 Arm Neoverse生態及性能優勢和遷移建議
Arm Neoverse生態及性能優勢和遷移建議
簡介:Arm Neoverse生態及性能優勢和遷移建議
2022年11月5日,“倚天開啟云原生算力新時代”專場在杭州·云棲大會D館云棲科創SHOW場舉行,安謀科技(Arm China)高級軟件經理別再平帶來了題為《Neoverse生態與軟件遷移》的主題分享,詳細的介紹了Arm Neoverse生態及性能優勢和遷移建議,本文根據該演講整理而成。
01 Arm完善、豐富的生態成為國內外多家云廠商首選
在Arm的生態系統中包含CPU架構、CPU微架構,芯片實現三個概念,CPU架構定義了用戶對CPU核心的期望行為,包括寄存器、內存模型,異常模型等等,而CPU微架構則是一個CPU核心的具體實現,芯片則是芯片廠商在CPU核心的基礎上配合各種加速器和總線互聯最終實現。

同一個CPU架構可以有不同的微架構實現,例如上圖右側中的例子:Arm的Cortex A710和Arm的Neoverse N2兩款CPU核心,都是基于Armv9.0架構實現,同一款軟件也同樣可以在兩款CPU上運行。

上圖中展示的是Arm的CPU架構演進,Arm自2011年推出基于64位的Armv8架構以來,保持著逐代演進的節奏,根據市場和客戶的需求,不斷地在安全、性能、功能等方面加入不同的CPU特性,不同的CPU特性會組合成為一個CPU擴展,也就是一個小(新)版本。Arm的CPU版本是逐年演進且向前兼容的,像Neoverse N2是基于Armv9的架構,它可以同時兼容前代架構的所有特性,系統軟件等也可以通過查詢系統寄存器了解當前硬件所實現的具體CPU架構特性。
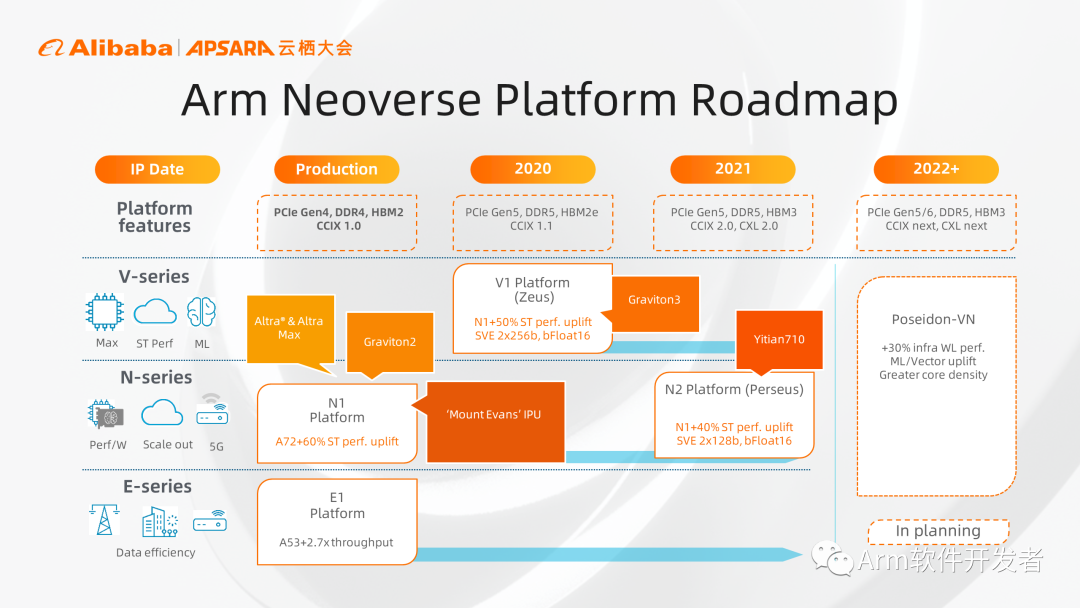
2018年Arm戰略性地將服務器芯片設計和傳統客戶端芯片設計分離,推出了Arm Neoverse產品線,縱向看Arm Neoverse平臺有三個系列產品,V系列、N系列和E系列。V系列強調性能,可提供最高單核處理能力,主要用于HPC和數據中心云應用等;N系列更注重性能、功耗和面積的平衡,具備最高的可擴展性,主要適用于數據中心、云計算應用;E系列更注重功耗和面積,主要應用于無線接入等功耗受限的領域。
橫向看Neoverse平臺近幾年推出的CPU產品,N1平臺是第一代聚焦基礎設施的CPU實現,目前已經獲得廣泛應用。在服務器領域,基于N1的產品有AWS和Ampere的服務器芯片,DPU領域有英特爾基于Neoverse N1的DPU實現。第二代是V1,屬V系列產品,更注重單核性能,新增2×256的SVE加速引擎,AWS的Graviton 3是基于V1來實現的,并且已經于今年5月份正式商用。
N2是第一個支持Armv9架構的CPU核心,支持2×128的SVE引擎,倚天710芯片也是基于N2平臺實現的。
Poseidon平臺基于Armv9.2架構,在N2的基礎上性能再提高30%,且增加了CCA架構特性,支持機密計算。

