

主要貢獻
論文詳細分析了意大利關于GBV的新聞報道中人類的責任觀念,證明了特定語法結構和語義框架的會引發不同的責任認知,并且可以被自動建模。
-01-
摘要
不同的語言表達可以通過強調某些部分從不同的角度來概念化同一事件。該論文調查了一個具有社會后果的案例:基于性別的暴力(GBV)的語言表達如何影響責任認知。文章建立在這一領域先前的心理語言學研究的基礎上,并對從意大利報紙的語料庫中自動提取的GBV描述進行了大規模的感知調查。
然后,訓練回歸模型,預測GBV參與者對不同的感知責任維度的顯著性。文章最好的模型(微調后的BERT)顯示了穩健的整體表現,在維度和參與者之間有很大的差異:顯著的關注比顯著的指責更可預測,犯罪者的顯著性比受害者的顯著性更可預測。
使用不同表示的嶺回歸模型的實驗表明,基于語言學理論的特征與基于單詞的特征相似。文章表明不同的語言選擇確實會引發不同的責任認知,而且這種感知可以自動建模。這項工作可以成為提高公眾和新聞制作人對不同視角所產生的后果認識的核心工具。
-02-
簡介及背景
同樣的事件可以用許多不同的方式來描述,這取決于報告者和他們所做的選擇。通過選擇一些特定的詞,可以為讀者提供一個關于發生了什么的具體視角。
一篇新聞的寫作方式,嚴重影響了讀者感知所描述事件中責任歸因的方式。
圖1:“騎自行車的人撞上車門”
圖1:“汽車司機打開車門撞到騎自行車的人”
圖1:“騎自行車的人在第五街的交通事故中受傷”
圖1:“自行車和汽車的碰撞”
使用不同的標題來說明當相同的事件從不同的角度的描述時,可以導致不同的對參與者責任歸屬的看法。
圖1說明了如何從不同的角度報告同一事件其方式確實會影響對參與者責任的感知。文章研究在基于性別的暴力(GBV)這一社會相關現象的背景下,使用NLP工具來解開責任歸因。針對婦女的暴力行為是令人擔憂的普遍現象,因此經常在新聞中被報道。
Pinelli和Zanchi在意大利新聞中觀察到,在對殺害女性的描述中,具有不同及物性水平的句法結構——也就是及物主動結構,到被動和反使役結構,對應于歸因于(男性)犯罪者的不同程度的響應性。
例如,當“he killed her(他殺了她)”(主動/及物)完全明確表達了主動行為者的參與,但“she was killed (by him)她是(被他)殺死的”(被動),這種表達方式就將注意力從主動行為者上轉移開來;再比如“themurder(謀殺)”或者是“the event(事件)”的表達方式,就將重點從兩個參與者轉移到事件的背景中。
在一篇相關的文章中,Meluzzi等人通過對意大利語中人工構建的GBV報告的調查,研究了論證結構構建對責任歸因的影響。他們的研究結果進一步證實了Pinelli和Zanchi關于讀者對犯罪者和受害者的能動性和責任影響的發現。這兩項研究的結果與之前的心理語言學研究結果一致,表明在任何層面上涉及暴力的事件中,行為人的語言背景阻礙了他們的責任,并促進了對受害者的指責。
基于這樣的框架選擇,普通讀者將如何看待所描述的事件?我們能自動模擬這種感知嗎?
