 SpringBoot利用ThreadPoolTaskExecutor批量插入百萬級數據實測!
SpringBoot利用ThreadPoolTaskExecutor批量插入百萬級數據實測!
前言
- 開發目的: 提高百萬級數據插入效率。
-
采取方案: 利用
ThreadPoolTaskExecutor多線程批量插入。 - 采用技術: springboot2.1.1+mybatisPlus3.0.6+swagger2.5.0+Lombok1.18.4+postgresql+ThreadPoolTaskExecutor等。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
具體實現細節
application-dev.properties添加線程池配置信息
> 基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
>
> * 項目地址:
> * 視頻教程:
spring容器注入線程池bean對象
@Configuration
@EnableAsync
@Slf4j
publicclassExecutorConfig{
@Value("${async.executor.thread.core_pool_size}")
privateintcorePoolSize;
@Value("${async.executor.thread.max_pool_size}")
privateintmaxPoolSize;
@Value("${async.executor.thread.queue_capacity}")
privateintqueueCapacity;
@Value("${async.executor.thread.name.prefix}")
privateStringnamePrefix;
@Bean(name="asyncServiceExecutor")
publicExecutorasyncServiceExecutor(){
log.warn("startasyncServiceExecutor");
//在這里修改
ThreadPoolTaskExecutorexecutor=newVisiableThreadPoolTaskExecutor();
//配置核心線程數
executor.setCorePoolSize(corePoolSize);
//配置最大線程數
executor.setMaxPoolSize(maxPoolSize);
//配置隊列大小
executor.setQueueCapacity(queueCapacity);
//配置線程池中的線程的名稱前綴
executor.setThreadNamePrefix(namePrefix);
// rejection-policy:當pool已經達到max size的時候,如何處理新任務
// CALLER_RUNS:不在新線程中執行任務,而是有調用者所在的線程來執行
executor.setRejectedExecutionHandler(newThreadPoolExecutor.CallerRunsPolicy());
//執行初始化
executor.initialize();
returnexecutor;
}
}
創建異步線程 業務類
@Service
@Slf4j
publicclassAsyncServiceImplimplementsAsyncService{
@Override
@Async("asyncServiceExecutor")
publicvoidexecuteAsync(ListlogOutputResults,LogOutputResultMapperlogOutputResultMapper,CountDownLatchcountDownLatch) {
try{
log.warn("startexecuteAsync");
//異步線程要做的事情
logOutputResultMapper.addLogOutputResultBatch(logOutputResults);
log.warn("endexecuteAsync");
}finally{
countDownLatch.countDown();//很關鍵,無論上面程序是否異常必須執行countDown,否則await無法釋放
}
}
}
創建多線程批量插入具體業務方法
@Override
publicinttestMultiThread(){
ListlogOutputResults=getTestData();
//測試每100條數據插入開一個線程
List>lists=ConvertHandler.splitList(logOutputResults,100);
CountDownLatchcountDownLatch=newCountDownLatch(lists.size());
for(ListlistSub:lists){
asyncService.executeAsync(listSub,logOutputResultMapper,countDownLatch);
}
try{
countDownLatch.await();//保證之前的所有的線程都執行完成,才會走下面的;
//這樣就可以在下面拿到所有線程執行完的集合結果
}catch(Exceptione){
log.error("阻塞異常:"+e.getMessage());
}
returnlogOutputResults.size();
}
模擬2000003 條數據進行測試

