") 基于本體的金融知識(shí)圖譜自動(dòng)化構(gòu)建技術(shù)
基于本體的金融知識(shí)圖譜自動(dòng)化構(gòu)建技術(shù)
寫(xiě)在前面
文本是參加2020CCKS評(píng)測(cè) 基于本體的金融知識(shí)圖譜自動(dòng)化構(gòu)建技術(shù)之后的一篇總結(jié)博客,筆者查閱了大量文獻(xiàn),并做了大量采用深度學(xué)習(xí)模型的實(shí)驗(yàn),但最終提交時(shí)效果最好的方法還是規(guī)則匹配。
文本中總結(jié)了筆者在最終提交時(shí)所使用的方案,以及在參加評(píng)測(cè)過(guò)程中所嘗試的各種實(shí)驗(yàn),另外還有評(píng)測(cè)結(jié)束后還沒(méi)有來(lái)得及實(shí)現(xiàn)的一些想法。
1. 評(píng)測(cè)任務(wù)介紹
1.1 介紹

金融研報(bào)是各類(lèi)金融研究結(jié)構(gòu)對(duì)宏觀(guān)經(jīng)濟(jì)、金融、行業(yè)、產(chǎn)業(yè)鏈以及公司的研究報(bào)告。報(bào)告通常是由專(zhuān)業(yè)人員撰寫(xiě),對(duì)宏觀(guān)、行業(yè)和公司的數(shù)據(jù)信息搜集全面、研究深入,質(zhì)量高,內(nèi)容可靠。報(bào)告內(nèi)容往往包含產(chǎn)業(yè)、經(jīng)濟(jì)、金融、政策、社會(huì)等多領(lǐng)域的數(shù)據(jù)與知識(shí),是構(gòu)建行業(yè)知識(shí)圖譜非常關(guān)鍵的數(shù)據(jù)來(lái)源。
另一方面,由于研報(bào)本身所容納的數(shù)據(jù)與知識(shí)涉及面廣泛,專(zhuān)業(yè)知識(shí)眾多,不同的研究結(jié)構(gòu)和專(zhuān)業(yè)認(rèn)識(shí)對(duì)相同的內(nèi)容的表達(dá)方式也會(huì)略有差異。這些特點(diǎn)導(dǎo)致了從研報(bào)自動(dòng)化構(gòu)建知識(shí)圖譜困難重重,解決這些問(wèn)題則能夠極大促進(jìn)自動(dòng)化構(gòu)建知識(shí)圖譜方面的技術(shù)進(jìn)步。
本評(píng)測(cè)任務(wù)參考TAC KBP中的Cold Start評(píng)測(cè)任務(wù)的方案,圍繞金融研報(bào)知識(shí)圖譜的自動(dòng)化圖譜構(gòu)建所展開(kāi)。評(píng)測(cè)從預(yù)定義圖譜模式(Schema)和少量的種子知識(shí)圖譜開(kāi)始,從非結(jié)構(gòu)化的文本數(shù)據(jù)中構(gòu)建知識(shí)圖譜。
其中圖譜模式包括 10 種實(shí)體類(lèi)型,如機(jī)構(gòu)、產(chǎn)品、業(yè)務(wù)、風(fēng)險(xiǎn)等;19 個(gè)實(shí)體間的關(guān)系,如(機(jī)構(gòu),生產(chǎn)銷(xiāo)售,產(chǎn)品)、(機(jī)構(gòu),投資,機(jī)構(gòu))等;以及若干實(shí)體類(lèi)型帶有屬性,如(機(jī)構(gòu),英文名)、(研報(bào),評(píng)級(jí))等。在給定圖譜模式和種子知識(shí)圖譜的條件下,評(píng)測(cè)內(nèi)容為自動(dòng)地從研報(bào)文本中抽取出符合圖譜模式的實(shí)體、關(guān)系和屬性值,實(shí)現(xiàn)金融知識(shí)圖譜的自動(dòng)化構(gòu)建。