本文回答上述問題,仍然基于意大利新聞中對殺害女性的描述,并利用框架語義作為一種理論和實踐工具,以及最新的NLP方法。
使用特定的預先選擇的語義框架,使用最先進的語義解析器自動提取,文章從意大利報紙中識別出對GBV事件的描述,通過大規模的調查來收集人類的判斷,要求參與者閱讀文本,并將一定程度的責任歸屬于犯罪者、受害者,或一些更抽象的概念(例如,“嫉妒”、“憤怒”)。更多細節見2。
文章開發一系列回歸模型(從頭開始以及預先訓練的transformer模型),利用從表面到框架的各種語言線索來自動建模責任感知。模型的訓練目標是預測人類的感知分數。文章實現了與基于Transformer model的模型的強相關性。調查和結果分析的細粒度特征也允許各個方面的預測復雜性的差異。第3節中討論建模和評價。
結果表明,不同的語言選擇確實觸發了不同的責任感知,而且這種感知可以自動建模。這一發現不僅證實了以前(人工)在小規模上進行的研究,而且也為文本進行大規模分析及其效果提供了可能。
-03-
構建【謀害女性感知數據集】
為了構建這個數據集,作者采用眾包的方式,設計了一個在線的問卷調研。具體來說,作者收集了關于2015至2017年間,意大利發生的937起殺害女性案件的新聞報道,從中抽取句子展示給眾包人員并要求其對句子所表達的責任程度進行打分。問卷結果表明,語義信息和句法結構明顯影響讀者對“謀害女性事件”的看法。下面將詳細說明作者如何設計調研問題。
3.1問題設定
對案件采取不同的描述方式,會導致讀者對“案件參與者應承擔多大責任?”這一問題產生不同的看法。作者首先將“責任”這一復雜的概念拆解成三個維度:
- FOCUS:句子關注的是否是加害人?
- CAUSE:句子所描述的事件是否主要由人引起?
- BLAME:句子是否將責任歸咎于加害人?
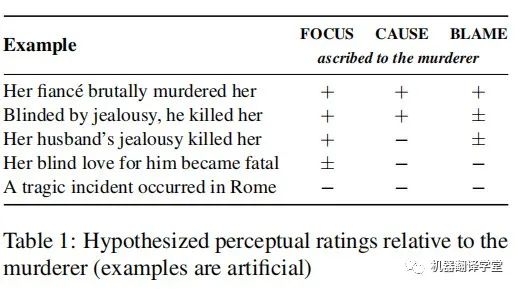
表1用人工構造的句子展示了這三個維度的區別。針對上述三個問題,表中+、-、±代表句子可能如何被讀者解讀。例如,第一、第二個句子都更加關注兇手(FOCUS +)并且強調他的行為致使案件發生(CAUSE +),但是第二句話將兇手描述為“被嫉妒蒙蔽了雙眼”,暗示兇手不必為其行為承擔全部責任(BLAME ±)。注意讀者的看法本質上是主觀的,因此這些例子不該被視為任何形式的“黃金準則”。
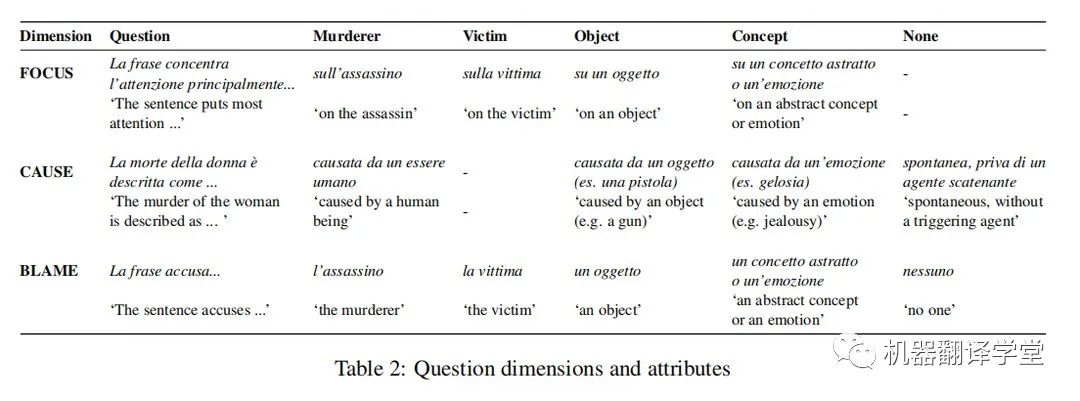
為了正確判斷讀者認為兇手應承擔責任的程度,作者還分別針對victim(受害人)、object(如武器)、concept(抽象概念)、emotion(如嫉妒)或nothing(不追究)設計了上述三個維度的問題。作者要求眾包人員按照五分制對每一類問題進行打分,參與者也可以認為句子與謀殺案無關直接跳過它。根據試點實驗的初步結果,作者對每個類別的問題做了些輕微的調整:例如因為句子總是關注某事(FOCUS),所以省略了FOCUS中的none類別,等等。表2展示了完整的調研問題。
