") 國產GPU繞不開的CUDA生態(tài)
國產GPU繞不開的CUDA生態(tài)
近日,摩爾線程在北京發(fā)布多款軟硬件新品,包括新一代GPU“春曉”、面向個人電腦的消費級顯卡MTT S80和服務器計算卡MTT S3000、一體化計算設備“MCCX元計算一體機”,以及開發(fā)套件、數(shù)字人解決方案等。GPU“春曉”做為本次發(fā)布會的核心產品受到廣泛關注。
“春曉”是摩爾線程的第二顆GPU,也是摩爾線程首顆面相國內消費級市場發(fā)售的GPU,它強調游戲、元宇宙與渲染用途,最重要的是,這個GPU支持英偉達CUDA生態(tài)。
其實經常關注顯卡的同學總能從英偉達的發(fā)布會上聽到CUDA這個詞,例如最新的RTX3060有擁有多少顆CUDA核心,某某游戲首發(fā)即支持CUDA生態(tài)等。作為顯卡領域的高頻詞匯,很多人好奇CUDA到底是什么?為什么國產顯卡會用到英偉達的技術?本文將帶你了解即熟悉又陌生的CUDA。
CUDA是什么?
CUDA(Compute Unified Device Architecture,統(tǒng)一計算架構)是由英偉達所推出的一種集成技術,是該公司對于GPGPU的正式名稱。通過這個技術,用戶可利用NVIDIA的GPU進行圖像處理之外的運算,CUDA也是首次可以利用GPU作為C-編譯器的開發(fā)環(huán)境。簡單來說,程序員平時如果不使用特定框架都是針對CPU進行編程的,CUDA是全球最大GPU廠商英偉達推出的針對GPU的編程的架構。
2006年,英偉達發(fā)布了CUDA,它提供了GPU編程的簡易接口,程序員可以基于CUDA編譯基于GPU的應用程序,利用GPU的并行計算能力更高效的解決復雜計算難題。在CUDA發(fā)布之前,程序員需要到顯卡內核并利用機器碼進行編譯,編程過程相當繁瑣也很困難。CUDA的發(fā)布,相當于將較為復雜的底層代碼封裝成了一個個簡單接口,使用時直接調用,其在GPU編程領域的革命性不亞于C、Python、PHP等高等編程語言的發(fā)明。當然,CUDA本身也是兼容C語言的,其本身就類似C語言,這可以幫助程序員更快速上手CUDA。現(xiàn)在主流的深度學習框架大多都基于CUDA進行GPU加速運算。
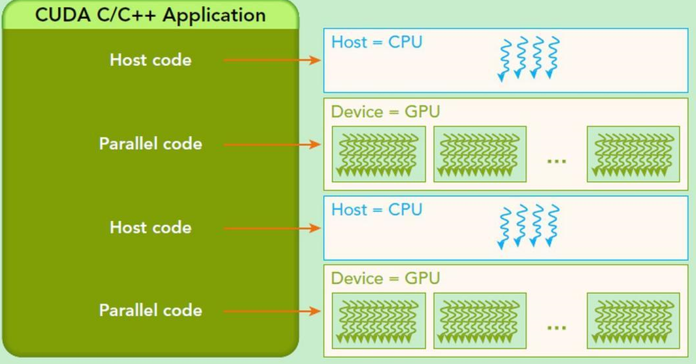
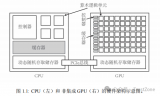
CUDA工作流程 圖源:CSDN
從硬件角度看,英偉達會經常宣傳自家顯卡擁有的CUDA Core數(shù)量。CUDA Core其實就是英偉達的流處理器,也就是FP32計算單元,同樣的結構在AMD的GPU內叫做SP。與CUDA Core相對的還有Tensor Core張量核心,從字面上就能看出該核心主要針對深度學習中的Tensor計算設計。Tensor計算就是混合精度計算,即在底層硬件算子層面用半精度(FP16)進行輸入和輸出,使用全精度(FP32)進行計算放置丟失過多精度的操作,這個底層硬件就是Tensor Core。CUDA 9.0引入了一個“warp矩陣函數(shù)” C++語言API,以便開發(fā)者可以使用GPU上的Tensor Core。