1.2 其他相關(guān)信息
筆者GitHub代碼[1],最終排名為第五名 :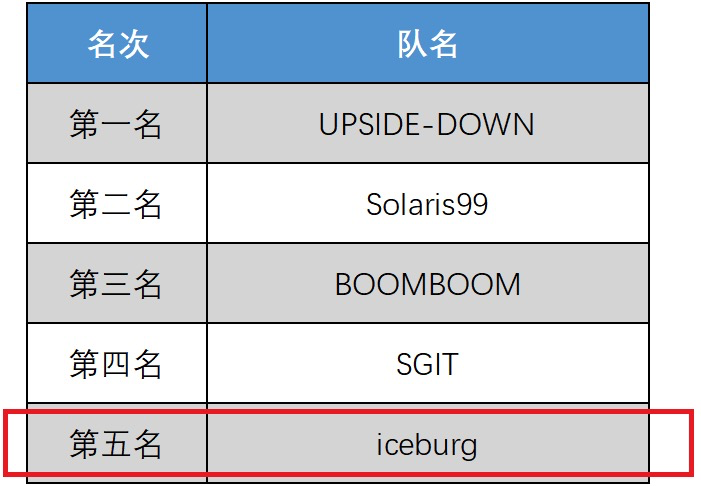
2.目前方案
由于評(píng)測(cè)包含的子任務(wù)比較多,有實(shí)體識(shí)別、關(guān)系抽取和屬性抽取;可使用的技術(shù)也非常多,有監(jiān)督,無(wú)監(jiān)督,半監(jiān)督等等;所以筆者在做評(píng)測(cè)的過(guò)程中嘗試了很多方法,但是大部分的模型都不如規(guī)則,所以筆者最終提交的方案中使用了大量規(guī)則匹配方法。
2.1 方案整體流程圖
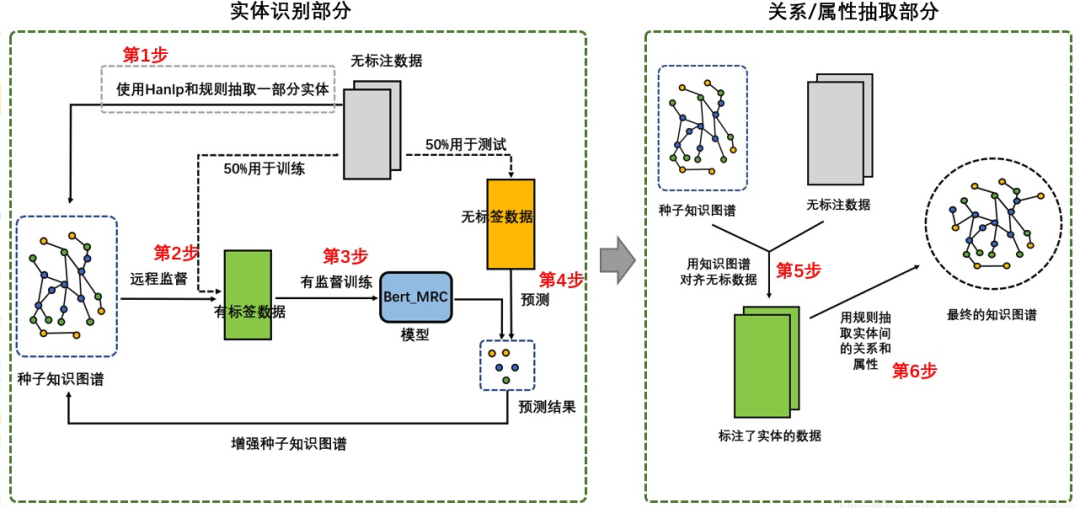 整體方案流程圖
整體方案流程圖整體結(jié)構(gòu)可以分為實(shí)體識(shí)別和關(guān)系、屬性抽取兩部分;流程可以分為6步,其中2、3和4步會(huì)重復(fù)執(zhí)行多次。
- 第1步:通過(guò)Hanlp和規(guī)則匹配的方式抽取部分實(shí)體;
- 第2步:采用遠(yuǎn)程監(jiān)督方法,用種子知識(shí)圖譜對(duì)齊無(wú)標(biāo)數(shù)據(jù)得到標(biāo)出了實(shí)體的數(shù)據(jù);
- 第3步:用上一步得到的標(biāo)出了實(shí)體的數(shù)據(jù)訓(xùn)練模型;
- 第4步:用上一步訓(xùn)練的實(shí)體識(shí)別模型抽取無(wú)標(biāo)數(shù)據(jù)中的實(shí)體,并將抽取出的實(shí)體加入到種子知識(shí)圖譜中,增加種子知識(shí)圖譜的規(guī)模,重復(fù)2,3,4步多次不斷使種子知識(shí)圖譜規(guī)則不斷擴(kuò)大;
- 第5步:通過(guò)重復(fù)2,3,4步多次后得到擴(kuò)展了大量實(shí)體的知識(shí)圖譜,用種子知識(shí)圖譜對(duì)齊無(wú)標(biāo)數(shù)據(jù),將無(wú)標(biāo)數(shù)據(jù)中的實(shí)體都找出來(lái);
- 第6步:通過(guò)上一步得到無(wú)標(biāo)數(shù)據(jù)中的實(shí)體后,使用規(guī)則的方法判斷實(shí)體間的關(guān)系和屬性。
2.2 實(shí)體抽取部分
1)外部工具
通過(guò)Hanlp實(shí)體識(shí)別工具,抽取“人物”和“機(jī)構(gòu)”兩種類(lèi)型的實(shí)體。Hanlp工具的實(shí)體識(shí)別模型是其他有標(biāo)語(yǔ)料上訓(xùn)練的,這里使用外部工具本質(zhì)上是使用了遷移學(xué)習(xí)方法。
2)規(guī)則
通過(guò)規(guī)則,抽取“研報(bào)“,“文章“,“風(fēng)險(xiǎn)“,“ 機(jī)構(gòu)“四種類(lèi)型的實(shí)體。
3)深度學(xué)習(xí)(遠(yuǎn)程監(jiān)督實(shí)體識(shí)別)
除了規(guī)則匹配外,還可以采用遠(yuǎn)程監(jiān)督的方法,主要用于抽取研報(bào)中的實(shí)體,具體流程如下圖所示:
