") Meta開發(fā)AITemplate,大幅簡化多GPU后端部署
Meta開發(fā)AITemplate,大幅簡化多GPU后端部署
眾所周知,GPU 在各種視覺、自然語言和多模態(tài)模型推理任務(wù)中都占據(jù)重要位置。然而,對于高性能 GPU 推理引擎,AI 從業(yè)者幾乎沒有選擇權(quán),必須使用一些平臺專有的黑盒系統(tǒng)。這意味著如果要切換 GPU 供應(yīng)商,就必須重新實現(xiàn)一遍部署系統(tǒng)。在生產(chǎn)環(huán)境中當(dāng)涉及復(fù)雜的依賴狀況時,這種靈活性的缺失使維護迭代成本變得更加高昂。
在 AI 產(chǎn)品落地過程中,經(jīng)常需要模型快速迭代。盡管一些閉源系統(tǒng)(如 TensorRT)提供了一些定制化功能,但這些定制化功能完全不能滿足需求。更進一步來說,這些閉源專有的解決方案,會使 debug 更加困難,對開發(fā)敏捷性造成影響。
針對這些業(yè)界難題,Meta AI 開發(fā)了擁有 NVIDIA GPU 和 AMD GPU 后端的統(tǒng)一推理引擎——AITemplate。
AITemplate 在 CNN、Transformer 和 Diffusion 模型上都能提供接近硬件上限的 TensorCore (NVIDIA GPU) 和 MatrixCore (AMD GPU) 性能。使用 AITemplate 后,在 NVIDIA GPU 上對比 PyTorch Eager 的提速最高能達到 12 倍,在 AMD GPU 上對比 PyTorch Eager 的提速達到 4 倍。
這意味著,當(dāng)應(yīng)用于超大規(guī)模集群時,AITemplate 能夠節(jié)約的成本數(shù)額將是驚人的。