上圖展示的是Arm Neoverse平臺推出以來,在最近兩年時間里取得的一些成就。可以看到在云上,AWS、微軟、谷歌、阿里云等都推出了基于Arm Neoverse的云實例。在智能網卡領域,Marvell推出了基于Neoverse的智能網卡,谷歌云和英特爾聯合推出了“Mt Evans”DPU。在企業領域,惠普發布了基于Ampere的ProLiant Gen11平臺,也代表Arm正進入傳統的企業領域。同時在規范方面,Arm推出了System Ready認證項目,針對Arm系統的軟硬件進行測試認證,確保最終Arm的系統可以開箱即用和安裝多樣的操作系統,過去兩年已經有五十多個系統獲得System Ready認證。

聚焦云計算領域,從上圖中可以看到Arm Neoverse系統已經被部署在公有云、私有云,混合云等方方面面,且已經被國內外主流云計算廠商所采用,比如阿里云、騰訊云、AWS、微軟、谷歌等。

在云原生的軟件生態方面,Arm持續致力于開源軟件開發和支持。目前Arm對超過100個開源項目進行投入,可以看到(上圖)自下而上從網絡、OS、虛擬化、容器,編程語言以及各種上層應用負載,Arm都有很完善的支持。對底層網絡側的DPDK、OVS、ODP均可支持。在語言層面,OpenJDK、GoLang等也都可以在Arm平臺上直接運行,包括壓縮方面的主流計算庫,Arm也可以很好的支持。
頂部(上圖)列出了一些主流的云負載應用,有常見的一些數據庫、緩存、Web服務器、大數據、存儲等。左側(上圖)中可以看到Arm在CI/CD領域也有很大的投入,GitLab、Github Actions、Travis等都原生支持Arm系統,方便開發者在Arm系統上進行開發構建。

在操作系統領域,從主流的發行版OS到社區版OS,Arm都已經是所謂的”第一等公民“,Red Hat Enterprise Linux、CentOS、SUSE、龍蜥社區等對Arm系統都有原生支持。

在編譯器領域,在GCC和LLVM,Arm和生態伙伴一起合作,持續投入,確保在Silicon硬件系統面世以前,相應的架構特性和微架構實現就在編譯器中獲得支持。隨著編譯器版本的更新,Arm會逐步支持相應架構特性,以及相應微架構實現,保證客戶用最簡便的編譯方法獲得最優化的運行性能。
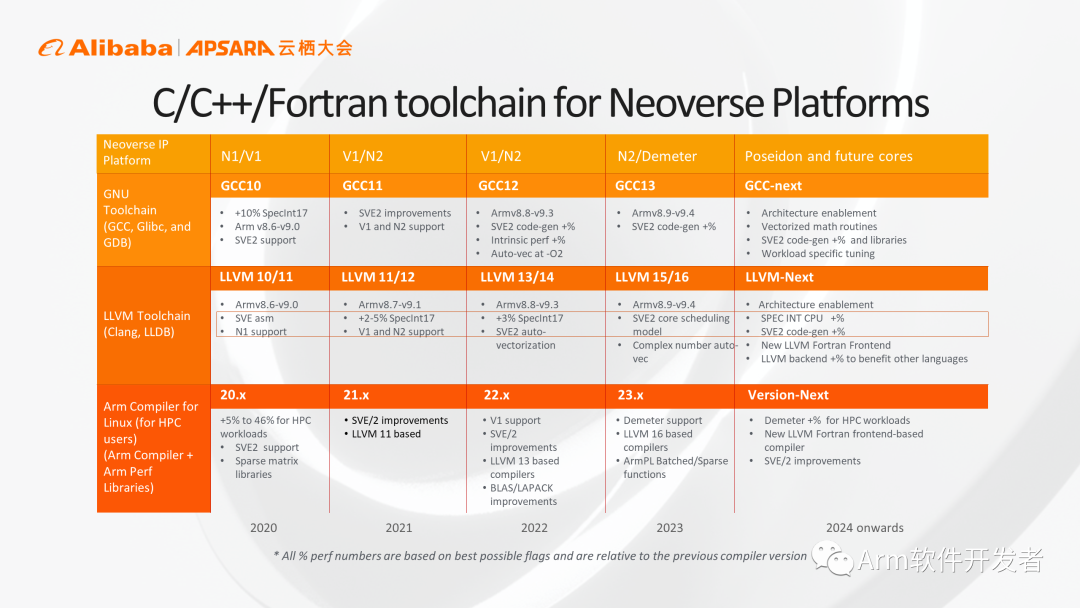
從另一角度可以看到,Arm會把自己的IP路線圖和編譯器路線圖相配合,例如在2024年之后,相應的編譯器就會支持Poseidon,我們會在Poseidon平臺落地前,就把相應的功能支持加入到編譯器當中,保證最終用戶拿到硬件之后可以第一時間用現有的編譯器獲得最好的性能。
02 多兼容,可擴展,Arm多業務場景性能大幅提升
下圖中列了Neoverse平臺的N1、N2兩款CPU核心以及Cortex A72的性能對比及架構特性的增強。Arm Neoverse N1這款CPU核心,對比Cortex A72有60%的性能提升,同時降低了30%的功耗。Arm Neoverse N1加入了很多服務器領域的架構特性,例如獨立的L2 Cache,支持原子操作,同時也支持基本的RAS特性。