3.2句子選擇
交給眾包人員進行評分的句子分兩步選出:首先使用LOME解析器自動抽取語義信息,這些信息與SpaCy自動依賴解析工具結合,對句法結構進行分類。例如,“he murdered her”將被分類為“KILLING/active”,代表“殺人”的語義和主動的句法表達;“she died”被分類為“DEATH/intransitive”;“the tragedy”被分類為“CATASTROPHE/nonverbal”。
第二步,作者設計了在不同程度上強調謀殺案件的典型語義集合,并在至少包含一個典型語義的句子中進行隨機采樣。具體來講,作者使用FrameNet框架手動注釋Pinelli和Zanchi中的例句,并選擇那些表述“受害者死亡事件”詞語(如killed、died、dead、incident等)的語義來構造典型語義集。
最終得到的語義集合為{KILLING,DEATH,DEAD_OR_ALIVE,EVENT,CATASTROPHE},所有語義都可以用來描述完全相同的事件,只是具有不同的動態性(已經死亡或者將要死亡)、能動性(兇手殺人或者受害人死亡)和普遍性(某人死亡或者某事發生)。作者使用這種方法為每一個“語義信息/句法結構”類別采樣了相同數目的句子。
3.3眾包實現細節
作者考慮到眾包人員分析復雜句子的認知負荷,以及閱讀一個主題沉重且痛苦的文本的情感負荷,每個參與人員只需在一組句子(50句)的三個維度之一上打分。為了平衡“每句話注釋的數量”和“注釋的總句子數”,作者為每句話每個維度安排10個眾包人員。這意味著完整的注釋一組句子需要30個眾包人員。
為了在事先不知道反饋率(眾包人員質量)的情況下,將眾包人員均勻的分配在每組句子和每個維度之間,作者創建了60個眾包小組(注釋20組句子,每組50句,因此共1000個句子且每個句子三個維度)并將參與者分配到滾動的小組中:每次開放一個組,一旦達到要求的參與者數量小組就會自動關閉,然后打開下一個組。一旦一個組被填滿就手動檢查響應的完整性和質量。
由于標注任務的主觀性,注釋沒有錯誤的回答,作者設定如果注釋至少滿足以下三個標準中的一個,則認為其質量較低:(i)參與者完成問卷的速度快得令人難以置信;(ii)參與者連續將句子標記為不相關并跳過;(iii)參與者總是給每句話同樣的評分;作者在意大利幾所大學不同專業的本科和碩士學生中分發調查平臺的鏈接,并匿名收集回答,僅要求參與者說明他們的性別、年齡和職業。
3.4結果