具體而言,AITemplate 是一個能把 AI 模型轉(zhuǎn)換成高性能 C++ GPU 模板代碼的 Python 框架。該框架在設(shè)計上專注于性能和簡化系統(tǒng)。AITemplate 系統(tǒng)一共分為兩層:前段部分進行圖優(yōu)化,后端部分針對目標 GPU 生成 C++ 模板代碼。AITemplate 不依賴任何額外的庫或 Runtime,如 cuBLAS、cudnn、rocBLAS、MIOpen、TensorRT、MIGraphX 等。任何 AITemplate 編譯的模型都是自洽的。
AITemplate 中提供了大量性能提升創(chuàng)新,包括更先進的 GPU Kernel fusion,和一些專門針對 Transformer 的先進優(yōu)化。這些優(yōu)化極大提升了 NVIDIA TensorCore 和 AMD MatrixCore 的利用率。
目前,AITemplate 支持 NVIDIA A100 和 MI-200 系列 GPU,兩種 GPU 都被廣泛應(yīng)用在科技公司、研究實驗室和云計算提供商的數(shù)據(jù)中心。
團隊對 AITemplate 進行了一系列測試。下圖的測試展示了 AITemplate 和 PyTorch Eager 在 NVIDIA A100 上的主流模型中的加速比。
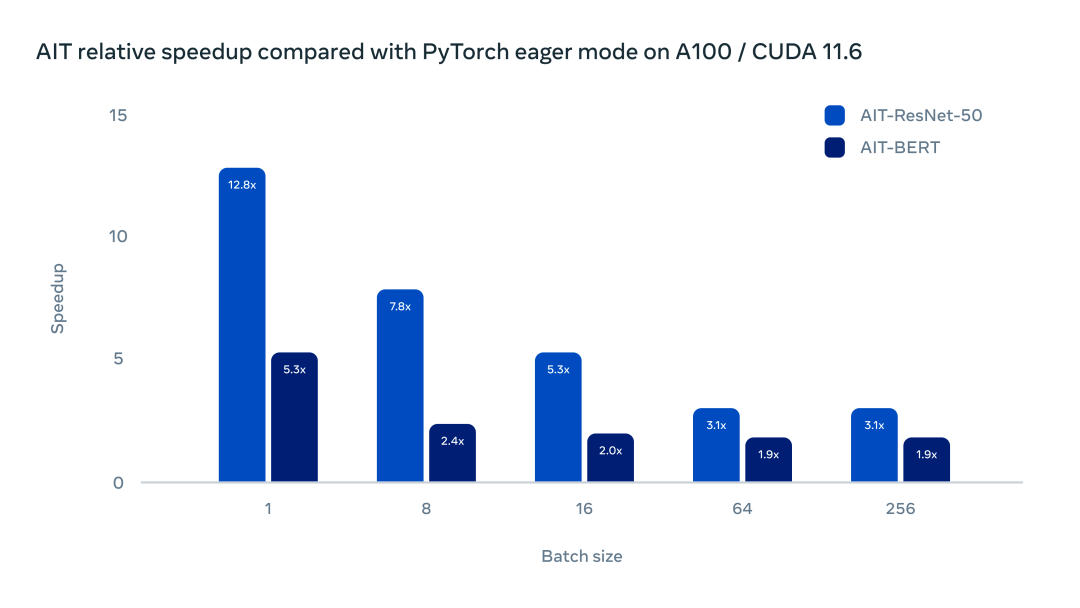
在帶有 Cuda 11.6 的 Nvidia A100 上運行 BERT 和 ResNet-50,AITemplate 在 ResNet-50 中提供了 3 到 12 倍的加速,在 BERT 上提供了 2 到 5 倍的加速。
經(jīng)測試,AITemplate 在 AMD MI250 GPU 上較 PyTorch Eager 也有較大的加速比。
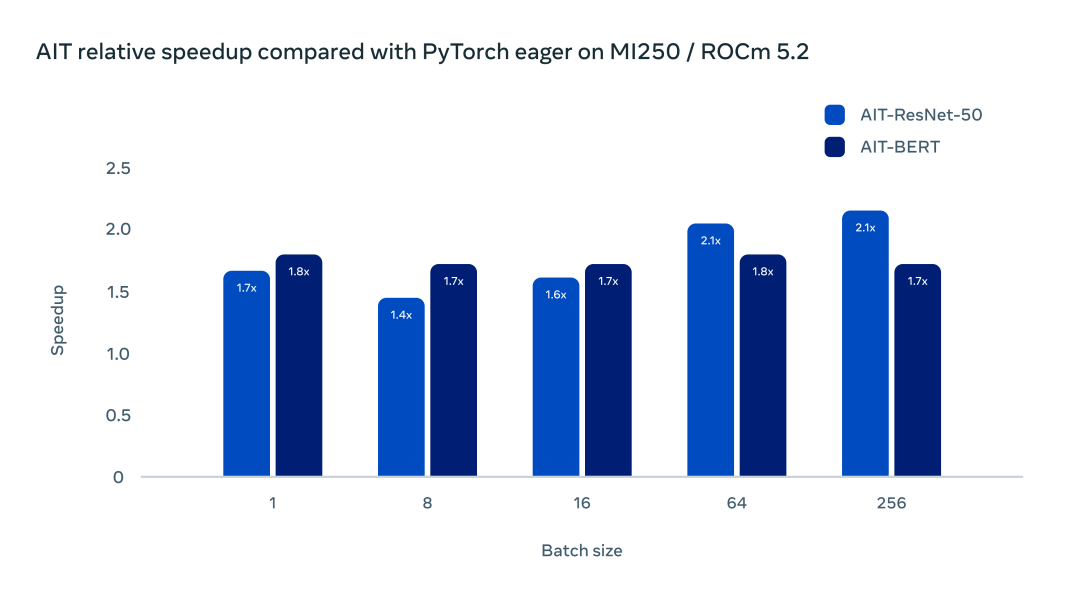
使用 ROCm 5.2 和 MI250 加速器,ResNet-50 和 BERT 的加速在 1.5-2 倍范圍內(nèi)。