接下來的Neoverse N2 CPU核心,在N1基礎上提升了35%的性能,且保持了同樣的功耗,使得N2有了非常好的可擴展性,同時N2也是第一款支持Armv9架構的CPU實現,尤其指出N2實現了MPAM架構特性,類似于傳統x86的RDT,可以把內存及cache進行隔離劃分,可以避免系統抖動及云環境下多租戶之間的相互影響。
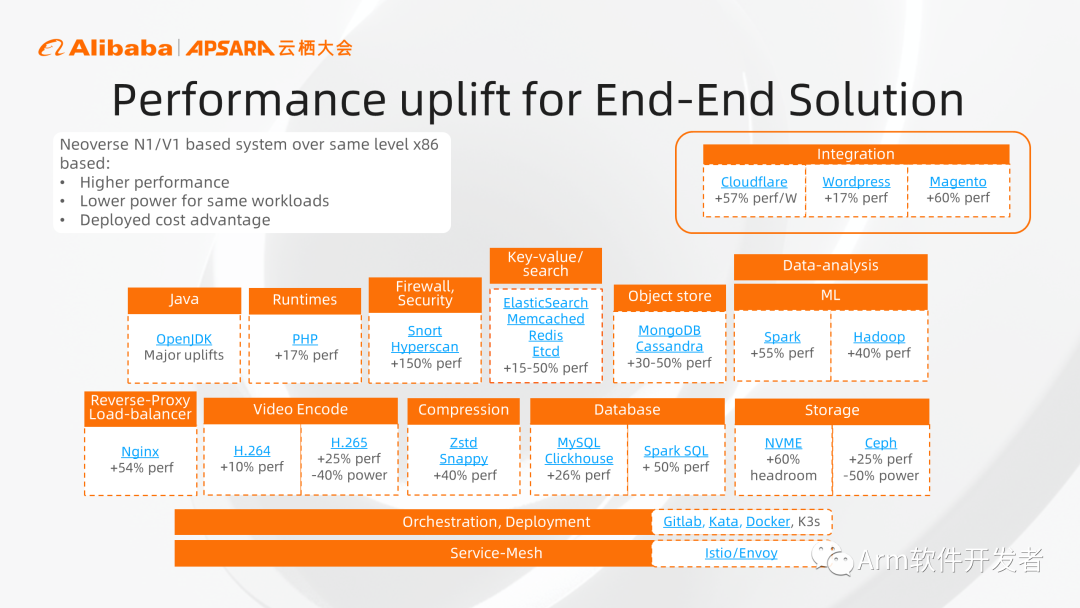
使用基于Arm Neoverse平臺的服務器,可以獲得更高的性能,更低的功耗,以及最終帶來更低的部署成本。給大家列一個端到端的例子,上圖中包含網絡服務的端到端的解決方案,可以看到從整個解決方案中的各種軟件,Arm都有相應的性能提升,比較熟悉的包括前端的web服務、反向代理、防火墻,后端的數據庫、緩存,以及業務處理的Java、視頻編解碼等,Arm系統相對于同代的x86系統,都有20%以上的性能優勢。
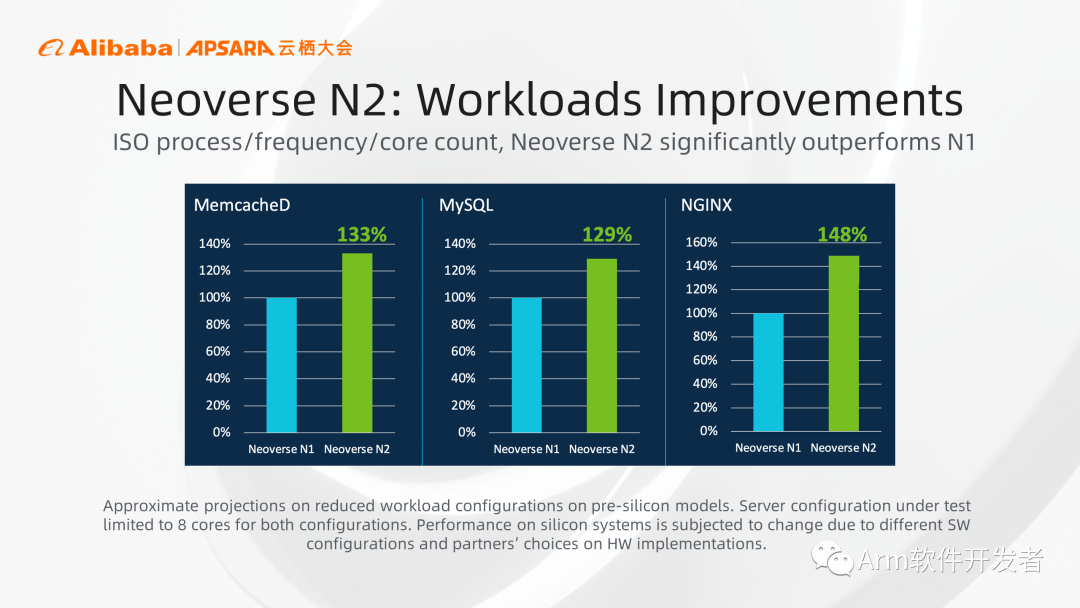
相對于第一代N1來說,N2在各種應用負載上均有大幅的性能提升,在MemcacheD、MySQL、NGINX上分別有30%、29%、48%的性能提升。
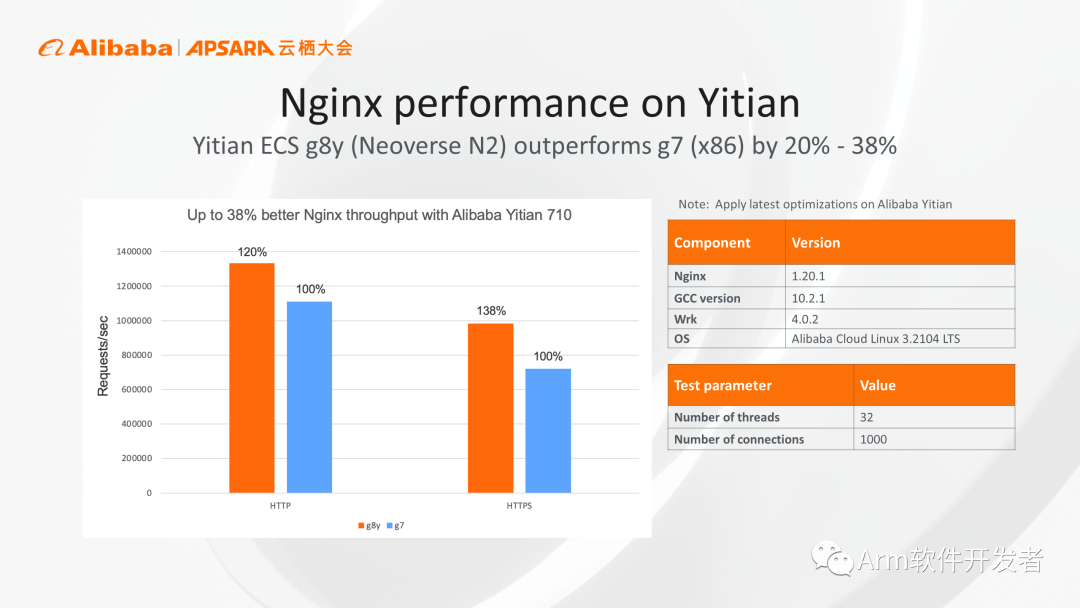