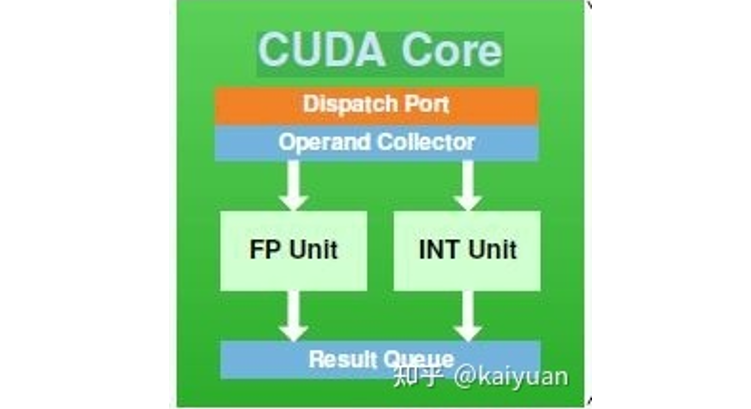
CUDA Core 圖源:知乎
CUDA與 GPGPU的概念一脈相承。GPU就是傳統(tǒng)意義上的顯卡與圖形加速卡。隨著人工智能產業(yè)爆炸式增長,導致計算復雜化和算力不足,CPU并行計算能力遠不如GPU,使得GPU在通用計算領域逐漸領先,為了進一步專注通用計算,GPGPU便應運而生。GPGPU與CUDA之間關系十分密切。GPGPU其實是去掉了圖形顯示功能的GPU,它將全部能力都投入到通用計算上,CUDA的出現(xiàn)讓GPU真正實現(xiàn)更廣泛的通用計算。CUDA與GPGPU也直接推動了AI與深度學習的發(fā)展與產業(yè)革命。
為什么要兼容CUDA?
當我們了解了CUDA是怎么回事,也就方便解釋為什么國產GPU需要兼容CUDA。
前文提到,目前世界上的主流深度學習架構都在使用CUDA,其主要原因就是深度學習的重要載體—GPU市場已被英偉達占領大半。隨之而來的,就是市面上絕大部分GPU相關軟件都是用CUDA開發(fā),國產GPU兼容CUDA可以同時“繼承”英偉達打造好的軟件生態(tài),也有更多資料可供學習,這對于蹣跚起步的國產GPU行業(yè)來說,減輕了不少開發(fā)難度,也降低了推廣壓力。
從開發(fā)角度分析。業(yè)內GPU工程師稱目前GPU市場可以籠統(tǒng)的分成兩大塊,分別是計算和渲染。此前國內GPU廠商通常專注與計算方面的研發(fā),也有少部分渲染產品問世,最近摩爾線程發(fā)布的GPU強調其具有強大的渲染能力。然而渲染賽道難度較大,其計算復雜度更高,除了通用計算,還包圖形渲染、前后端著色器配置、物體幾何屬性等需要處理。目前世界上標準API主要是CUDA與OpenCL,CUDA是英偉達系統(tǒng)架構,OpenCL則主要被AMD采用。采用標準化的API接口,無論是CUDA還是OpenCL,都可以極大減少開發(fā)渲染類GPU的前提投入,后期可以再做相應的優(yōu)化,這樣可以降低與CUDA等 “地位”穩(wěn)固的GPU生態(tài)直接競爭的難度。
從市場推廣角度看。英偉達的CUDA生態(tài)已經問世多年,與下游軟件、驅動廠家已經有了深度合作。大部分廠家對于GPU生態(tài)的觀點,往往是不在乎GPU本身好與壞,而是關注GPU好不好用、能不能用。好不好用的評價較為主觀,但采用現(xiàn)成的英偉達CUDA接口進行編程,可以規(guī)避大多數(shù)未知風險,多數(shù)初創(chuàng)企業(yè)開發(fā)GPU軟件采用統(tǒng)一接口也能增加開發(fā)穩(wěn)定性,降低人才招聘難度。所以,構建自己的GPU生態(tài)要慢慢起步,一味求快推廣自家生態(tài)只會把風險轉嫁給更多下游開發(fā)者。
國產GPU要挑戰(zhàn)CUDA嗎?
CUDA本身涵蓋了多個技術領域,其開發(fā)與后續(xù)更新都與英偉達自家GPU高度綁定,即使全部開源,第三方廠家也難以完美移植到自家GPU上。從另一個角度看,英偉達在GPU領域的壟斷地位主要通過CUDA平臺上的軟件生態(tài)實現(xiàn)。國產GPU若想真正做到與英偉達一較高下,CUDA生態(tài)是繞不開的最終BOSS。