AITemplate 的統(tǒng)一 GPU 后端支持,讓深度學(xué)習(xí)開發(fā)者在最小開銷的情況下,擁有了更多的硬件提供商選擇。下圖直觀展示了 AITemplate 在 NVIDIA A100 GPU 和 AMD MI250 GPU 上的加速對比:
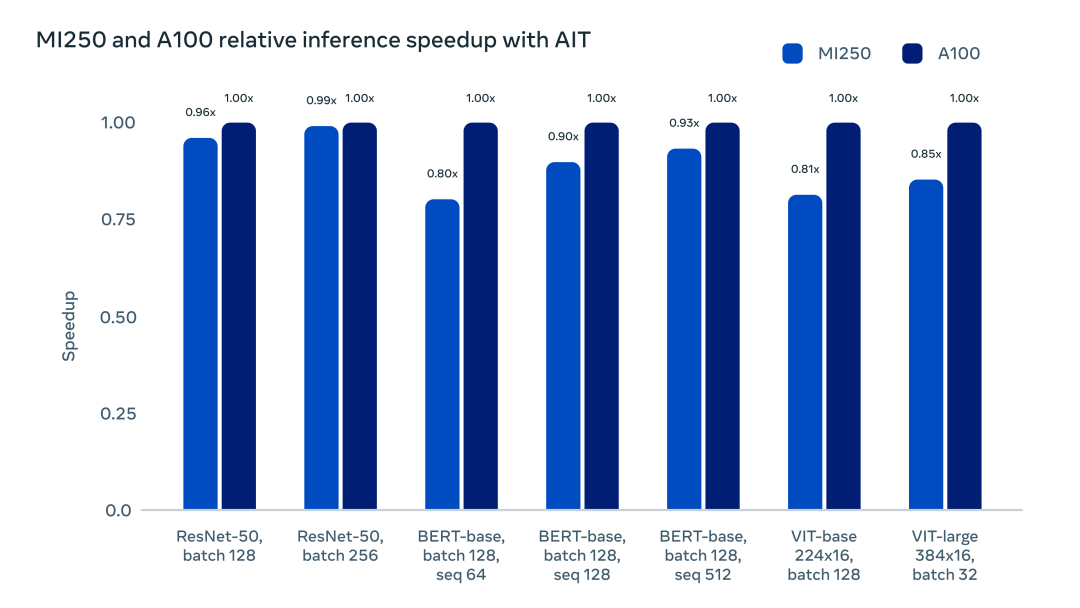
此外,AITemaplte 的部署較其他方案也更為簡潔。由于 AI 模型被編譯成了自洽的二進制文件并且不存在任何第三方庫的依賴,任何被編譯的二進制文件都能在相同硬件、CUDA 11/ ROCm 5 或者更新的軟件環(huán)境中運行,也不用擔(dān)心任何后向兼容問題。AITemplate 提供了開箱即用的模型樣例,如 Vision Transformer、BERT、Stable Diffusion、ResNet 和 MaskRCNN,使得部署 PyTorch 模型更加簡單。
AITemplate 的優(yōu)化
AITemplate 提供了目前最先進的 GPU Kernel 融合技術(shù):支持縱向、水平和內(nèi)存融合為一體的多維融合技術(shù)。縱向融合將同一條鏈上的操作進行融合;水平融合將并行無依賴的操作進行融合;內(nèi)存融合把所有內(nèi)存移動操作和計算密集算子進行融合。
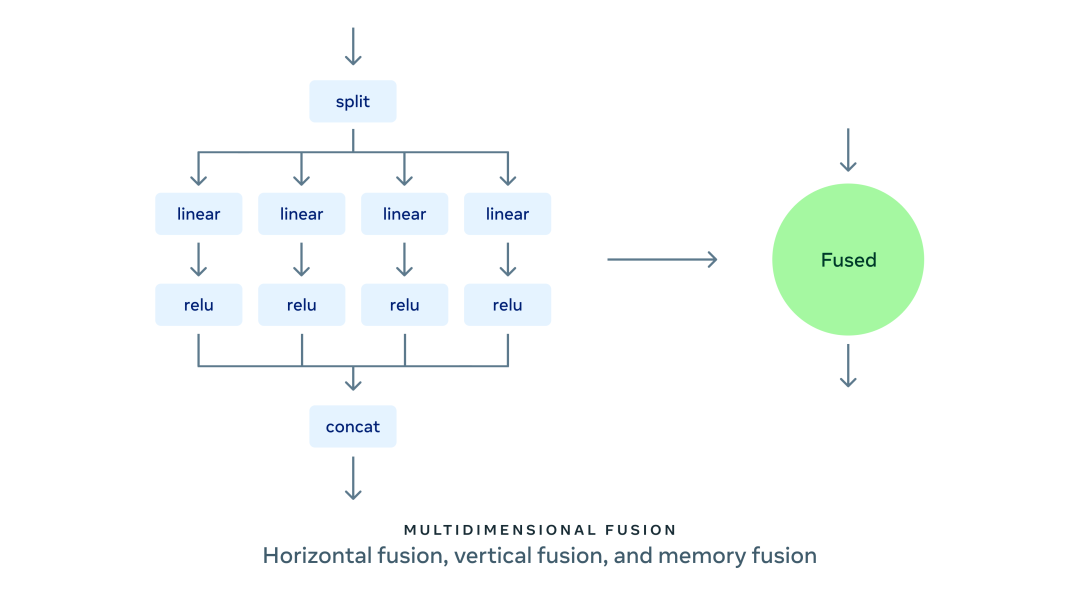
在水平融合中,AITemplate 目前可以把不同輸入形狀的矩陣乘法 (GEMM)、矩陣乘法和激活函數(shù),以及 LayerNorm、LayerNorm 和激活函數(shù)進行融合。
在縱向融合中,AITemplate 支持超過傳統(tǒng)標準的 Elementwise 融合,包括:
通過 CUTLASS 和 Composable Kernel 支持了矩陣和 Elementwise 算子融合;
為 Transformer 的 Multi-head Attention 提供了矩陣乘法和內(nèi)存布局轉(zhuǎn)置融合;