上圖中為大家展示的是我們基于Neoverse N2的倚天G8y實例,和傳統x86實例的實測對比結果,我們對Web服務器場景進行測試,使用默認的編譯器及軟件版本,最終測試得到的結果顯示,對于HTTP場景下,G8y實例相對于x86實例有20%的性能優勢。如果再考慮加密層面,針對HTTPS進行測試會有38%的性能優勢。倚天G8y實例將于11月15號正式商用,相應的測試參數都在上圖中列了出來,大家可以參考進行對比測試。
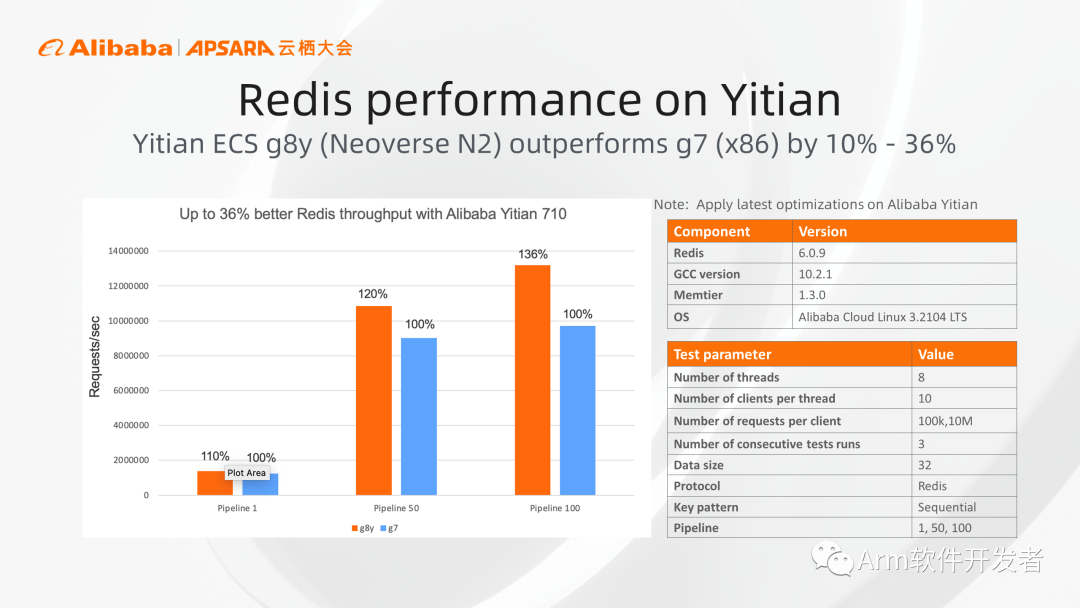
同時我們也進行了內存數據庫Redis的測試,在pipeline參數分別設置為1、50、100的情況下,基于倚天710芯片的g8y實例相對于x86實例分別有10%、20%,36%的性能收益。其中整個軟件都是直接用現有的開源軟件項目直接下載并直接編譯安裝,無需經過任何手動優化即可獲得圖中的結果。
03 有效操作優化保障代碼安全,實現性能提升
在上文中我們已經看到,Arm本身有很完善的軟件生態,尤其在云原生領域,用戶在使用的時候,基本無需進行特殊代碼改動,接近于開箱即用的場景,我這邊給到大家的遷移建議主要是針對一些自研非開源的軟件,尤其是大家之前的軟件中使用了一些針對x86系統的手動優化,在這些場景下,主要是在SIMD并發處理和內存訪問優化方面給大家提一些建議。