作者最終的數據集涵蓋了400個句子,共有240名參與者對其進行了評級(153名女性,86名男性,1名非二元性別;平均年齡23.4)。表3給出了跨句子的評價得分匯總。作者給出了所有參與者和所有句子的平均分(綠色部分,在0~5的范圍內),以及句子間平均分的標準差。總的來說,對應于行兇者的屬性往往有更高的平均分,但方差也比其他屬性更高。由于任務固有的主觀性,并且結果與之前關于感知規范的研究一致,作者沒有計算注釋者之間的一致性分數。
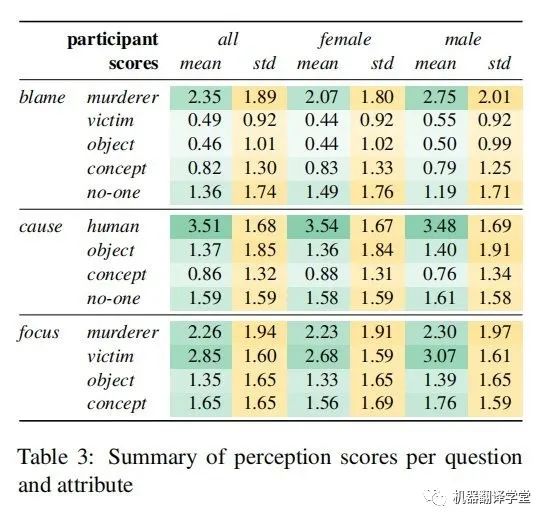
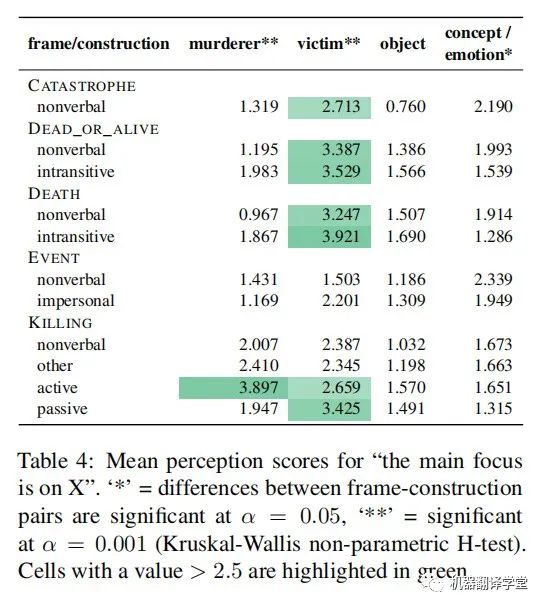
表4按語義信息和句法結構劃分,顯示了FOCUS問題的平均得分。這顯示出了顯著的效果:包含KILLING語義的句子傾向于將更高的FOCUS放在兇手身上,當使用主動結構時更是如此。同時,在主動或被動結構中包含CATASTROPHE, DEAD_OR_ALIVE、DEATH和KILLING語義,會增加受害者的FOCUS。
另一方面,object的FOCUS得分上沒有顯著差異,concept或emotion的FOCUS得分上有顯著但較小的差異。在每一種情況下,研究結果都符合作者基于語言學理論的預期:如果一個事件參與者在謂詞中進行了詞匯編碼,并且需要在語法上進行表達,那么這個參與者更有可能被認為處于關注狀態。基于句子的內容,以及在詞匯上編碼了受害者或殺手的幾個典型語義(如KILLING),人們會更多地關注兇手和受害者,而無生命的concept或emotion是非必要的。
-04-
感知分數預測
在本文中,作者將該任務建模為一個多輸出回歸任務:給定一個句子,作者希望預測一個感知向量,其中該向量每一維代表問卷中一個特定的Likert維的值。
4.1 參與者聚合
作者首先對每句話和每個參與者的感知值計算z-score(也叫標準分數,是一個數與平均數的差再除以標準差的過程。在統計學中,標準分數是一個觀測或數據點的值高于被觀測值或測量值的平均值的標準偏差的符號數。),然后取參與者的平均值。分別計算每個Likert維度和參與者的z-score,以考慮兩種類型的變異性:
1)維度內偏好,指的是不同的參與者對分數范圍的不同使用:根據自信程度和其他因素,參與者可能會選擇大量使用范圍的端點(例如,經常分配“0”或“5”)或集中在范圍的特定部分(例如,在中心附近或靠近高點或低點)。
2)維度間偏好,指的是參與者總是傾向于給特定維度分配更高或更低的分數的可能性。例如,一些參與者可能總是給“blame on the murderer”和“blame on the victim”更高的分數。
通過對z-score的感知值進行回歸,作者希望模型預測出句子中是否存在明顯偏見(例如,這個句子是否將高于平均水平的責任推給了受害者?對兇手的關注低于平均水平?)