通過張量訪問器對內(nèi)存操作,如 split、slice、concatenate 等進行融合來消除內(nèi)存搬運。
在標準的 Transformer Multi head attention 模塊,目前 AITemplate 在 CUDA 平臺使用了 Flash Attention,在 AMD 平臺上使用了 Composable Kernel 提供的通用背靠背矩陣乘法融合。兩種解決方案都能大幅減小內(nèi)存帶寬需求,在長序列問題中,提升更為明顯。如下圖所示:
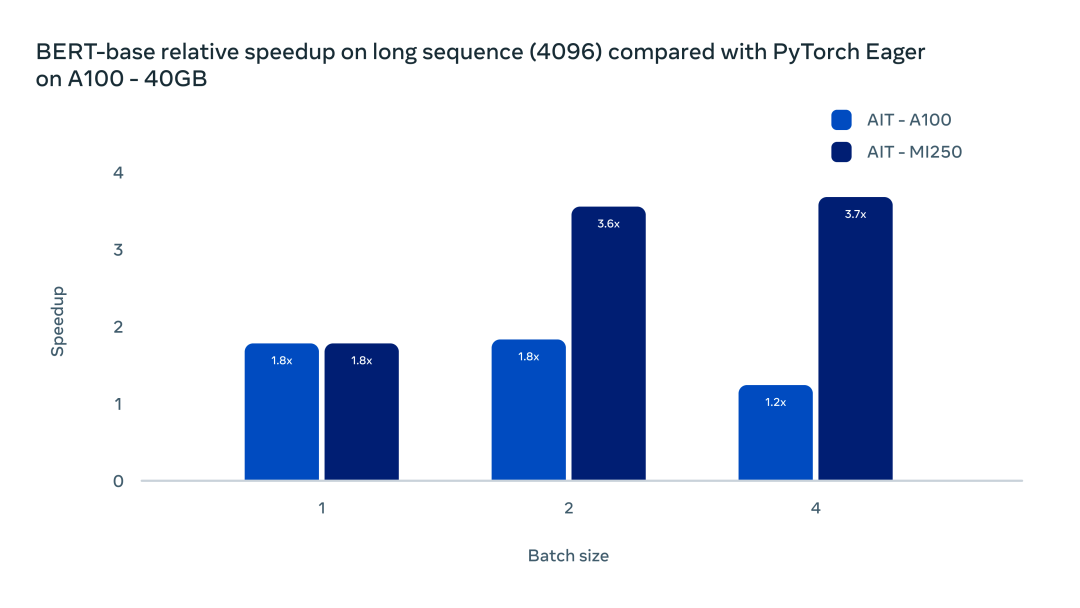
AITemplate 與 Composable Kernel 的廣義背靠背融合顯著提高了長序列 Transformer 的推理效率。在 batch size 為 1 時,使用 AITemplate 的兩張 GPU 均比原生框架加速了 80%。
開發(fā) AITemplate
AITemplate 有兩層模版系統(tǒng):第一層在 Python 中使用 Jinja2 模板,第二層在 GPU TensorCore/MatrixCore 中使用 C++ 模板(NVIDIA GPU 上使用 CUTLASS,AMD GPU 上使用 Composable Kernel)。AITemplate 在 Python 中找到性能最優(yōu)的 GPU 模板參數(shù),再通過 Jinja2 渲染出最終的 C++ 代碼。
在代碼生成后,就能使用 GPU C++ 編譯器(NVIDIA 平臺上的 NVCC 和 AMD 平臺上的 HIPCC)編譯出最終的二進制代碼。AITemplate 提供了一套類似于 PyTorch 的前端,方便用戶直接將模型轉(zhuǎn)換到 AITemplate 而不是通過多層 IR 轉(zhuǎn)換。
總體來看,AITemplate 對當(dāng)前一代及下一代 NVIDIA GPU 和 AMD GPU 提供了 SOTA 性能并大幅簡化了系統(tǒng)復(fù)雜度。
