 詳細介紹一些CNN模型的設計理論和關鍵設計點
詳細介紹一些CNN模型的設計理論和關鍵設計點

卷積神經網絡設計史上的主要里程碑:模塊化、多路徑、因式分解、壓縮、可擴展
一般來說,分類問題是計算機視覺模型的基礎,它可以延申解決更復雜的視覺問題,例如:目標檢測的任務包括檢測邊界框并對其中的對象進行分類。而分割的任務則是對圖像中的每個像素進行分類。
卷積神經網絡(CNNs)首次被用于解決圖像分類問題,并且取得了很好的效果,所以在這個問題上,研究人員開始展開競爭。通過對ImageNet Challenge中更精確分類器的快速跟蹤研究,他們解決了與大容量神經網絡的統計學習相關的更普遍的問題,導致了深度學習的重大進展。
在本文中我們將整理一些經典的CNN模型,詳細介紹這些模型的設計理論和關鍵設計點:
VGGNet
我們介紹的第一個CNN,命名是為VGGNet[2]。它是AlexNet[3]的直接繼承者,AlexNet[3]被認為是第一個“深度”神經網絡,這兩個網絡有一個共同的祖先,那就是Lecun的LeNet[4]。
我們從它開始,盡管它的年代久遠,但是由于VGGNet的特殊性,,直到今天仍然站得住腳(這是極少數的DL模型能夠做到的)。第一個介紹VGGNet還有一個原因是它還建立了后續cnn所采用的通用組件和結構。
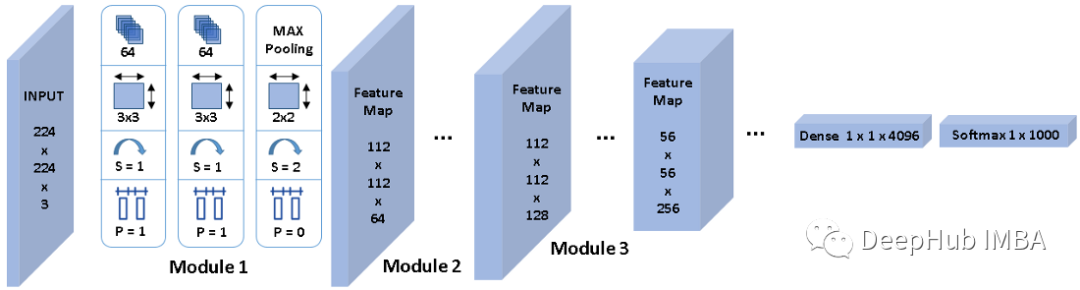
如上圖1所示,卷積神經網絡從一個輸入層開始,它與輸入圖像具有相同的尺寸,224x224x3。
然后,VGGNet堆疊第一個卷積層(CL 1),其中包括64個大小為3x3的核,輸出一個224x224x64的張量。
接下來,它在具有相同配置的64個通道上堆疊使用相同大小的3x3核的CL 2,生成相同尺寸的特征映射。
然后,使用filter size為2x2、填充和步幅為2的最大池化來降低特征映射的空間分辨率,從224x224x64降低到112x112x64。最大池并不影響特性映射深度,因此通道的數量仍然是64。
這里我將這三層之上稱作module 1,一般情況下也被稱作stem,可以理解為它提取的是最基本的線條特征。我們將其稱為module 被是因為它定義為以一定分辨率操作的處理單元。所以我們可以說VGGNet的module 1以224x224分辨率工作,并生成分辨率為112x112的特征圖,后面的module 2繼續在其上工作。
類似地,module 2也有兩個帶有3x3核的CLs,用于提取更高級別的特征,其次是最大池化,將空間分辨率減半,但核的數量乘以2,使輸出特征映射的通道數量翻倍。
每個module 處理輸入特征映射,將通道加倍,將空間分辨率除以2,以此類推。但是不可能一直這樣做,因為module 6的空間分辨率已經是7x7了。
因此,VGGNet包括一個從3D到1D的展平(flatten)操作,然后應用一個或兩個稠密層,最后使用softmax計算分類概率(這里是1000個標簽)。
讓我們總結一下VGGNet引入的設計模式,以在準確性方面超越所有以前的研究:
模塊化架構允許卷積層內的對稱性和同質性。通過構建具有相似特征的卷積層塊,并在模塊之間執行下采樣有助于在特征提取階段保留有價值的信息,使用小核,兩個 3x3 核的卷積的感知范圍可以等效于單個 5x5 的感知范圍。級聯的小核卷積也增強了非線性,并且可以獲得比具有一層更大核的更好的精度。小核還可加快 Nvidia GPU 上的計算速度。
與平均池化或跨步卷積(步幅大于 1)相比,最大池化操作是一種有效的下采樣方法。最大池化允許捕獲具有空間信息的數據中的不變性。因為圖像分類任務需要這種空間信息減少才能達到類別分數的輸出,而且它也被“流形假設”證明是合理的。在計算機視覺中,流形假設指出 224x224x3 維度空間中的真實圖像表示非常有限的子空間。
將整體下采樣與整個架構中通道數量的增加相結合形成金字塔形結構。通道的倍增補償了由于學習到的特征圖的空間分辨率不斷降低而導致的表征表達能力的損失。在整個層中,特征空間會同步變窄和變深,直到它準備好被展平并作為輸入向量發送到全連接層。每個特征都可以看作一個對象,其存在將在整個推理計算過程中被量化。早期的卷積層捕獲基本形狀,因此需要的對象更少。后面的層將這些形狀組合起來,創建具有多種組合的更復雜的對象,所以需要大量的通道來保存它們。
Inception
接下來介紹與VGGNet[2]同年出現但晚一點的第二個CNN,Inception[5]。這個名字的靈感來自克里斯托弗諾蘭的著名電影,這個網絡引發了關于“尋求更深層次的 CNN”的爭論,并很快變成了一個問題。事實上,深度學習研究人員意識到,如果能正確訓練更深層次的神經網絡,那么獲得的準確性就越高,尤其是在涉及 ImageNet 等復雜分類任務時。簡而言之,更多的堆疊層提高了神經網絡的學習能力,使其能夠捕捉復雜的模式并并能在復雜的數據中進行泛化。
但是設法訓練更深的網絡是非常困難的。堆疊更多層會產生成本,并使訓練神經網絡變得更加困難。這是由于梯度消失問題,當損失梯度通過無數計算層反向傳播,并逐漸收斂到幾乎為零的微小的值時,就會發生這種情況。因此訓練網絡的早期層(距離輸入近的層)變得很復雜,這些層無法執行特征提取并將提取的信息傳遞給后續層。
在Inception中,研究人員在一個深度級別上模擬了幾個層。這樣既增強了神經網絡的學習能力,又擴大了神經網絡的參數空間,避免了梯度的消失。

上圖 2 是這個多尺度處理層的內部視圖結構。關注藍色
審核編輯:劉清
-
cnn
+關注
關注
3文章
353瀏覽量
22285 -
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11892
發布評論請先 登錄
相關推薦
PID設計理論
一文詳解CNN
SNMP常用的一些OID詳細例表說明
變壓器的設計理論資料免費下載






 工商網監
工商網監
評論