4.2 評價方法
作者從多個角度對此多輸出回歸問題進行評價。
1)Root Mean Squared Error (均方根誤差,RMSE)和{R^2}(均方誤差),它估計了由回歸模型解釋的感知分數變化的比例。作者分別計算了每一個維度和維度平均值的{R^2}。
2)Cosine (余弦相似度,COS),它度量了答案和預測結果之間的余弦相似度,并提供在映射中保存維度之間關系的程度的估計。
3)Most Salient Attribute (MSA),作者將回歸評估為預測哪個Likert維度對每個問題具有最高(z-score)感知值的分類任務的準確性(實現為簡單地計算argmax對每個問題對應的輸出維度)。例如,對于一個特定的句子,“concept”是責備問題得分最高的維度,這意味著“blame on a concept”在這個句子中比其他句子更突出。
注意,每個維度的z-score是獨立計算的,因此,具有最高z-score的維度不一定也具有最高的絕對值。類似于給特定維度分配更高或更低分數的風險,在這種情況下,參與者在指責問題上給“殺人犯”的分可能比“concept”多,即使在“concept”非常突出的句子中也是如此。在這種情況下,“concept”的絕對值總是比“murderer”低,但在“concept”得分相對較高、“murderer”得分相對較低的句子中,“concept”的z-score可能會更高。
4.3 模型
作者比較了兩種模型,分別是嶺回歸模型(一種使用L2正則的線性回歸模型)和預訓練transformer模型。前者在不同類型的輸入特征上面進行訓練,后者則經過微調后回歸預測多輸出。
特征(用作嶺回歸模型的輸入)
特征分為三類:
1)表面特征:代表輸入句子的詞法級別的特征,分別使用bag-of-words (bow)模型和FastText (ft)模型的輸出特征。
2)框架語義特征:通過frame semantic parser配合bow模型得到的在語義級別上略高于表面特征的表示,包括f1、f2、f1+、f2+。
3)句子特征:transformer模型產生的句子級別的表示,分別使用了SentenceBERT (sb)、XLM-R、BERT-IT Mean (bm) 和 XLM-R Mean (xm)提取特征。
預訓練transformer模型
作者在預訓練transformer編碼器的后面接上了有一個簡單的線性層構成的神經回歸模型。作者分別實驗了不同的BERT變體。包括Italian BERT XXL Base (BERT-IT)、BERTino、Multilingual BERT Base、Multilingual DistilBERT、XLM-RoBERTa Base。
4.4結果
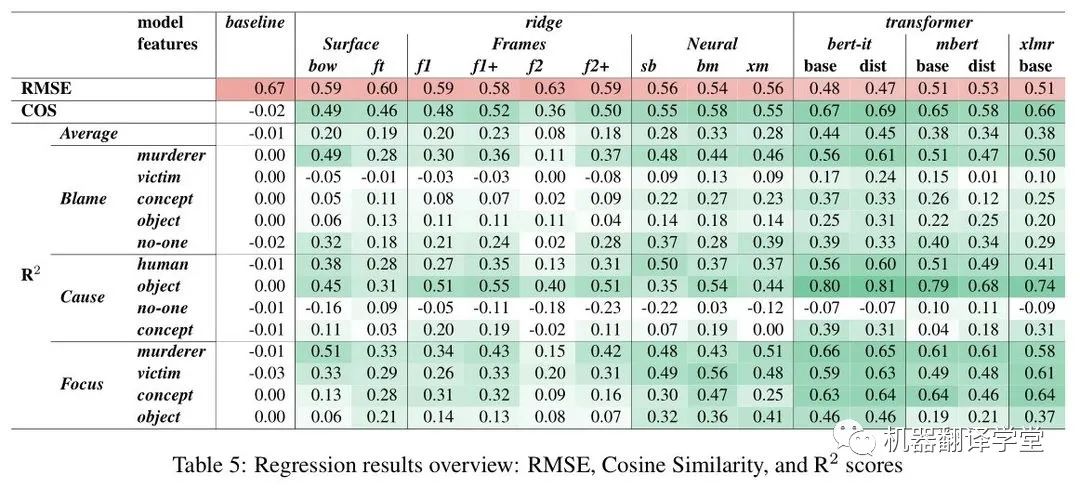
表5顯示了RMSE、COS和{R^2}指標測試集的主要結果。作者列出如下觀察結論:
經過微調的單語BERT模型在所有測試中表現最好,其總體{R^2}分數約為0.45,這意味著模型成功預測了感知分數中近一半的方差。
多語言BERT模型(mBERT和XLM-R)的表現均較差,平均{R^2}為0.38或更低。
有趣的是,普通的蒸餾版BERT對比原始BERT性能有所下降,但意大利語版蒸餾的BERT(BERTino)的性能沒有下降,甚至比原始模型略好。
{R^2}的下降并不總是與余弦分數的下降一致:例如,XLM-R分數比BERT-IT/base低0.06 {R^2}分,但余弦分數只下降0.01,而mBERT/dist在{R^2}上損失0.10分,在COS上損失0.09分。因此,似乎有些模型(如XLM-R)在預測每個異常得分的確切大小方面不太準確,但在捕捉跨維度的總體得分模式方面相對較好。
另外,雖然嶺回歸模型的表現比transformer差很多,但比較不同特征之間的結果對于理解預測感知需要什么信息是有幫助的:
基于表面和框架特征的回歸模型表現相似,{R^2}分數在0.20左右(f2為負離群值),而具有神經特征的模型更好({R^2} 0.28-0.33)。
對于那些基于transformer提取得到的特征訓練的脊模型,作者發現意大利語版本的BERT (bm)的平均最后一層表示的結果最好,而基于XLM-R (sb和xm)的兩種模型得分略低。
通過比較不同問題和屬性的{R^2}分數,還可以發現預測難度的巨大差異:
例如,在各個模型中,blame on murderer得到了很好的分數,而blame on victim的分數相對較低,即使是最強的模型(例如BERTino的0.24),而在基線(或更低)分數較弱的模型——特別是蒸餾mBERT,它在其他屬性上表現不錯。
Caused by no-one 是最難預測的,沒有模型得分在0.10以上。
Focus問題具有總體上最好和最一致的性能,特別是對于意大利語版本的BERT模型,對于四個屬性中的每一個都實現了不錯的性能(0.46- 0.66 {R^2})。
這種模式也反映在MSA中(表6):對于focus類別,它基本上更容易預測的維度與最高的得分比Blame和Cause。然而,對于每個問題,所有模型的表現都好于概率水平,其中BERTino的綜合得分最高(56-72%)。
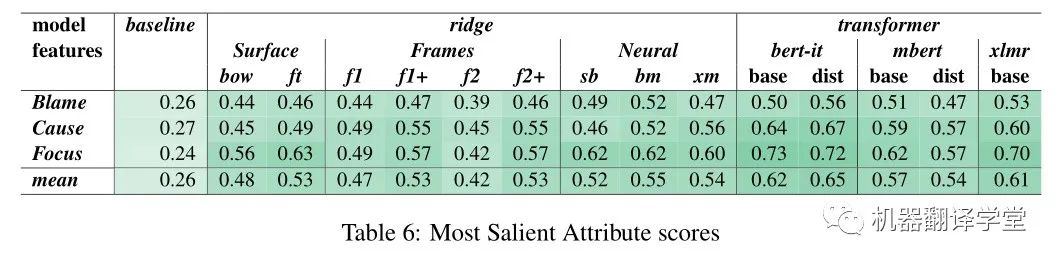
在嶺回歸模型中,相對于基于表面特征的模型,基于BERT特征的模型的性能增益(BERT特征比表面特征的增益)在屬性之間有很大差異。例如,bow模型有一個令人驚訝的高得分的指責殺人犯({R^2} 0.49),只有適度的收益從BERT-IT 和 BERTino模型(resp.+0.06和+0.12分)。相比之下,bow在專注概念上得分較低({R^2} 0.13),而BERT-IT和BERTino得分較高({R^2} 0.63/0.64)。