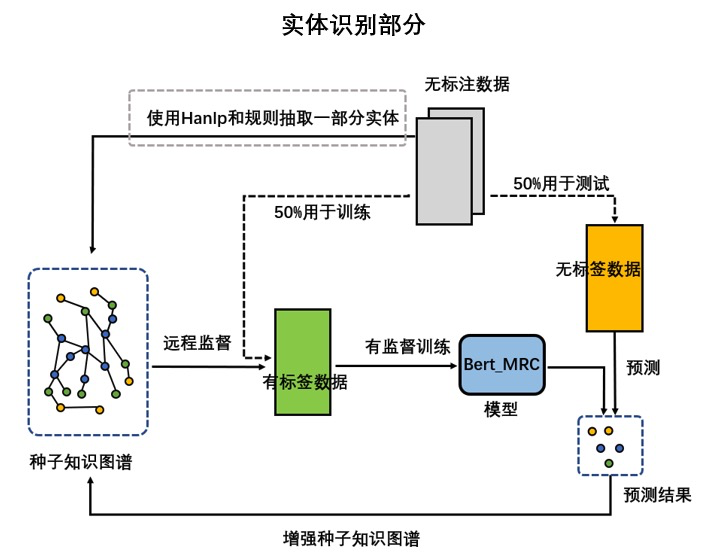 遠(yuǎn)程監(jiān)督實(shí)體識(shí)別
遠(yuǎn)程監(jiān)督實(shí)體識(shí)別- 使用規(guī)則和外部工具抽取一部分實(shí)體;
- 將原始數(shù)據(jù)平均分成兩半,一半用于訓(xùn)練,一半用于測(cè)試,對(duì)用于訓(xùn)練的一半數(shù)據(jù)使用遠(yuǎn)程監(jiān)督進(jìn)行標(biāo)注;
- 采用將遠(yuǎn)程監(jiān)督方法標(biāo)注的數(shù)據(jù)按4:1劃分,分別作為訓(xùn)練和驗(yàn)證集,訓(xùn)練模型;
- 使用上一步訓(xùn)練出的模型在測(cè)試集上進(jìn)行預(yù)測(cè),抽取出一部分實(shí)體;
- 通過(guò)規(guī)則匹配的方法篩選掉一些實(shí)體,剩下的實(shí)體加入種子知識(shí)圖譜,然后從第2步開(kāi)始,重復(fù)上一次訓(xùn)練,迭代進(jìn)行實(shí)體抽取。
2.3 關(guān)系抽取、屬性抽取部分
關(guān)系抽取和屬性抽取方法非常相似,可以使用同樣的方案來(lái)解決。
在做評(píng)測(cè)的過(guò)程中,考慮到?jīng)]有給出有標(biāo)注的關(guān)系抽取數(shù)據(jù)集,所以最初我計(jì)劃采用遠(yuǎn)程監(jiān)督關(guān)系抽取的相關(guān)方法,首先使用經(jīng)典的模型PCNN做了相關(guān)實(shí)驗(yàn),在實(shí)驗(yàn)過(guò)程中發(fā)現(xiàn)語(yǔ)料中有大量的關(guān)系需要通過(guò)跨句的抽取方法才能識(shí)別,所以又查看了文檔級(jí)關(guān)系抽取的相關(guān)方法。但是,目前文檔級(jí)關(guān)系抽取方法幾乎都使用有監(jiān)督訓(xùn)練,所以筆者最后對(duì)數(shù)據(jù)做了一些處理后,還是使用了PCNN+ATT模型。在進(jìn)行了相關(guān)實(shí)驗(yàn)后并與使用規(guī)則的方法做比較之后,筆者發(fā)現(xiàn)深度學(xué)習(xí)模型在對(duì)關(guān)系的準(zhǔn)確率上還是差的比較遠(yuǎn),所以在評(píng)測(cè)的最后階段還是采用的規(guī)則匹配方法。
3.相關(guān)實(shí)驗(yàn)
下面是在參加評(píng)測(cè)的過(guò)程中,筆者做的采用深度學(xué)習(xí)方法的一些實(shí)驗(yàn),筆者比較了各種方法的優(yōu)劣,選了幾種在評(píng)測(cè)給定的場(chǎng)景下較優(yōu)的方法,但是在最終的效果都不如采用規(guī)則匹配的方法。這里筆者把在評(píng)測(cè)中做的一些實(shí)驗(yàn),采用的一些模型做一個(gè)總結(jié)。
3.1 實(shí)體抽取部分
3.1.1 BERT-MRC模型
該評(píng)測(cè)的實(shí)體識(shí)別模型就采用的該方法,BERT-MRC模型是目前實(shí)體識(shí)別領(lǐng)域的SOTA模型(2020年),在數(shù)據(jù)量較小的情況下效果較其他模型要更好,原因是因?yàn)?strong>BERT-MRC模型可以通過(guò)問(wèn)題加入一些先驗(yàn)知識(shí),減小由于數(shù)據(jù)量太小帶來(lái)的問(wèn)題。在實(shí)際實(shí)驗(yàn)中,在數(shù)據(jù)量比較小的情況下,BERT-MRC模型的效果確實(shí)要較其他模型要更好些。BERT-MRC模型很適合用在本評(píng)測(cè)這種缺乏標(biāo)注數(shù)據(jù)的場(chǎng)景下。
