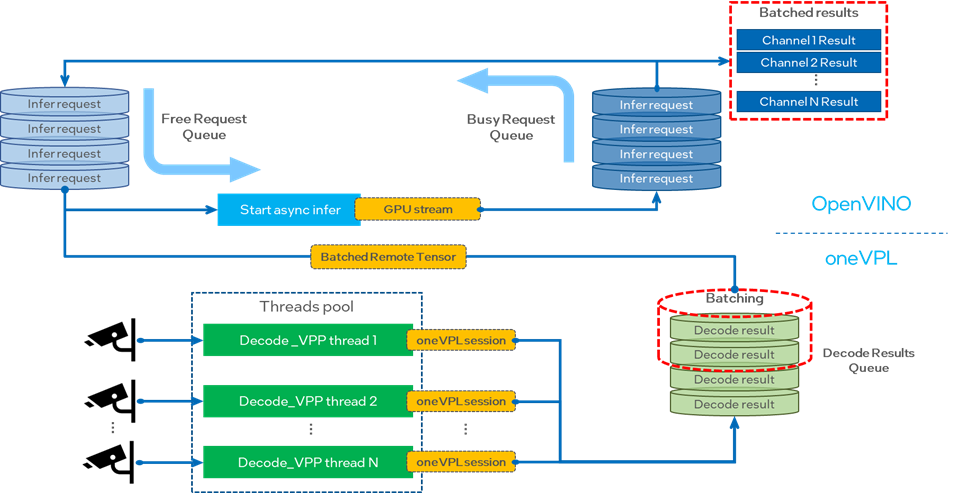
圖:多通道視頻處理服務(wù)示例流程圖
1. 視頻處理部分
視頻處理部分我們需要使用 oneVPL 完成每一個通道數(shù)據(jù)的解碼和前處理任務(wù),并將結(jié)果按次序送入解碼結(jié)果隊列(Decode results queue)中,等待后面的 AI 處理部分進行調(diào)用。為了提高任務(wù)的并行度,我們需要為每個通道的視頻處理任務(wù)單獨配置一個 CPU 線程,此外由于 oneVPL 的每個 session 只能處理一個數(shù)據(jù)源示例,因此我們同樣也要為每個視頻源單獨創(chuàng)建一個獨立的 session 來進行 decode 和 VPP 處理。
在返回結(jié)果數(shù)據(jù)時,我們希望隊列中的數(shù)據(jù)可以被存儲在通道間共享的 GPU surface 內(nèi)存中,方便OpenVINO的 remote tensor 進行調(diào)用,但實際上每次初始化 oneVPL session 以后,都會生成一個新的內(nèi)存 handle 句柄對象,所以我們要通過 MFXVideoCORE_SetHandle 強制為每個 session 配置相同的handle句柄。
MFXVideoCORE_SetHandle 配置 handle
sts = MFXVideoCORE_SetHandle(session,
static_cast(MFX_HANDLE_VA_DISPLAY),
va_dpy);
向右滑動查看完整代碼
2. AI 推理部分
AI 推理部分是本次分享的重頭戲,首先我們需要分別創(chuàng)建兩個隊列用來存放開啟推理任務(wù)的 busy infer request,以及空閑的 free infer request,在空閑的 infer request 中提前載入經(jīng)過 oneVPL 處理以后的結(jié)果數(shù)據(jù),等待 busy infer request 完成推理后,再送入 stream 中進行推理, 而 busy infer request 則會在輸出結(jié)果數(shù)據(jù),轉(zhuǎn)變?yōu)?free infer request,被送入到 free request 隊列中,并從 oneVPL 的結(jié)果隊列中取出第一組等待被推理的解碼結(jié)果。通過這種機制我可以確保 stream 中會源源不斷有 infer request 被執(zhí)行。
創(chuàng)建 free request 隊列
BlockingQueue free_requests; for (int i = 0; i < FLAGS_nr; i++) ? ?free_requests.push(compiled_model.create_infer_request());
向右滑動查看完整代碼
從 busy request 隊列中的 infer request 取出推理結(jié)果數(shù)據(jù), 并壓入 free request 隊里
for (;;) {
auto res = busy_requests.pop();
auto batched_frames = res.first;
auto infer_request = res.second;
if (!infer_request)
break;
infer_request.wait();
ov::Tensor output_tensor = infer_request.get_output_tensor(0);
PrintMultiResults(output_tensor, batched_frames, input_shape);
// When application completes the work with frame surface, it must call release to avoid memory leaks
for (auto frame : batched_frames)
{
frame.first->FrameInterface->Release(frame.first);
}
free_requests.push(infer_request);
}
向右滑動查看完整代碼