多線程 測試 2000003 耗時如下:耗時1.67分鐘
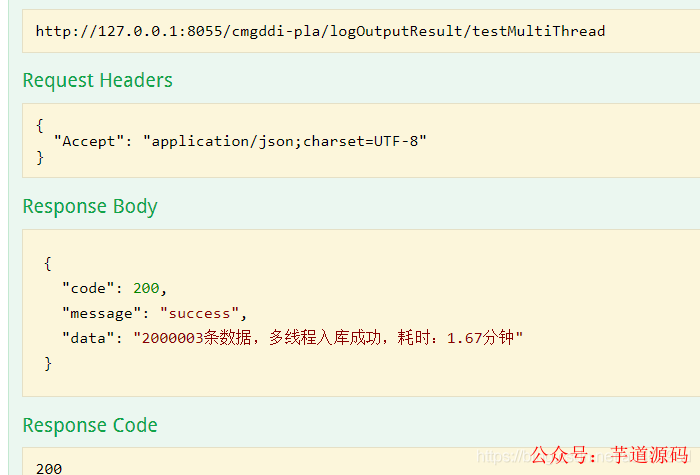

本次開啟30個線程,截圖如下:
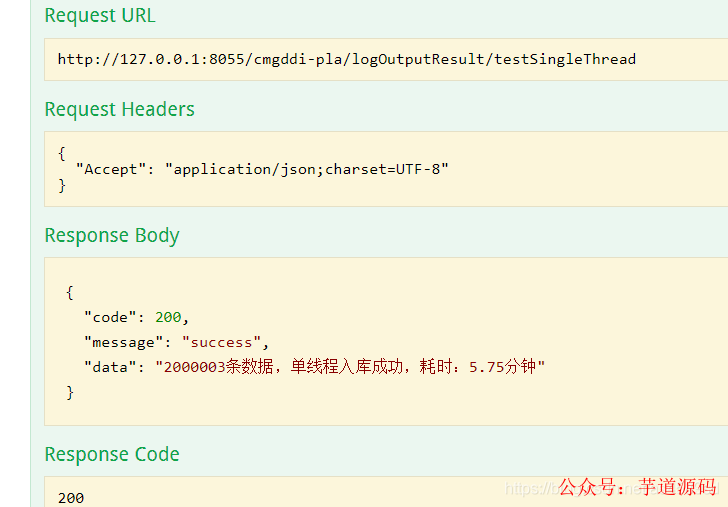
單線程測試2000003 耗時如下:耗時5.75分鐘

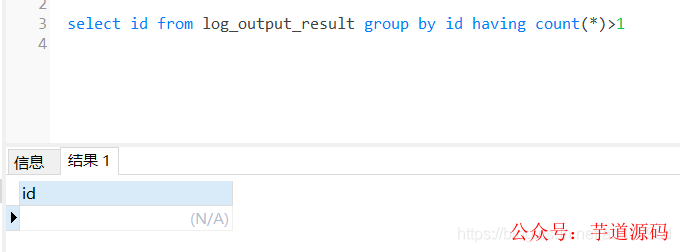
檢查多線程入庫的數據,檢查是否存在重復入庫的問題:
根據id分組,查看是否有id重復的數據,通過sql語句檢查,沒有發現重復入庫的問題
檢查數據完整性:通過sql語句查詢,多線程錄入數據完整
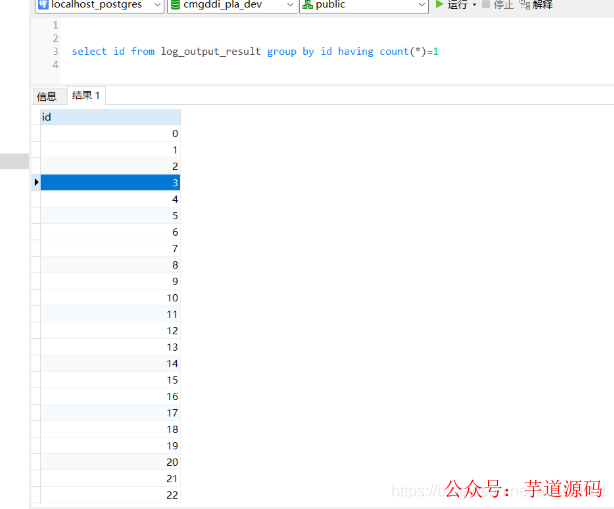
測試結果
不同線程數測試:


總結
通過以上測試案列,同樣是導入2000003 條數據,多線程耗時1.67分鐘,單線程耗時5.75分鐘。通過對不同線程數的測試,發現不是線程數越多越好,具體多少合適,網上有一個不成文的算法:
CPU核心數量*2 +2 個線程。
附:測試電腦配置

審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
SQL
+關注
關注
1文章
773瀏覽量
44219 -
多線程
+關注
關注
0文章
278瀏覽量
20053 -
spring
+關注
關注
0文章
340瀏覽量
14369 -
SpringBoot
+關注
關注
0文章
174瀏覽量
194
原文標題:性能爆表:SpringBoot利用ThreadPoolTaskExecutor批量插入百萬級數據實測!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
工業現場數據實時采集:解鎖工業智能化轉型的關鍵
在當今工業智能化轉型的浪潮中,工業現場數據實時采集的重要性不言而喻。它猶如企業運營的 “慧眼”,為企業帶來全方位的顯著價值。