(1)方法概述
-
任務(wù)定義:給定一個(gè)文本序列,它的長(zhǎng)度為,要抽取出其中的每個(gè)實(shí)體,其中實(shí)體都屬于一種實(shí)體類(lèi)型。
-
模型思想:假設(shè)該數(shù)據(jù)集的所有實(shí)體標(biāo)簽集合為,那么對(duì)其中的每個(gè)實(shí)體標(biāo)簽,比如地點(diǎn)“國(guó)家”,都有一個(gè)關(guān)于它的問(wèn)題。這個(gè)問(wèn)題可以是一個(gè)詞,也可以是一句話(huà)等等。使用上述MRC中片段抽取的思想,輸入文本序列和問(wèn)題,是需要抽取的實(shí)體,BERT_MRC通過(guò)建模來(lái)實(shí)現(xiàn)實(shí)體抽取。
-
提示信息(問(wèn)題構(gòu)造):對(duì)于問(wèn)題的構(gòu)造是建模的重要環(huán)節(jié)。BERT_MRC使用“標(biāo)注說(shuō)明”作為每個(gè)標(biāo)簽的問(wèn)題。所謂“標(biāo)注說(shuō)明”,是在構(gòu)造某個(gè)數(shù)據(jù)集的時(shí)候提供給標(biāo)注者的簡(jiǎn)短的標(biāo)注說(shuō)明。比如標(biāo)注者要去標(biāo)注標(biāo)簽為“國(guó)家”的所有實(shí)體,那么對(duì)應(yīng)“國(guó)家”的標(biāo)注說(shuō)明就是 “指擁有共同的語(yǔ)言、文化、種族、血統(tǒng)、領(lǐng)土、政府或者歷史的社會(huì)群體。
(2)模型輸入與模型損失
將問(wèn)題和語(yǔ)料中的句子合并成一句話(huà)作為輸入,問(wèn)題和語(yǔ)料句之間用BERT的句子級(jí)特殊符號(hào)“[SEP]”隔開(kāi),下圖中紅色框線(xiàn)框出的為問(wèn)題:
 輸入示例
輸入示例在用BERT編碼得到詞向量之后,訓(xùn)練三個(gè)分類(lèi)器,得到開(kāi)始、結(jié)束位置標(biāo)簽以及一個(gè)概率矩陣。上述兩個(gè)標(biāo)簽一個(gè)矩陣共可以求三個(gè)loss,模型的總loss是上述三個(gè)loss之和 :
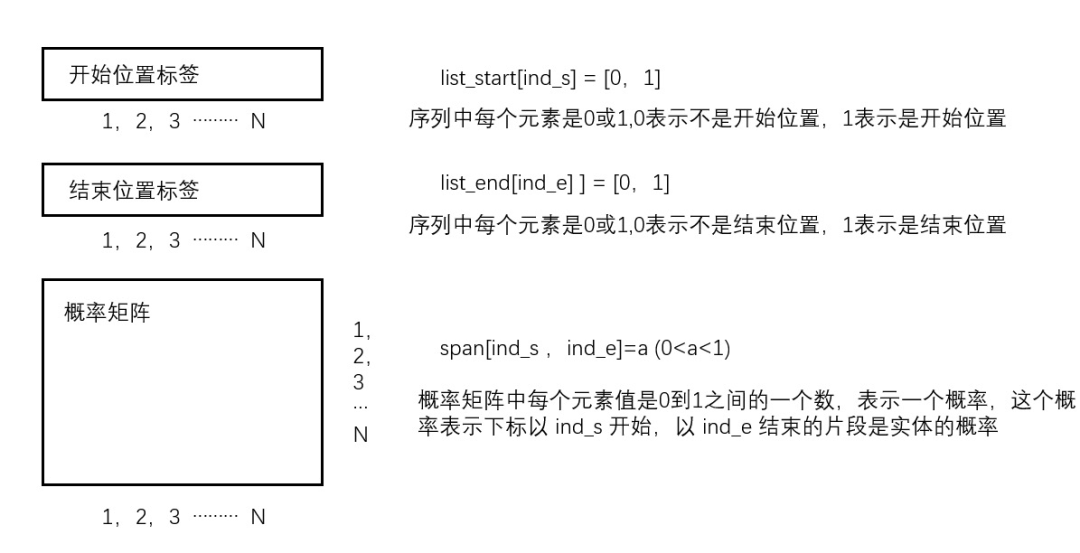 損失函數(shù)
損失函數(shù)3.1.2 BERT-CRF、LSTM-CRF模型
將實(shí)體識(shí)別看做一個(gè)序列標(biāo)注問(wèn)題,設(shè)計(jì)BIO和實(shí)體類(lèi)型的聯(lián)合標(biāo)簽,每個(gè)字符對(duì)應(yīng)一個(gè)標(biāo)簽。在訓(xùn)練時(shí),采用標(biāo)注了標(biāo)簽的字符序列作為語(yǔ)料訓(xùn)練模型,預(yù)測(cè)階段使用模型預(yù)測(cè)字符對(duì)應(yīng)的標(biāo)簽,然后通過(guò)標(biāo)簽得到實(shí)體的片段的具體位置以及實(shí)體片段的類(lèi)型。