此外在為每個 free infer request 加載解碼結(jié)果數(shù)據(jù)之前,我們還需要進行 batching 的操作,將多個 decode result 隊列當中的前n個數(shù)據(jù)打包成一個 batch,再進行推理。大家可以根據(jù)自己 GPU 的機能選擇合適的 batch size,理論上 batch size 越大帶來的吞吐量提升也越大,但受限于 GPU 上的內(nèi)存資源有限,過大的 batch size 反而會造成性能瓶頸,因此 batch size 的大小盡量以實測為準。當然如果嫌測試麻煩,OpenVINO 2022.1的版本中也更新的 auto-batching 功能,該功能會根據(jù) GPU 的硬件資源能力和實際任務(wù)負載,自動配置為 GPU 配置 batch size 大小,提供相對最優(yōu)的配置參數(shù)。具體說明詳見:
https://docs.openvino.ai/latest/openvino_docs_OV_UG_Automatic_Batching.html#doxid-openvino-docs-o-v-u-g-automatic-batching:
將多個解碼結(jié)果打包為一個batch
for (auto va_surface : batched_frames)
{
mfxResourceType lresourceType;
mfxHDL lresource;
va_surface.first->FrameInterface->GetNativeHandle(va_surface.first,
&lresource,
&lresourceType);
VASurfaceID lvaSurfaceID = *(VASurfaceID *)(lresource);
auto nv12_tensor = shared_va_context.create_tensor_nv12(shape[2], shape[3], lvaSurfaceID);
y_tensors.push_back(nv12_tensor.first);
uv_tensors.push_back(nv12_tensor.second);
}
向右滑動查看完整代碼
參考示例使用方法
本示例已開源,并在 Ubuntu 20.04 操作系統(tǒng),第十一代英特爾 酷睿 iGPU 及 ARC A380 dGPU 環(huán)境下進行了驗證。
1. 依賴安裝及編譯
可以參考 github 中的 README 文檔完成以來安裝和源碼編譯:
https://github.com/OpenVINO-dev-contest/decode-infer-on-GPU
2. 運行輸出
當完成可執(zhí)行文件編譯后,可以按以下規(guī)則運行多通道版本的示例
$ ./multi_src/multi_source -i ../content/cars_320x240.h265,../content/cars_320x240.h265,../content/cars_320x240.h265 -m ~/vehicle-detection-0200/FP32/vehicle-detection-0200.xml -bz 2 -nr 4 -fr 30
向右滑動查看完整代碼
其中可配置參數(shù)為:
-i = .h265格式的輸入視頻路徑,多視頻源之間用逗號隔開
-m = IR .xml 格式 IR 模型文件路徑;
-bs = Batch size 大小;
-nr = Inference requests 數(shù)量;
-fr = 單個視頻源的解碼幀數(shù),默認前30幀;
輸出結(jié)果示意如下圖,該示例會為按預(yù)先設(shè)置的 batch size 大小輸出對應(yīng)結(jié)果,此處 batch size 為2:
libva info: VA-API version 1.12.0 libva info: Trying to open /opt/intel/mediasdk/lib64/iHD_drv_video.so libva info: Found init function __vaDriverInit_1_12 libva info: va_openDriver() returns 0 Implementation details: ApiVersion: 2.7 Implementation type: HW AccelerationMode via: VAAPI Path: /usr/lib/x86_64-linux-gnu/libmfx-gen.so.1.2.7 Frames [stream_id=1] [stream_id=0] image0: bbox 204.99, 49.43, 296.43, 144.56, confidence = 0.99805 image0: bbox 91.26, 115.56, 198.41, 221.69, confidence = 0.99609 image0: bbox 36.50, 44.75, 111.34, 134.57, confidence = 0.98535 image0: bbox 