知乎用戶對英偉達GPU生態(tài)做出分析。國產GPU廠商若無法做到與英偉達的架構、封裝技術、驅動優(yōu)化等都保持完全一致,CUDA生態(tài)就一定不會完美適配其他顯卡。做到完全移植,CUDA生態(tài)內的各種庫以及套件等都需要做相應調試,工作量太大。
此外,CUDA也并不是一成不變的。每隔一代GPU,CUDA架構就會發(fā)生很大變化。每個驅動小版本推送,CUDA都會做出部分微調。國產GPU如果完全基于CUDA生態(tài)進行開發(fā),那它的硬件更新將完全綁定英偉達的開發(fā)進程,這樣就失去了主動性,且永遠慢人一步。
不過內開發(fā)者也不用悲觀。CUDA本質是一個計算結構,甚至是一個理念,它并不需要英偉達的完全授權。我們可以參考英偉達的有力競爭者AMD。AMD的生態(tài)雖然基于開源生態(tài)OpenCL開發(fā),但AMD也制作了HIP的編程模式,與CUDA相比,其開發(fā)函數(shù)甚至可以進行直接替換。如果說英偉達在GPU領域是摸著石頭過河的,那AMD就是摸著英偉達過河。國內GPU廠家或許可以參考AMD發(fā)展模式,前期借鑒可以是后期創(chuàng)新的基礎。
寫在最后
CUDA作為英偉達壟斷GPU領域的關鍵力量,是國產廠商必須面對的挑戰(zhàn)。CUDA在誕生之初,為人們在深度學習與AI領域攻堅克難立下汗馬功勞,但如果它被用來鉗制新力量的發(fā)展,CUDA也將成為英偉達的馬奇諾防線。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4768瀏覽量
129217 -
CUDA
+關注
關注
0文章
121瀏覽量
13656 -
英偉達
+關注
關注
22文章
3842瀏覽量
91680
原文標題:國產GPU繞不開的CUDA生態(tài)
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
《CST Studio Suite 2024 GPU加速計算指南》
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
打破英偉達CUDA壁壘?AMD顯卡現(xiàn)在也能無縫適配CUDA了
大模型發(fā)展下,國產GPU的機會和挑戰(zhàn)

英國公司實現(xiàn)英偉達CUDA軟件在AMD GPU上的無縫運行
軟件生態(tài)上超越CUDA,究竟有多難?
借助NVIDIA Aerial CUDA增強5G/6G的DU性能和工作負載整合
Keil使用AC6編譯提示CUDA版本過高怎么解決?
大模型時代,國產GPU面臨哪些挑戰(zhàn)

國產GPU在AI大模型領域的應用案例一覽

盤點國產GPU在支持大模型應用方面的進展

一文詳解GPU硬件與CUDA開發(fā)工具
GPU CUDA 編程的基本原理是什么





 工商網監(jiān)
工商網監(jiān)
評論