命名實(shí)體識(shí)別經(jīng)典的baselineLSTM-CRF采用的就是這種方法,18年之后BERT代替了LSTM,b變成了一個(gè)重要的實(shí)體識(shí)別baseline。采用CRF的原因是CRF能對(duì)標(biāo)簽的轉(zhuǎn)移狀態(tài)建模,減小一些錯(cuò)誤的標(biāo)簽序列出現(xiàn)的概率,增加模型的準(zhǔn)確率。
 樣本示例
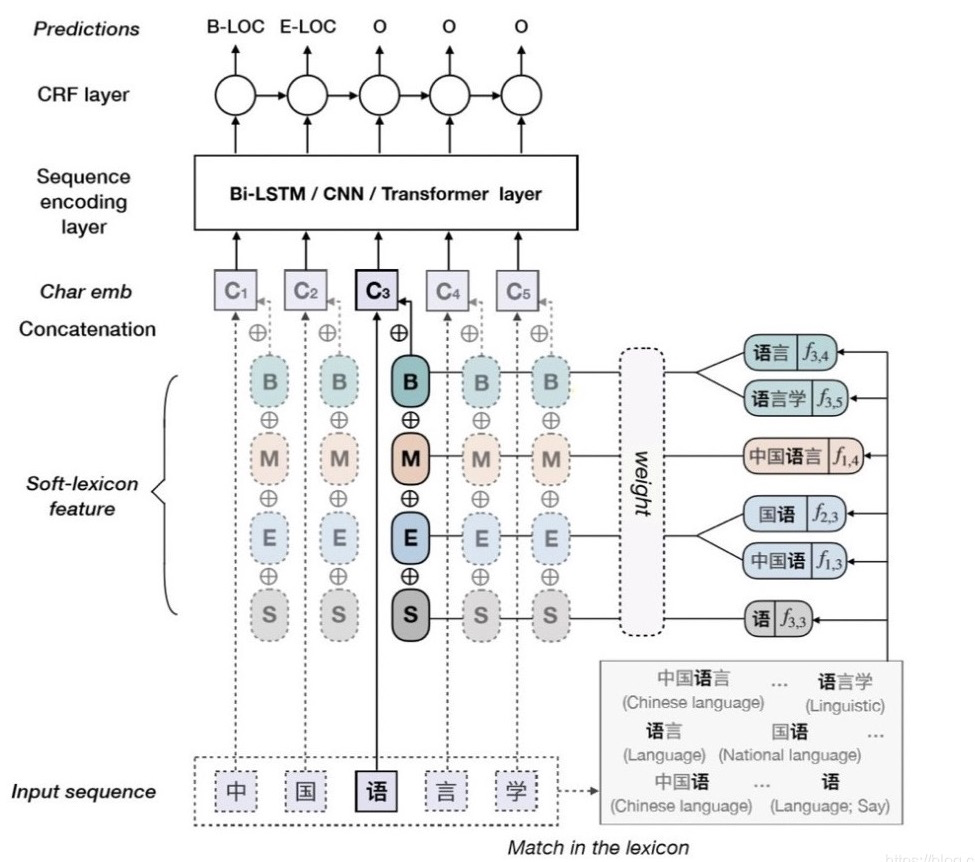
樣本示例3.1.3 Simple-Lexicon模型
以LatticeLSTM為代表的詞匯增強(qiáng)模型,其主要目的是解決中文分詞的問(wèn)題。實(shí)體識(shí)別任務(wù)經(jīng)常被轉(zhuǎn)換為一個(gè)序列標(biāo)注問(wèn)題,序列標(biāo)注問(wèn)題以字為單位,預(yù)測(cè)每個(gè)字對(duì)應(yīng)的標(biāo)簽,模型的輸入是以字序列作為輸入,而以字序列的形式進(jìn)行編碼和解碼,會(huì)忽略中文中重要的分詞信息。如何分詞在中文NLP任務(wù)中是非常重要的,會(huì)很大地影響模型的性能。
詞匯增強(qiáng)模型的目的就是為了解決以如何讓以字作為輸入的模型使用詞匯信息,在該評(píng)測(cè)中筆者只簡(jiǎn)單的做了一些和Simple-Lexicon模型相關(guān)的實(shí)驗(yàn)。筆者發(fā)現(xiàn)Simple-Lexicon模型并沒(méi)有比BERT-CRF模型的效果好很多,分析原因是由于任務(wù)的特殊性,影響遠(yuǎn)程監(jiān)督實(shí)體識(shí)別模型性能的比較重要的因素還是在于遠(yuǎn)程監(jiān)督和迭代增強(qiáng)帶來(lái)的錯(cuò)誤傳遞和召回率低等問(wèn)題,采用什么樣的實(shí)體識(shí)別模型對(duì)能否解決以上兩個(gè)問(wèn)題其實(shí)影響并不大。
3.2 關(guān)系抽取、屬性抽取部分
3.2.1 遠(yuǎn)程監(jiān)督關(guān)系抽取與多示例學(xué)習(xí)
遠(yuǎn)程監(jiān)督假設(shè)是指,假如兩個(gè)實(shí)體之間存在某種關(guān)系,那么所有這兩個(gè)實(shí)體共現(xiàn)的句子都有可能表達(dá)這種關(guān)系。這一假設(shè)過(guò)強(qiáng),有些兩個(gè)實(shí)體共現(xiàn)的句子并不能表達(dá)實(shí)體間的這種關(guān)系,例如下圖中的兩個(gè)句子,以及關(guān)系三元組 (“比爾蓋茨,創(chuàng)建者 , 微軟”)。
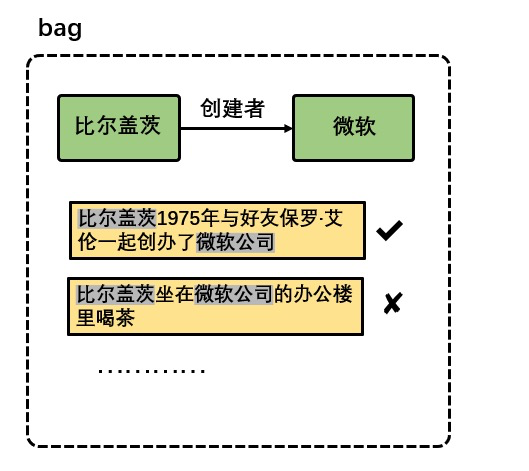 遠(yuǎn)程監(jiān)督與噪聲數(shù)據(jù)
遠(yuǎn)程監(jiān)督與噪聲數(shù)據(jù)上圖中的兩個(gè)句子有一個(gè)可以體現(xiàn)三元組表達(dá)的關(guān)系,另一個(gè)不能表達(dá)這種關(guān)系。這些不能表達(dá)兩個(gè)實(shí)體間關(guān)系信息的句子根據(jù)遠(yuǎn)程監(jiān)督假設(shè)也會(huì)被進(jìn)行標(biāo)注然后當(dāng)做訓(xùn)練語(yǔ)料,這些句子就是噪聲數(shù)據(jù),噪聲數(shù)據(jù)嚴(yán)重影響了遠(yuǎn)程監(jiān)督關(guān)系抽取模型的性能。