77.92, 72.38, 155.06, 164.30, confidence = 0.97510 image1: bbox 204.99, 49.43, 296.43, 144.56, confidence = 0.99805 image1: bbox 91.26, 115.56, 198.41, 221.69, confidence = 0.99609 image1: bbox 36.50, 44.75, 111.34, 134.57, confidence = 0.98535 image1: bbox 77.92, 72.38, 155.06, 164.30, confidence = 0.97510 Frames [stream_id=1] [stream_id=0] image0: bbox 206.96, 50.41, 299.54, 146.23, confidence = 0.99805 image0: bbox 93.81, 115.29, 200.86, 222.94, confidence = 0.99414 image0: bbox 84.15, 92.91, 178.14, 191.82, confidence = 0.99316 image0: bbox 37.78, 45.82, 113.29, 132.28, confidence = 0.98193 image0: bbox 75.96, 71.88, 154.31, 164.54, confidence = 0.96582 image1: bbox 206.96, 50.41, 299.54, 146.23, confidence = 0.99805 image1: bbox 93.81, 115.29, 200.86, 222.94, confidence = 0.99414 image1: bbox 84.15, 92.91, 178.14, 191.82, confidence = 0.99316 image1: bbox 37.78, 45.82, 113.29, 132.28, confidence = 0.98193 image1: bbox 75.96, 71.88, 154.31, 164.54, confidence = 0.96582 ... decoded and infered 60 frames Time = 0.328556s
向右滑動查看完整代碼
小結(jié)
通過 batching 以及多線程的方式,我們可以進一步提升多數(shù)據(jù)源任務(wù)處理時,GPU 在吞吐量性能上的優(yōu)勢,并且降低 CPU 側(cè)的任務(wù)負載。隨著越來越多的英特爾獨立顯卡系列產(chǎn)品的推出,相信這樣一套參考設(shè)計幫助開發(fā)者在 GPU 平臺上實現(xiàn)更出色的性能表現(xiàn)。
-
英特爾
+關(guān)注
關(guān)注
61文章
10007瀏覽量
172152 -
gpu
+關(guān)注
關(guān)注
28文章
4768瀏覽量
129227 -
流水線
+關(guān)注
關(guān)注
0文章
121瀏覽量
25921
原文標題:基于OpenVINO? 2022.2與oneAPI構(gòu)建GPU視頻分析服務(wù)流水線 第二篇
文章出處:【微信號:英特爾物聯(lián)網(wǎng),微信公眾號:英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
工業(yè)二維碼條碼掃描器流水線條碼掃描

工業(yè)讀碼器解決方案在自動化流水線上掃描條碼的應(yīng)用

SMT流水線布局優(yōu)化技巧
工業(yè)流水線的智能助手——智能計數(shù),效率倍增

行云流水線 滿足你對工作流編排的一切幻想~skr
ADS900高速流水線模數(shù)轉(zhuǎn)換器(ADC)數(shù)據(jù)表

ADS930高速流水線模數(shù)轉(zhuǎn)換器(ADC)數(shù)據(jù)表
ADS5421流水線式模數(shù)轉(zhuǎn)換器(ADC)數(shù)據(jù)表
ADS5413 CMOS流水線模數(shù)轉(zhuǎn)換器(ADC)數(shù)據(jù)表
ADS828流水線式CMOS模數(shù)轉(zhuǎn)換器數(shù)據(jù)表
固定式的掃碼器在SMT流水線中的使用

RISC-V架構(gòu)的多級流水線處理
具有3態(tài)輸出的多級流水線寄存器數(shù)據(jù)表
固定式安裝工業(yè)讀碼器,助力提高流水線人工上料效率

牽引機和挖掘機裝配流水線自動互鎖防呆系統(tǒng)無線通訊應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論