基于Java、springboot、avue技術開發的醫院績效核算系統源碼
醫院績效考核系統可根據工作績效考核管理規定,配置相應的績效考核模型,從工作量統計、核算維度、核算權重三方面計算工作績效,利用數據處理和數據分析的支撐作用,實現對工作量統計和績效考核結果的統計分析展示
ADS8674輸出數據有尖刺,實測時鐘時序和datasheet不符是怎么回事?
14位ADC。使用verilog實現數據讀寫。SCLK時鐘7.5MHZ。CS和SDI按照data上操作。但實測ADC的SDO數據波形和data上不一致。data上說一個讀寫周期(CS兩個高脈沖
發表于 12-10 06:15
電桿傾斜監測裝置 桿塔傾斜監測裝置 支持數據實時讀取 精確預警
TLKS-PMG-QX電桿傾斜監測裝置的核心組件是雙軸傾角傳感器,該傳感器能夠精確測量桿塔在縱向和橫向兩個方向的傾斜角度。傳感器持續進行數據采集,并將這些數據實時傳輸至監測主機。監測主機配備了高性能通信模塊,支持包括3G、4G、光纖和WiFi在內的多種傳輸方式,將處理后的

企業級數據庫的配置和管理要求匯總
企業級數據庫配置需高性能硬件支撐,包括服務器、存儲、網絡及電源冗余,選用穩定DBMS與操作系統,注重索引與查詢優化。管理上,強調數據安全,實施加密、訪問控制與審計;確保高可用,配置容錯機制與備份恢復;監控調優性能,規劃容量與擴展性;追求易用性,簡化日常管理與維護,確保
DNA計算機研究取得突破性進展:PB級數據存儲與高效處理
8月29日,科學界傳來振奮人心的消息,一項革命性的研究成果為實現全功能DNA計算機奠定了堅實基礎。研究團隊成功開發出一種創新技術,該技術不僅能在DNA中存儲驚人的PB級數據,還能確保這些數據在數千乃至數百萬年內保持完好,同時實現
天拓四方:工業級數據采集網關核心功能解析與應用價值
在數字化轉型浪潮中,工業4.0與智能制造的概念日益深入人心,而這一切的基石在于高效、準確的數據采集與處理能力。工業級數據采集網關作為連接現場設備與云端或數據中心的關鍵橋梁,扮演著至關重要的角色。本文
帶電插入檢測電路的TPD4S1394 Firewire ESD箝位電路數據表
電子發燒友網站提供《帶電插入檢測電路的TPD4S1394 Firewire ESD箝位電路數據表.pdf》資料免費下載
發表于 07-10 10:29
?0次下載

LPS完成戰略性收購 增強數據實踐和營銷云能力
對Explora和Eleven Digital的戰略性收購,以增強其數據實踐和營銷云能力。此次收購將加強LPS技術創新及賦能聯想AI卓越中心(Center of Excellence)所必需的數據基礎,加速企業AI

fanuc robot interface V3.0批量讀寫數據寄存器問題
labview只能讀寫機器人單個R數據寄存器,不能批量讀取,其他讀寫IO和坐標都沒問題。
調用的方法只能使用getValue和setvalue讀寫單個,不能批量一次性讀寫數組
發表于 06-04 15:43
濾波器插入損耗怎么測試?測試標準是什么?
插入損耗是指信號通過濾波器后,輸出信號與輸入信號之間的功率差距。插入損耗包括共模插入損耗和差模插入損耗兩種。插入損耗越小,說明濾波器對輸入信

淺談多線合用牽引變電所電能質量實測分析
淺談多線合用牽引變電所電能質量實測分析 張穎姣 安科瑞電氣股份有限公司 上海嘉定 201801 摘要: 多線合用牽引變電所運行條件復雜,實測數據更能反映牽引變電所真實的運行狀況。首先分析了牽引變所
車規級數字功放一體成型電感VSAD0660-3R3M數據手冊
電子發燒友網站提供《車規級數字功放一體成型電感VSAD0660-3R3M數據手冊.pdf》資料免費下載
發表于 03-04 11:38
?0次下載
工業級數據采集通用網關在車間數據采集的應用-天拓四方分享
的數據采集網關是至關重要的。 工業級數據采集通用網關具備數據采集、處理、傳輸功能的設備,可連接多種工業現場設備,如PLC、傳感器、執行器等,實現數據的實時采集、傳輸。其核心功能包括





 工商網監
工商網監
評論