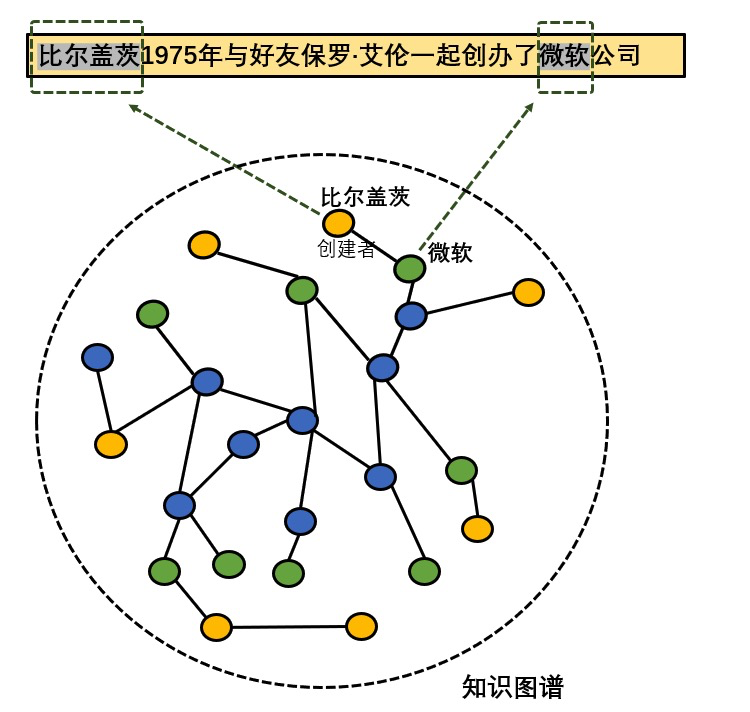
目前能夠有效地在使用遠(yuǎn)程監(jiān)督方式標(biāo)注的數(shù)據(jù)集上進(jìn)行關(guān)系抽取的模型,基本都采用了多示例學(xué)習(xí)的方法(小喵以前也在小組內(nèi)分享過(guò)這個(gè)方法)。多示例學(xué)習(xí)的具體做法是,將訓(xùn)練集劃分成多個(gè)具有分類(lèi)標(biāo)簽的多實(shí)例包(bag),每個(gè)包含有若干個(gè)實(shí)例(instance)。多示例學(xué)習(xí)通過(guò)對(duì)包中實(shí)例的學(xué)習(xí),訓(xùn)練出一個(gè)能夠?qū)ΠM(jìn)行分類(lèi)的分類(lèi)器,并將該分類(lèi)器應(yīng)用于對(duì)未知標(biāo)簽的多示例包的預(yù)測(cè)。
上圖就是一個(gè)多示例包,這個(gè)包的標(biāo)簽是“創(chuàng)建者”類(lèi)型,包中有兩個(gè)實(shí)例。其中第一個(gè)實(shí)例可以表達(dá)“創(chuàng)建者”這種關(guān)系,而第二個(gè)實(shí)例則無(wú)法體現(xiàn)這種關(guān)系,使用多示例學(xué)習(xí)方式訓(xùn)練的分類(lèi)器想要達(dá)到一定的性能,需要能夠很好地分辨出哪些實(shí)例是正實(shí)例(能夠體現(xiàn)包的標(biāo)簽的含義),哪些實(shí)例是負(fù)實(shí)例(不能體現(xiàn)包的標(biāo)簽的含義)。
3.2.2 PCNN-One模型、PCNN-ATT模型
在多示例學(xué)習(xí)的訓(xùn)練過(guò)程中,關(guān)于如何從包中選擇出正實(shí)例用于關(guān)系分類(lèi),主要有三種思想:
-
一種是基于“至少一個(gè)”假設(shè),即假設(shè)包中至少有一個(gè)句子實(shí)例可以代表實(shí)體對(duì)之間的關(guān)系,這時(shí)任務(wù)目標(biāo)就是訓(xùn)練一個(gè)分類(lèi)器,將包中最有可能代表實(shí)體間關(guān)系的句子作為輸入,對(duì)關(guān)系進(jìn)行分類(lèi)。這種思想就是PCNN-One模型采用的方法。
-
另一種方法基于注意力機(jī)制,使用一個(gè)能代表實(shí)體間關(guān)系的向量和包中的句子實(shí)例求相似度,得到一個(gè)權(quán)重參數(shù),對(duì)不同的實(shí)例分配以不同的權(quán)重再求和,通過(guò)注意力的方式減小噪聲數(shù)據(jù)的影響。這種思想是PCNN-ATT模型采用的方法。
-
還有一種是使用強(qiáng)化學(xué)習(xí)的方式,篩選出正實(shí)例進(jìn)行關(guān)系分類(lèi)。由筆者沒(méi)有接觸過(guò)強(qiáng)化學(xué)習(xí),所以沒(méi)有做采用強(qiáng)化學(xué)習(xí)方法去噪的相關(guān)實(shí)驗(yàn)。