首先是SIMD單指令多數據的優化,通過使用這種技術,我們可以在一條指令中同時執行多個操作,提高操作并行度,進而最終提高IPC。Arm架構主要包含兩個架構擴展,Neon和SVE,特別適合用在一些數據量比較大的處理場景,起到加速作用,例如視頻編解碼、圖形圖像處理、音頻語音處理、壓縮與解壓縮,以及一些網絡的處理等等。
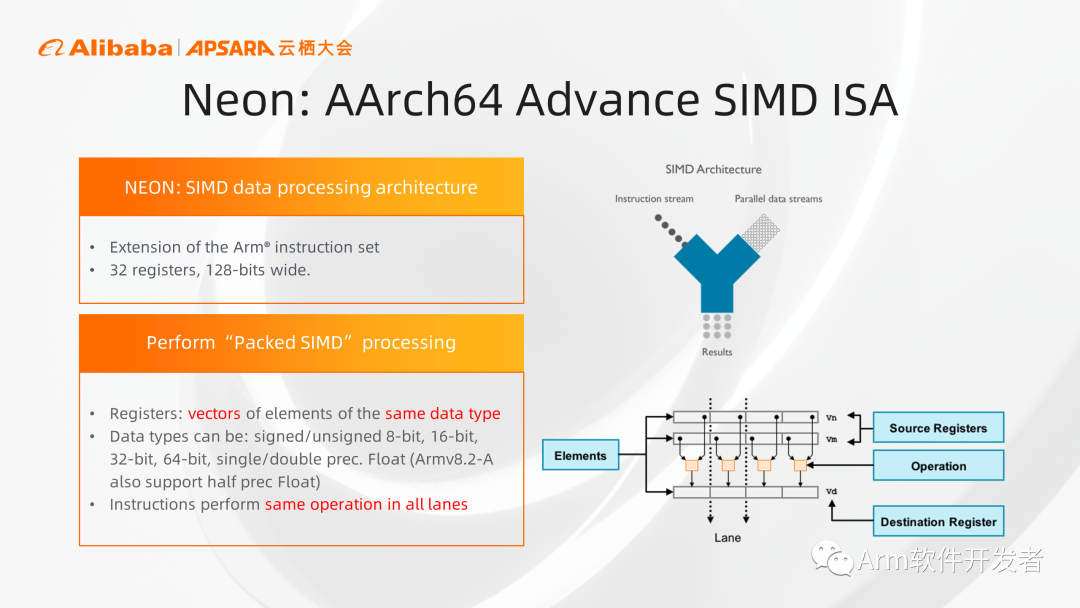
首先來看Neon,我們可以把一個128比特的寄存器,當做是幾個元素的集合,元素的大小可以是8、16、32、64位,元素可以被當作整數或者浮點數進行處理,但是要保證這里面的每個元素和數據類型是相同的,對應的元素會組成一個通道,當我們執行一條Neon指令的時候,就可以同時處理多個數據元素,提高效率。
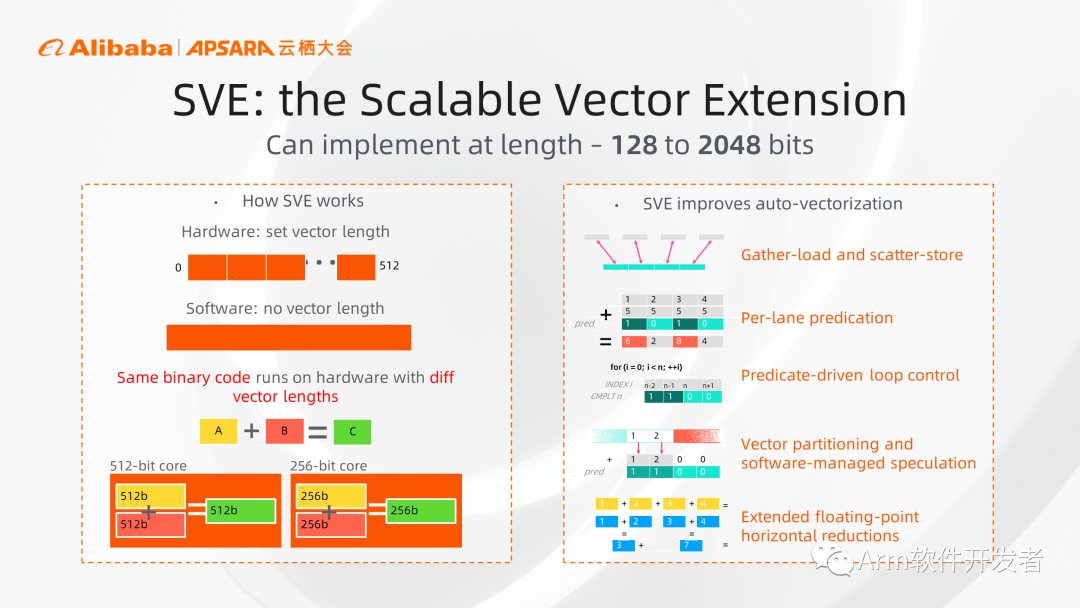
再看SVE架構擴展,其功能和Neon類似,但SVE相比Neon主要有兩個方面的優勢:
1、從架構角度看,Neon寄存器寬度固定為128比特,限制了它的擴展。SVE在架構上允許從128一直到2048比特的位寬,只要是128比特的整數倍就可以,給了設計者更大的靈活度。
2、從軟件角度看,SVE在軟件上不需要關心Vector具體的寬度,開發人員只需要寫一套代碼,就可以運行在不同硬件上。