Meta 表示,這只是創(chuàng)建高性能多平臺推理引擎旅程的開始:「我們正在積極擴展 AITemplate 的完全動態(tài)輸入支持。我們也有計劃推廣 AITemplate 到其他平臺,例如 Apple 的 M 系列 GPU,以及來自其他供應(yīng)商的 CPU 等等。」
此外,AITemplate 團隊也正在開發(fā)自動 PyTorch 模型轉(zhuǎn)換系統(tǒng),使其成為開箱即用的 PyTorch 部署方案。「AITemplate 對支持 ONNX 和 Open-XLA 也持開放態(tài)度。我們希望能構(gòu)建一個更為綠色高效的 AI 推理系統(tǒng),能擁有更高的性能,更強的靈活性和更多的后端選擇。」團隊表示。
審核編輯:郭婷
-
gpu
+關(guān)注
關(guān)注
28文章
4768瀏覽量
129232 -
AI
+關(guān)注
關(guān)注
87文章
31490瀏覽量
269929
原文標題:推理速度數(shù)倍提升,大幅簡化多GPU后端部署:Meta發(fā)布全新推理引擎AITemplate
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Meta發(fā)布新AI模型Meta Motivo,旨在提升元宇宙體驗
Arm推出GitHub平臺AI工具,簡化開發(fā)者AI應(yīng)用開發(fā)部署流程
Meta開發(fā)新搜索引擎,減少對谷歌和必應(yīng)的依賴
亞馬遜云科技上線Meta Llama 3.2模型
Meta發(fā)布多模態(tài)LLAMA 3.2人工智能模型
Meta不會在歐盟提供新的多模態(tài)AI模型
NVIDIA全面加快Meta Llama 3的推理速度
高通與Meta合作優(yōu)化Meta Llama 3,實現(xiàn)終端側(cè)運行
Meta第二代自研AI芯片出世,性能提升三倍以上






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論