在實(shí)驗(yàn)過(guò)程中遠(yuǎn)程監(jiān)督關(guān)系模型在其他的一些語(yǔ)料上表現(xiàn)還可以,但是在評(píng)測(cè)的數(shù)據(jù)集上效果很不理想,主要是因?yàn)樵u(píng)測(cè)語(yǔ)料數(shù)據(jù)是以金融研報(bào)文章為單位,和標(biāo)準(zhǔn)的遠(yuǎn)程監(jiān)督關(guān)系抽取語(yǔ)料(以句子為單位,需要分類(lèi)的兩個(gè)實(shí)體都會(huì)在句子中出現(xiàn))差別較大,所以筆者在最終提交時(shí)還是使用的規(guī)則匹配的方法,沒(méi)有使用PCNN-One模型和PCNN-ATT模型。
4.相關(guān)問(wèn)題
4.1 實(shí)體抽取部分
4.1.1 使用Snowball方法在迭代過(guò)程中產(chǎn)生錯(cuò)誤傳遞
使用迭代訓(xùn)練的方法,在一次訓(xùn)練過(guò)程中模型抽取出了錯(cuò)誤的實(shí)體片段,這個(gè)錯(cuò)誤的片段加入到種子知識(shí)圖譜去標(biāo)注語(yǔ)料會(huì)造成錯(cuò)誤傳遞,為了提高Snowball方法的抽取效果,需要設(shè)計(jì)過(guò)濾方法,將模型抽取出的實(shí)體經(jīng)過(guò)篩選后再加入進(jìn)種子知識(shí)圖譜中。
在做評(píng)測(cè)的過(guò)程中,筆者使用了規(guī)則的方法,觀(guān)察模型抽取的結(jié)果,然后設(shè)計(jì)規(guī)則,過(guò)濾錯(cuò)誤片段。這種方法不是很有效,因?yàn)槟P妥鲆恍┱{(diào)整后,抽取的結(jié)果就不同了,規(guī)則也需要做相應(yīng)的修改。而且錯(cuò)誤片段的種類(lèi)非常多,規(guī)則的方法很難全部覆蓋到。
4.1.2 遠(yuǎn)程監(jiān)督訓(xùn)練召回率低
如下圖所示,種子知識(shí)圖譜中有比爾蓋茨和微軟兩個(gè)實(shí)體,通過(guò)實(shí)體對(duì)齊之后,無(wú)標(biāo)數(shù)據(jù)中的比爾蓋茨和微軟兩個(gè)實(shí)體被標(biāo)注出來(lái),但是,由于知識(shí)圖譜的規(guī)模限制,實(shí)體 保羅·艾倫 不在知識(shí)圖譜中,通過(guò)遠(yuǎn)程監(jiān)督的方式不能將該實(shí)體標(biāo)注出來(lái)。
采用知識(shí)圖譜對(duì)齊的方式會(huì)出現(xiàn)大量的目標(biāo)實(shí)體未被標(biāo)注的情況,所以使用遠(yuǎn)程監(jiān)督標(biāo)注的數(shù)據(jù)集訓(xùn)練的模型召回率比較低。
Snowball方法理論上是解遠(yuǎn)程監(jiān)督實(shí)體識(shí)別召回率低的一個(gè)比較好的方案,但是實(shí)際實(shí)驗(yàn)結(jié)果卻不是非常好。筆者打算在未來(lái)的改進(jìn)方案中結(jié)合少量人工標(biāo)注的數(shù)據(jù),解決由于遠(yuǎn)程監(jiān)督造成的召回率低的問(wèn)題。
4.2 關(guān)系抽取、屬性抽取部分
由于語(yǔ)料的問(wèn)題,必須從句子級(jí)的關(guān)系抽取擴(kuò)展到文檔級(jí)別的關(guān)系抽取。
5.改進(jìn)方案
這部分內(nèi)容筆者正在嘗試突破的方向,也是筆者研究生畢設(shè)的內(nèi)容,現(xiàn)在已經(jīng)有一些想法但還不好直接寫(xiě)出來(lái),如果之后有一定的成果我再來(lái)完善。
5.1 實(shí)體抽取部分