關于使用Neon和SVE加速,最常用的方式是通過傳入一些編譯選項,或者編譯器識別當前CPU類型去自動應用Neon和SEV加速。但如果大家發現了一些熱點想要手動進行優化的時候,建議直接用intrinsics方式,相對于匯編代碼,代碼邏輯更清晰且更容易編寫,同時也便于編譯器進一步進行性能優化。

關于性能優化的例子:Arm在SPDK當中應用Neon對算法進行優化,無論編碼還是解碼,基本上都有大約2倍的性能提升,在SPDK內存清零操作中,使用SVE加速獲得了8倍的性能提升。右側(上圖)是代碼的示例,通過代碼示例,在右下角也可以看到,這套代碼沒有具體vector寬度的指定,不管最終SVE硬件的寬度是128還是256, 都可以直接運行。另外也可以看到這個SVE版本的循環沒有針對尾循環的特殊處理,因為SVE擴展配合特殊的循環指令以及相應的掩碼預測寄存器,可以自動處理尾循環。
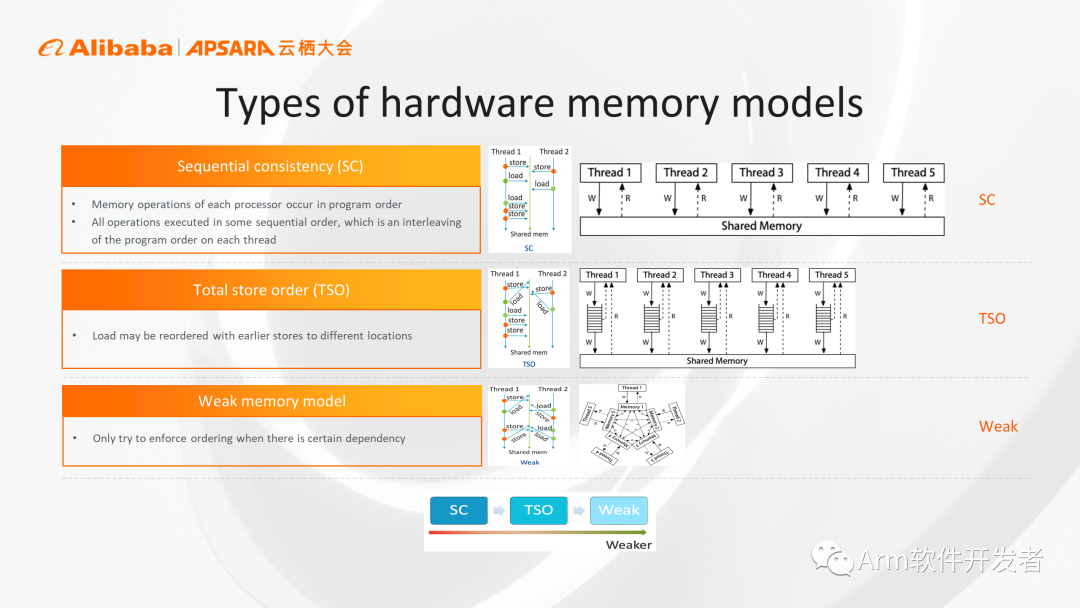