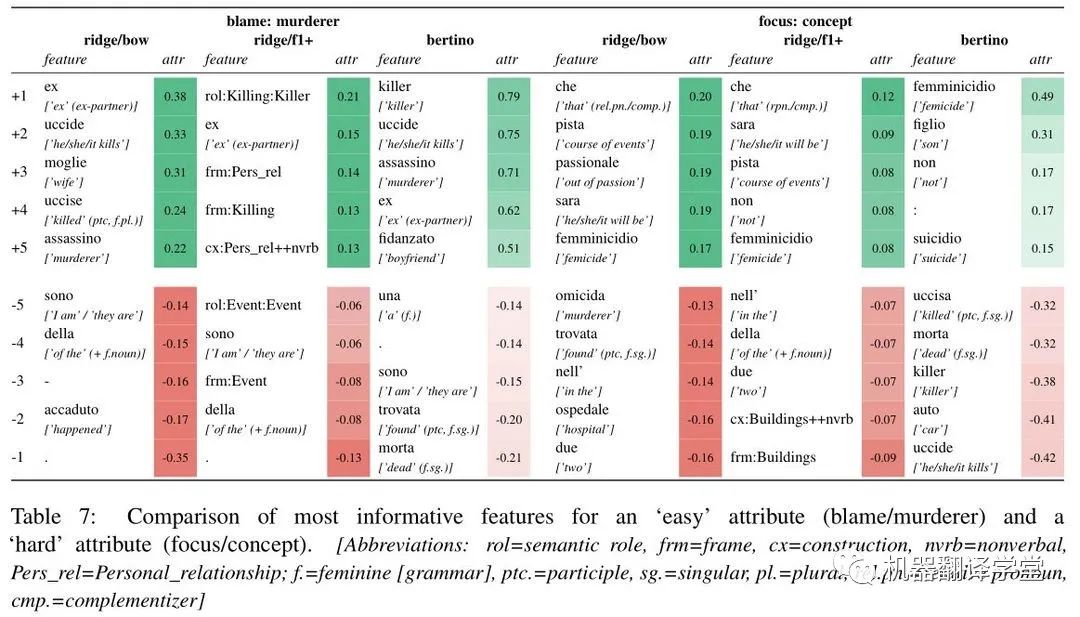
為了進一步了解模型之間的差異,作者進行了特征歸因分析。blame on murderer 和 focus on concept的結果如表7所示。對于殺人犯的責任,三種模型似乎都聚焦于相似的詞匯項:例如,“uccide”(“(he) kills”)在脊回歸和微調BERTino模型中都有很高的正歸因值,在f1+中作者發現KILLING框架的正歸因值,這是對殺人相關詞匯的抽象。
作者還發現,個人關系(‘wife’, ‘ex’, PER-SONAL_RELATIONSHIP )在所有三種模型中都得到了積極的歸因。相比之下,作者發現了“accaduto”(“happened”)的負歸因值以及bow和f1中相應的EVENT框架,這與§2.4中討論的觀察結果完全吻合。由于對概念的關注,三種模型之間沒有明顯的深刻區別。
作者確實在每個模型中發現了幾個直觀的相關特征:"passionale"("out of passion")和"femminicidio"("femicide")可以測試句子可以聚焦的概念的集合,而"omicida"("murderer/murderous’")和"killer"可以被視為強調人類主體的作用,而不是一個抽象的概念。
-05-
結論與未來工作
論文詳細分析了意大利關于GBV的新聞報道中人類的責任觀念。文章收集的判斷證實了之前關于特定語法結構和語義框架的影響以及它們在讀者中引發的感知。
文章研究了不同的NLP架構在多大程度上可以預測人類的感知判斷。微調單語transformer獲得在多個評估措施的最佳結果,為集成能夠識別潛在感知效應的系統作為媒體專業人員的支持工具提供了可能性。
未來,文章也計劃對數據進行更詳細的分析,考慮受訪者在個人和人口統計方面的差異。除此之外,后續實驗將側重于將該方法應用于其他語言和文化背景,既針對基于性別的暴力,也針對其他社會相關主題,如車禍等。
審核編輯:劉清
-
編碼器
+關注
關注
45文章
3751瀏覽量
136543 -
MSA
+關注
關注
0文章
31瀏覽量
8929 -
nlp
+關注
關注
1文章
490瀏覽量
22414
原文標題:AACL'22 Best Paper | 不同的表達可能會引發讀者不同的想法,可以通過模型自動模擬這種語言“偏見”
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深圳市德上光電科技有限公司招聘LED封裝業務員
請問一下,用AVR studio 5如何用C語言表達attiny85的進入睡眠?
招聘照明設計師
招聘銷售代表
基于情緒特征用戶性別識別

簡單的gcc內嵌匯編例分析
AI打LeetCode周賽進入前10%!秘訣:自然語言編程

如何解決LLMs的規則遵循問題呢?






 工商網監
工商網監

評論