在現(xiàn)有的方案上主要做兩點(diǎn)改進(jìn):
1)加入使用深度學(xué)習(xí)方法訓(xùn)練的實(shí)體判別器
2)使用遷移學(xué)習(xí)的方法,在訓(xùn)練過(guò)程中加入相關(guān)領(lǐng)域的人工標(biāo)注數(shù)據(jù)集,以及自己標(biāo)注的部分?jǐn)?shù)據(jù),解決遠(yuǎn)程監(jiān)督訓(xùn)練召回率低的問(wèn)題
5.2 關(guān)系抽取/屬性抽取部分
在現(xiàn)有的方案上主要做兩點(diǎn)改進(jìn):
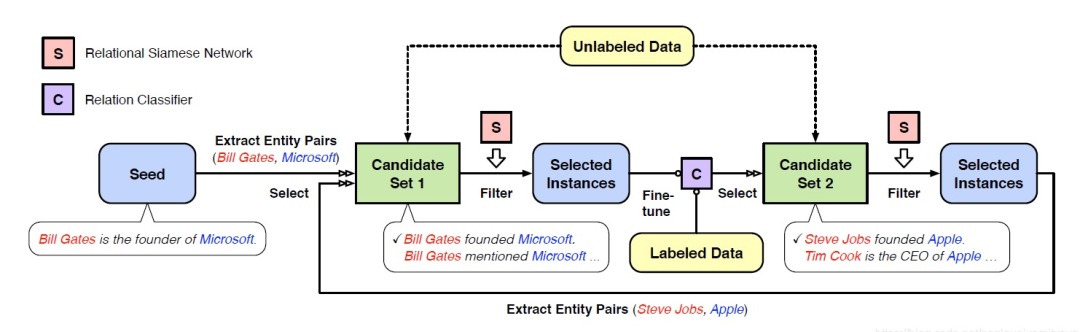
1)增加關(guān)系分類(lèi)器,解決遠(yuǎn)程監(jiān)督關(guān)系抽取的噪聲問(wèn)題
主要是參考AAAI2020年的一篇論文NeuralSnowball,增加一個(gè)像RSN關(guān)系分類(lèi)器的模塊,增強(qiáng)模型對(duì)噪聲數(shù)據(jù)的區(qū)分,同時(shí)用人工標(biāo)注一部分?jǐn)?shù)據(jù),使用其他領(lǐng)域大規(guī)模有標(biāo)數(shù)據(jù),少量人工標(biāo)注的任務(wù)數(shù)據(jù)和大量無(wú)標(biāo)注的任務(wù)數(shù)據(jù)做遷移學(xué)習(xí)。
2)使用文檔級(jí)關(guān)系抽取模型
審核編輯 :李倩
-
自動(dòng)化
+關(guān)注
關(guān)注
29文章
5620瀏覽量
79532 -
知識(shí)圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7725
原文標(biāo)題:5.改進(jìn)方案
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
三星自主研發(fā)知識(shí)圖譜技術(shù),強(qiáng)化Galaxy AI用戶(hù)體驗(yàn)與數(shù)據(jù)安全
三星電子將收購(gòu)英國(guó)知識(shí)圖譜技術(shù)初創(chuàng)企業(yè)
知識(shí)圖譜與大模型之間的關(guān)系
機(jī)械自動(dòng)化和電氣自動(dòng)化區(qū)別是什么
機(jī)械自動(dòng)化是自動(dòng)化的一種嗎
自動(dòng)化設(shè)備的伺服電機(jī)選型指南
工業(yè)自動(dòng)化包含哪些技術(shù)領(lǐng)域
機(jī)械制造與自動(dòng)化是自動(dòng)化類(lèi)嗎
工業(yè)自動(dòng)化和自動(dòng)化區(qū)別是什么
工業(yè)自動(dòng)化包含哪些技術(shù)
工業(yè)自動(dòng)化控制技術(shù)原理是什么
機(jī)器視覺(jué)檢測(cè)技術(shù)在工業(yè)自動(dòng)化中的應(yīng)用
IPv6 在電力自動(dòng)化系統(tǒng)中的應(yīng)用

利用知識(shí)圖譜與Llama-Index技術(shù)構(gòu)建大模型驅(qū)動(dòng)的RAG系統(tǒng)(下)

自動(dòng)化構(gòu)建環(huán)境在FPGA設(shè)計(jì)中的應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論