Arm和傳統x86 CPU之間一個很顯著的區別是它們的內存模型(memory model)。大家最直觀的內存序是順序內存序(SC),這種情況下所有的內存操作都不會亂序,好處是容易理解,但對于CPU的實現限制太嚴,會嚴重影響CPU性能。目前比較多的是x86采用的TSO模型,相對于第一種SC,解除了一些限制,允許存儲和加載這兩個操作亂序。
Arm架構則采用了一種限制更少的memory model,這種模型下所有的內存加載和存儲操作都可以進行亂序,這樣給了微架構設計者最大的自主權,可以帶來更高的性能。
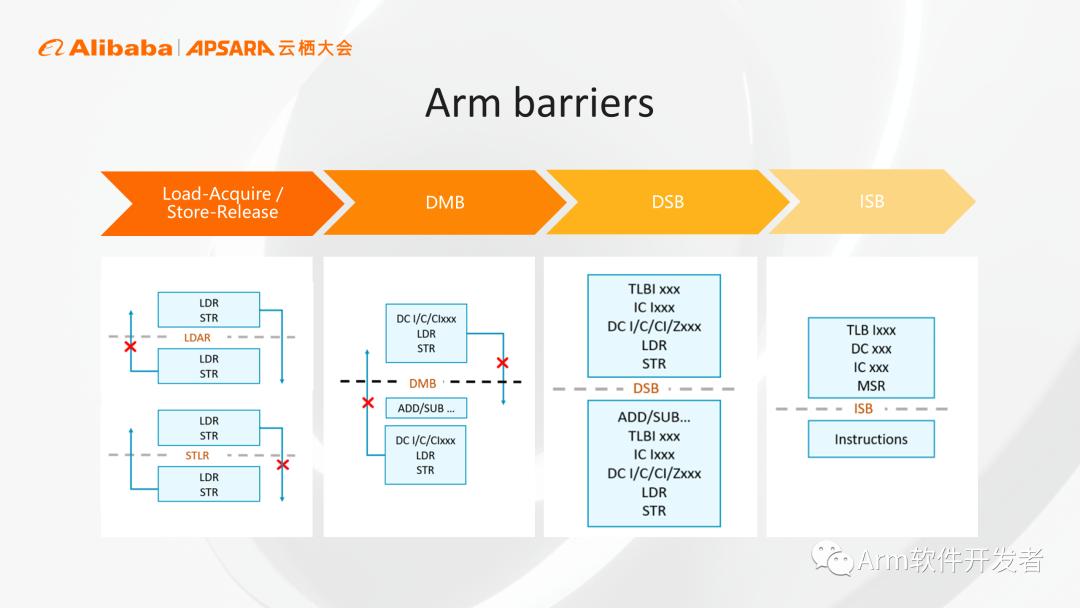
Arm為了提高性能允許各種內存操作進行亂序,當我們需要按照一種固定的順序執行時,Arm提供了各種內存柵欄來保證內存訪問的順序,幫助大家來保證代碼正確性。從左到右(上圖)分別是Load-Acquire / Store-Release半柵欄、DMB全柵欄、DSB、ISB,屏障的限制越來越強,對性能的影響也越來越大,在保障正確性的前提下,盡量選擇比較弱的柵欄,做到恰到好處地實現正確性和性能的平衡。
我們的建議是寫代碼時,先選擇比較強的柵欄,保證代碼的正確性,后續進行代碼評測優化的過程中如果發現成為瓶頸的話,再選用一些比較弱的柵欄進行優化。

上圖是Arm對DPDK Virtio應用進行優化的例子,包含前端后端,通過一個隊列進行通信,相當于一個生產者一個消費者。這里最初使用的是全柵欄,后續在性能測試時發現是一個瓶頸,做優化時把相應的全柵欄DMB換成了半柵欄后,在PVP測試場景下獲得了20%的性能提升,只要改動這一處即可達到性能提升的效果。

這里說明一下,Arm memory model是一種硬件定義的內存模型,對于大多數情況,我們并不建議大家直接操作依賴于具體架構的匯編代碼,一種更推薦的方式是借助于語言定義的memory model,例如我們可以使用C++11或者C11的memory model,調用其API,這樣工具鏈會處理語言的memory model并自動映射到最終硬件架構的memory model,這樣的操作方便移植且不容易出錯。
最后再次強調,與內存序相關的編程非常復雜,memory model是非常容易出問題的點,我們必須仔細權衡其正確性和性能。為了代碼的安全,建議大家在開發初期可以使用一些較強的屏障指令保證邏輯正確,在后續的代碼優化過程當中,通過移除一些冗余屏障或在必要時切換到較輕的屏障,最終達到提高性能的目的。
以上就是我要分享的全部內容,謝謝大家。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10901瀏覽量
212646 -
遷移
+關注
關注
0文章
33瀏覽量
7943 -
生態系統
+關注
關注
0文章
703瀏覽量
20763
原文標題:安謀科技(Arm China)高級軟件經理別再平:Neoverse生態與軟件遷移
文章出處:【微信號:Arm軟件開發者,微信公眾號:Arm軟件開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Arm Neoverse如何加速實現AI數據中心
淺析RISC-V領先ARM的優勢
MediaTek加入Arm全面設計生態項目 塑造AI計算的未來

ARM進軍汽車芯片市場,推出Neoverse設計
Arm新Arm Neoverse計算子系統(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N3

Google Cloud推出基于Arm Neoverse V2定制Google Axion處理器
Arm Neoverse CSS V3 助力云計算實現 TCO 優化的機密計算
Arm Neoverse CSS N3 助力快速實現出色能效
Arm首次面向汽車應用發布Neoverse級芯片設計
Neoverse CSS V3助力云計算實現TCO優化的機密計算

Arm Neoverse CSS N3助力快速實現出色能效

Arm發布Neoverse V3和N3 CPU內核
Arm發布新一代Neoverse數據中心計算平臺,AI負載性能顯著提升
FunASR語音大模型在Arm Neoverse平臺上的優化實踐流程





 工商網監
工商網監
評論